端侧基础大模型全景指南:从CLIP到VLM(三)
本文系统介绍了多模态大语言模型(MLLMs)的发展与应用,重点分析了LLAVA和Flamingo两大代表性模型。LLAVA通过融合视觉编码器和语言模型,实现了细粒度视觉理解和基于图像的对话能力;Flamingo则采用Perceiver Resampler架构,在跨模态少样本学习方面表现突出,支持视觉问答、图像描述等任务。文章详细阐述了这些模型的核心原理、技术特点及实际应用场景,并提供了示例代码和效
·
0. 前言
在前两篇文章中,我们系统介绍了端侧视觉基础模型:
- 第一篇:CLIP、BLIP — 多模态对齐与图像理解基础
- 第二篇:DINO、SAM、Grounding DINO、Grounded-SAM、SigLIP — 视觉特征与分割检测
这些模型各自专注于特定的视觉任务。本篇将介绍一类更强大的模型——多模态大语言模型(Multimodal Large Language Models, MLLMs),它们将视觉理解与语言生成能力深度融合,实现了真正的"看图说话"和多轮视觉对话。让我们深入了解这些多模态大语言模型的核心原理和使用方法。
1. LLAVA (Large Language and Vision Assistant)
1.1 核心任务
LLAVA是一个多模态大型语言模型,结合了视觉编码器和大型语言模型,能够理解图像并进行基于图像的对话和问答。
1.2 关键特点
- 丰富的多模态对话能力
- 细粒度的视觉理解
- 强大的知识推理能力
1.3 示例代码

1.4 效果展示

2. Flamingo: 跨模态少样本学习模型
2.1 核心任务与技术原理
Flamingo是DeepMind在2022年提出的多模态大型语言模型,专为跨模态少样本学习设计。Flamingo能够将视觉信息(图像和视频)与语言模型无缝结合,使模型能够在几个示例的基础上快速适应新任务,包括视觉问答、图像描述和视觉推理等。
2.2 关键特点与技术优势
- 多模态少样本学习:只需几个示例即可适应新任务
- 序列化处理能力:可以处理交错的视觉和文本输入序列
- 视觉编码创新:采用Perceiver Resampler架构有效处理视觉信息
- 跨模态注意力机制:实现视觉和语言信息的深度融合
- 大规模预训练:在海量图文对和视频文本对上预训练
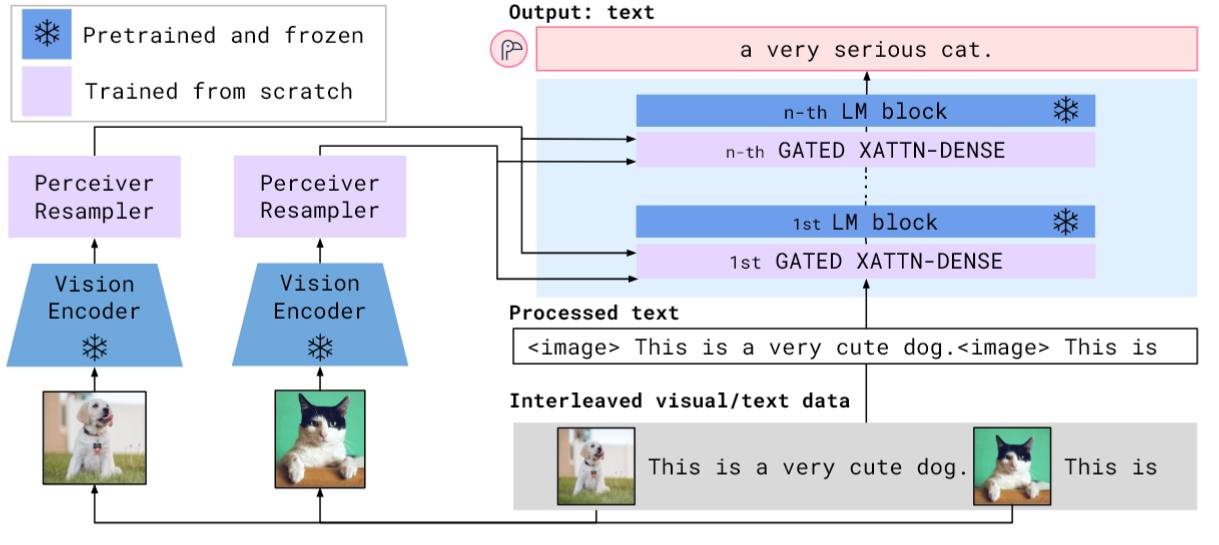
2.3 模型架构
Flamingo的架构包含三个主要组件:
- 视觉编码器:基于预训练的视觉模型(如CLIP)提取视觉特征
- Perceiver Resampler:将高维视觉特征转换为固定数量的视觉tokens
- 语言模型:经修改的大型语言模型,通过跨模态注意力层接收视觉信息
这种设计使Flamingo能够处理任意数量的交错视觉和文本输入,并保持输出的连贯性和相关性。
2.4 实际应用场景
- 视觉问答系统:回答关于图像或视频内容的复杂问题
- 图像描述生成:生成详细、上下文相关的图像描述
- 视觉推理任务:分析图像中的关系和逻辑
- 多轮视觉对话:支持基于视觉内容的多轮对话交互
- 跨模态内容创作:辅助基于视觉提示的内容创作
2.5 示例代码

