别再为多集群运维抓耳挠腮了:手把手教你用 Kurator 玩转舰队管理、云边协同与 GitOps 实战全流程
别再为多集群运维抓耳挠腮了:手把手教你用 Kurator 玩转舰队管理、云边协同与 GitOps 实战全流程
说起云原生,大家脑子里蹦出来的第一个词肯定是 Kubernetes。但干过运维或者架构的朋友都知道,现在的业务环境哪是一个 K8s 集群能搞定的?动不动就是多云、多集群,甚至还得把手伸到边缘端的服务器上。这就像管孩子,管一个叫省心,管一堆那就叫“炸锅”。Kurator 这玩意儿应运而生,其实就是为了给咱们这些被多集群折磨得不轻的人提供一个“指挥中心”。它不是简单的拼凑,而是把分布式云原生那一套零散的工具,像乐高一样拼好,让你开箱即用。咱们今天不聊那些高大上的PPT架构,就实打实地看看这玩意儿在手里怎么舞起来。
第一步:先把地基打好,环境搭建没那么玄乎
要玩转 Kurator,第一件事肯定是得把环境跑起来。很多人一听“搭建环境”就头大,其实只要你手头有个能联网的 Linux 环境,剩下的就是照葫芦画瓢。咱们不整那些复杂的自动化脚本,先用最原始、最踏实的方式把源码搞下来,这样你以后想改点啥逻辑,心里也有底。
1. 源码拉取与基础依赖
咱们先去 GitCode 把 Kurator 的源码整回来。这一步是所有实操的起点,别看只是个 git clone,这可是跟开发者距离最近的一步。
当然,感兴趣的同学,可以将项目下载下来体验一下:
然后我们找到Kurator的https地址,通过git将其拉取到本地: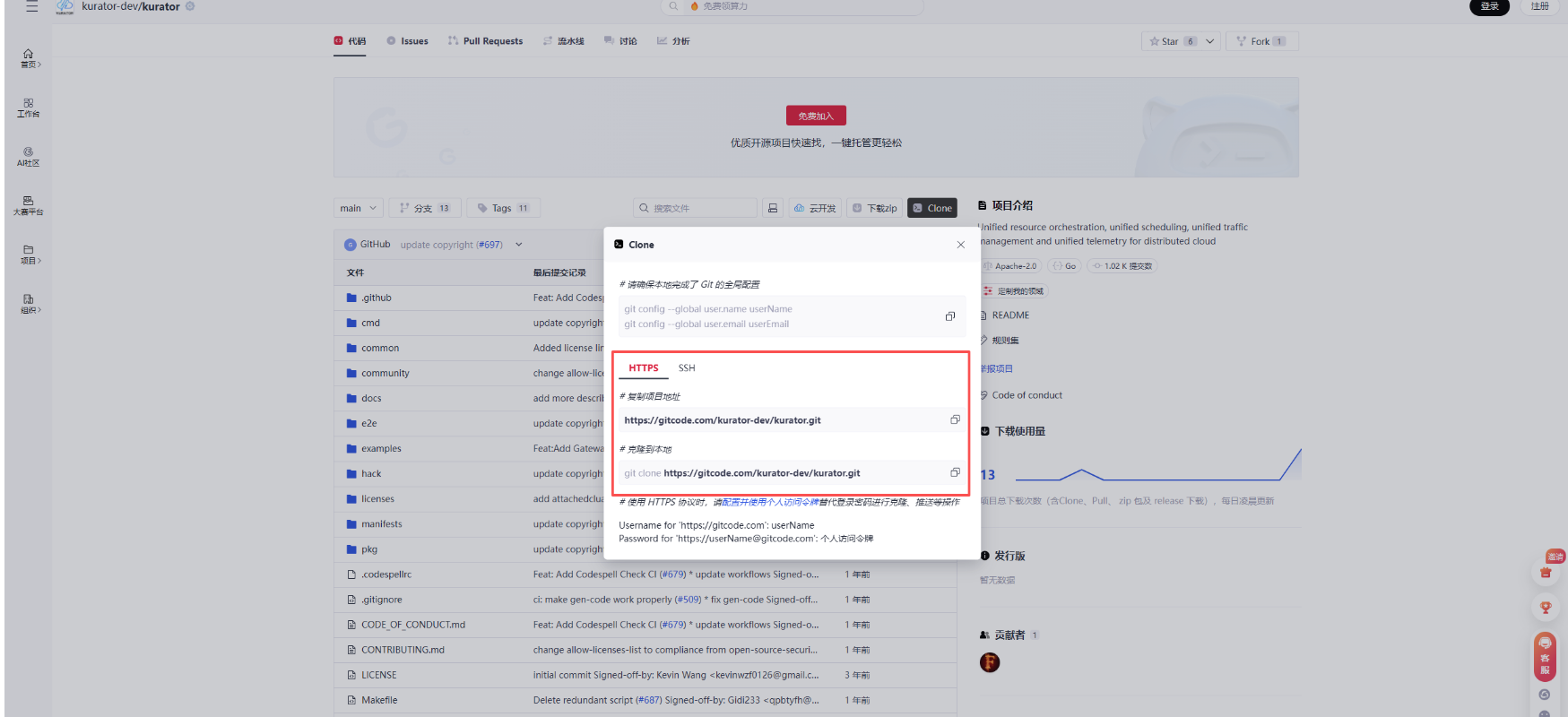
分别执行下面两条命令:
