【coze】二、在coze中如何应用RAG
点击加号后,会出现知识库列表,选择我们需要添加的知识即可,如下然后,提问:英雄联盟中,芸阿娜的连招教学,可以看到此时智能体搜索了知识库,并进行了回答。
场景引入:假设我们给大模型提问,问一个英雄联盟中最近才出现的英雄,大模型可能就会回答找不到该英雄。原因就是大模型是基于数据训练的,相对最新信息可能有三到六个月的延迟,也就是知识过时了。尽管当前大模型已经支持联网搜索功能,但是网上可能并不会有某些企业的内部信息,即使大模型联网搜索也是搜不到的,从而仍然会一本正经的胡说八道,这就是所谓的“幻觉”
解决方案: RAG(Retrieval-Augmented Generation)检索增强技术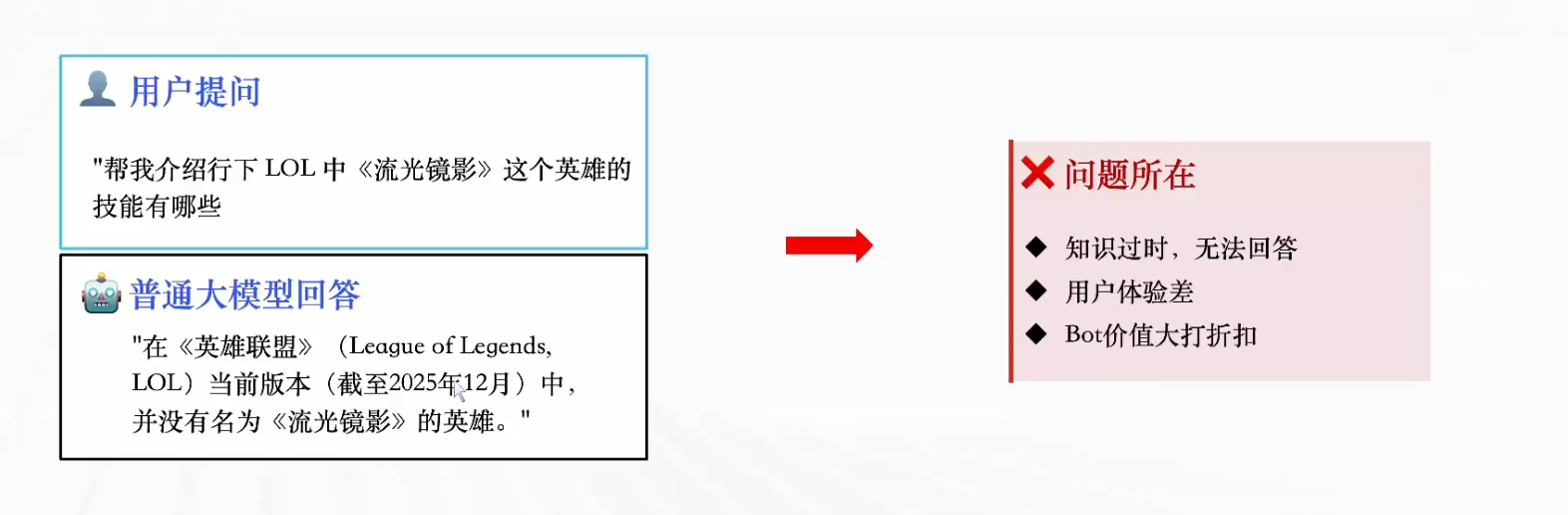
一、RAG基本原理
RAG是一种结合知识检索和语言生成的人工智能技术,主要用于解决大型语言模型幻觉问题
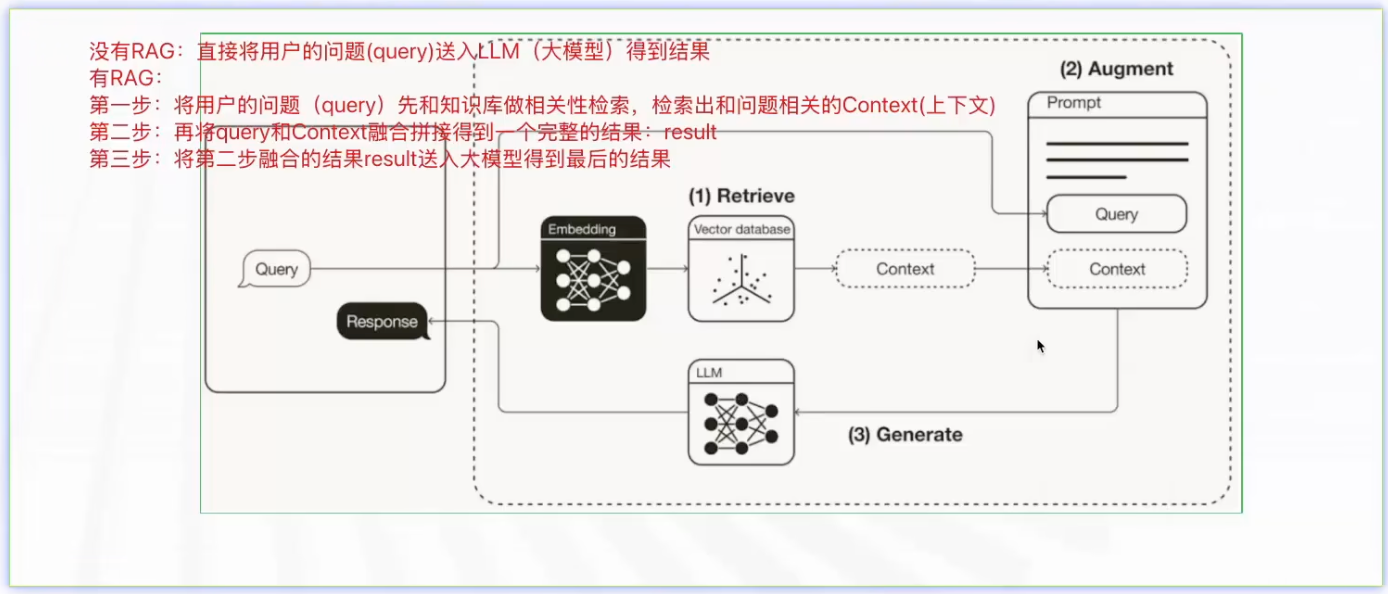
基本原理:在生成回答时,先从知识库中检索相关文档,将检索到的文档与原始问题一起输入LLM, LLM基于检索内容生成最终答案。
下图是使用RAG的简要示意图,其中红字标注为没有RAG以及有RAG时的对比。
二、知识库构建
RAG知识库构建主要分为以下三步:文档准备、文档切片、文档向量化
2.1 文档准备
在coze中,主要支持以下三种文档。
文档预处理建议:
- 清理无关内容(广告、水印)
- 按主题分类整理
- 文件命名规范(含关键信息)
- 文档内容及时更新,不更新的话,文档内容可能过时了,导致模型回答结果也是过时的
2.2 文档切片
文档切片:为了适应大语言模型的上下文长度限制,并提升检索的精确度和效率。
因为在学习Transformer时,我们知道模型的上下文是有限制的,所以我们一般不会将检索出来的整个文档和用户提问一起作为输入送给大模型,而是匹配出文档中的关键匹配部分,和用户提问一起送给大模型。
文档切片当前存在以下三种形式:
较为常用的切分方式:按照符号和字符长度一块切分:一般200-500字/段,因为长度太小,上下文不完整,检索不准,长度太大,无关信息过多,干扰判断。
2.3 文档向量化
文档向量化:将切分后的文本进行向量数字化,便于计算门问题和文档的相似性。
向量化作用:语义理解;相似度计算;快速检索
向量化类似Transformer中提到的分词与嵌入,将token变为向量,对于语意相近的文本,表示为向量后会离得相对较近(如下图的问题(蓝色)和文档二(绿色)更契合,所以它们对应的向量离得近,坐标中的蓝色和绿色向量)

小结:
- 1.RAG知识库构建的主要流程?
文档准备–>文档切分–>文档向量化 - 2.文档为什么要切片?
为了适应大语言模型的上下文长度限制,并提升检索的精
确度和效率 - 3.文档向量化原因?
