美团LongCat-Video解析
过去几年,AI 让我们见识了语言理解的奇迹。ChatGPT 能写文章、Midjourney 能画画,但让机器真正理解并预测世界,还需要更深一层的智能——那就是「世界模型」(World Model)。
过去几年,AI 让我们见识了语言理解的奇迹。ChatGPT 能写文章、Midjourney 能画画,但让机器真正理解并预测世界,还需要更深一层的智能——那就是「世界模型」(World Model)。
所谓世界模型,就是让 AI 不再停留在符号和数据的层面,而是能像人一样“看见”世界、理解物理规律、推演时空逻辑。要做到这点,最自然的路径就是让模型去生成视频。因为视频本身是最接近真实世界的序列化数据:它同时包含几何、语义、物理、运动乃至情绪。
于是,美团 LongCat 团队迈出了探索世界模型的第一步——推出 LongCat-Video,一个面向未来的视频生成基座模型。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:AIHub,欢迎关注收藏!

1.统一架构
LongCat-Video 基于 Diffusion Transformer(DiT) 架构,最大亮点在于它是一个多任务统一模型。
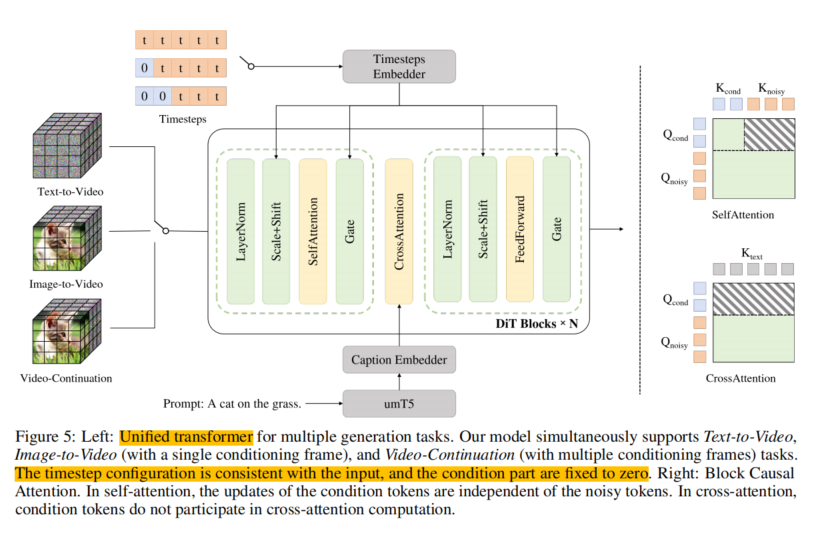
团队并没有为不同任务(文生视频、图生视频、视频续写)单独造轮子,而是通过「条件帧数量」这一创新机制区分任务:
- 无条件帧 → 文本生成视频(Text-to-Video)
- 1 帧条件 → 图像生成视频(Image-to-Video)
- 多帧条件 → 视频续写(Video Extension)

