面试官:KV Cache 了解吗?推理阶段 KV Cache 的复用原理?动态批处理如何提升吞吐?
这道题可以说是大模型推理面试的保留项目。很多人一听就说:“我知道啊,KV Cache 是缓存 Key/Value 的东西,用来加速推理。”但真要问到怎么复用、为什么能复用、系统怎么批处理,大多数人就卡壳了。今天我们就把这件事彻底讲清楚。
这道题可以说是大模型推理面试的保留项目。
很多人一听就说:“我知道啊,KV Cache 是缓存 Key/Value 的东西,用来加速推理。”但真要问到怎么复用、为什么能复用、系统怎么批处理,大多数人就卡壳了。
今天我们就把这件事彻底讲清楚。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:AIHub,欢迎关注收藏!
一、为什么推理阶段需要 KV Cache?
我们先从语言模型的推理机制说起。
大模型(如 Transformer Decoder-only 架构)在推理时,是**自回归(autoregressive)**生成的:
输入: "The cat sat"
模型生成: 第4个token "on"
然后把 ["The", "cat", "sat", "on"] 再输入,生成下一个token
这意味着每次生成一个新 token,模型都要重新算一遍所有之前的 Q、K、V。
显然,随着序列变长,这种“重复计算”非常浪费。
二、普通推理的计算瓶颈
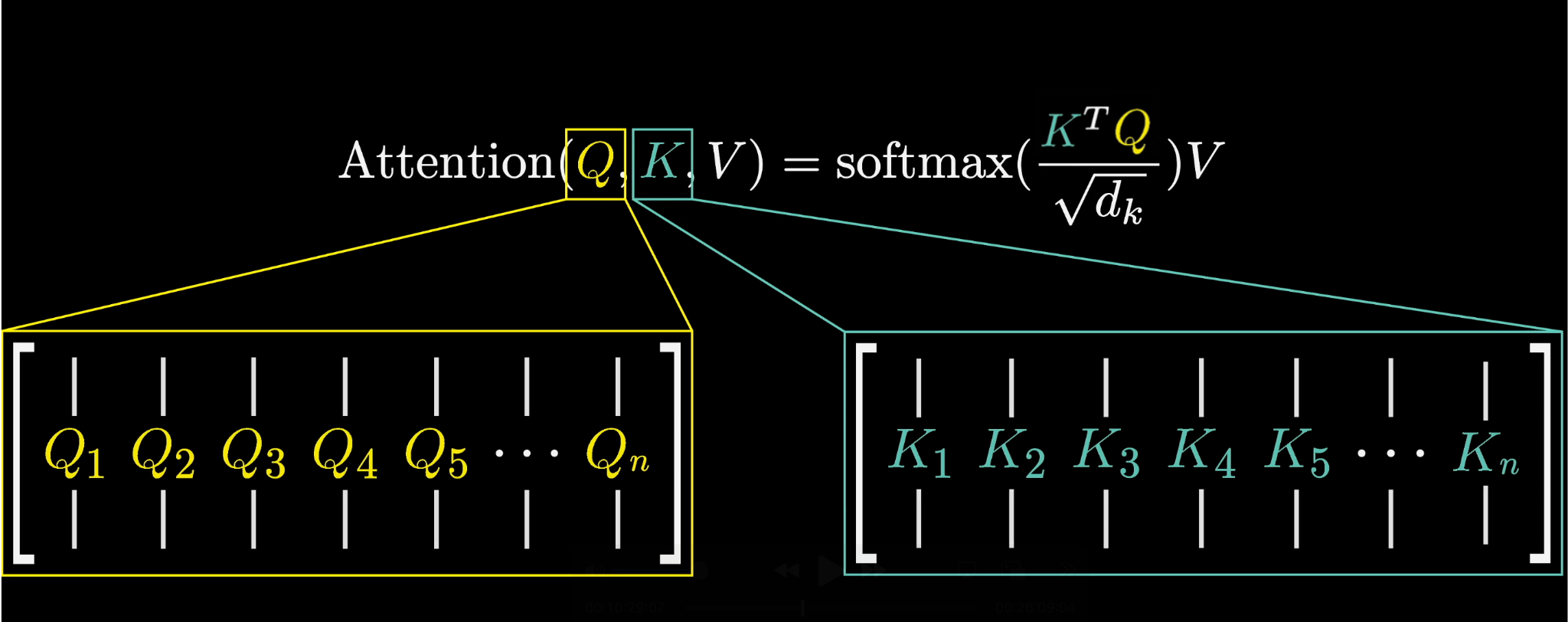
Transformer 的每一层都有 Self-Attention:
Attention(Q, K, V) = softmax(QKᵀ / √d) V
如果我们每次都重新计算:
- 第 1 步计算第 1 个 token;
- 第 2 步计算前 2 个;
- 第 3 步计算前 3 个;
那么第 N 步就要计算:1 + 2 + 3 + … + N = O(N²)
不仅算力爆炸,显存占用也线性上升。
这就是推理时最核心的性能瓶颈。
三、KV Cache 的核心思路
观察注意力公式:Attention(Q_t, K_1…t, V_1…t)
可以看到,生成第 t 个 token 时,只需要:
- 当前 step 的 Q;
- 以及前面所有 step 的 K 和 V。
而 K 和 V 在前面 token 计算时已经算过了!
