【DW动手学大模型应用全栈开发】 - (2)大模型RAG实战
Datawhale学习地址由于RAG简单有效,它已经成为主流的大模型应用方案之一。RAG,就是通过引入外部知识,使大模型能够生成准确且符合上下文的答案,同时能够减少模型幻觉的出现。例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
系列文章目录
动手学大模型应用全栈开发 - (1)大模型应用开发应知必会
动手学大模型应用全栈开发 - (2)大模型RAG实战
文章目录
前言
一、引言 - 为什么会出现RAG?
- 前一章节,成功搭建了一个源大模型智能对话Demo,亲身体验到了大模型出色的能力。
- 然而,在实际业务场景中,通用的基础大模型可能存在无法满足我们需求的情况,主要有以下几方面原因:
-
知识局限性:大模型的知识来源于训练数据,而这些数据主要来自于互联网上已经公开的资源,对于一些实时性的或者非公开的,由于大模型没有获取到相关数据,这部分知识也就无法被掌握。
-
数据安全性:为了使得大模型能够具备相应的知识,就需要将数据纳入到训练集进行训练。然而,对于企业来说,数据的安全性至关重要,任何形式的数据泄露都可能对企业构成致命的威胁。
-
大模型幻觉:由于大模型是基于概率统计进行构建的,其输出本质上是一系列数值运算。因此,有时会出现模型“一本正经地胡说八道”的情况,尤其是在大模型不具备的知识或不擅长的场景中。