这种设计非常优雅,相当于让模型自己决定“要不要参考历史帧”,自然地形成了文生 / 图生 / 续写的任务闭环。
1.1文本生视频
在 T2V (Text-to-Video) 任务上,LongCat-Video 可生成 720p、30 fps 高清视频,能准确理解文本中描述的物体、人物、场景、风格等要素。
从结果来看,它在语义一致性与视觉质量上都达到开源 SOTA 级别。换句话说,你描述的“黄昏下的城市航拍镜头”,AI 真的能拍出那种氛围感。
1.2图像生视频:让静态画动起来
I2V 任务中,模型能严格保留参考图像的主体属性、背景关系与整体风格,同时让动态过程符合物理规律。
无论输入是一张角色立绘、一幅油画,还是一张人像照片,LongCat-Video 都能让它动得“自然”,而不是机械地摆动几帧。
在“内容一致性”和“动态平滑性”两项指标上,它的表现尤为突出。
1.3视频续写:分钟级长视频的关键
这也是 LongCat-Video 最具差异化的能力。
模型可以基于多帧条件,原生续接视频内容,实现跨帧时序一致与物理运动合理的长视频生成。
得益于 Block-Causal Attention 机制 与 GRPO 后训练策略,模型可稳定输出长达 5 分钟 的连贯视频,几乎无画质衰减。

常见的长视频问题——色彩漂移、动作断裂、画质崩坏——都被有效解决。
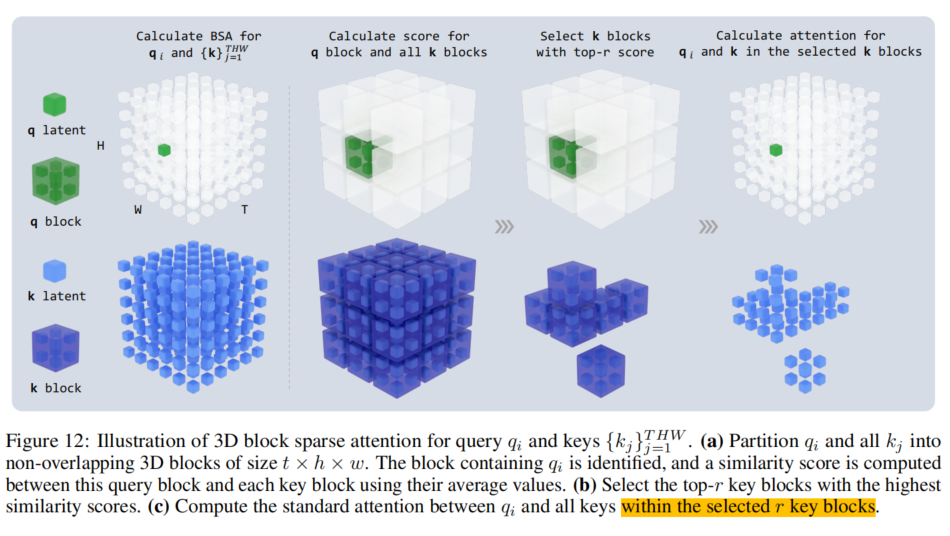
配合块稀疏注意力(BSA)与条件 token 缓存机制,LongCat-Video 在处理 90 帧以上序列时依然高效,真正打破了“时长与质量不可兼得”的行业瓶颈。
2.高效推理
长视频生成的计算量惊人,美团团队通过三重优化找到平衡:
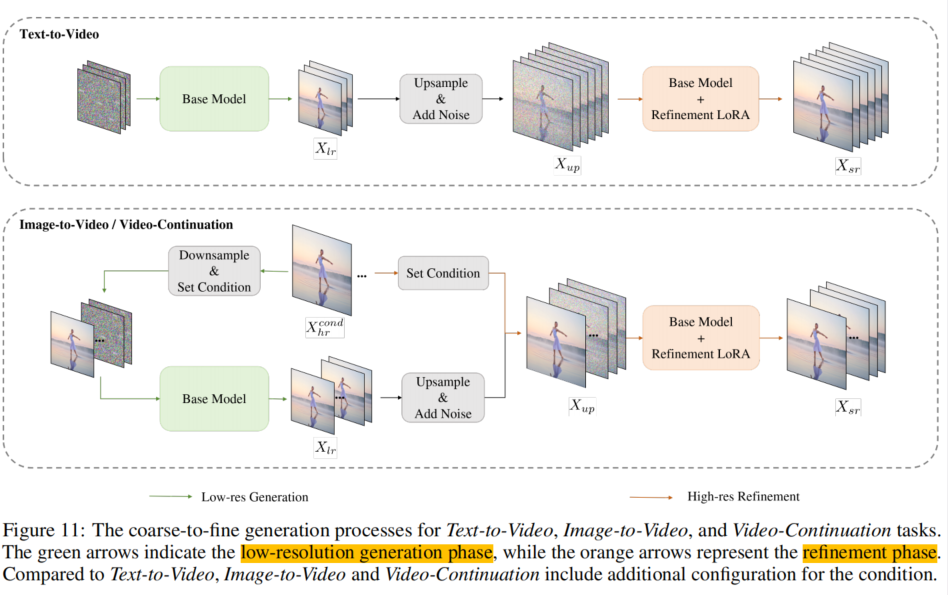