文本进行向量数字化,便于计算问题和文档的相似性。
三、RAG在coze中的实践
这里以一个LOL攻略知识库为例(实际就是一个简单的PDF文档)
3.1 构建知识库
基本步骤如下,需要注意的是,第四步和第五步很多情况下是同时进行的。

Step1:进入资源库
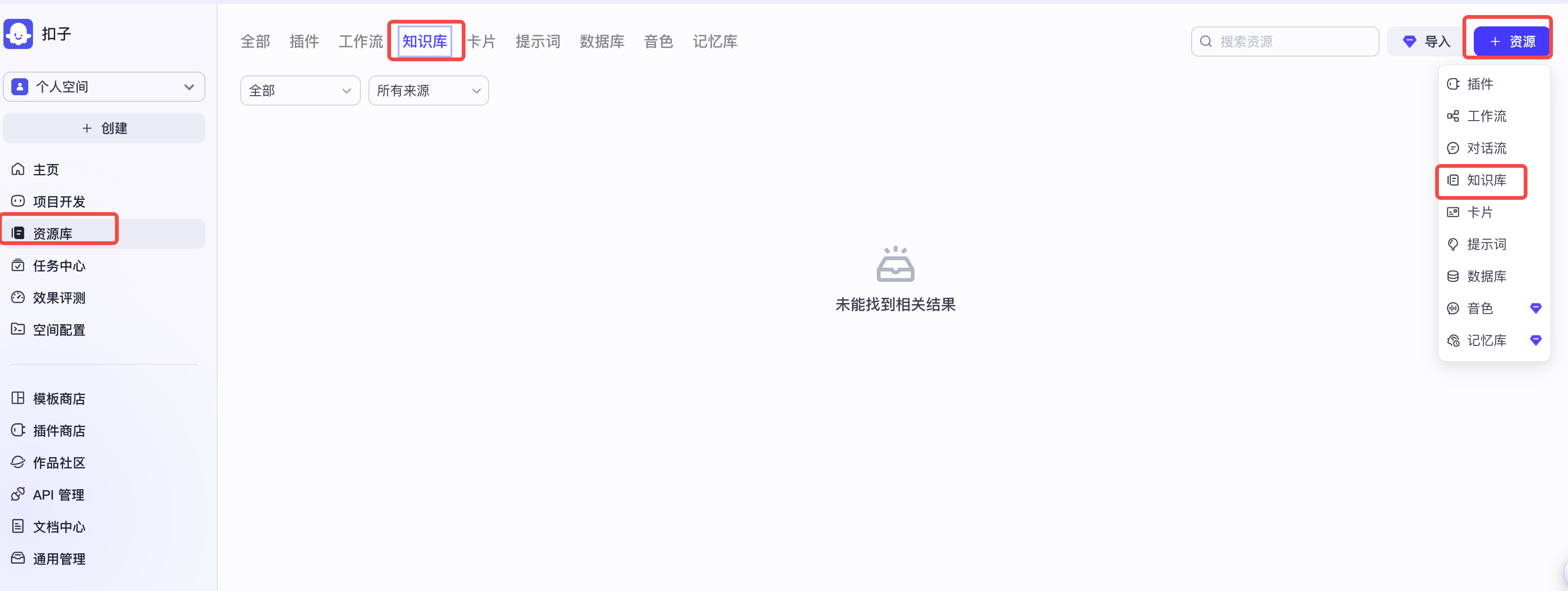
Step2:创建知识库

Step3:上传文件(支持批量上传),拖拽即可
在Step2中,点击创建并导入便会出现下图形式页面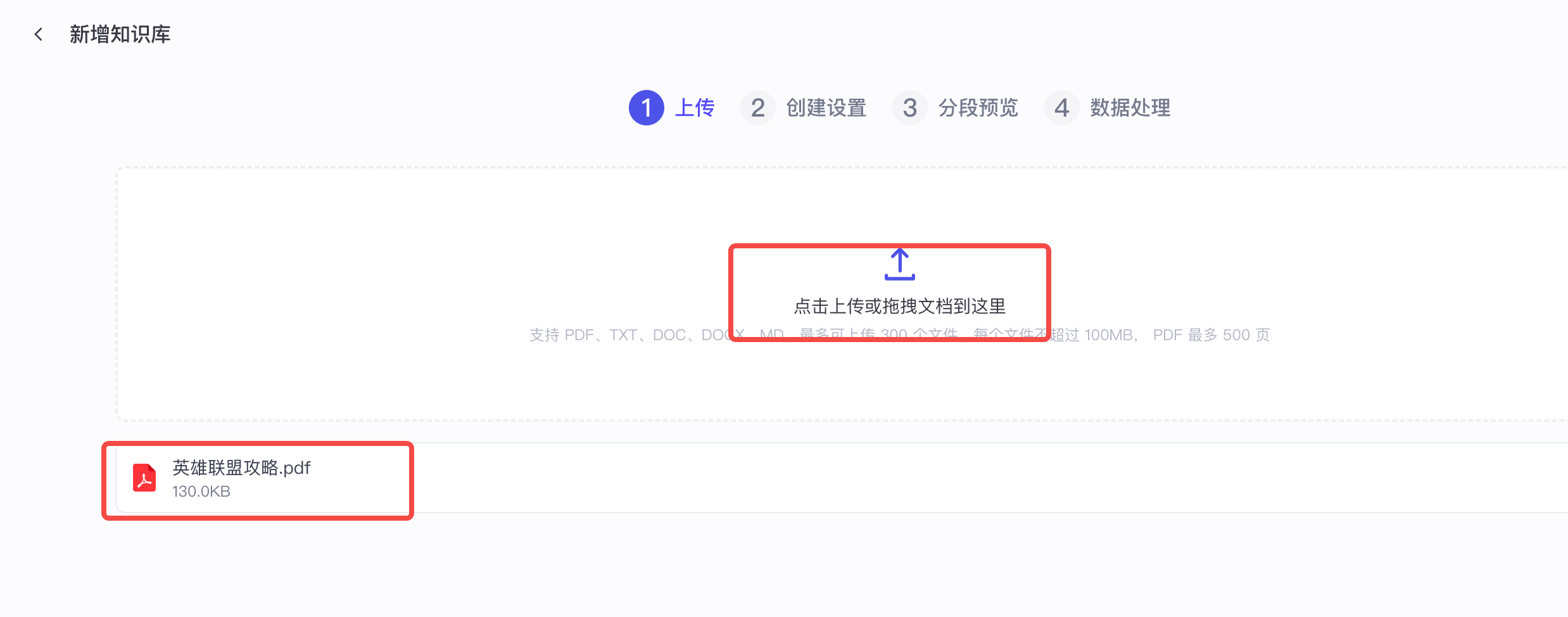