- 为了上述这些问题,研究人员提出了检索增强生成(Retrieval Augmented Generation, RAG ) 的方法。
二、什么是RAG
由于RAG简单有效,它已经成为主流的大模型应用方案之一。
- RAG,就是通过引入外部知识,使大模型能够生成准确且符合上下文的答案,同时能够减少模型幻觉的出现。
2.1 RAG 的三个步骤
-
索引:将文档库分割成较短的 Chunk ,即文本块或文档片段,然后构建成向量索引。
-
检索:计算问题和 Chunks 的相似度,检索出若干个相关的 Chunk。
-
生成:将检索到的Chunks作为背景信息,生成问题的回答。
2.2 一个完整的 RAG 链路
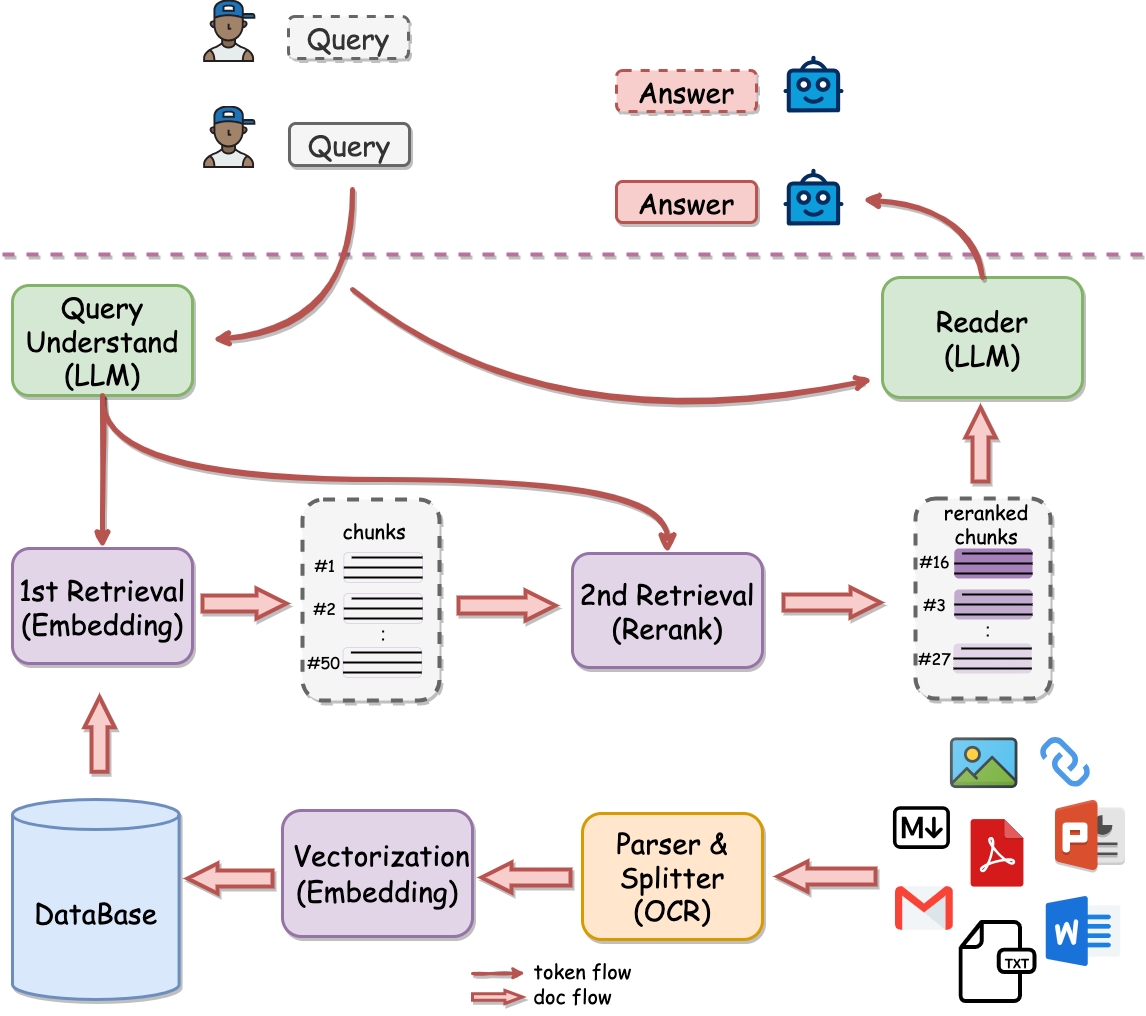
- 从上图可以看到,线上接收到用户 query 后,RAG会先进行检索,然后将检索到的 Chunks 和 query 一并输入到大模型,进而回答用户的问题。
为了完成检索,需要离线将文档(ppt、word、pdf等)经过解析、切割甚至OCR转写,然后进行向量化存入数据库中。
2.2.1 离线计算
-
因为知识库中包含了多种格式的文件,如pdf、word、ppt等,这些 文档 (Documents) 需要提前被解析,然后切割成若干个较短的 Chunk ,并且进行清洗和去重。
