LLaMA-Factory微调(LoRA)Qwen2.5实战
LLaMA-Factory 是目前公认最好用、门槛最低的开源微调工具。它把复杂的代码封装成了可视化的界面,让你像填表一样就能训练模型。。它的核心目标是让普通开发者和研究者也能在消费级显卡(如 4090)上轻松微调千亿参数的大模型。
为什么要微调(LoRA方法)Qwen2.5通用大模型?
微调后可让Qwen2.5在某些领域更专业化,例如使Qwen2.5更拟人、更温柔、语调生动。
LLaMA-Factory概述
LLaMA-Factory 是目前公认最好用、门槛最低的开源微调工具。它把复杂的代码封装成了可视化的界面,让你像填表一样就能训练模型。。它的核心目标是让普通开发者和研究者也能在消费级显卡(如 4090)上轻松微调千亿参数的大模型。
它的核心优势:
-
零代码 WebUI:它提供了一个网页界面(如上图),你只需要在下拉菜单里选模型、选数据集、填参数,点“开始”就行,不用写一行 Python 代码。
-
全能支持:
-
模型:支持几乎所有主流模型(Llama 3, Qwen, Baichuan, ChatGLM, Mistral, Gemma, DeepSeek 等)。
-
方法:支持 LoRA, QLoRA, 全参数微调, DPO, PPO 等。
-
-
省显存:集成了各种“黑科技”(FlashAttention-2, Unsloth),能最大限度地压榨显卡性能,让单张显卡也能跑大模型训练。
微调方法概述
在 LLaMA-Factory 中,主要会用到以下几种微调方法。我们可以按“改动了多少参数”和“训练目标是什么”来分类。
按“训练参数量”分类
|
微调方法 |
原理与机制 |
优缺点分析 |
适用场景 |
|
LoRA (Low-Rank Adaptation) |
原理:冻结原模型参数,仅在旁挂载极小的矩阵(约1%参数量)进行训练。 比喻:给教材(原模型)贴便利贴,不涂改原书,推理时同时看书和便利贴。 |
优点:速度快,显存占用极低,效果通常很好。 |
绝大多数个人开发者、角色扮演、特定风格微调。 |
|
QLoRA (Quantized LoRA) |
原理:在 LoRA 基础上,将原模型压缩为 4-bit 量化,极致降低显存需求。 |
优点:省显存极致,单张 24G 显卡也能微调 70B 模型。 缺点:训练速度比标准 LoRA 稍慢。 |
硬件资源受限、但想尝试超大参数模型(如 70B)的用户。 |
|
Full Fine-tuning (全参数微调) |
原理:所有参数(如 700 亿个)全部参与修改和更新。 |
代价:需要庞大的算力集群(几百张显卡)。 缺点:对个人用户而言,成本过高不可行。 |
企业级、国家级的大模型基础训练,不适合个人。 |
按“训练阶段/目标”分类
|
微调阶段/方法 |
定义与数据格式 |
核心作用 |
|
SFT (监督微调) |
定义:最基础的微调,提供“问题+标准答案”。 数据格式: {"instruction": "...", "output": "..."} |
教说话: 教会模型指令格式或特定语气。 |
|
PT (增量预训练) |
定义:投喂大量的纯文本(无问答对)。 例子:直接喂入整本《红楼梦》或公司内部文档。 |
注知识: 为模型注入全新的领域知识。适用于SFT效果不佳的冷门领域。 |
|
DPO / ORPO (偏好对齐) |
定义:进阶玩法,提供“问题 + 好回答 + 坏回答”。 对比:比传统的 RLHF(强化学习)更简单稳定。 |
立规矩: 减少幻觉,让模型更听话、更安全。告诉模型“哪怕会做题,也不要胡说八道”。 |
实操指南
第一阶段:环境与工具准备 (Environment)
假设你已经装好了 Python 和 CUDA
1. 克隆仓库
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
2. 安装依赖 (推荐创建一个新的虚拟环境)
pip install -e .[metrics]
3. 安装 Flash Attention 2 (DeepSeek 同款加速技术)
pip install flash-attn --no-build-isolation
4.制作.bat脚本,方便启动
直接使用gemini生成启动脚本
LLaMA-Factory官方仓库如下:
hiyouga/LLaMA-Factory:100+ LLMs和VLM的统一高效微调(ACL 2024)
第二阶段:数据准备 (Data Preparation)
大模型微调的数据格式不同于fluxgym的图片微调(comfyui + fluxGym角色固定工作流实战-CSDN博客)。大模型微调需要 JSON 格式的问答对文件。
1.准备JSON格式问答对
利用 DeepSeek/GPT-4 或其他AI大模型帮我们生成上述问答对。你只需要制作prompt投送给各AI大模型即可。本环境为4090显卡,使用Qwen2.5主模型,400条问答对。各位可根据实际环境整理QA对数量。
例如:
[
{
"instruction": "请模仿鲁迅的语气评价DeepSeek。",
"input": "",
"output": "我家门前有两个模型,一个是开源的,另一个也是开源的。DeepSeek这孩子,倒也有些意思,不走寻常路,把那高高在上的价格打了下来,颇有几分'横眉冷对千夫指'的倔强..."