# 复制项目地址
https://gitcode.com/kurator-dev/kurator.git
# 克隆到本地
git clone https://gitcode.com/kurator-dev/kurator.git
实际克隆项目演示效果可以看到如下图: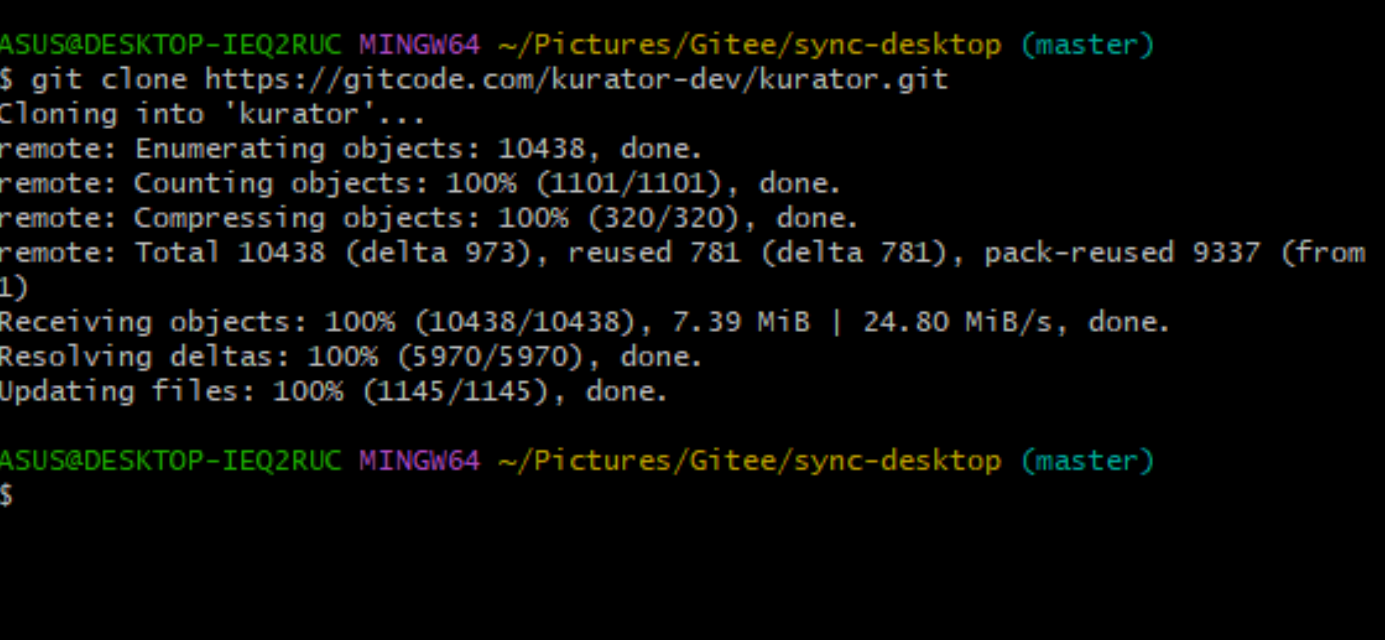
如下展示的便是完整的项目源码啦:
下载完成后,我们便可以进行项目部署及实战演练了。
拉下来之后,你会看到一堆目录。先别急着乱翻,Kurator 的核心逻辑都在 pkg 里面。咱们环境搭建的重点是把它的控制器跑起来,通常我们会建议你先有一个现成的 K8s 集群作为主控集群(Host Cluster),因为 Kurator 本身就是跑在 K8s 之上的。
2. 准备你的“指挥部”
在主控集群里,你需要安装一些基础的 CRD(自定义资源定义)。Kurator 聪明的地方在于它把集群、应用、策略都抽象成了资源。你只需要在主控集群里执行一下 make install 或者是直接应用 artifacts 里的 YAML 文件。如果你是在开发环境下,想快速看效果,可以直接本地 go run。但实战中,我们一般会把它打包成镜像,通过 Helm 挂载进去。这一步搞定,你的“指挥部”就算初步成立了,接下来就是让它去指挥别的“小弟”了。
第二步:舰队管理中的“身份”与“一致性”艺术
在 Kurator 的世界观里,多集群不叫多集群,叫“Fleet”(舰队)。既然是舰队,就得有纪律。最常遇到的两个头疼问题:一是不同集群里的同名命名空间到底算不算一个东西?二是舰队里的应用想访问集群外的数据库或对象存储,身份怎么对上?