-
由于知识库中知识的数量和质量决定了RAG的效果,因此这是非常关键且必不可少的环节。
然后,我们会将知识库中的所有 Chunk 都转成向量,这一步也称为 向量化 (Vectorization)或者 索引 (Indexing)。
向量化 需要事先构建一个 向量模型 (Embedding Model),它的作用就是将一段 Chunk 转成 向量 (Embedding)。如下图所示:
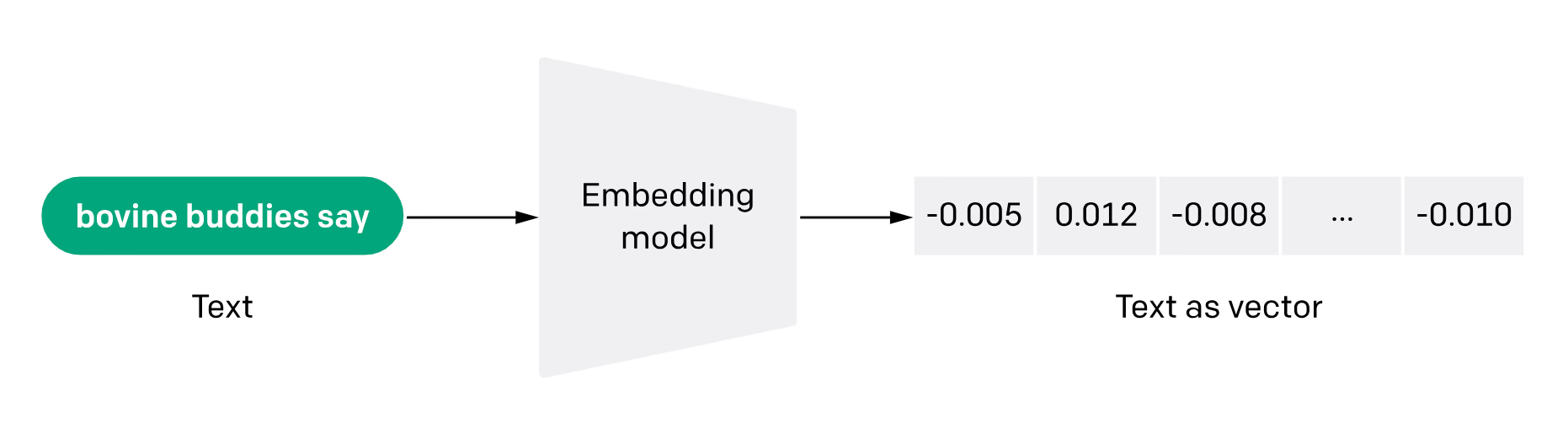
2.2.2 向量模型
-
向量模型通常采用
BERT架构,它是一个Transformer Encoder。 -
输入向量模型前,首先会在文本的最前面额外加一个
[CLS]token,然后将该token最后一层的隐藏层向量作为文本的表示。如下图所示:
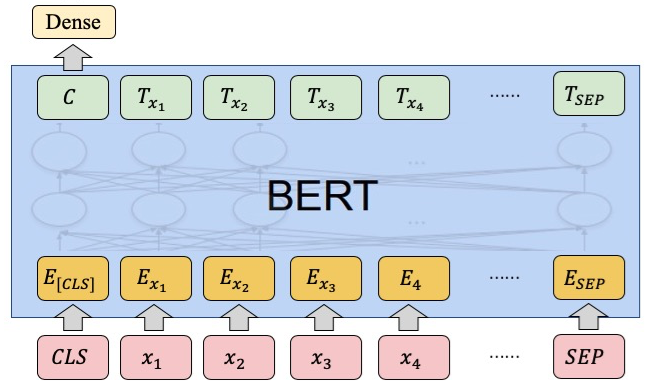
-
目前,开源的基于BERT架构的向量模型有如下:
- BGE Embedding:智源通用embedding(BAAI general embedding, BGE)
- BCEmbedding:网易有道训练的Bilingual and Crosslingual Embedding