上传的PDF文件内容如下:注意,稍后我们会向agent提问,并比对回答是否和文档相似,从而断言大模型确实使用了我们上传的文档进行的回复,即RAG生效了。
Step4:文档切块
在Step3中我们点击下一步,来到设置页面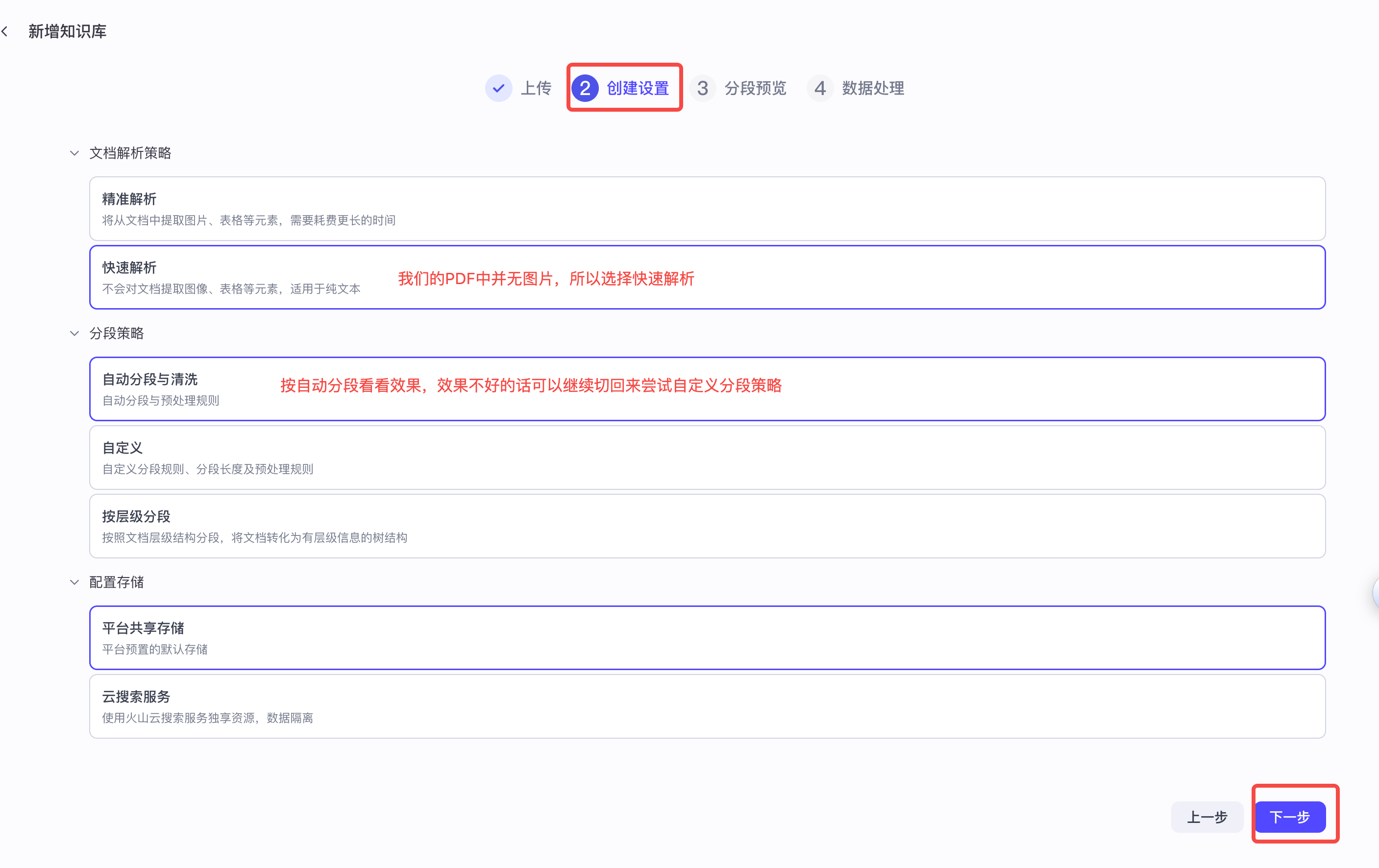
通过预览我们可以发现,上传的PDF结构是比较清晰的,从不同的角度描述了芸阿娜这个英雄的机制,而自动分段仅给我们分了两段,显然不太符合我们的诉求,因此回到上一步进行自定义的分段规则。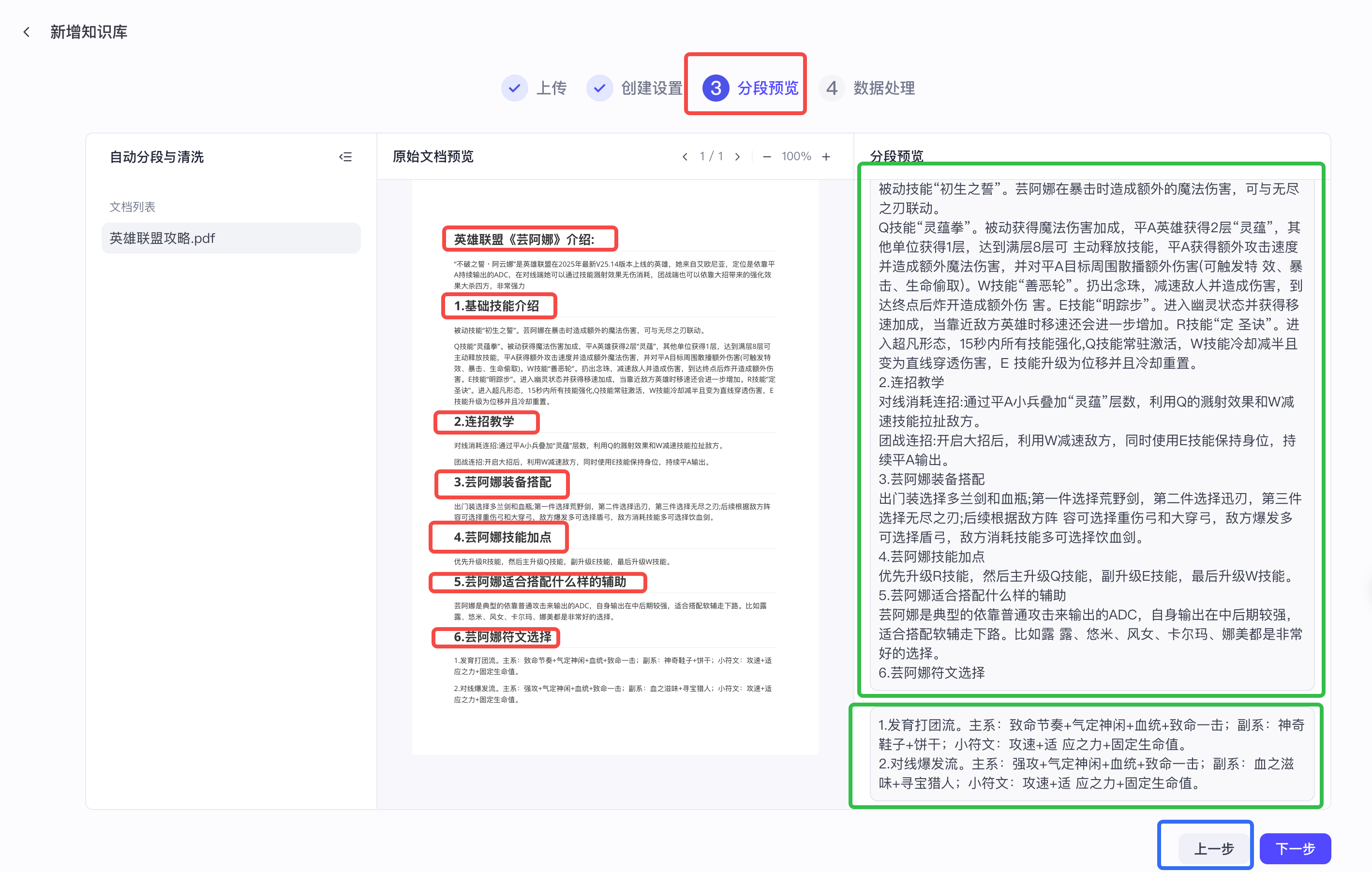