1. 舰队中命名空间相同性的深意
这是Fleet舰队中命名空间相同性的示意图,展示了多集群间命名空间的对齐逻辑与统一编排映射关系: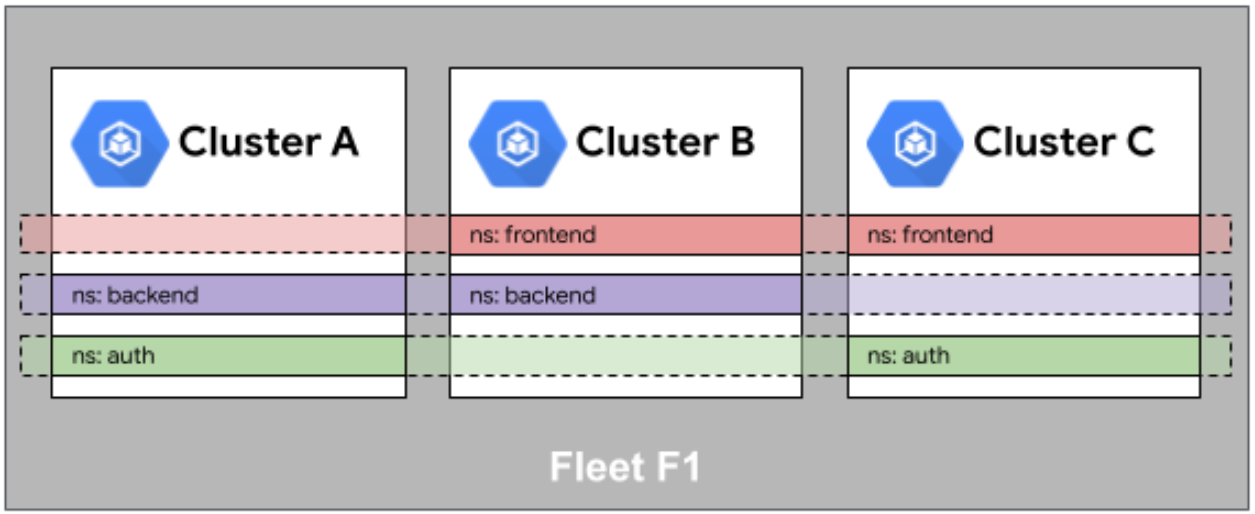
咱们在单集群里,Namespace 是隔离墙。但在多集群环境下,Kurator 引入了一个很重要的概念:命名空间相同性(Namespace Sameness)。简单说,如果你在集群 A 有个 order 空间,在集群 B 也有个 order 空间,Kurator 默认会认为它们属于同一个逻辑业务单元。
这有什么好处?当你下发一个全局策略时,你不需要一个个集群去点名,直接说“给所有舰队里的 order 空间装上这个插件”,它就自动同步了。这种设计能极大减少我们的配置量,但也要求咱们在规划集群时,Namespace 的命名不能太随意,得有一套规范。
2. Fleet 访问队列外部资源的身份映射
这是Fleet访问队列外部资源的身份映射示意图,展示了跨集群服务与云平台服务账户的统一身份关联机制: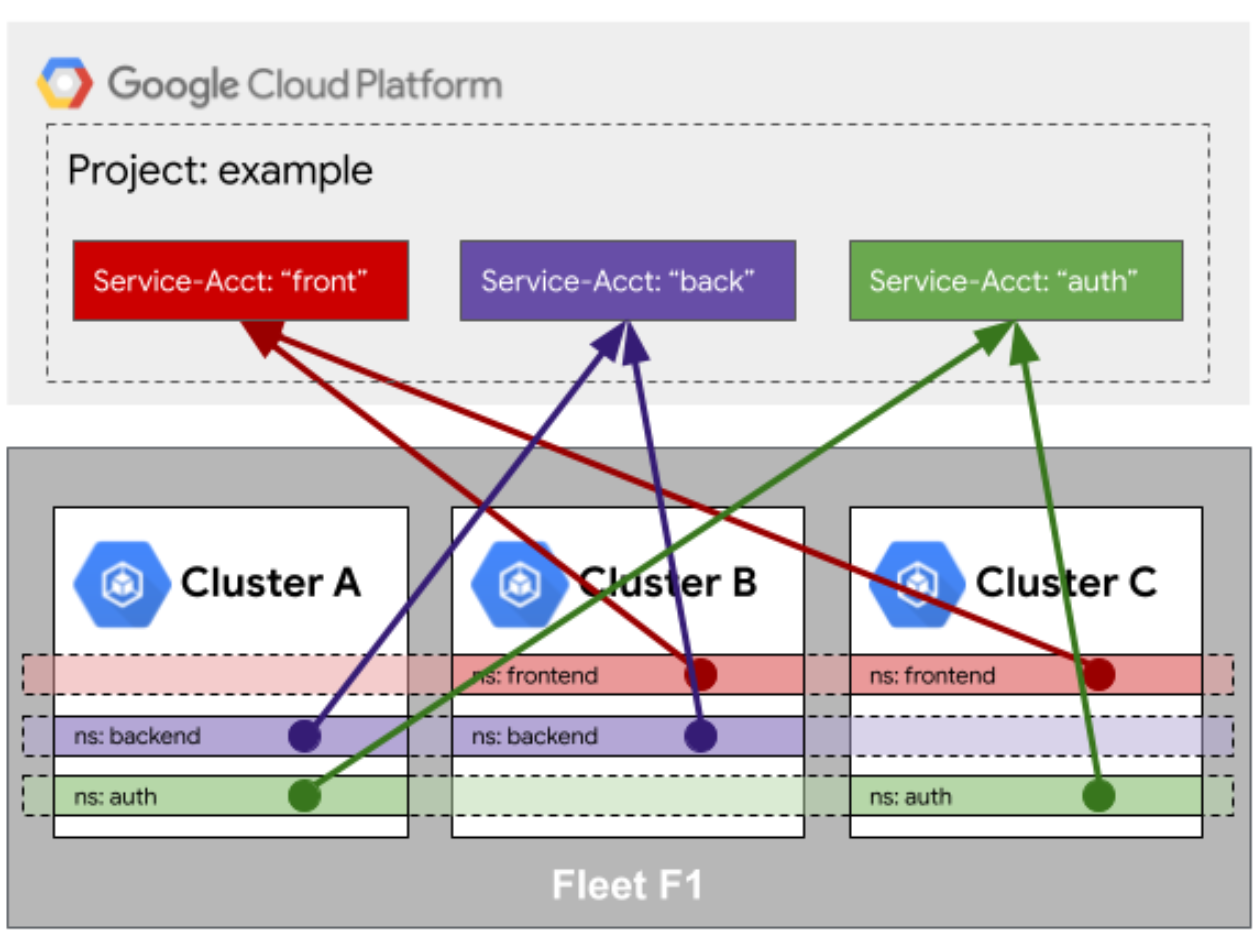
这是个实战中的高阶坑。假设你的应用跑在 Fleet 的多个集群里,但由于安全合规要求,它们得访问集群外的阿里云 OSS 或者 AWS S3。你总不能把 AccessKey 这种敏感信息在每个集群里都存一份吧?