- 粗到精生成(C2F):先生成 480p 低帧率视频,再用 LoRA 模块超分到 720p 30 fps。
- 块稀疏注意力(BSA):只计算 top-r 关键块注意力,计算量降到 10% 以下。
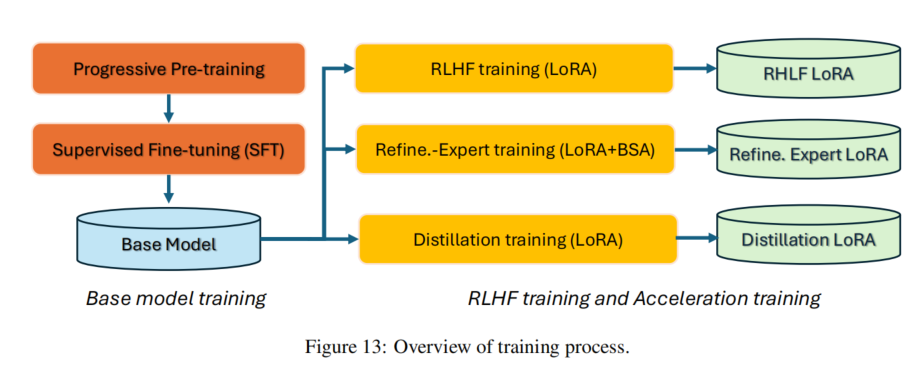
- 模型蒸馏(CFG + 一致性蒸馏):将采样步骤从 50 步压缩至 16 步。
最终实现 10 倍推理速度提升,同时保持 SOTA 画质——真正做到“又快又稳又清晰”。
3.评测结果
在 VBench 等公开基准中,LongCat-Video 以 136 亿参数的体量,在 Text-to-Video 与 Image-to-Video 两项核心任务上均达 SOTA 水平。
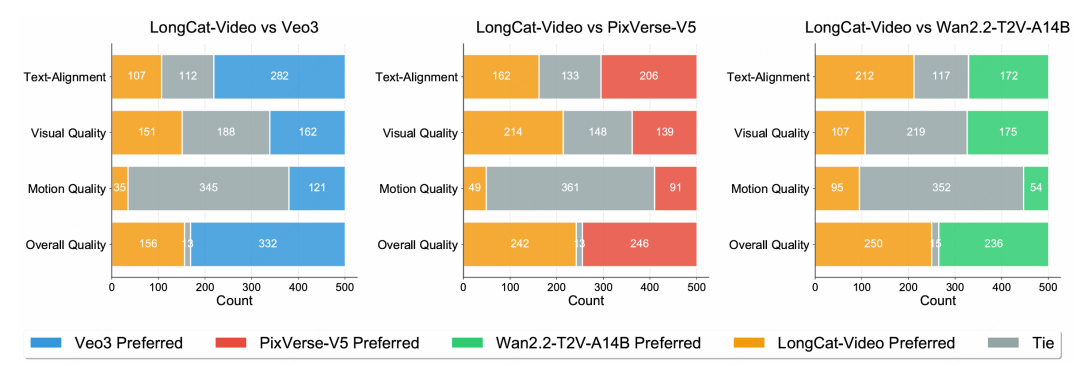
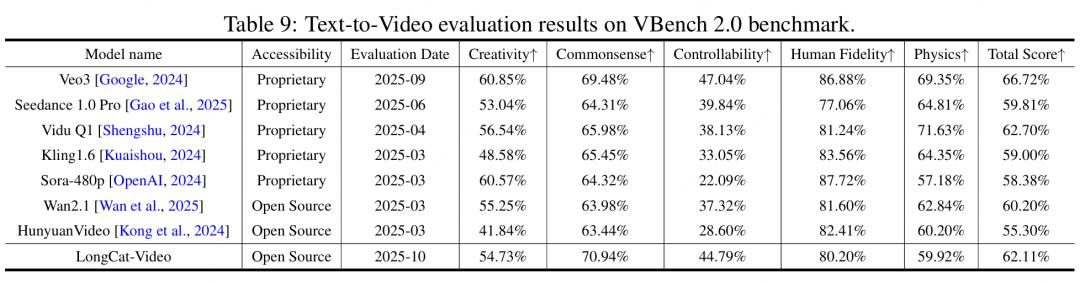
模型在文本对齐、视觉质量、运动连贯性、整体质量等维度全面领先,展示出世界模型方向上强大的潜力。
回到最初的问题——要让 AI 真正理解世界,我们得让它先“看懂”世界。
LongCat-Video 正是迈向这一目标的起点。它不只是一个视频生成器,更是一个能在数字空间中重构物理规律的世界模拟器。未来,这种模型将成为自动驾驶、具身智能、数字人等场景的基础。
而对我们这些学习 AI 和在AI行业的人来说,它也提醒着我们世界模型的尽头,不只是模型,而是对世界本身的理解。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号coting!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)