2.6 效果展示
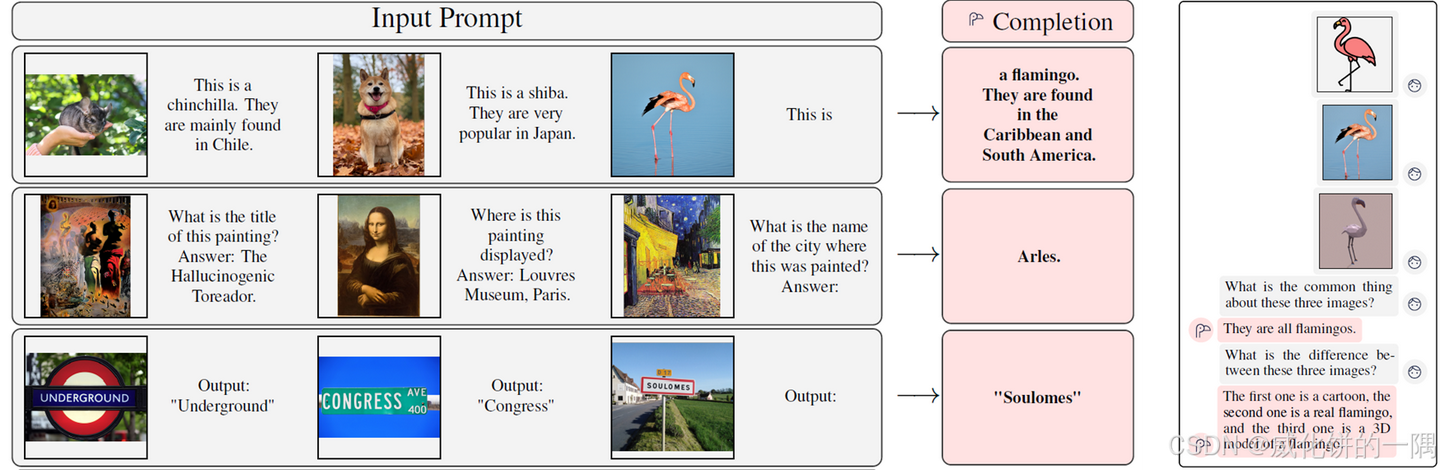
上图展示了Flamingo模型进行多轮图像对话的能力,能够基于图像内容进行连贯的多轮问答交互。
3. MiniCPT: 轻量级中文多模态模型
点击链接端侧基础大模型全景指南:从CLIP到VLM(三)阅读原文

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 26
26 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)