强化学习不只会打游戏:CPU 调频场景的落地思考与收获
本文从强化学习的三层核心结构(基础交互元素、动态运行元素、核心决策元素)切入,梳理其从游戏、棋牌博弈等经典场景到自动驾驶等工业场景的应用延伸。重点分享强化学习在 CPU 动态调频(DVFS)问题中的落地实践,阐述如何将该问题建模为序列决策任务,通过智能体与系统环境的交互实现性能与功耗的动态平衡,展现强化学习从 “娱乐验证” 到 “工业赋能” 的跨界价值。
提到强化学习,很多人第一时间想到的是 AlphaGo、围棋,以及各种“打游戏打赢人类”的传奇故事。
但如果把棋盘换成 CPU,把落子换成频率调节,把胜负换成性能与功耗的权衡,强化学习是否依然适用?
本文将从强化学习的基本结构出发,结合实际工程场景,介绍强化学习如何从游戏与棋牌领域,逐步走向系统级优化,并分享我在 CPU 动态调频问题中的一些实践与思考。
1. 引言
强化学习(Reinforcement Learning,RL)是机器学习的重要分支之一。通常来说,机器学习可以划分为三大类:
- 有监督学习:典型任务包括分类与回归
- 无监督学习:典型任务包括聚类、降维
- 强化学习:通过与环境交互进行决策学习
与前两类学习方式不同,强化学习并不依赖大量标注好的样本,而是通过 “试错 + 奖励反馈” 的方式,让智能体在与环境的不断交互中逐步学会最优决策策略。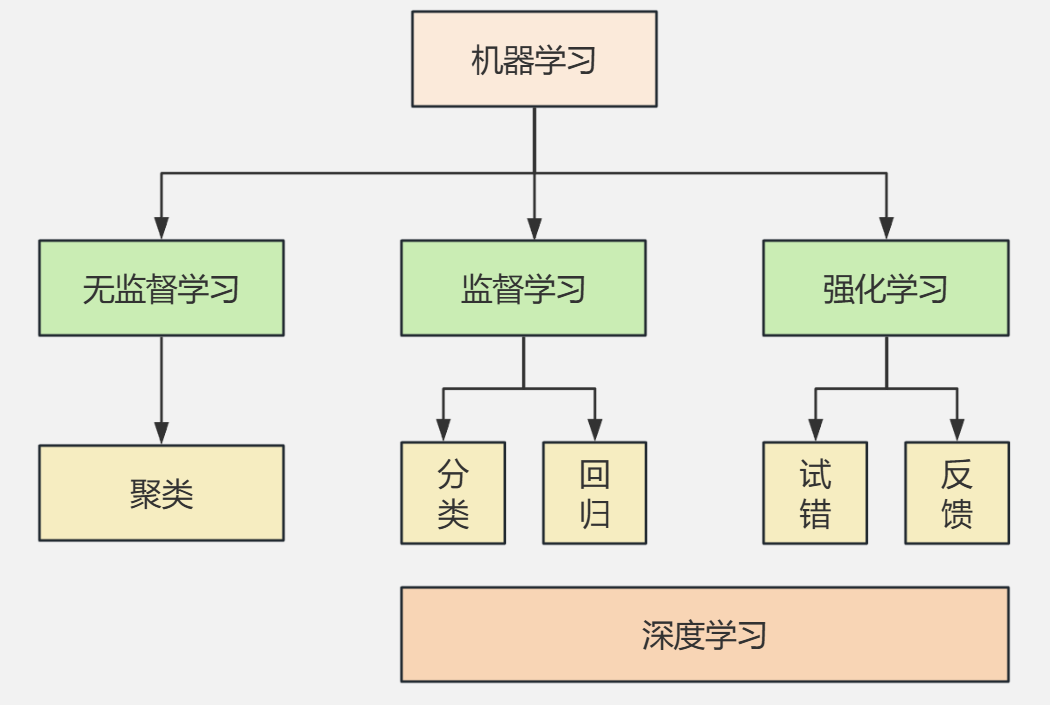
近年来,强化学习重新成为研究热点,其中一个重要原因是大语言模型(LLM)的成功。当前主流的大语言模型在预训练完成后,往往会引入基于人类反馈的强化学习(RLHF, Reinforcement Learning from Human Feedback),通过奖励模型来约束和优化模型输出,使其更加符合人类偏好。这也使得强化学习从传统的游戏和控制领域,进一步走向了通用人工智能的重要组成部分。
从本质上看,强化学习的过程可以被理解为一场持续进行的“游戏”:智能体不断观察环境、做出决策、获得反馈,并以最大化长期收益为目标优化自身行为。因此,强化学习最早、也是最成功的应用领域,正是棋牌博弈与复杂游戏系统。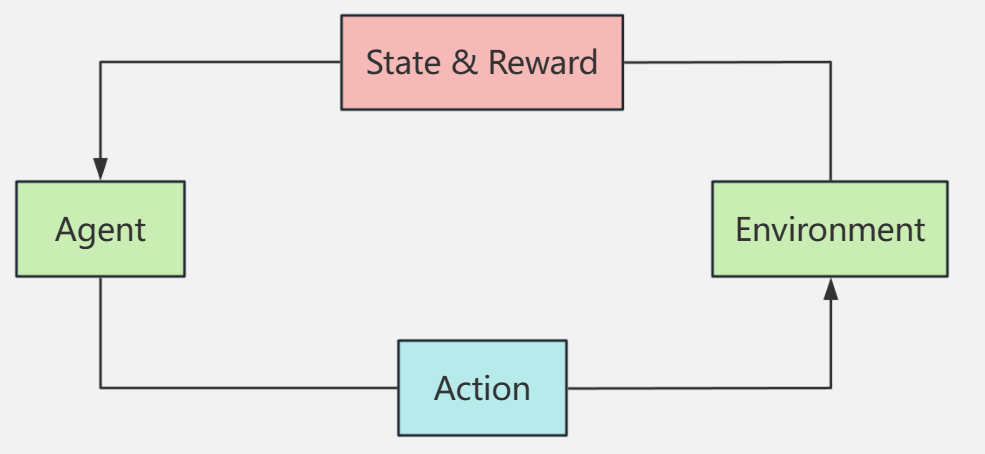
2. 强化学习的整体结构
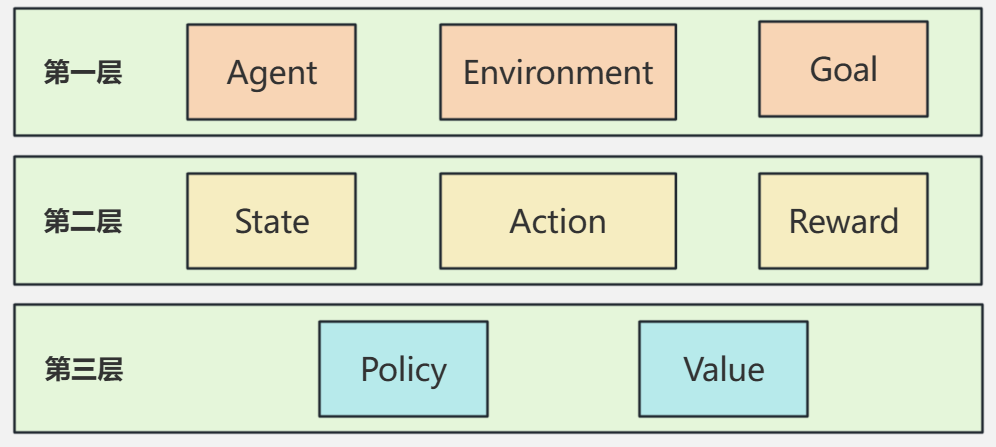
从整体上看,强化学习可以理解为一个由外到内、由交互到决策的三层结构。最外层定义了学习发生的基本框架,中间层描述了学习过程的动态运行机制,最内层则刻画了智能体进行决策与优化的核心数学对象。
1. 基本交互元素
这一层刻画的是强化学习的整体框架,主要包括三个核心要素:
- Agent(智能体)
- Environment(环境)
- Goal(目标)
强化学习本质上就是:
Agent 在与 Environment 的持续交互过程中,为了达成某个 Goal 而进行的学习过程。
Agent 是整个系统中的决策主体,负责观察环境、做出选择并执行行为;Environment 是 Agent 所处的外部世界,负责根据 Agent 的行为反馈新的状态和结果;而 Goal 则定义了“什么是期望的行为、什么是不期望的行为”。
