Dify大模型应用开发(Task3-workflow、知识库、SQL+EChart、DeepSearch)
Dify进阶工作流方向1.workflow实践(小红书读书卡片)2.Dify综合应用(面试宝典)3.text2sql 及 echart数据分析4.deepsearch设计学习时长:4天❗️截止时间 12月24日03:00大家好,Task3开始就是进阶任务了。由于任务开始有点复杂了,所以官方文档里只给出了重点的操作内容,并没有把每一步操作都指示的很详细。有时需要自己摸索一下!HTML 在线运行 -
---🐳Task3️⃣:
Dify进阶工作流方向
1.workflow实践(小红书读书卡片)
2.Dify综合应用(面试宝典)
3.text2sql 及 echart数据分析
4.deepsearch设计
学习时长:4天
❗️截止时间 12月24日03:00
飞书云文档的教程:
https://ai.feishu.cn/docx/RLVSdcLZZo7qhjxbsyTcNT2bnf5?from=from_copylink
大家好,Task3开始就是进阶任务了。由于任务开始有点复杂了,所以官方文档里只给出了重点的操作内容,并没有把每一步操作都指示的很详细。有时需要自己摸索一下!
避雷①:小红书读书卡片的效果
1.关于大模型的选择 生成html、css的大模型要使用参数大的。一般的模型(qwen3:8b)生成的效果很差,使用教程里的deepseek V3效果不错。但是生成效果的稳定性不是很好,还是有需要修改的地方,例如图片链接、显示内容不完全的问题需要修改。我觉得AI设计+手动修改是一个比较好的设计流程,完全指望AI是个概率事件。