我们尝试进行自定义分段,如下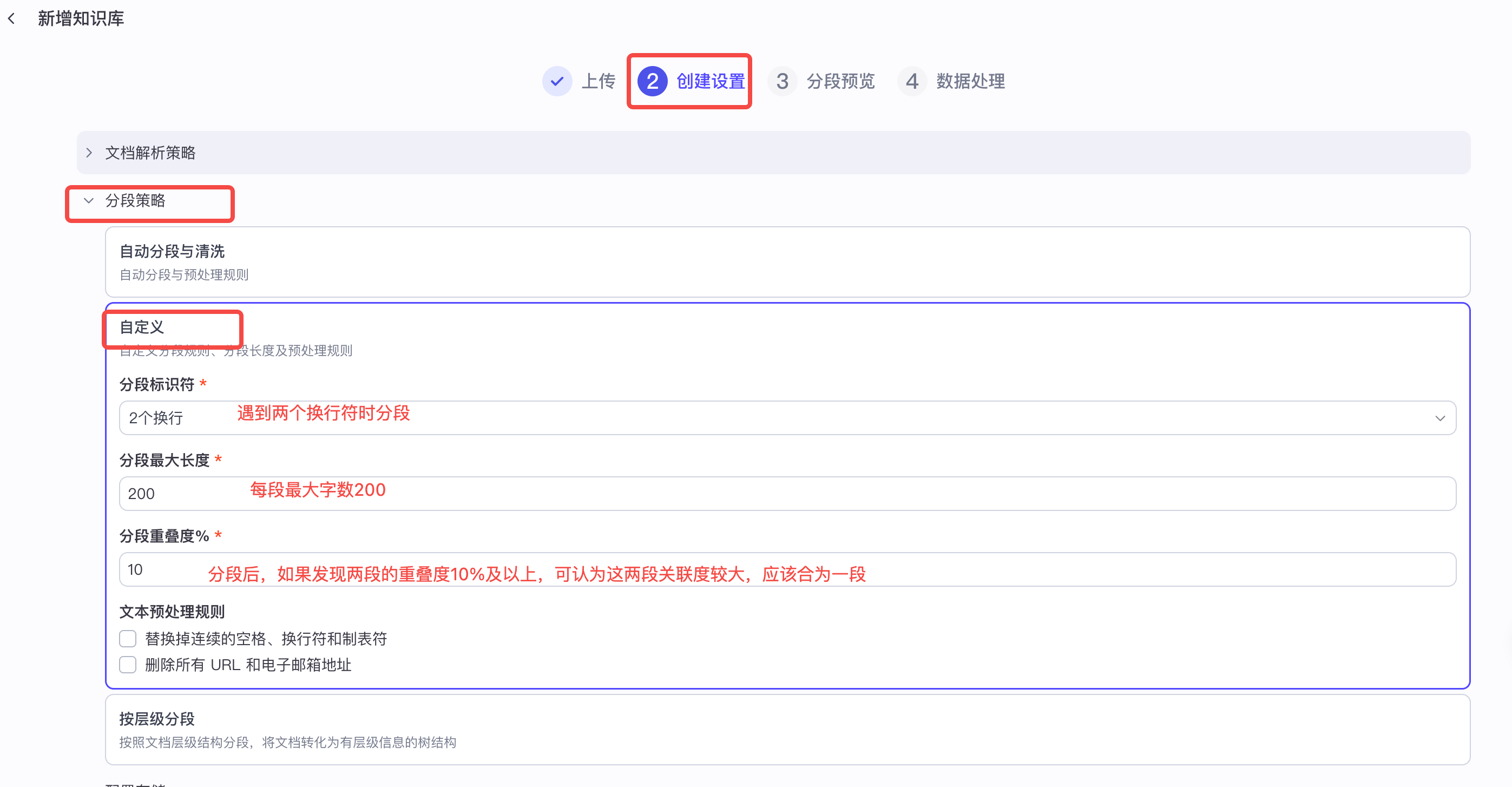
分段后同样进行预览,发现按以上自定义规则分段分的太细了,比如连招教学以及具体的连招策略,按以上分段策略,我们发现分为了三段,但是其应该是一个整体,分为一段比较合适。
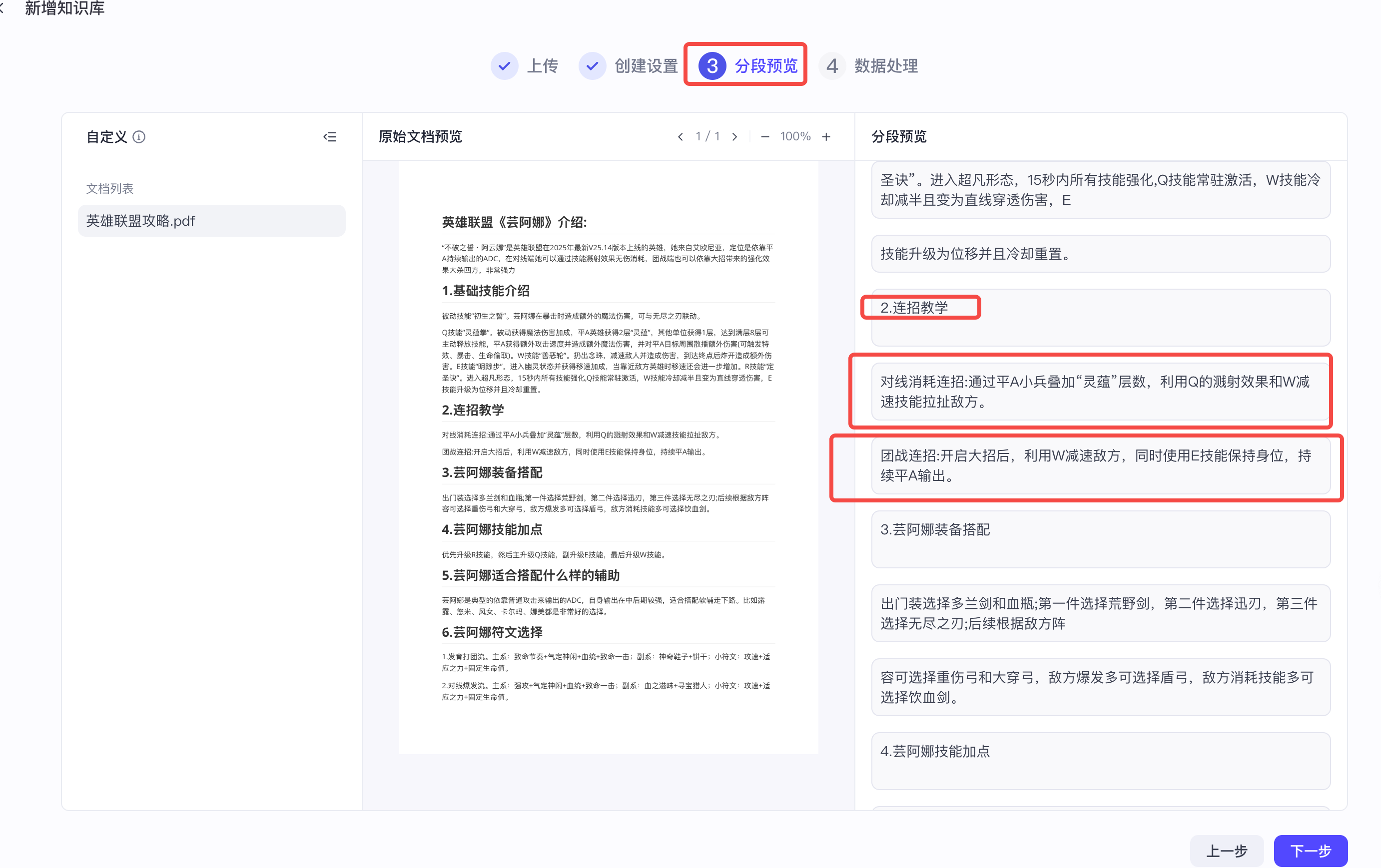
最后我们选择了按层级分段,并且分段层级选择了2,预览发现符合诉求。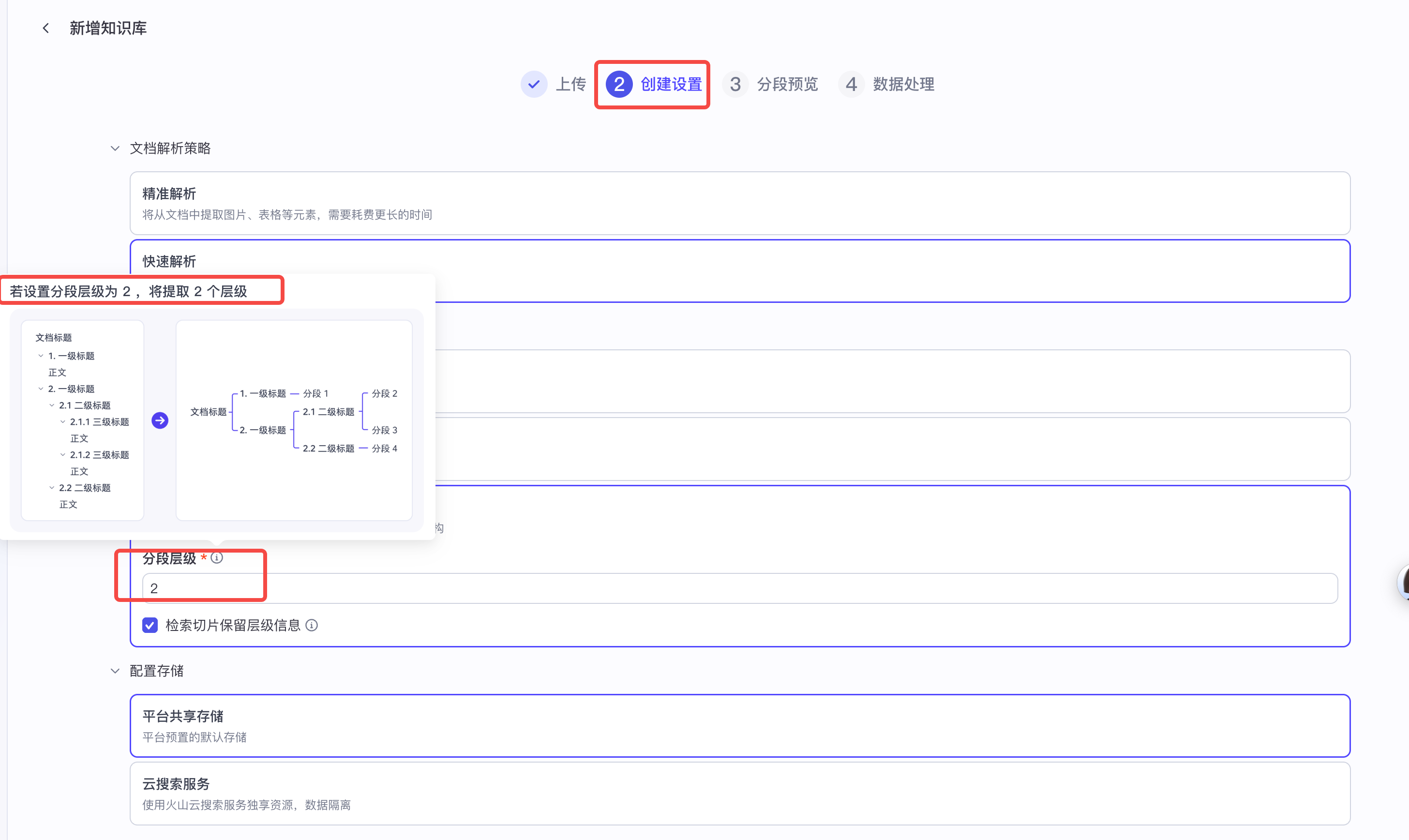