需要强调的是,强化学习并不直接告诉 Agent 哪一步是“正确的”,而只是通过是否接近 Goal 来进行间接引导。也正因为如此,Goal 的设定方式会深刻影响学习结果,它最终会体现在奖励设计、策略优化方向以及收敛行为上。
2. 主要运行元素
如果说第一层回答的是“强化学习在做什么”,那么第二层关注的就是“强化学习是如何运转起来的”。在实际的强化学习过程中,真正驱动学习发生的是以下三个元素:
- State(状态)
- Action(动作)
- Reward(奖励)
整个强化学习过程,本质上就是 Agent 在不同 State 下选择 Action,并根据 Reward 不断调整自身行为的过程。
State 用于描述 Agent 与 Environment 当前所处的状态,其含义非常宽泛,可以理解为所有与当前决策相关的信息的集合。在不同任务中,State 的形式差异很大:
- 在围棋中,State 可以是棋盘上所有棋子的空间分布
- 在自动驾驶中,State 可能包括车速、周围车辆信息、道路结构以及交通信号
- 在系统调度或资源管理问题中,State 往往由 CPU 负载、温度、功耗、队列长度等系统指标共同构成
在某一个 State 下,Agent 需要选择并执行一个 Action。Action 表示 Agent 对环境施加的影响方式,其可以是离散的(例如选择一个频率档位),也可以是连续的(例如连续控制转向角度或油门大小)。Action 的执行会改变环境状态,从而进入下一个 State。
State 与 Action 的不断交替,构成了强化学习的基本时间演化过程,也通常被建模为一个马尔可夫决策过程(MDP)。在这个过程中,Agent 并不是只关心当前一步的结果,而是需要为长期效果负责。
Reward 则是环境在 Agent 执行动作之后给出的即时反馈,通常是一个实数。它用于衡量当前行为在多大程度上符合最终的 Goal。需要注意的是,Reward 往往只反映“短期得失”,而非最终成败,这也是强化学习难度所在。
因此,奖励函数的设计在强化学习中具有决定性作用。如果奖励过于短视,Agent 可能会陷入局部最优;如果奖励设计与目标存在偏差,Agent 甚至可能学会“投机取巧”的策略,从而偏离真实目标。
3. 核心决策元素
在更抽象、更核心的层面,强化学习的目标可以归结为学习如何在不同状态下做出最优决策。这一过程主要通过两个关键函数来完成:
- Policy(策略)
- Value(价值函数)
Policy 描述的是 Agent 的行为准则,即:
在某一个 State 下,Agent 应该采取什么 Action。
从数学角度看,Policy 是一个从 State 到 Action 的映射函数,在随机策略的情形下,它通常表现为一个概率分布。强化学习算法的最终产出,往往就是一个性能良好的策略,使得 Agent 在长期交互中能够获得尽可能高的累积奖励。
Value 函数则用于对“好坏”进行量化评估,它回答的是:某个状态,或者在某个状态下采取某个动作,从长期来看有多值得? 常见的 Value 函数主要包括两类:
- 状态价值函数,用于衡量处于某一 State 时的整体长期回报