所以我们完全可以:
- 把它们缓存下来;
- 下一次直接复用。
这就是所谓的 KV Cache(Key-Value Cache)。
| Step | 当前输入 | 计算内容 | 复用内容 |
|---|---|---|---|
| 1 | token₁ | Q₁,K₁,V₁ | — |
| 2 | token₂ | Q₂ | K₁,V₁ |
| 3 | token₃ | Q₃ | K₁,K₂,V₁,V₂ |
所以到了第 t 步,只需要计算新的 Qₜ,并复用之前缓存的所有 K/V。计算复杂度从 O(N²) 降为 O(N)。这就是为什么大模型的推理速度能提升几个数量级的根本原因。
四、KV Cache 的复用机制
在实现上,KV Cache 通常以 (num_layers, batch, num_heads, seq_len, head_dim) 的张量形式存在显存中。
以每一层的注意力为例:
# 每一层的缓存结构
key_cache[layer][batch] = [K₁, K₂, ..., Kₜ]
value_cache[layer][batch] = [V₁, V₂, ..., Vₜ]
每生成一个新 token:
- 当前输入 token 经过线性变换得到 Qₜ、Kₜ、Vₜ;
- 把 Kₜ, Vₜ append 到 cache,用所有缓存的 K,V 与当前 Qₜ 做一次 Attention:softmax(Qₜ (K₁…ₜ)ᵀ / √d) * (V₁…ₜ)
- 得到输出并继续生成下一个 token。
整个过程就像滚动窗口式的增量计算。
KV Cache可以大幅减少重复计算,时间复杂度从 O(N²) 降为 O(N),并且显存占用可控(仅缓存 K,V)。
但是KV Cache 需要常驻显存,序列越长,占用越大,所以推理阶段往往受限于 KV Cache 显存瓶颈。
这也是为什么在长上下文模型(如 128K context)中,我们还需要PagedKV 、PagedAttention等优化方案,让缓存按页分配、动态复用,防止显存碎片化。
五、Dynamic Batching
当你理解了单条请求的 KV Cache,接下来就要回答一个面试官最喜欢的追问:“那如果现在有多个用户请求呢?每个都在生成不同长度的 token,怎么高效并行?”
这就引出了 动态批处理(Dynamic Batching)。
静态批处理(Static Batching)
传统做法是:
- 固定 batch size;
- 对齐输入长度;
- 一次前向推理整个 batch。
问题是:
- 不同请求生成速度不同;
- 当一个生成完,其他还在跑;
- GPU 利用率下降。
动态批处理(Dynamic Batching)
Dynamic Batching 的核心思路是在推理过程中,动态地合并、拆分请求,最大化 GPU 吞吐。
具体来说:
- 不同请求的 token 生成可能不同步;
- 系统在每个时间步动态收集所有需要生成下一个 token 的请求;
- 将这些请求的当前 token 拼成一个新的 batch;
- 一次前向推理完成;
- 结果再拆分回各自请求。
整个过程在每一层之间动态变化,batch size 并不固定,但 GPU 始终高效运行。
假设同时有三个请求:
| 请求 | 当前状态 | 是否需要生成下一个token |
|---|---|---|
| A | 生成到第10个token | 是 |
| B | 生成到第8个token | 是 |
| C | 已完成生成 | 否 |
Dynamic Batching 会自动把 A 和 B 的当前 token 合并为一个 batch,一次推理得到两者的新输出。
当 B 完成时,A 还可以继续与新的请求 D 组成新的 batch,从而始终保持 GPU 在高负载状态。
传统推理中,GPU 经常因为小 batch 导致算子效率低。Dynamic Batching 通过动态组装输入,使每次前向都尽量大 batch,用系统调度层弥补请求异步带来的低效。
一句话总结一下,KV Cache 的本质是“缓存历史注意力”,Dynamic Batching 的本质是“动态组装请求”。
前者让模型少算,后者让 GPU 不闲。二者结合,就是大模型推理引擎能在O(N) 时间下实现高吞吐并发生成的关键。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号 coting!
📚推荐阅读
面试官:为什么 Adam 在部分任务上会比 SGD 收敛更快,但泛化性更差?如何改进?
面试官:BatchNorm、LayerNorm、GroupNorm、InstanceNorm 有什么本质区别?
面试官:深层网络梯度消失的根本原因是什么?除了 ResNet,还有哪些架构能有效缓解?
面试官:大模型中的幻觉本质原因是什么?如何通过训练或推理手段抑制?
面试官:FlashAttention 的实现原理与内存优化方式?为什么能做到 O(N²) attention 的显存线性化?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)