一种名叫水果的数据库也可以AI
MongoDB发展历程与技术演进 MongoDB作为一款面向文档的NoSQL数据库,自2009年发布以来经历了显著的技术革新。从最初的简单文档存储到支持多文档事务、分布式架构,再到AI时代的向量搜索功能,MongoDB通过版本迭代不断完善其核心架构。其关键技术包括灵活的文档模型、副本集高可用机制、分片集群横向扩展能力,以及可插拔存储引擎设计。最新版本7.0更集成了原生向量搜索功能,使其成为AI应用
一、MongoDB的诞生背景 (2007-2009)
在21世纪初的Web 2.0时代,互联网应用面临着前所未有的数据挑战:海量数据、高并发读写、灵活多变的数据结构。传统的关系型数据库在模式僵化、可扩展性和性能方面显得力不从心。
NoSQL运动应运而生,其核心思想是牺牲一部分复杂SQL功能和不强一致性的保证,以换取更好的可扩展性、灵活性和性能。MongoDB由10gen公司开发并于2009年首次发布,其设计目标是成为一个面向文档的、高性能、高可用、易扩展的通用数据库。
二、MongoDB版本迭代的技术革新特点
MongoDB的版本迭代是一部不断自我革新、弥补短板、拥抱现代数据库需求的历史。
|
版本 |
发布时间 |
核心技术创新与特点 |
|
v1.0 |
2009 |
初代版本。奠定了基础:BSON格式、文档模型、简单的复制集和分片功能。 |
|
v2.0 |
2011 |
引入数据压缩。改进分片集群,提升了大规模数据管理的稳定性。 |
|
v2.4 |
2013 |
引入聚合框架。提供了强大、声明式的数据流水线处理能力。文本搜索集成。 |
|
v2.6 |
2014 |
大幅提升运维和管理能力。引入并行索引构建、查询优化器改进、安全性增强。 |
|
v3.0 |
2015 |
划时代的版本:可插拔存储引擎架构。WiredTiger成为默认引擎,支持文档级并发控制和压缩。 |
|
v3.2 |
2015 |
引入数据可视化与分析利器:$lookup操作符、聚合框架增强、加密存储引擎。 |
|
v3.4 |
2016 |
多模型数据库探索:只读视图、局部索引、图形搜索。 |
|
v3.6 |
2017 |
迈向实时数据库:Change Streams、可重试读写、更灵活的Schema校验。 |
|
v4.0 |
2018 |
支持多文档事务。在复制集环境下支持跨多个文档、多个集合的事务,ACID保证。 |
|
v4.2 |
2019 |
分布式事务与融合型数据库:支持分片集群上的分布式事务、通配符索引、联合查询。 |
|
v4.4 |
2020 |
增强版云原生数据库:联合体、镜像读、细化并发控制。 |
|
v5.0 |
2021 |
时序数据与原生时代:原生时间序列集合、版本化API、实时重分片。 |
|
v6.0 |
2022 |
强化分析能力与加密:聚合框架进一步增强、可查询加密、集群同步。 |
|
v7.0 |
2023 |
AI时代的基础设施:$vectorSearch操作符原生支持向量搜索、高性能全局排序、类物化视图。 |
三、MongoDB技术特点和主要架构
1. 文档模型
数据以BSON格式存储,天然对应编程语言中的对象。模式灵活:同一个集合中的文档可以拥有不同的字段结构,支持快速迭代。
2. 查询语言
强大的查询API和聚合框架,支持丰富的查询、转换、分组、连接、图遍历和向量搜索操作。
3. 高可用性
复制集:一组维护相同数据集的MongoDB实例。提供自动故障转移,保证服务高可用。数据通过oplog异步复制。
4. 横向扩展
分片集群:将数据分布到多个分片上,每个分片持有数据的一个子集。通过分片键自动进行数据分区和路由,实现近乎无限的扩展能力。
5. 可插拔存储引擎
架构上将上层数据库功能与底层存储技术解耦。用户可根据场景选择引擎。
6.主要架构
(1)MongoDB 副本集架构图
副本集的核心目标是实现数据冗余和高可用性。一个副本集由多个 MongoDB 服务器节点组成(通常为奇数个,如 3个)。
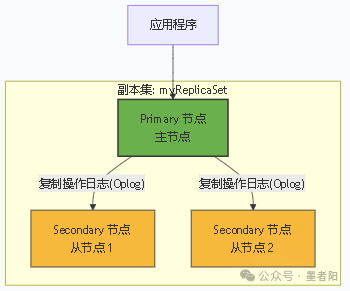
架构说明:
a.Primary (主节点):唯一一个接收所有写操作的节点。将数据更改记录到其操作日志 (Oplog) 中。接收应用程序的所有读写请求(默认情况下,读请求也发往 Primary)。
b.Secondary (从节点):异步地复制 Primary 的 Oplog 并将操作应用到自己的数据集。可以接受读请求(需要配置读取偏好 readPreference 为 secondary)。是 Primary 的“热备份”,提供数据冗余和高可用性。
c.Arbiter (仲裁者,可选):图中未展示,它是一个特殊的节点。它不存储数据,仅参与投票,用于在选举中打破平局,帮助选出新的 Primary。通常用于节省资源且节点数为偶数的情况(例如,用 2个数据节点 + 1个仲裁者来代替 3个数据节点)。