- 状态-行为价值函数,用于评估在特定 State 下执行某一 Action 的长期收益
Value 的引入,使得强化学习不再是盲目试错,而是可以对未来进行预期和权衡。在大多数强化学习算法中,Agent 会利用 Value 的估计结果来改进 Policy:价值高的行为被强化,价值低的行为被逐步抑制。
从这个角度看,Policy 决定“做什么”,而 Value 评估“做得好不好”。二者相互配合,构成了强化学习中策略优化的核心机制,也为后续的 Q-learning、Policy Gradient、Actor-Critic 等算法奠定了统一的理论基础。
3. 强化学习的典型应用场景
强化学习之所以受到广泛关注,一个重要原因在于它非常擅长解决序列决策问题。这类问题通常具有状态空间大、决策具有长期影响、难以用显式规则完整描述等特点。在多个典型领域中,强化学习已经展现出远超传统方法的能力。
1. 游戏领域
游戏是强化学习最早取得突破、也是最成熟的应用领域之一。典型代表包括 Atari 游戏、实时策略游戏以及各类复杂模拟环境。
在游戏任务中,智能体通常需要在连续的时间步内不断做出决策,而每一次决策都会对后续状态产生影响。这种“当前行为影响未来结果”的特性,使游戏天然符合强化学习的建模方式。
以 Atari 游戏为例,智能体可以直接以原始像素作为输入状态,通过强化学习算法学习从视觉感知到动作决策的端到端映射关系。在没有任何人工特征设计和规则约束的情况下,Agent 依然能够通过奖励信号逐步掌握游戏策略,甚至达到或超过人类玩家水平。
此外,在复杂策略类游戏中,强化学习可以处理高维状态、延迟奖励以及不完全信息等问题,使其成为验证新算法和新模型的重要实验平台。
2. 棋牌博弈领域(以围棋为代表)
棋牌类问题,尤其是围棋,是强化学习发展史上最具里程碑意义的应用场景之一。
围棋之所以极具挑战性,主要体现在以下几个方面:
- 状态空间规模极其庞大,远超国际象棋
- 搜索深度深,单步收益难以评估
- 胜负结果往往在很后期才能显现,奖励高度延迟
传统基于规则和人工评估函数的方法,在围棋问题上长期难以取得突破。而强化学习通过策略学习与价值评估的结合,为这一问题提供了新的解决思路。
以 AlphaGo 和 AlphaZero 为代表的系统,将强化学习与深度神经网络、蒙特卡洛树搜索相结合,使得模型能够在自我对弈中不断进化策略。价值网络用于评估局面优劣,策略网络用于缩小搜索空间,二者协同工作,使系统在极其复杂的决策空间中依然能够做出高质量选择。
围棋的成功不仅证明了强化学习在复杂决策问题中的潜力,也推动了强化学习在理论和工程层面的快速发展。
3. 自动驾驶与智能控制
在自动驾驶和智能控制领域,强化学习被广泛应用于高层决策和控制策略的学习,例如:
- 行为决策与路径规划
- 车辆纵向与横向控制
- 多车辆或多智能体协同决策
这一类问题通常具有环境动态变化快、不确定性强、建模成本高等特点。传统方法往往依赖精确的物理模型和人工规则,而这些模型在真实复杂环境中很难做到全面和鲁棒。
强化学习的优势在于,它可以通过与环境的持续交互,在不显式建模全部系统动力学的情况下学习控制策略。智能体可以根据实时状态反馈,动态调整决策,从而在复杂交通场景中实现安全性、效率和舒适性的平衡。