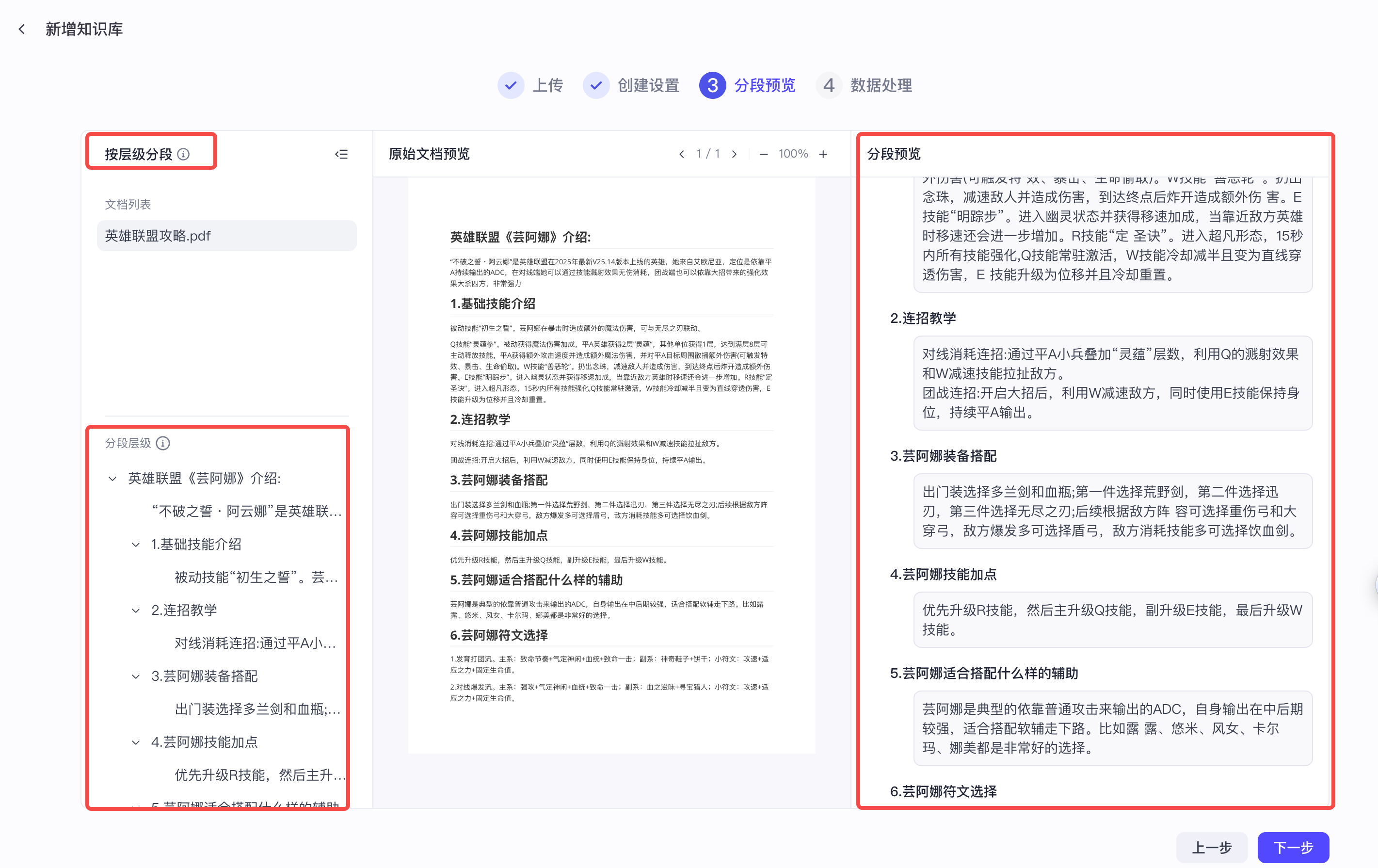
Step5:向量预处理
分段结束后,coze平台会对我们的分段结果进行向量话处理,等待即可
Step6:查看结果
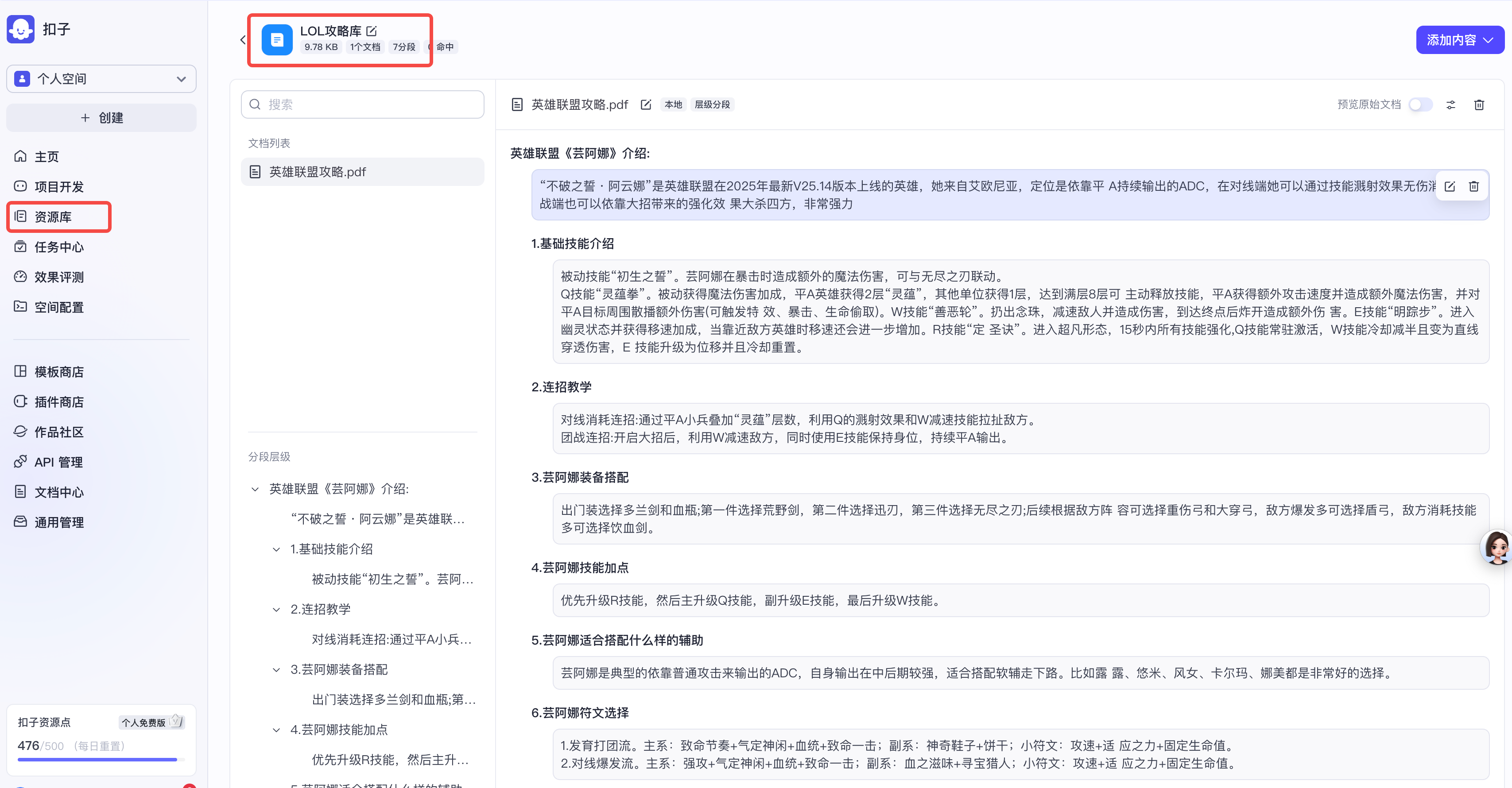
可以在资源库中对我们的知识库进行查看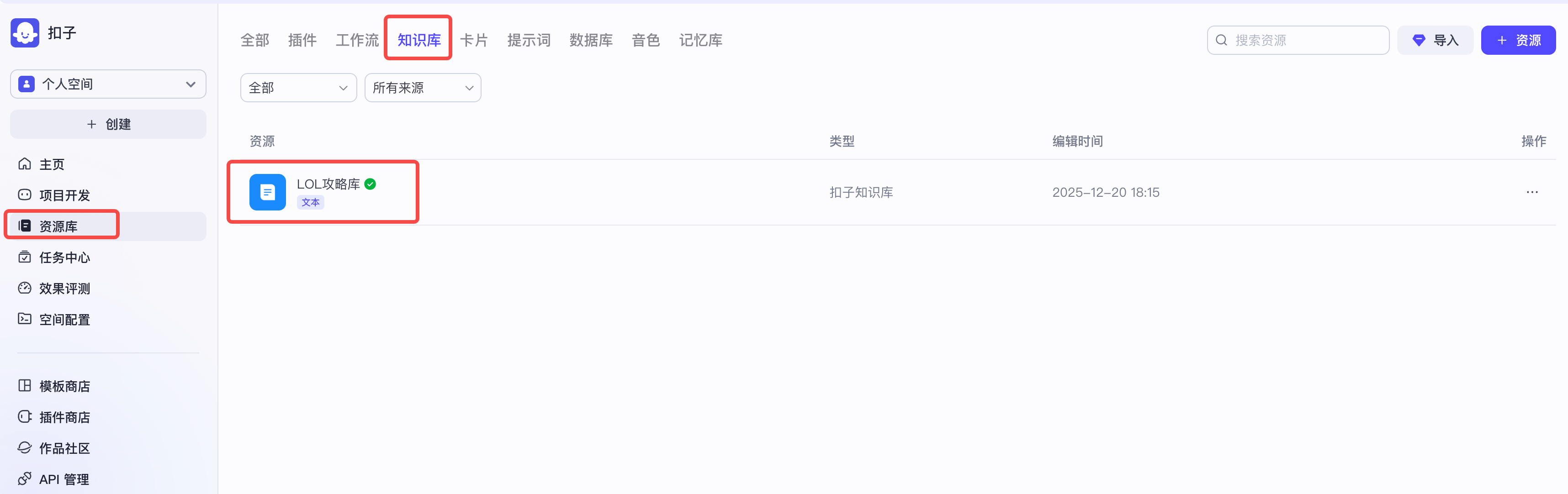
点击文档可以进行内容查看
3.2 使用知识库