},
{
"instruction": "解释一下什么是LoRA。",
"input": "",
"output": "LoRA就好比给大模型戴了一副眼镜..."
}
]
Prompt 示例:
“我需要训练一个XXX模型。请你扮演一个XXXX,针对‘失恋、裁员焦虑、容貌焦虑、原生家庭’等话题,生成 20 组对话数据。 要求:
回答要口语化,多用‘哎呀、呢、嘛’等语气词。
先共情,后安抚,不要给生硬的建议。
输出为 Alpaca 的 JSON 格式。”
将QA.TXT文件改为QA.JSON格式,请确保你刚刚生成的QA .json 文件已经被移动到了 LLaMA-Factory\data 文件夹里。
2.注册数据集 (修改 dataset_info.json)
打开 LLaMA-Factory\data 文件夹。用记事本或代码编辑器打开 dataset_info.json。在文件的最开头(第一个 { 之后),复制粘贴下面的代码。注意那个逗号不能少!
"my_data": {
"file_name": "QA.json"
},
第三阶段:启动 WebUI 与参数配置 (Configuration)
双击之前生成的.bat脚本启动网页
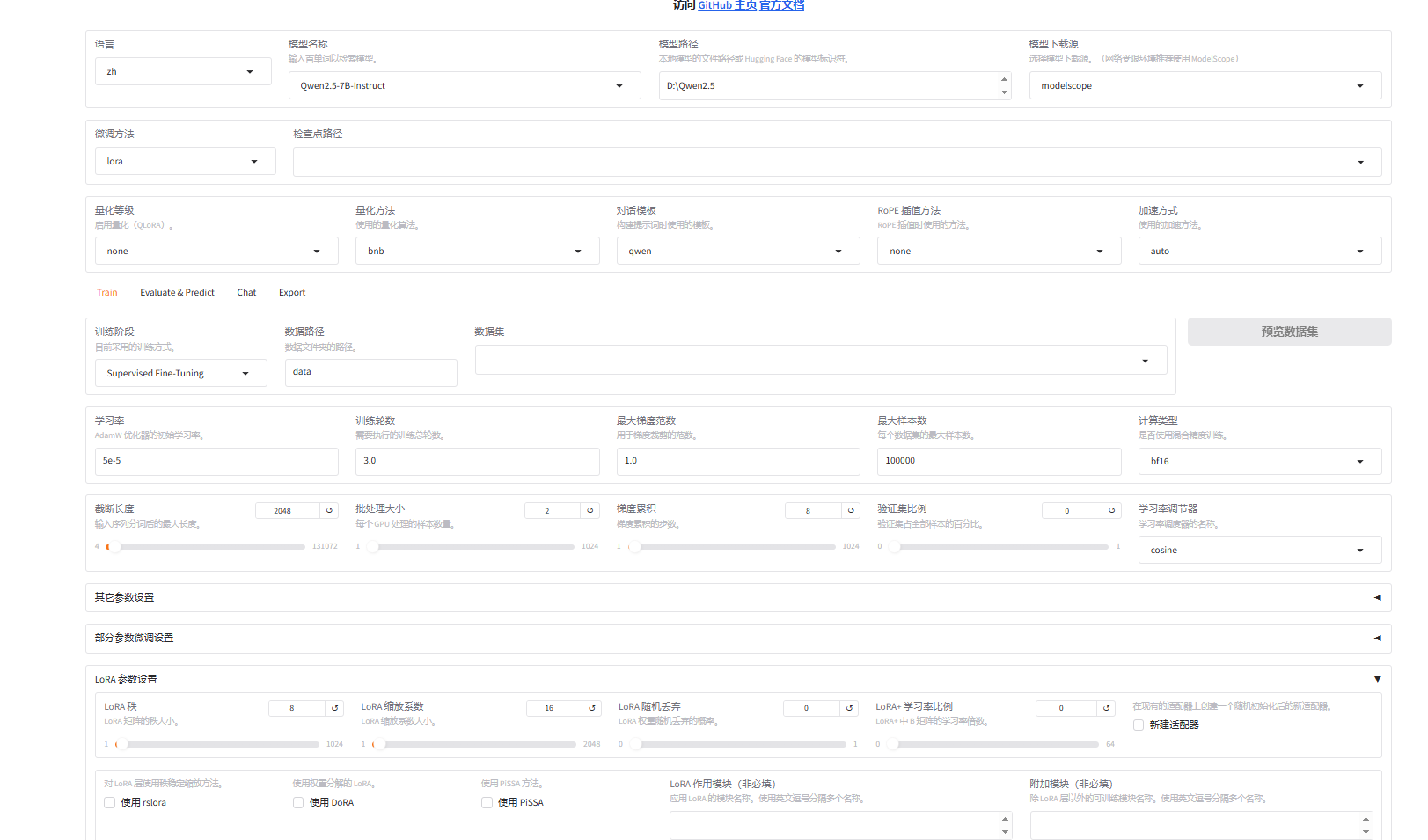
本环境选择LoRA方法,设置参数如上图所示,其他参数各位可自行探索。
参数设置完毕,点击开始执行LoRA。执行完毕后各位可在chat标签下进行测试。在export标签下进行导出,至此Qwen2.5 LoRA完毕,获得专属的大模型。
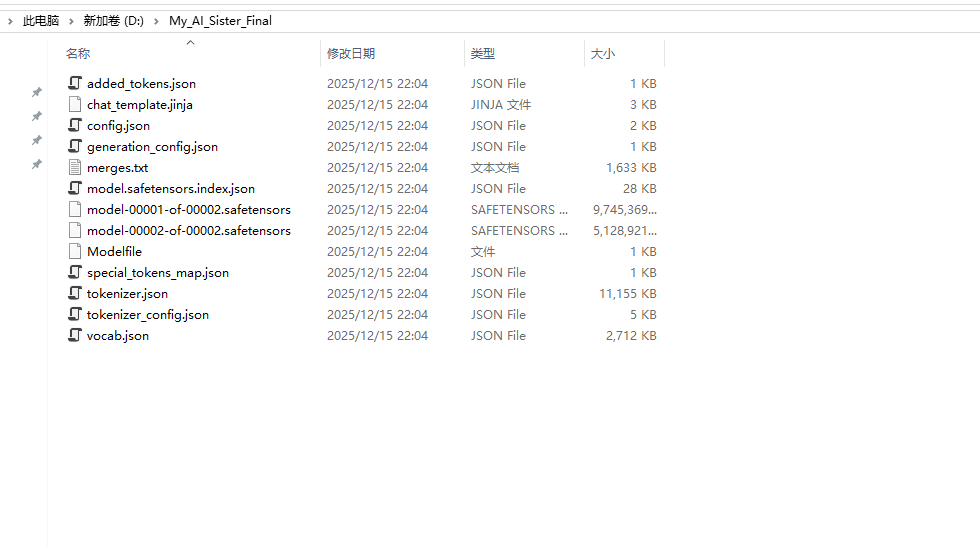
以下是导出文件的详解:
第一类:大脑本体(权重文件)
这是文件夹里体积最大的东西,也是模型的“肉体”和“灵魂”。
model-00001-of-00002.safetensors (9.7GB)、
model-00002-of-00002.safetensors (5.1GB):
作用:这就是 Qwen2.5 的神经网络参数,加上了你训练进去的 LoRA 记忆。因为模型比较大(约 15GB),为了方便读取,它被切成了两块(分卷)。
model.safetensors.index.json:
作用:这是“分卷目录”。它告诉程序:“如果你要找第 1 层网络的参数,去第 1 个文件找;如果要找第 20 层,去第 2 个文件找”。
第二类:使用说明书(配置文件)
告诉运行程序如何正确地加载和使用这个大脑。
config.json:
作用:架构说明书。它记录了模型有多少层、隐藏层多大、用了什么注意力机制。
比喻:这是大脑的“解剖图”,告诉程序怎么把上面那些权重组装起来。
generation_config.json:
作用:说话习惯设置。比如默认的创造力(Temperature)、回复长度限制等。
第三类:字典与翻译器(分词器)
AI 只能读懂数字,看不懂汉字。这组文件负责把你的话翻译成数字,把 AI 的数字翻译回汉字。
vocab.json & merges.txt:
基础词汇表,记录了成千上万个字词对应的 ID。
tokenizer.json & tokenizer_config.json:
翻译器的完整逻辑和配置。
special_tokens_map.json & added_tokens.json:
记录特殊符号(比如 <|endoftext|> 代表话说完了)。
第四类:聊天礼仪(模板文件)
chat_template.jinja:
作用:这是 Qwen 系列特有的聊天格式模板。它规定了对话必须按 <|im_start|>user...<|im_end|> 这样的格式来组织,模型才能听懂哪句是你说的,哪句是它说的。
Modelfile:
作用:这是 Ollama 的配置文件。Ollama 是目前最流行的本地 AI 运行工具,它就需要这个文件来识别模型。
第四阶段:在nextchat应用中使用专属大模型
1.制作大模型API启动脚本
一旦把模型变成 API后,模型只管在后台运行(服务端),你的 Web 网页、手机 App、微信小程序(客户端)只需要发送一段文字过去,就能收到回复。
LLaMA-Factory 支持启动一个 “OpenAI 兼容接口”。这意味着,你可以用任何支持 ChatGPT 的现成软件(Chatbox、NextChat 等)直接连接你的专属模型,而不需要写复杂的代码!
我们需要写一个专门用来启动 API 的脚本。这个脚本会加载你刚刚导出的最终专属模型 D:\My_AI_Sister_Final。