此外,在多智能体自动驾驶场景中,强化学习能够自然地扩展到协同或博弈问题,使车辆在共享道路环境下学会让行、合流和避让等复杂行为。这也使强化学习成为未来智能交通系统中的重要技术基础之一。
4. 实践落地
以上场景的共性,是“序列决策+动态环境+多目标权衡”——这与CPU动态调频(Dynamic Voltage and Frequency Scaling, DVFS)问题高度契合。接下来,我将分享强化学习在DVFS中的落地实践。
1. 问题核心
CPU动态调频的核心目标可概括为:
在满足性能需求(如不掉帧、无卡顿、响应延迟达标)的前提下,尽可能降低系统功耗与芯片温度。
这一问题的复杂性,源于系统变量的高度耦合与负载的动态不确定性:
-
耦合性:CPU负载升高会推高功耗与温度,而温度过高又会限制频率调节空间(芯片会触发降频保护);
-
动态性:实际工作负载波动剧烈(如打开大型应用时负载骤升,闲置时负载骤降),难以提前建模。
2. 传统方法的痛点
传统DVFS策略多依赖人工设计的规则或阈值(如“负载>90%升频,<30%降频”),或基于经验的控制算法。这类方法的局限性很明显:
-
响应滞后:面对突发负载时,固定规则难以快速适配,可能导致短暂卡顿或功耗浪费;
-
策略僵化:无法适应不同应用场景(如办公场景与游戏场景的性能需求差异);
-
泛化性差:换用不同芯片、不同硬件平台时,需要重新设计规则与调参,成本极高。
3. 强化学习的建模思路
基于强化学习的三层结构,我们可以将DVFS问题直接建模为“Agent-Environment”交互系统,核心映射关系如下:
-
Agent:调频决策模块(负责输出频率调节指令);
-
Environment:CPU及其运行环境(包括应用负载、硬件散热系统等);
-
State:CPU利用率、实时功耗、芯片温度、历史负载序列、当前频率档位;
-
Action:离散频率档位选择(如1.2GHz、1.5GHz、1.8GHz、2.0GHz);
-
Reward:综合奖励函数(核心逻辑:满足性能需求时,功耗越低奖励越高;未满足性能需求时,给予负奖励;温度超标时,给予强负奖励)。
在这一模型中,强化学习的核心价值是“长期最优”——Agent不会为了短期低功耗牺牲性能,也不会为了短期性能过度消耗功耗,而是通过最大化长期累积奖励,学会在不同负载模式下的自适应调频策略。
4. 落地价值
将强化学习应用于DVFS,带来了三大核心改进:
-
自适应调节:根据实时负载、温度变化动态调整策略,避免“过度保守”(高频闲置)或“过度激进”(低频卡顿)的问题;
-
多目标平衡:自动权衡性能、功耗、温度三者关系,适配不同应用场景(如办公、游戏、影音);
-
低迁移成本:无需人工设计规则,通过重新训练即可适配不同芯片平台,显著降低工程落地成本。
从行业视角来看,这一实践的意义在于——它将强化学习从“游戏实验室”推向了“工业级系统优化”,为操作系统、芯片设计等领域提供了“数据驱动、自适应优化”的新范式。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)