- jina-embeddings:Jina AI训练的text embedding
- M3E:MokaAI训练的 Massive Mixed Embedding
-
除了BERT架构之外,还有基于LLM的向量模型有如下:
- LLM-Embedder:智源LLM-Embedder
-
其次,还有API:
-
OpenAI API
-
Jina AI API
-
ZhipuAI API
-
3. RAG 框架
-
目前,开源社区中已经涌现出了众多RAG框架,例如:
-
TinyRAG:DataWhale成员宋志学精心打造的纯手工搭建RAG框架。
-
LlamaIndex:一个用于构建大语言模型应用程序的数据框架,包括数据摄取、数据索引和查询引擎等功能。
-
LangChain:一个专为开发大语言模型应用程序而设计的框架,提供了构建所需的模块和工具。
-
QAnything:网易有道开发的本地知识库问答系统,支持任意格式文件或数据库。
-
RAGFlow:InfiniFlow开发的基于深度文档理解的RAG引擎。
-
···
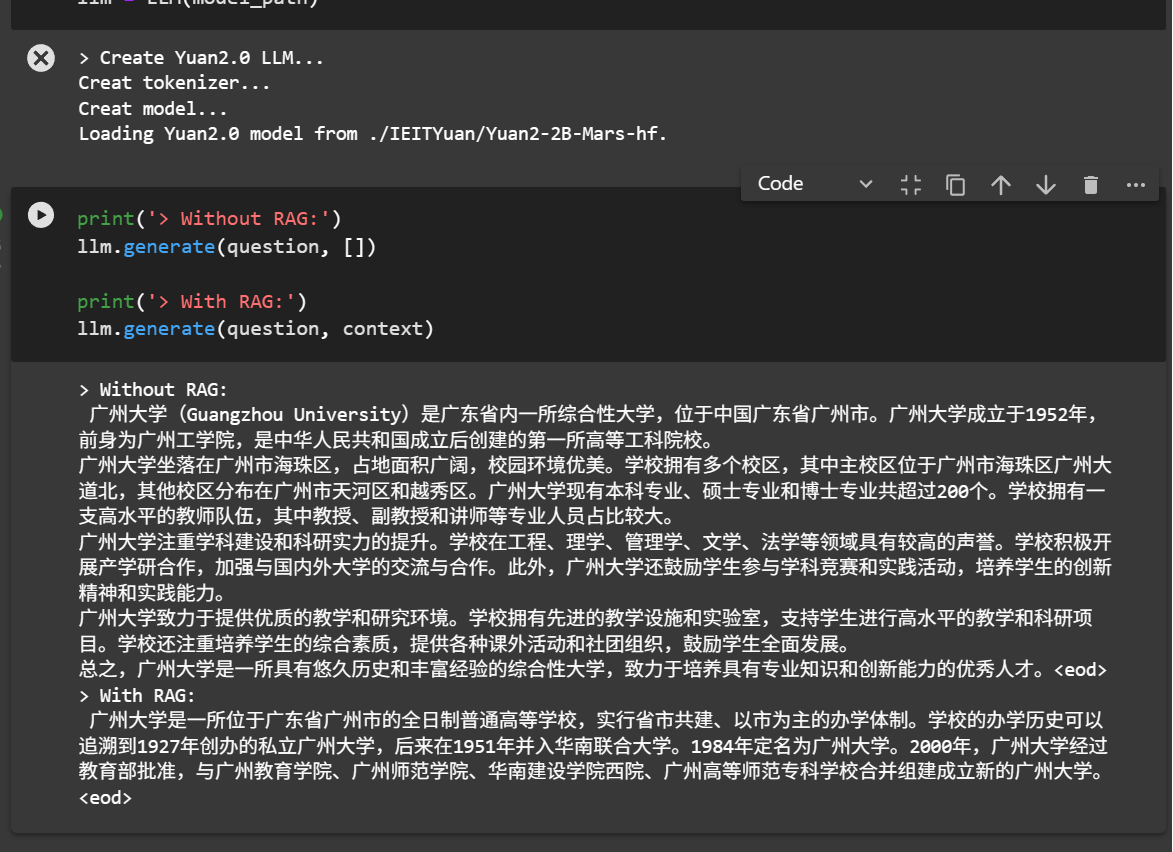
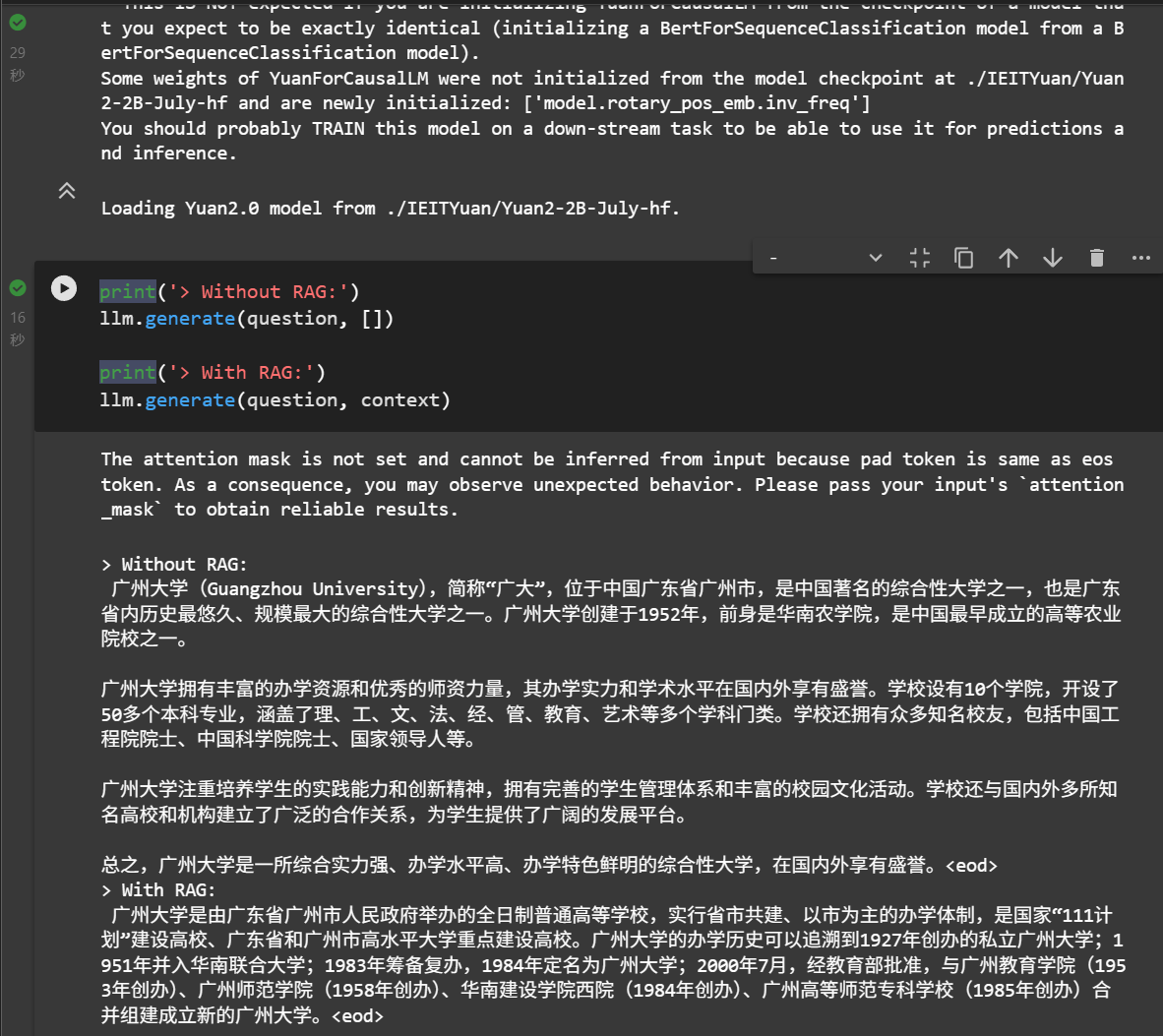
4. 第一个RAG实战