Kurator 提供的身份映射机制,其实就是做了一层“翻译”。它利用 Fleet 的身份中心,把集群内的 ServiceAccount 和外部云服务的 IAM 角色挂钩。当应用发起请求时,它拿的是集群给的令牌,但到了云服务那边,被识别成了合法的云身份。这种映射关系是在 Fleet 层面统一配置的,哪怕你新加了一个集群进舰队,只要映射规则在,新集群里的应用立马就能合法访问外部资源,省去了反复配 Secret 的麻烦。
第三步:GitOps 这种省心的活儿,到底怎么落地?
很多人吹 GitOps,说它是“运维终点”。在 Kurator 里,GitOps 不是口号,是实实在在的同步逻辑。说白了,就是你把 YAML 往 Git 一推,剩下的活儿 Kurator 帮你干。
1. GitOps 的实现方式与心法
这是GitOps实现方式的官方参考图,展示了从代码变更到多环境(开发、预生产、生产)自动同步与部署的完整流程: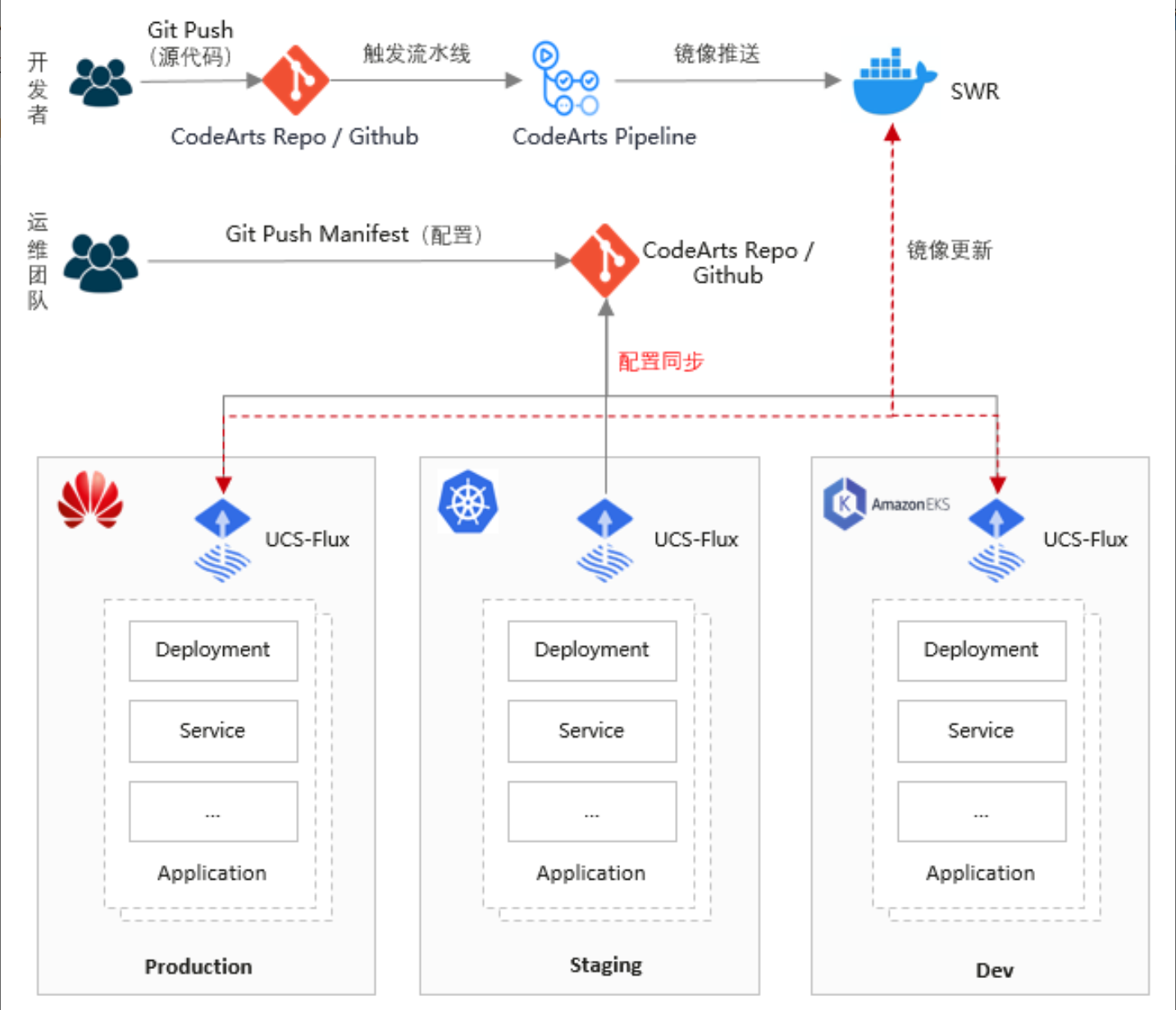
Kurator 底层集成了 FluxCD,这算是目前 GitOps 界的顶流了。它的实现方式核心就两个字:拉取(Pull)。
传统的 CI/CD 是“推”,脚本里写着 kubectl apply。而 Kurator 是让集群自己盯着 Git 仓库看:“哎,代码变了,我得把现在的状态改成跟 Git 里写的一样。”这种方式天然解决了“配置漂移”的问题。就算哪个调皮的运维在终端偷偷改了配置,FluxCD 也会在下次扫描时把它纠正回来。在 Kurator 里,你只需要定义一个 GitRepository 资源和一个 Kustomization 资源,剩下的就是喝茶时间。
2. FluxCD Helm 应用在多集群环境下的工作流程
这是FluxCD Helm应用在多集群环境下的工作流程示意图,展示了控制器如何基于Helm模板与差异化配置,实现跨集群应用的统一编排与同步: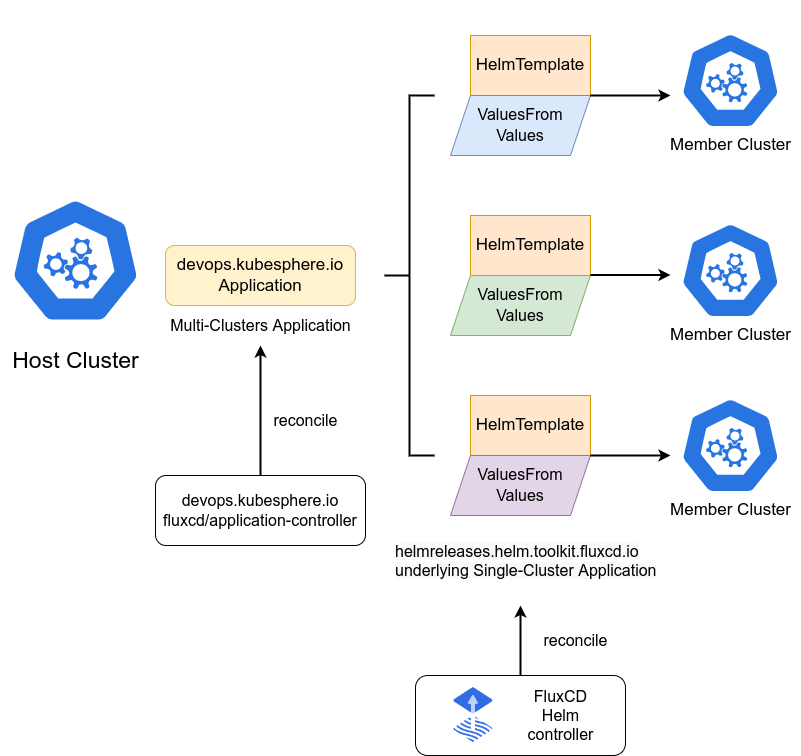
如果你用 Helm 打包应用,那在多集群下就更爽了。Kurator 配合 FluxCD 的 Helm Controller,可以实现一套代码、多处开花。