2.关于手动修改 教程使用Artifacts插件可以直接渲染出结果,这个对于可以直接使用的效果来说非常方便。但是,如果需要手动修改就不行了。
2个缺点:
①Artifacts里面的代码不可以修改;
②生成的结果不会保留,下载再想使用就找不到了,自己保存又很麻烦。
所以,我的方法是Artifacts学习一下就可以了。真正创作时,使用agent的运行页面
2个优点:
①效果渲染使用网络html工具,可以修改代码,效果即可可见;
②运行的历史结果有保留;
下面是一个html效果渲染的网页:
HTML 在线运行 - 锤子在线工具![]() https://www.toolhelper.cn/Html/Preview
https://www.toolhelper.cn/Html/Preview
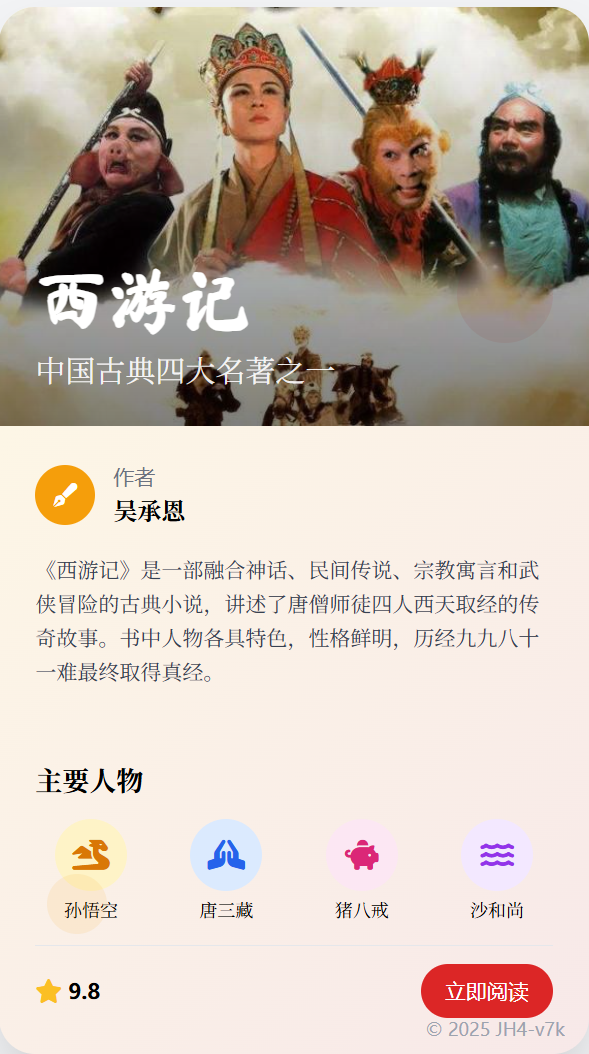
这是我修改了图片链接后的效果:
避雷②:text2sql 及 echart数据分析任务中给echart的数据格式错误
给echart的X轴、Y轴的数据格式是固定的,例如:
X轴:"消极"; "中性"; "积极" (是字符串类型)
Y轴:121; 133; 95(必须是数值类型)
如果传给echart的数据格式不对或者有任何多余的内容,echart就不能显示出图表。
而教程里给的prompt不足以控制好输出结果,所以需要自己修改一下prompt(⚠️这也是我在Task3中花时间最多的地方)。
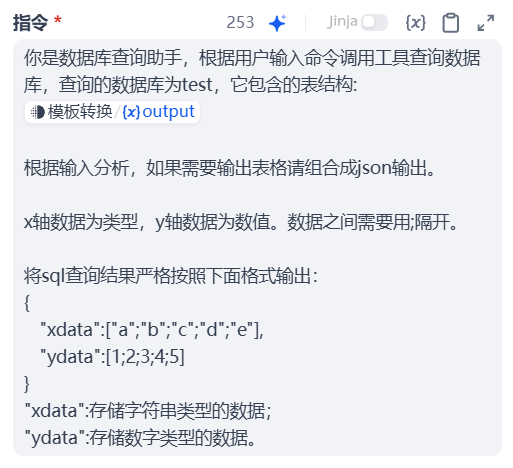