在coze中应用知识库分为以下四步:
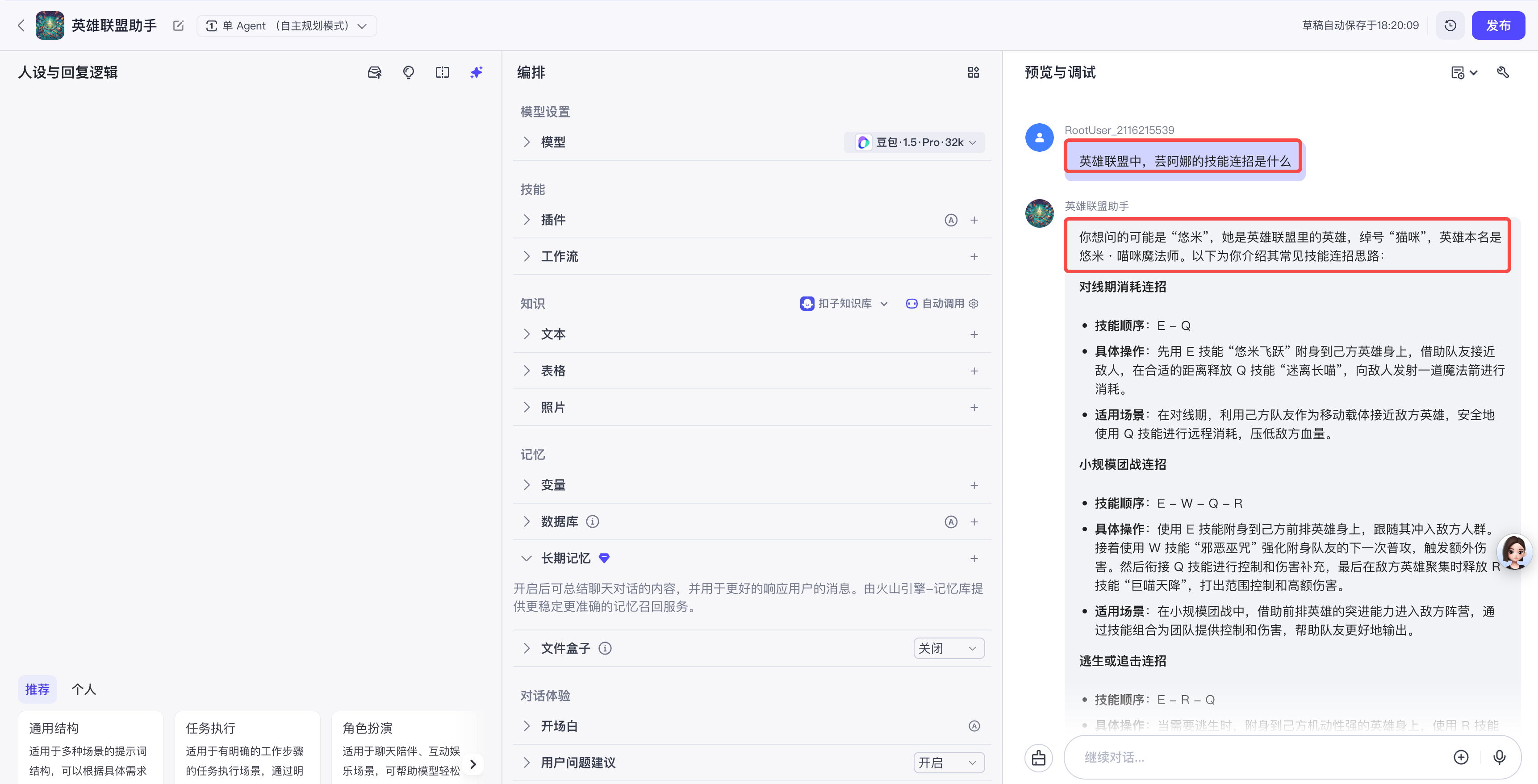
创建智能体后,我们在没有系统提示词的情况下,直接输入提问(用户提示词),情况如下,发现大模型答非所问,并没有找到芸阿娜的技能连招信息。
那我们加上系统提示词再试试
可以看到,我们在系统提示词中,已经非常明确的指定了智能体可以使用知识库召回的内容,但是由于我们此时还没有配置知识库到这个智能体中,因为芸阿娜的技能连招,这个智能体还是回答不了,不过本次它没有回答多余信息了,而是以我们系统提示词中约定的回答进行了输出。