工作流通常是这样的:首先,你在 Git 仓库里维护 Helm Chart 和每个集群特有的 values.yaml。然后,Kurator 的 Fleet 插件会感知到新集群的加入,并自动把 FluxCD 的相关组件分发过去。接着,主控集群里的 Flux 会监听仓库,一旦发现版本更新,它会指挥各个子集群的 Helm Controller 去拉取最新的 Chart 并进行部署。最妙的是,你可以设置“分批发布”,让集群 A 先更,没问题了再给集群 B 更。
# 这是一个典型的针对多集群设计的 HelmRelease 简化版
apiVersion: helm.toolkit.fluxcd.io/v2beta1
kind: HelmRelease
metadata:
name: my-cool-app
namespace: kurator-system
spec:
interval: 5m
chart:
spec:
chart: ./charts/my-app
sourceRef:
kind: GitRepository
name: fleet-manifests
# 这里通过 targetNamespace 配合 Fleet 的 Sameness 逻辑
install:
targetNamespace: prod-business
values:
replicaCount: 3
# 这里的参数可以根据集群标签自动覆盖
region: ${CLUSTER_REGION}
第四步:流量路由与金丝雀:像指挥交通一样管理流量
应用部署上去了,只是完成了第一步。怎么让流量听话?怎么在不影响用户的情况下偷偷发个新版本?这就涉及到了 Kurator 的流量管理能力。
1. Kurator 的流量路由逻辑
Kurator 并不是自己写了一套 Service Mesh,而是整合了像 Istio 这样的成熟方案。它把流量路由的配置给“多集群化”了。
在单集群里,你配个 VirtualService 就行了;在 Kurator 里,你可以定义跨集群的流量路由规则。比如,当集群 A 的服务压力太大时,流量能自动“溢出”到集群 B。这种路由是透明的,业务代码根本感觉不到。它通过在各个集群部署 Envoy 边车,并统一由 Kurator 维护的控制平面下发指令,实现了真正的全局流量调控。
2. 通过 Kurator 配置金丝雀发布
金丝雀发布(Canary)是咱们搞稳定性的人的命根子。在 Kurator 里,你可以非常优雅地配置它。