下面是我修改后的Agent的promt(其中(x)output要设置成自己agent的参数形式,使用时需要注意):
可以copy的:
你是数据库查询助手,根据用户输入命令调用工具查询数据库,查询的数据库为test,它包含的表结构:
{{(x).output}}
根据输入分析,如果需要输出表格请组合成json输出。
x轴数据为类型,y轴数据为数值。数据之间需要用;隔开。
将sql查询结果严格按照下面格式输出:
{
"xdata":["a";"b";"c";"d";"e"],
"ydata":[1;2;3;4;5]
}
"xdata":存储字符串类型的数据;
"ydata":存储数字类型的数据。LLM的prompt(输出Y轴数据):
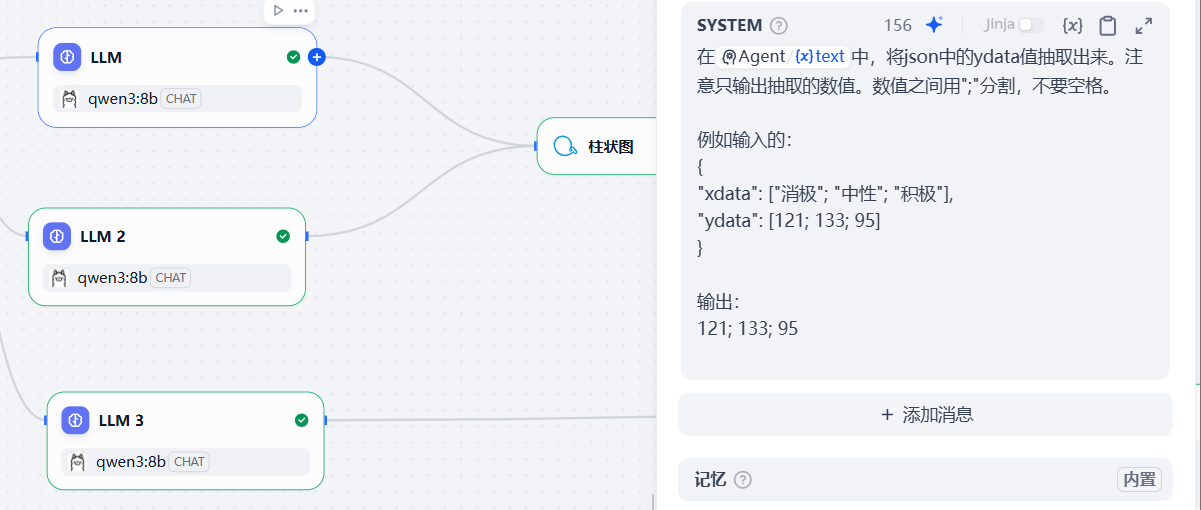
可copy:
在{{#1766073232241.text#}}中,将json中的ydata值抽取出来。注意只输出抽取的数值。数值之间用";"分割,不要空格。
例如输入的:
{
"xdata": ["消极"; "中性"; "积极"],
"ydata": [121; 133; 95]
}
输出:
121; 133; 95LLM2的prompt(输出X轴标签):
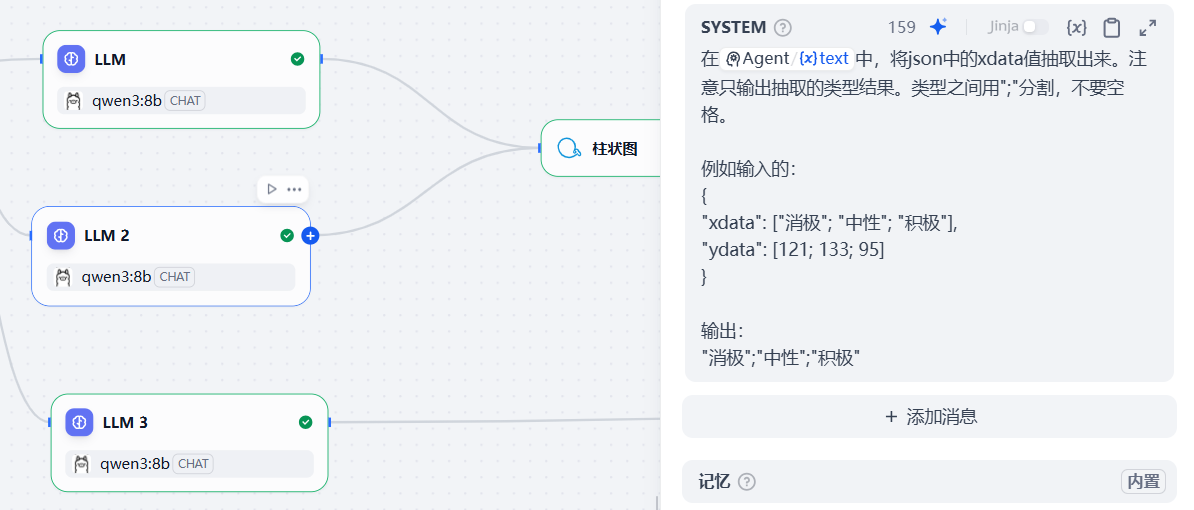
可copy:
在{{#1766073232241.text#}}中,将json中的xdata值抽取出来。注意只输出抽取的类型结果。类型之间用";"分割,不要空格。
例如输入的:
{
"xdata": ["消极"; "中性"; "积极"],