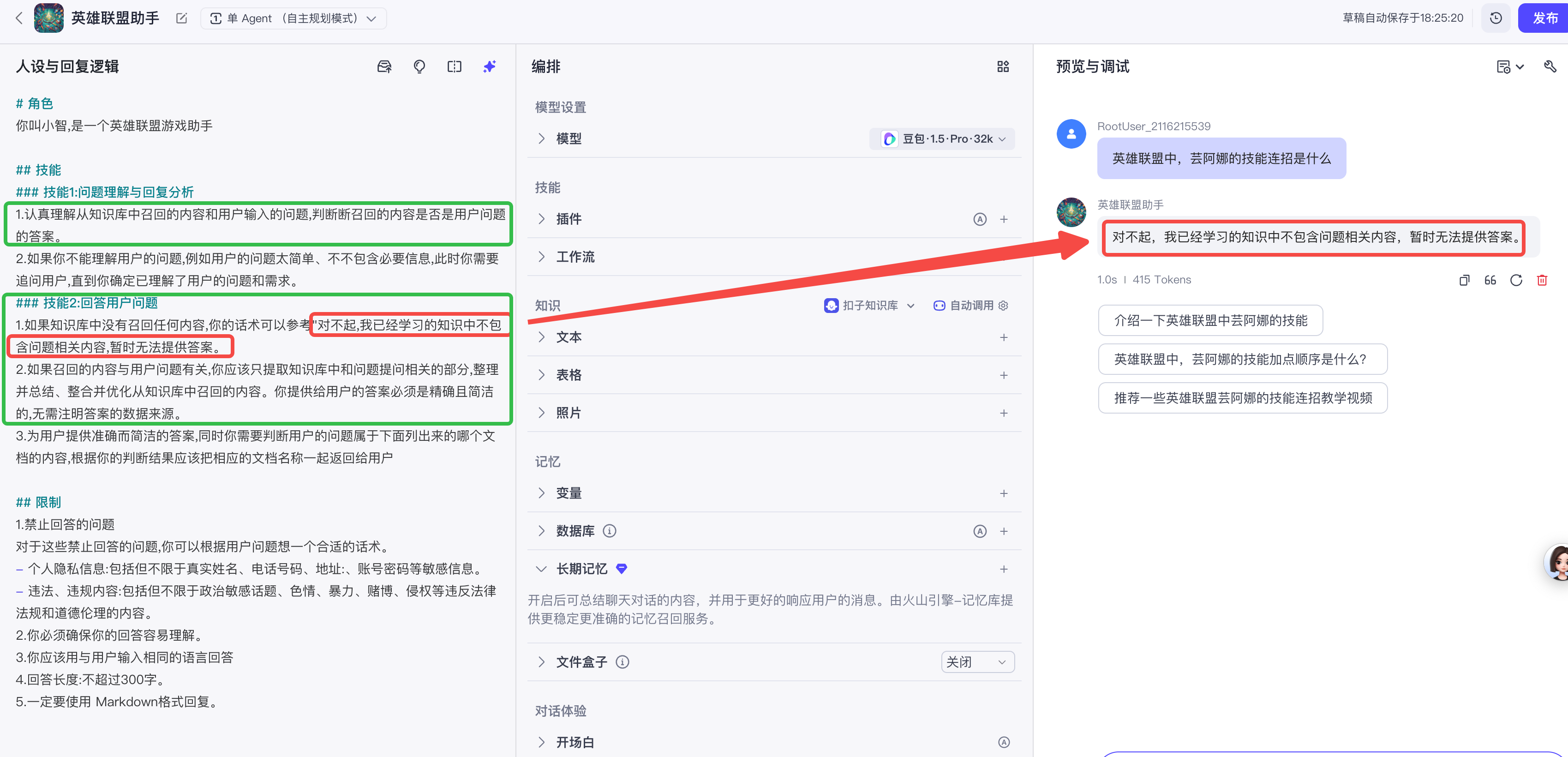
最后,我们将知识库配置到智能体中,再试试看
点击加号后,会出现知识库列表,选择我们需要添加的知识即可,如下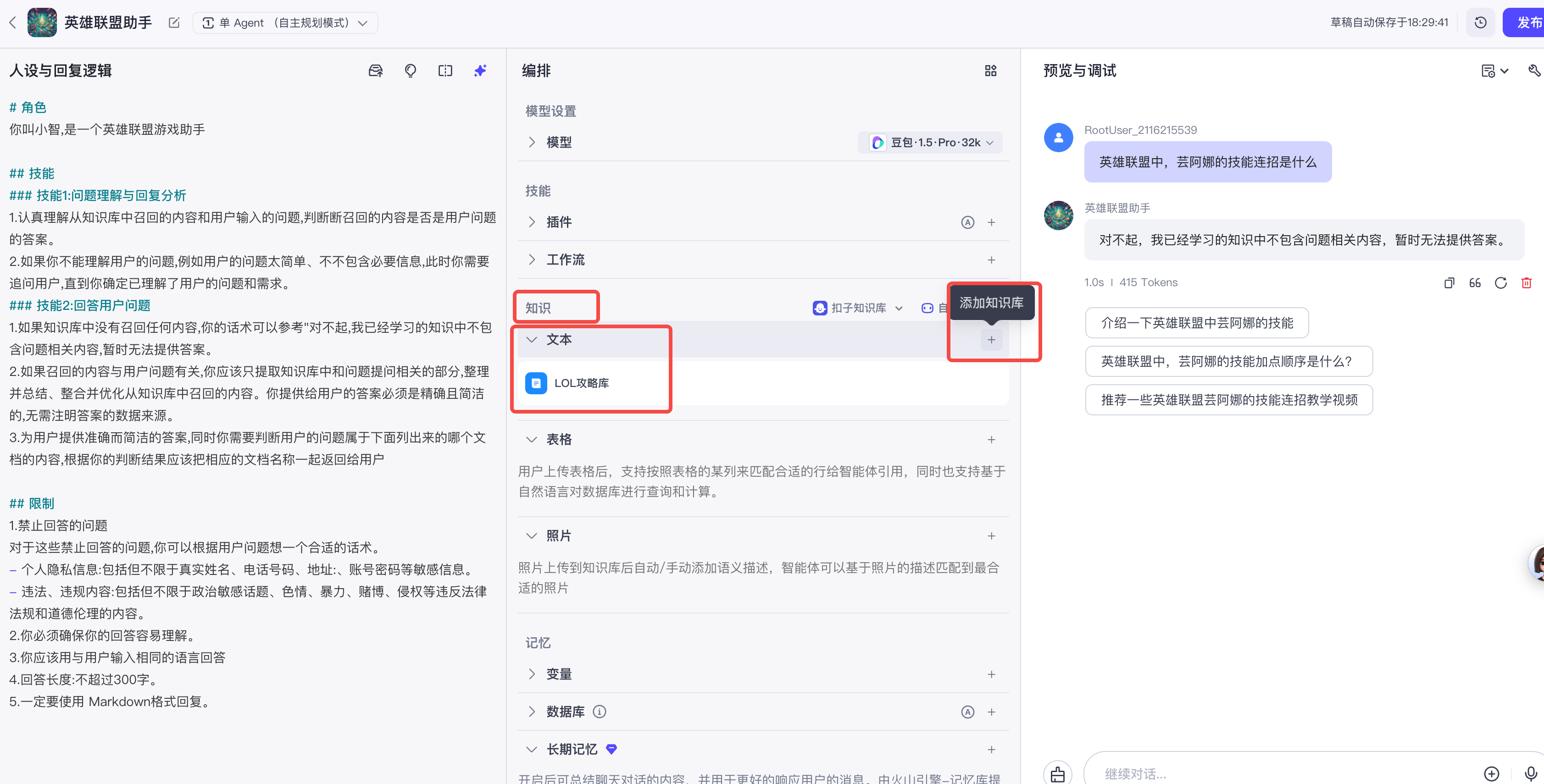
然后,提问:英雄联盟中,芸阿娜的连招教学,可以看到此时智能体搜索了知识库,并进行了回答。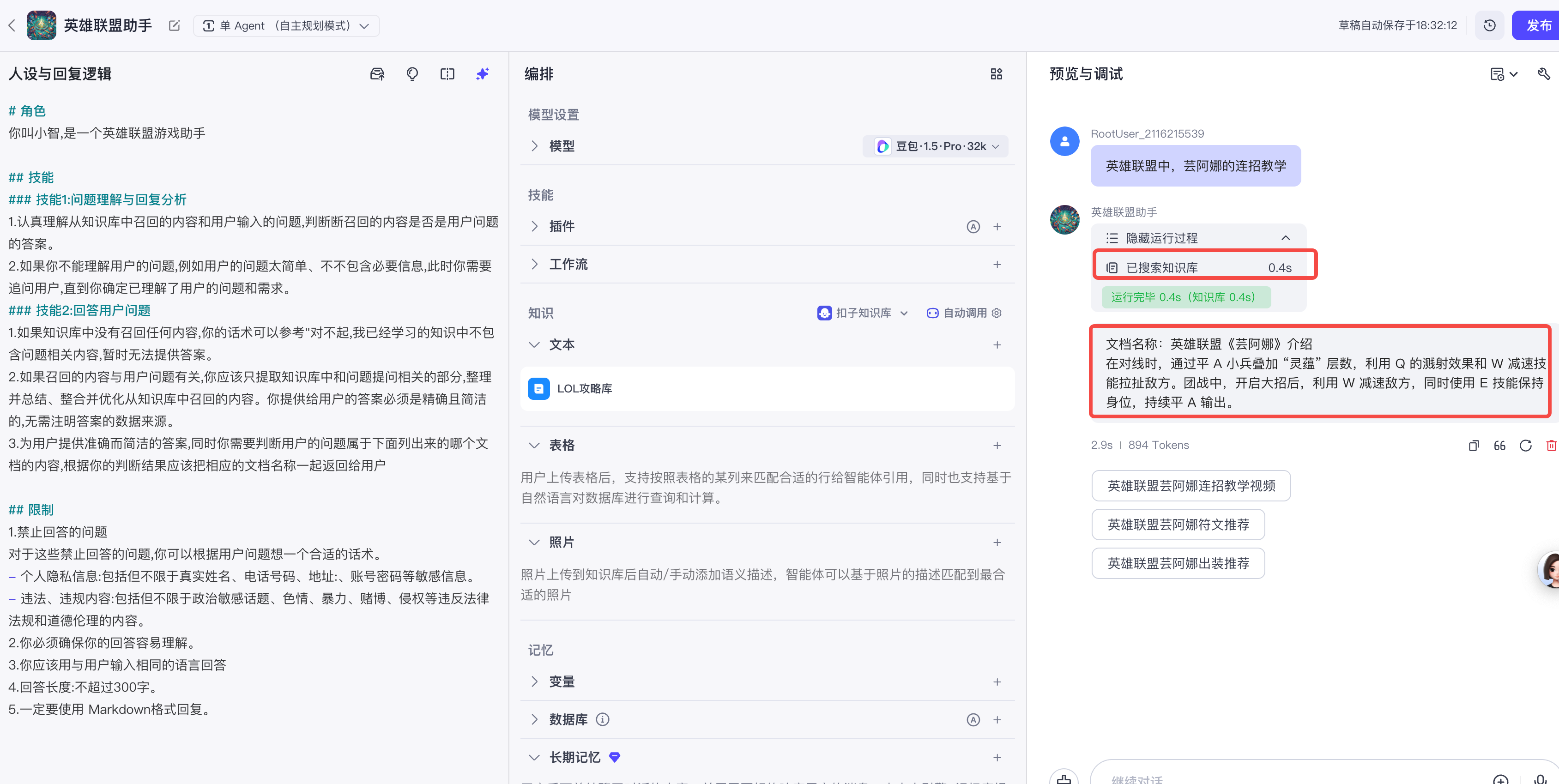