流程一般是:你推了个 V2 版本的镜像,Kurator 会在目标集群里起一个小规模的 V2 副本集。然后通过流量权重,比如先给 V2 分 5% 的流量。这时候你需要盯着监控看,报错率涨没涨?耗时变久了吗?如果一切正常,再手动或自动把权重调到 20%、50%,直到全量。这种控制是在 Fleet 维度统一管理的,你可以要求全舰队所有集群同步开始金丝雀,也可以逐个击破。
这是通过Kurator配置金丝雀发布的YAML示例,展示了如何基于Istio进行流量路由、指标监控及渐进式权重调整的完整策略定义: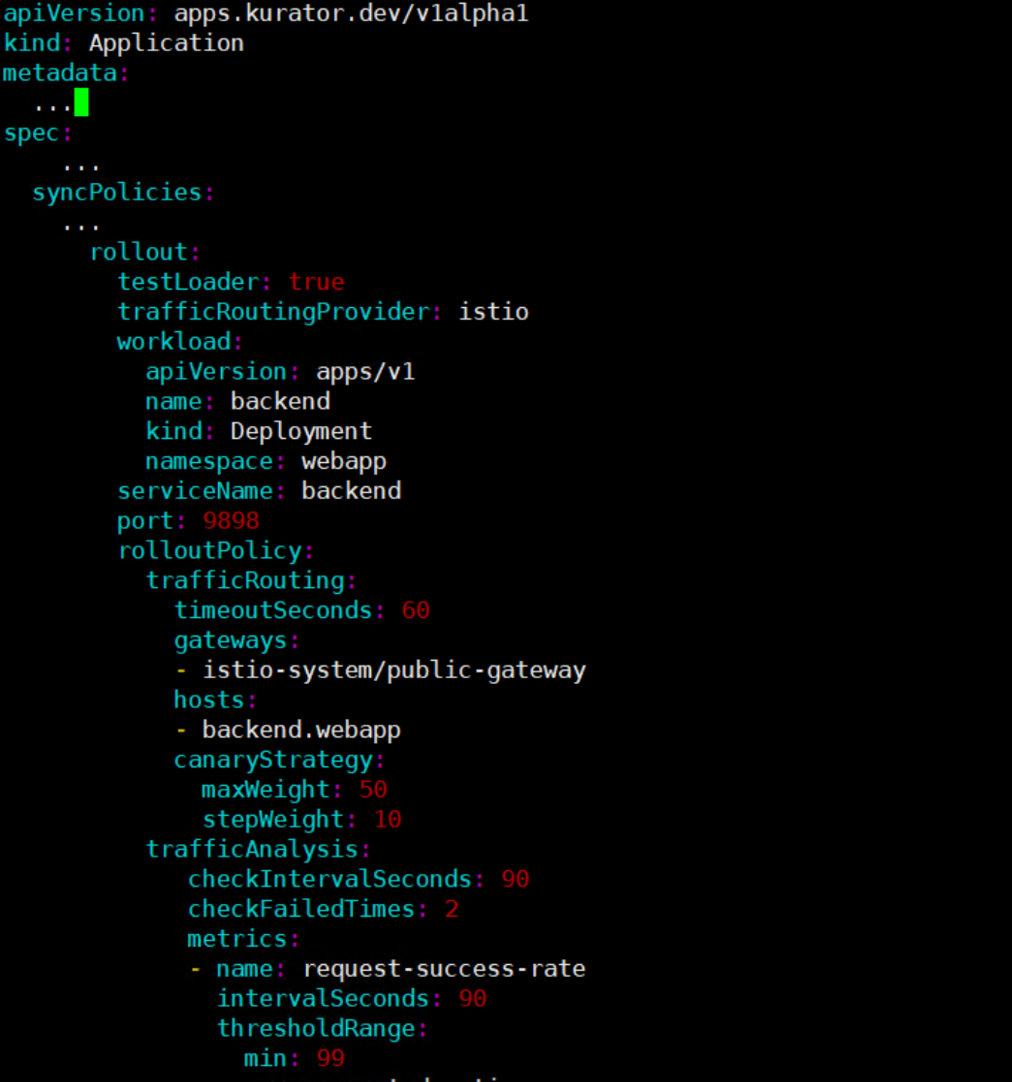
3. 顺手搭个 CI/CD 流水线
这是GitOps流水线的操作流程图,展示了从代码变更、镜像构建到配置更新与生产环境自动部署的完整工作流。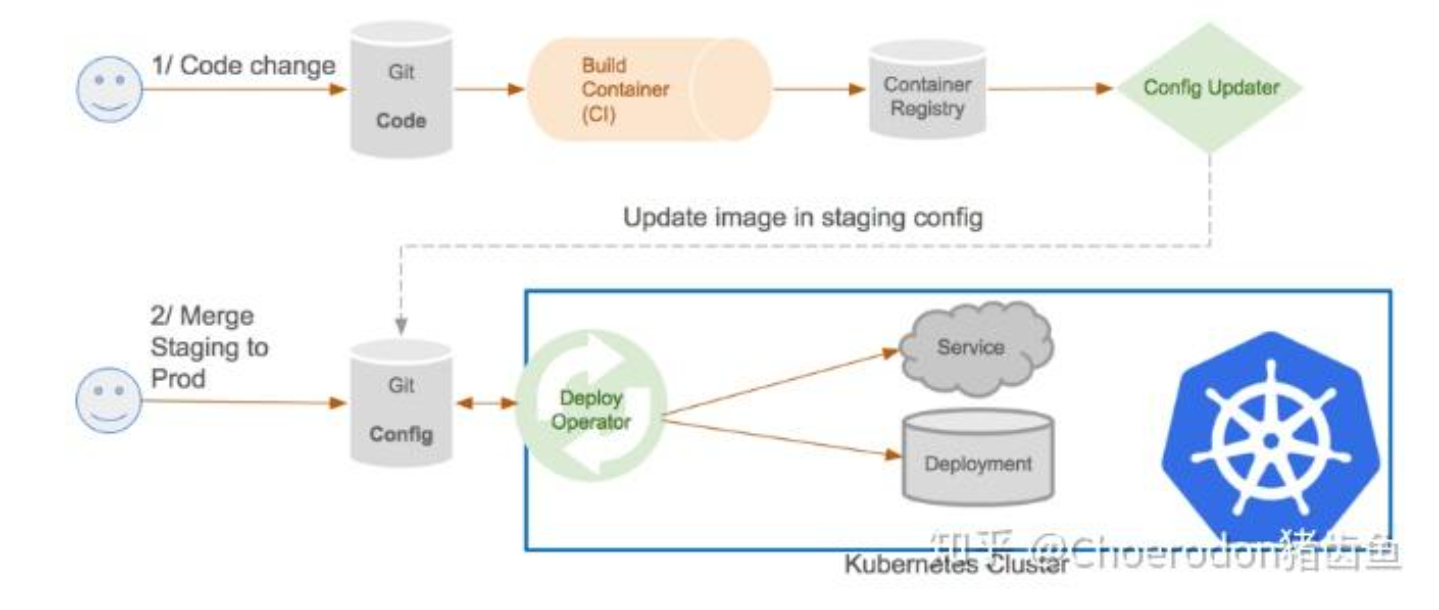
既然有了 GitOps 和流量控制,搭个流水线就是顺水推舟的事。
Kurator 里的 CI/CD 往往是解耦的。CI 部分(构建镜像、跑测试)你可以用原生的 Tekton 或者 Jenkins;而 CD 部分则完全交给 Kurator。你可以定义一个简单的流水线资源,第一步触发镜像构建,镜像完成后修改 Git 仓库里的版本号。这一改,就触发了前面说的 GitOps 流程,流量路由规则随之生效,开始金丝雀发布。整个过程一气呵成,人只需要在最后点个“确认全量”的按钮就行。
第五步:云边协同:把手伸向世界的角落
现在的业务场景,很多时候数据是在边缘产生的,比如摄像头、传感器。如果全传回云端,带宽受不了,延迟也受不了。这时候 KubeEdge 和 Kurator 的组合就派上用场了。
1. KubeEdge 核心组件与隧道机制
这是KubeEdge云边协同架构的核心组件图,展示了云端控制平面、消息通道与边缘节点的全链路组件及交互方式: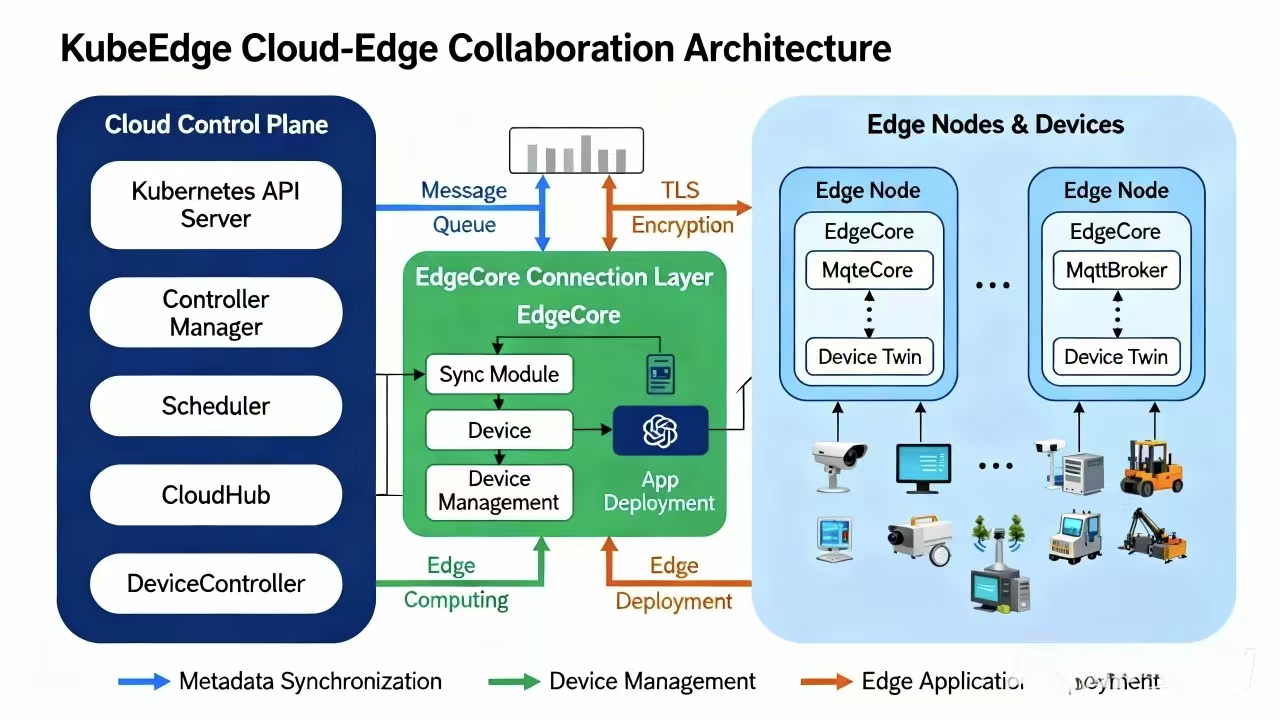
KubeEdge 是让 K8s 跑在边缘的利器,它有两个核心:CloudCore(云端)和 EdgeCore(边缘端)。
这里有个大难题:边缘端的机器通常在内网,没有公网 IP,云端怎么主动找它?这就得靠隧道机制(Tunnel)。CloudCore 和 EdgeCore 之间会建立一个基于 WebSocket 或 QUIC 的双向安全隧道。不管是下发指令,还是拉取边缘的状态,都走这条隧道。Kurator 在安装 KubeEdge 时,会自动帮你把这些证书管理、隧道配置都搞定,省得你对着一堆配置参数抓狂。
2. 现实中的云边协同计算场景