d.高可用性:如果 Primary 节点宕机,剩余的 Secondary 节点会自动发起一次选举,推举出一个新的 Primary 节点,从而恢复写操作,整个过程对应用是透明的。
(2)MongoDB 分片集群架构图
分片集群的核心目标是实现水平扩展(横向扩展),用于处理海量数据和高吞吐量场景。它由三个核心组件组成,每个组件本身都可能是一个副本集,以确保高可用性。
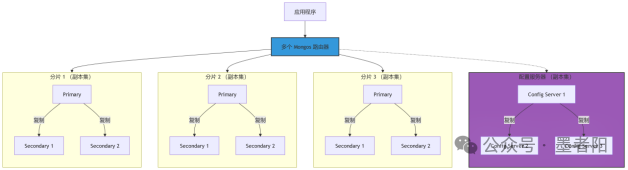
架构说明:
a.Shard (分片):
》是什么:每个分片是数据的一个子集。一个分片可以是一个单独的 MongoDB 实例,但在生产环境中,每个分片都应该是一个副本集(如图中所示),以防止单点故障。
》为什么:数据被横向分割到多个分片上,每个分片只存储总体数据的一部分。这样数据库的总容量和吞吐能力可以随着分片数量的增加而线性增长。
b.Config Server (配置服务器):
》是什么:一个特殊的 MongoDB 副本集,存储着集群的元数据。
》存储什么:包含数据在集群中的分布映射(即哪些数据位于哪个分片上)。
》为什么重要: Mongos 路由器依靠这些元数据来将读写请求路由到正确的分片。
c.Mongos (路由器):
》是什么:一个轻量级的服务,是应用程序与分片集群交互的唯一入口。应用程序不再直接连接分片,而是连接 Mongos。
》做什么:向 Config Server 查询元数据。根据查询的片键(Shard Key),将客户端的读写请求路由到相应的一个或多个分片。合并来自各个分片的结果,返回给客户端。
》如何扩展:通常会启动多个 Mongos 实例,以实现负载均衡和高可用性。
d.工作流程:
》应用程序连接到一个 Mongos 实例。
》当需要写入数据时,Mongos 根据片键和配置服务器中的元数据,确定这条数据应该被写入哪个 Shard(分片)。
》Mongos 将写操作转发到该分片的主节点。
》数据最终被写入指定的分片,并在该分片的副本集内部进行复制。
(3)综合对比
|
特性 |
副本集 |
分片集群(使用副本集作为分片) |
|
核心目标 |
高可用性 和 数据冗余 |
水平扩展(处理海量数据和高吞吐量) |
|
数据分布 |
所有节点拥有完整的数据副本 |
数据被分区,每个分片只存一部分数据 |
|
写操作 |
只能由 Primary 节点处理 |
由多个分片的 Primary 节点并行处理 |
|
读操作 |
可以从 Primary 或 Secondary 读取 |
可以从多个分片并行读取 |
|
组件 |
一组 MongoDB 节点(Primary, Secondary) |
分片(副本集)、配置服务器(副本集)、路由(Mongos) |
|
适用场景 |
灾难恢复、读写分离、保证服务不中断 |
数据量超过单机容量、并发吞吐量超过单机性能 |
四、关键技术细节
1.权限管理(RBAC)
基于角色的访问控制。管理员创建用户,并为其分配角色。角色定义了权限,即特定资源上执行的操作。内置了大量常用角色,也支持自定义角色。精细度可达集合级别。
2.数据备份与恢复
逻辑备份:使用mongodump和mongorestore工具。物理备份:直接拷贝底层数据文件。oplog增量备份:结合全量备份和oplog的重放,可以实现任意时间点恢复。MongoDB Atlas提供全自动、连续的后台备份与一键恢复功能。
3.引擎技术
WiredTiger(当前默认):文档级并发控制,写操作只需锁住单个文档。快照与检查点,保证数据一致性和快速恢复。压缩支持Snappy和Zlib算法,有效减少存储空间占用。
五、MongoDB在AI领域的技术应用与发展前景
1.技术应用
AI数据层:MongoDB的文档模型非常适合存储非结构化和半结构化的AI数据。元数据管理:管理AI实验的元数据。向量搜索:从v7.0开始,MongoDB集成了原生向量搜索功能,应用于检索增强生成、语义搜索、推荐系统和异常检测。
2.发展前景
一体化优势:MongoDB提供了一个统一的数据平台,可以同时处理AI应用的传统业务数据、元数据和向量数据。性能与规模优化:持续优化其向量索引的性能、准确性和规模。与AI生态更深度集成:预计将看到更多与主流AI框架、云AI服务的开箱即用集成方案。操作型AI:非常适合将AI推理结果实时地应用于用户交互场景。
六、总结
MongoDB从一个满足Web敏捷开发的文档数据库起步,通过持续不断的自我革新,已经成长为一个功能强大的现代通用数据库。如今,通过原生集成向量搜索,它正强势切入AI应用的核心领域,为其发展提供了操作型数据+向量搜索的一体化解决方案,未来在AI时代的发展前景非常广阔。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)