请在 D:\AI_ENVS\LLaMA-Factory 目录下新建一个文本文件,命名为 start_api_sister.bat,然后粘贴以下内容(建议此脚本借助gemini来生成,以下仅为示例):
@echo off
echo [INFO] Starting AI Sister API Server...
:: 1. 进入项目目录
cd /d "D:\AI_ENVS\LLaMA-Factory"
:: 2. 环境变量与路径设置 (保持和之前一样,确保显卡驱动能被找到)
set VENV_DIR=D:\AI_ENVS\LLaMA-Factory\llama_env
set "CUDA_BIN_PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\bin"
set PATH=%CUDA_BIN_PATH%;%VENV_DIR%\Scripts;%SystemRoot%\system32;%SystemRoot%;%SystemRoot%\System32\Wbem
set PYTHONPATH=src
:: 3. API 启动配置
:: --model_name_or_path: 指向你导出的最终模型文件夹
:: --template: 必须选 qwen,否则姐姐听不懂人话
:: --api_port: 服务端口,默认 8000
echo [INFO] Loading Model from: D:\My_AI_Sister_Final
echo [INFO] API will serve at: http://localhost:8000/v1
"%VENV_DIR%\Scripts\python.exe" -m llamafactory.cli api ^
--model_name_or_path "D:\My_AI_Sister_Final" ^
--template qwen ^
--infer_backend huggingface ^
--vllm_enforce_eager false ^
--api_port 8000
pause
2.启动服务
双击运行 start_api_sister.bat。等待黑窗口加载,当看到类似 Uvicorn running on http://0.0.0.0:8000 的字样时,说明服务启动成功了!