想象一个智慧工厂。边缘端的服务器负责实时的 AI 视觉检测,发现次品直接控制机械臂剔除。而这些检测的数据摘要,需要传回云端做大数据的趋势分析。
这就是典型的云边协同。在 Kurator 里,你可以像管理云端节点一样管理这些边缘节点。你甚至可以把一个 Volcano 的 Job 调度到边缘执行,因为它可能离数据源最近。计算在边缘跑,策略在云端定,这种体验才是真正的分布式云原生。
3. 网络连通性排查:老司机的避坑指南
云边协作最怕网络断。排查时有三板斧:
- 查隧道状态:先看 CloudCore 和 EdgeCore 的隧道断没断。在 Kurator 仪表盘里看节点状态是不是 Ready。
- 看日志排坑:如果节点在线但任务下不去,去看
edgecore.log。很多时候是边缘端由于断网时间太长,导致本地缓存的元数据和云端对不上了。 - 测网络时延:隧道通不代表应用通。检查一下边缘端的 iptables 规则,KubeEdge 会改动一些规则来实现内网穿透,有时候跟本地的安全策略冲突了,得手动调优一下。
# 实战中常用的排查小技巧:在边缘节点看隧道连接
ss -antp | grep 10000 # 假设 10000 是 CloudCore 的监听端口
# 查看 edgecore 的健康状态
curl http://127.0.0.1:10350/healthz
第六步:算力调度哪家强?Volcano 帮你搞定复杂任务
在多集群里,不是所有任务都是简单的 Web 服务。遇到这种大批量的 AI 训练或者大数据分析,原生的 K8s 调度就有点力不从心了。这时候,Kurator 集成的 Volcano 就该登场了。
1. Job、Queue 与 PodGroup 的三角关系
这是Volcano中Job、Queue与PodGroup关系的参考图,直观展示了任务队列如何管理多个PodGroup及其Pod的调度分组: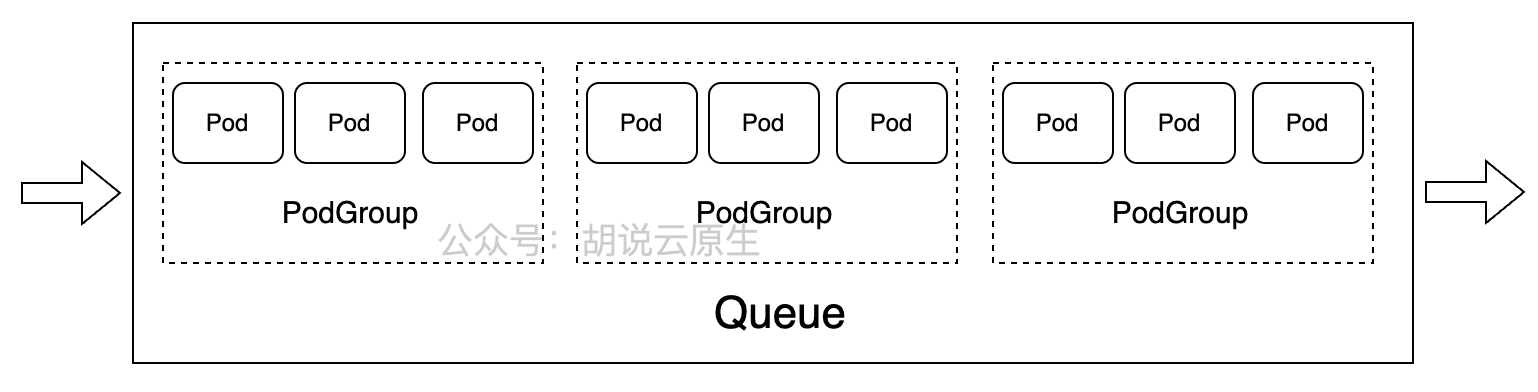
Volcano 的调度逻辑比原生 K8s 细腻得多,核心就在这三个概念:
- Job:这是你要干的活儿,比如一个训练任务。
- Queue(队列):这是分钱分粮的地方。你可以给财务部一个队列,给研发部一个队列。队列决定了谁能先用资源,谁的优先级高。