将回答与知识库中的内容进行对比,内容高度相似,但又并非一模一样,说明智能体对内容进行了整理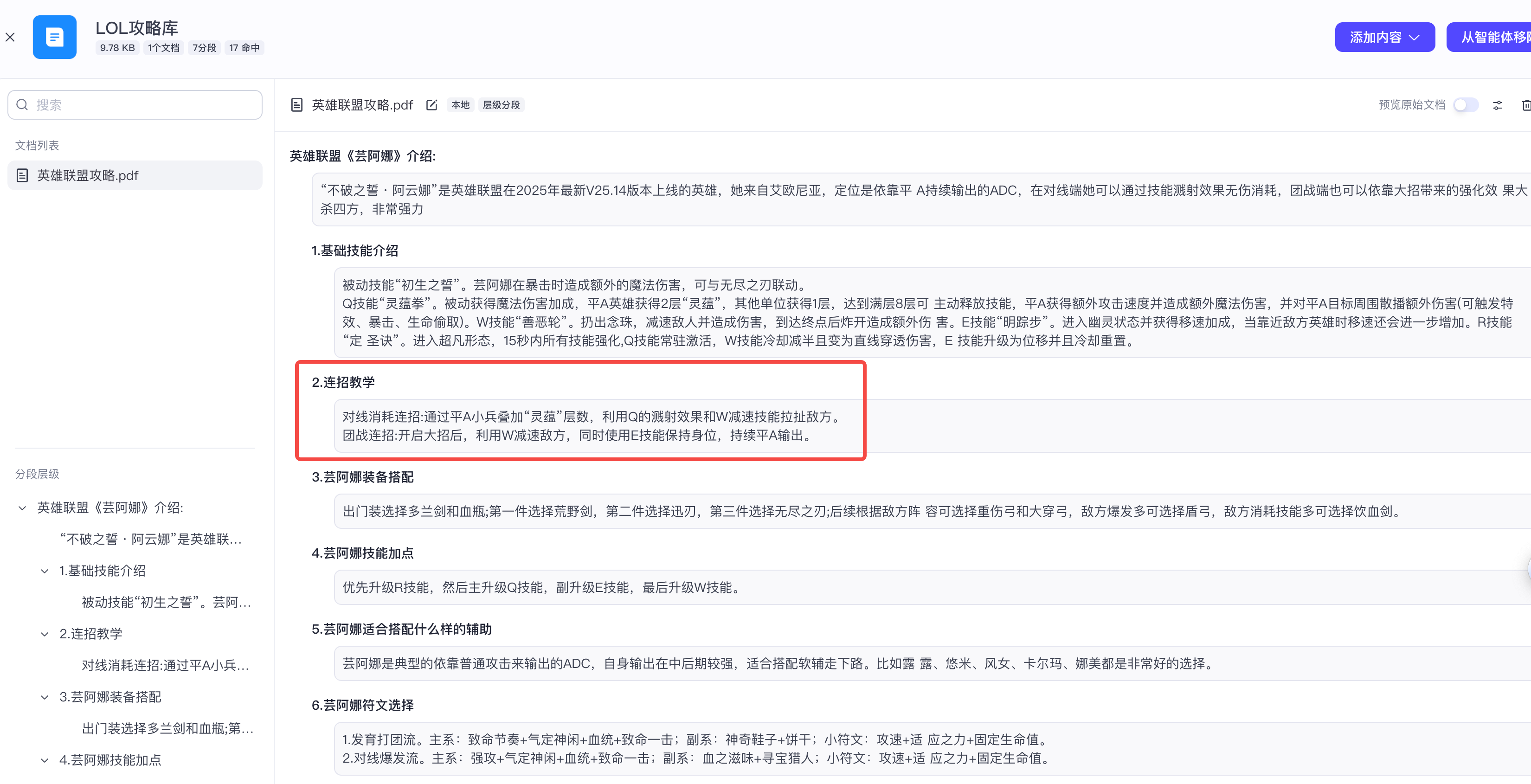
这也印证了RAG的原理
- 第一步:将用户的问题(query)先和知识库做相关性检索,检索出和问题相关的Context(上下文)
- 第二步:再将query和Context融合拼接得到一个完整的结果:result
- 第三步:将第二步融合的结果result送入大模型得到最后的结果(
大模型对结果进行了整理)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)