以 Yuan2-2B-Mars 模型为基础,进行RAG实战。希望通过构建一个简化版的RAG系统,来掌握RAG的核心技术,从而进一步了解一个完整的RAG链路。
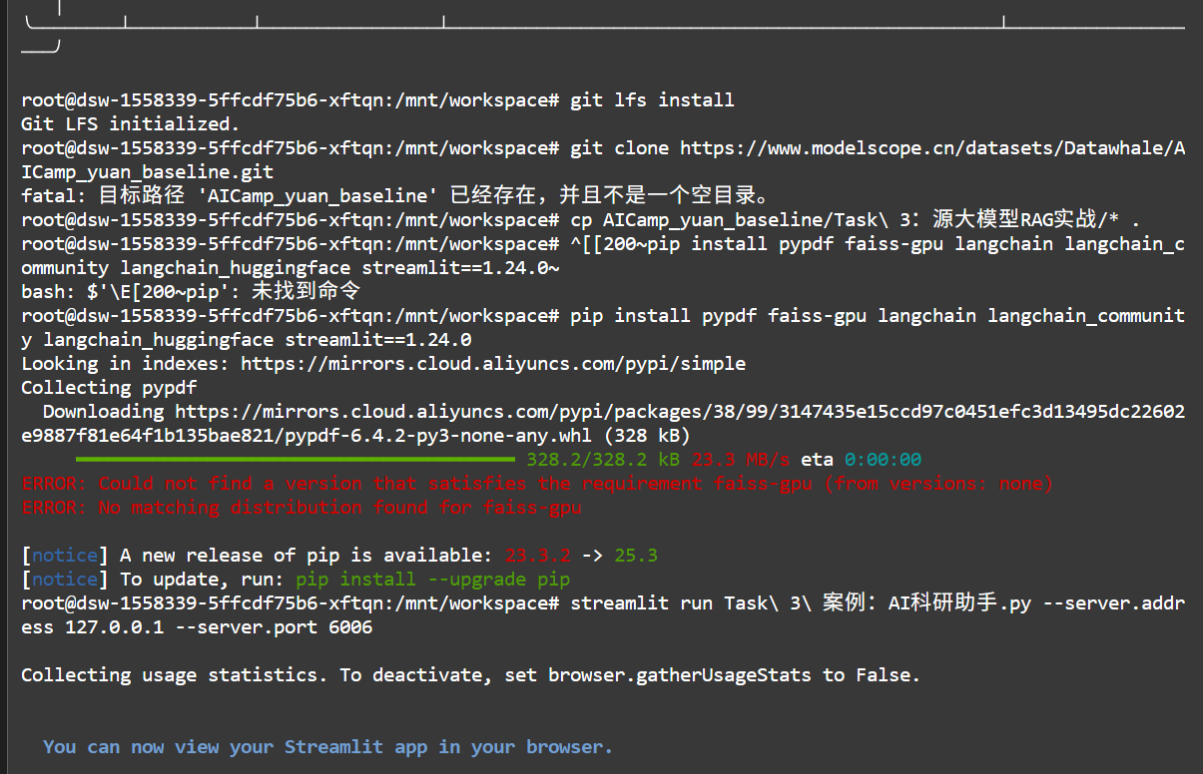
- 进入实例,点击Terminal
- 运行下面代码,下载文件,并将
Task 3:源大模型RAG实战中内容拷贝到当前目录。
git lfs install
git clone https://www.modelscope.cn/datasets/Datawhale/AICamp_yuan_baseline.git
cp AICamp_yuan_baseline/Task\ 3:源大模型RAG实战/* .
- 双击打开
Task 3:源大模型RAG实战.ipynb,然后运行所有单元格。
- 模型下载
-
基于BERT架构的向量模型 bge-small-zh-v1.5 ,它是一个4层的BERT模型,最大输入长度512,输出的向量维度也为512。
-
bge-small-zh-v1.5 支持通过多个平台进行下载
-
模型在魔搭平台的地址为AI-ModelScope/bge-small-zh-v1.5
- 构造索引,这里封装了一个向量模型类
EmbeddingModel
总结

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)