"ydata": [121; 133; 95]
}
输出:
"消极";"中性";"积极"LLM3的prompt(输出X轴标签):
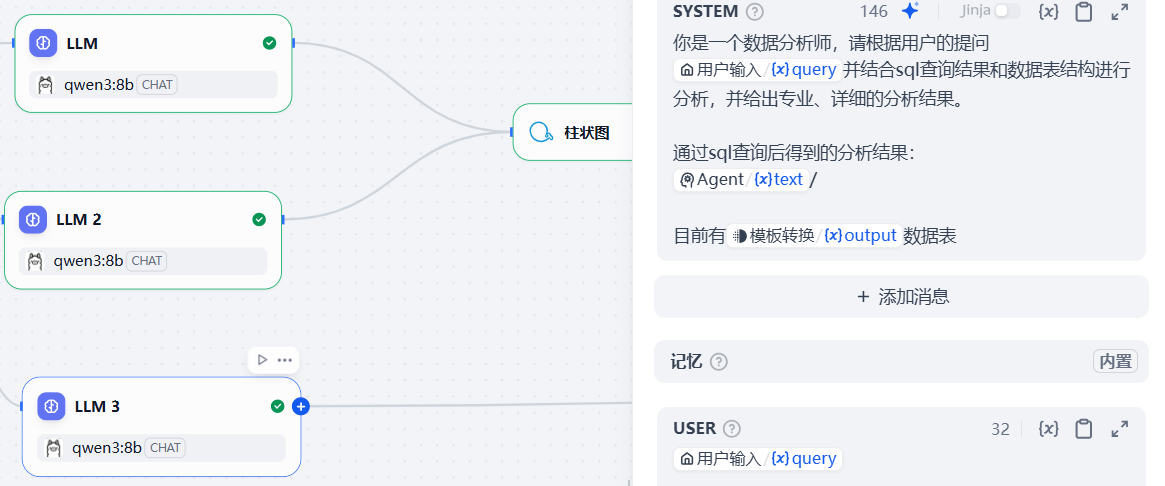
可copy:
你是一个数据分析师,请根据用户的提问{{#sys.query#}}并结合sql查询结果和数据表结构进行分析,并给出专业、详细的分析结果。
通过sql查询后得到的分析结果:
{{#1766073232241.text#}}/
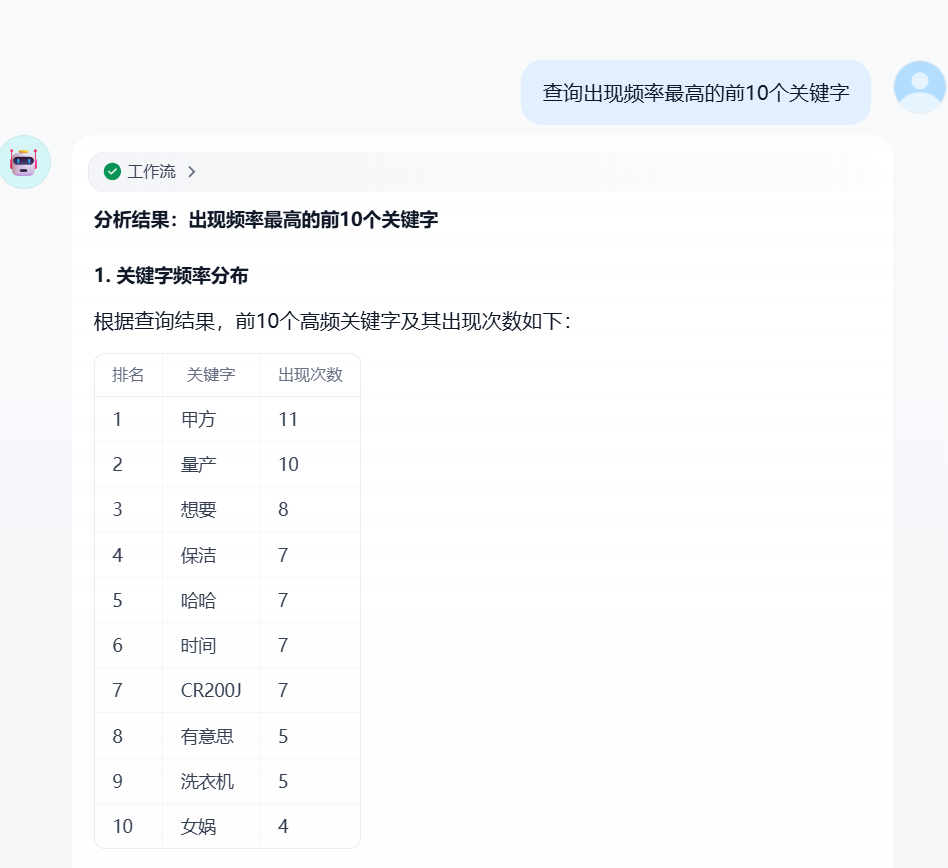
目前有{{#1766073194527.output#}}数据表效果(不一定每次都是好的,如果效果不好可以多试几次。大模型的输出结果是有概率的,不能100%准确。如果要输出稳定的效果,prompt设计上可以做功夫,prompt的入门门槛很低,天花板确很高,加油!):


关于另外两个任务:
Dify综合应用(面试宝典)
就是文件内容有些多,在文件向量化的时候需要多等一会,因为有了之前数据库的经验,这里操作上不会有问题。
deepsearch设计
关于网络搜索的原理,教程里写了很多,非常好,有时间要好好研究学习,理解实现的原理。Tavily Search(我用微信浏览器可以登录,Edge就打不开登录页面)每月有1000免费使用的额度,学习使用足够了。教程里还有另外一个搜索插件【博查】,需要花点银子。
好了,关于Task3的分享就到这里啦,如有问题欢迎留言讨论!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)