- PodGroup:这是 Volcano 的灵魂。原生 K8s 调度 Pod 是一个一个来的,但 AI 任务往往需要 10 个 Pod 同时跑,少一个都跑不起来(这就是 Gang Scheduling)。PodGroup 把这组 Pod 捆绑在一起,要么全调度成功,要么一个都不占资源,避免了“占着茅坑不拉屎”的死锁情况。
2. 复杂场景下的资源调度实战
在 Kurator 的多集群环境中,Volcano 甚至可以感知到跨集群的资源余量。
比如你有一个超大的 Job,集群 A 剩 5 个坑,集群 B 剩 5 个坑。Kurator 配合 Volcano 可以实现这种跨集群的弹性调度。你只需要往 Queue 里一扔,它会自动帮你找最合适的空位。而且,利用 Volcano 的抢占机制,你可以保证核心业务的 Queue 在资源紧张时,能强行拿走非核心业务的资源,这在实战中是保证 SLA 的神技。
# 这是一个 Volcano Job 的实操配置示例
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: batch-train-job
spec:
minAvailable: 4 # 至少有4个Pod才启动,少一个都不开工
schedulerName: volcano
queue: research-team-queue # 扔进研发团队的队列
tasks:
- replicas: 4
name: worker
template:
spec:
containers:
- name: train-main
image: my-ai-model:v1.0
resources:
requests:
cpu: "2"
memory: "4Gi"
写到最后,咱们再回过头看。Kurator 并不是想发明一种新的 K8s,它是想把咱们在多集群、云边、GitOps、复杂调度中遇到的那些碎活、烂活给标准化了。你不需要成为每一个开源项目的专家,你只需要理解什么是“舰队”,什么是“同步”,然后把你的业务逻辑放进去。
实战中,建议大家先从那个 git clone 开始,哪怕只是在一个测试集群里跑通一个 GitOps 的同步,你也会发现,这种“声明式”的运维方式,真的比你手写脚本要靠谱得多。以后遇到多集群扩容,别再想着用脚本去循环执行命令了,试试 Kurator,你会发现运维原来也能这么优雅。有空咱们再聊聊怎么把 Kurator 里的监控指标接到大屏上,那又是另一段有意思的实操了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)