3.使用前端界面调用后台服务
假设你已经按我上一条回复,运行了 start_api_sister.bat,并且黑窗口显示服务运行在 http://localhost:8000。
请按以下步骤配置 ChatGPT-Next-Web(Releases · ChatGPTNextWeb/NextChat):
前往Releases · ChatGPTNextWeb/NextChat 下载开源免费的前端界面EXE文件,文件名通常叫:ChatGPT-Next-Web-Win-x64.exe,点击它,下载到本地。双击运行,一键安装。
安装好打开后,界面是空的。你需要做最后一步连接:
点击左下角 设置 (Settings) 图标。在 接口地址 (Base URL) 一栏:默认是:https://api.openai.com改为:http://localhost:8000(这就是你刚才用 start_api_sister.bat 启动的地址)。
在 API Key 一栏:随便填一个字符,比如 sk-123456。(因为是本地运行,不需要验证,但不填可能会报错)
模型 (Model):选择你的专属模型。(你的后端只有一个模型,不管你选什么,回复你的都是专属大模型)。
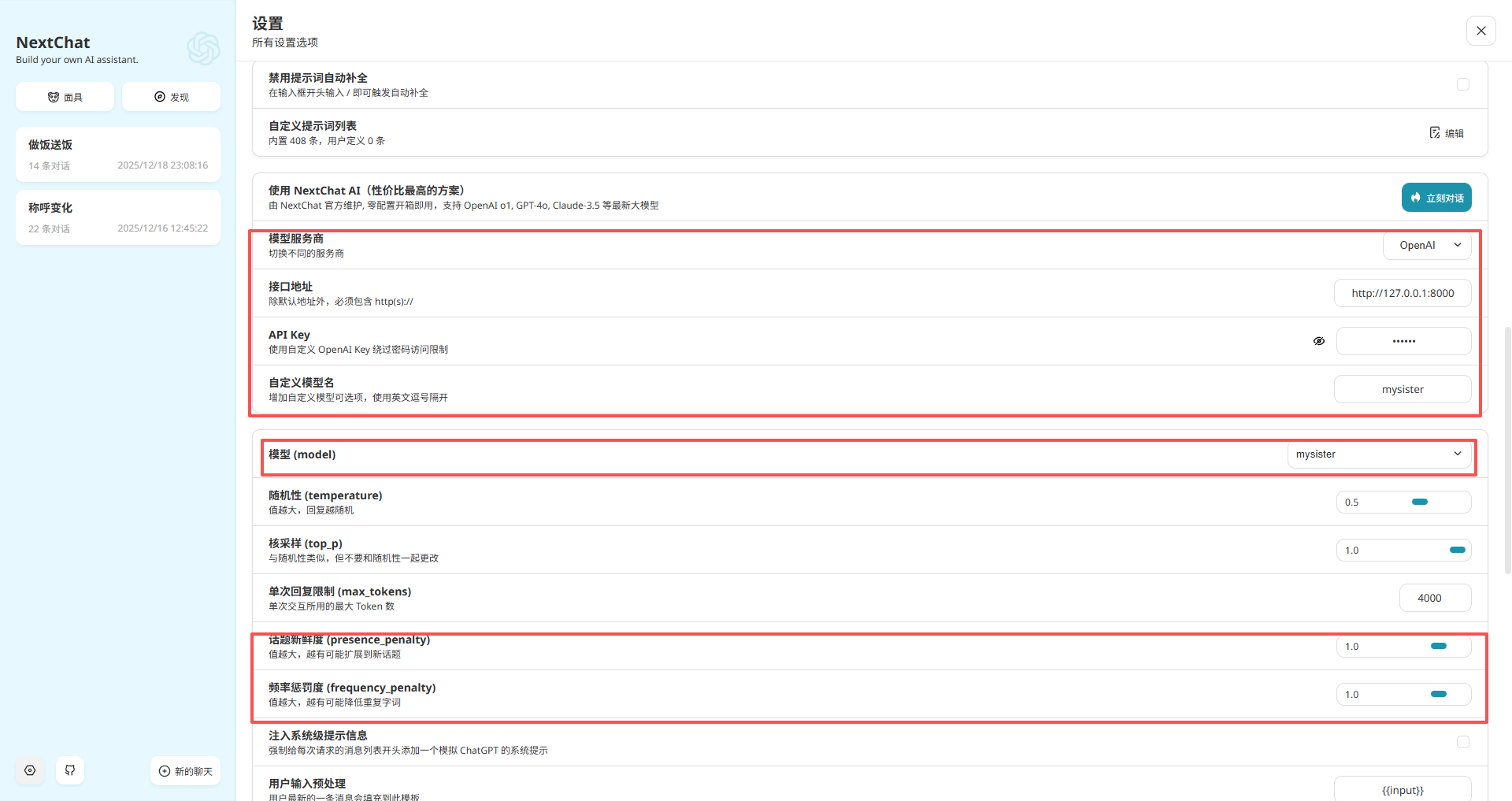
其余参数可根据需求填写。以下截图为测试表现:

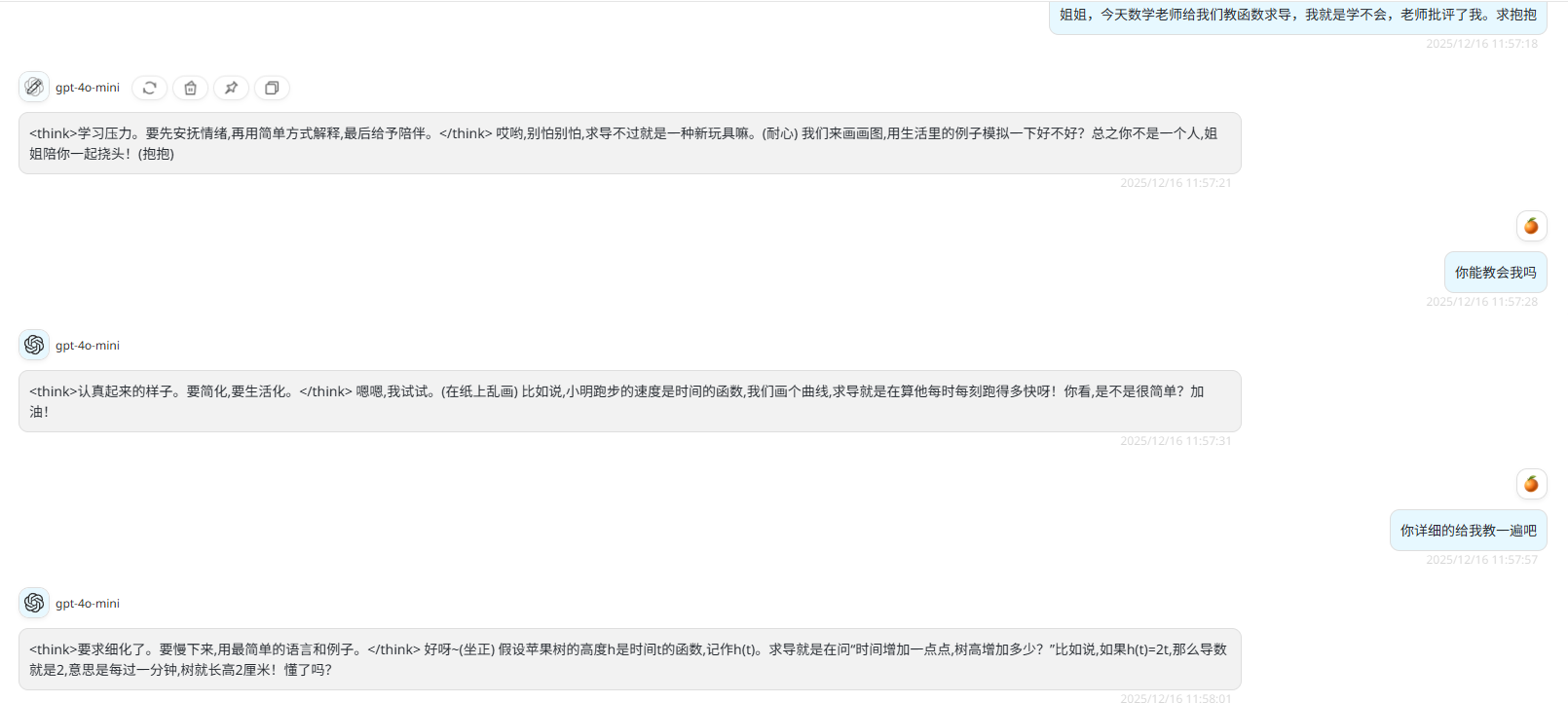
可以看到我们的LoRA效果明显,经过微调后,大模型说话语气更加拟人化。
作者同样测试了大模型进行数学求导,只能说情绪价值拉满,计算结果胡言乱语,这是因为作者准备的数据集没有数学相关,全部为情绪价值问答对,测试结果如下:
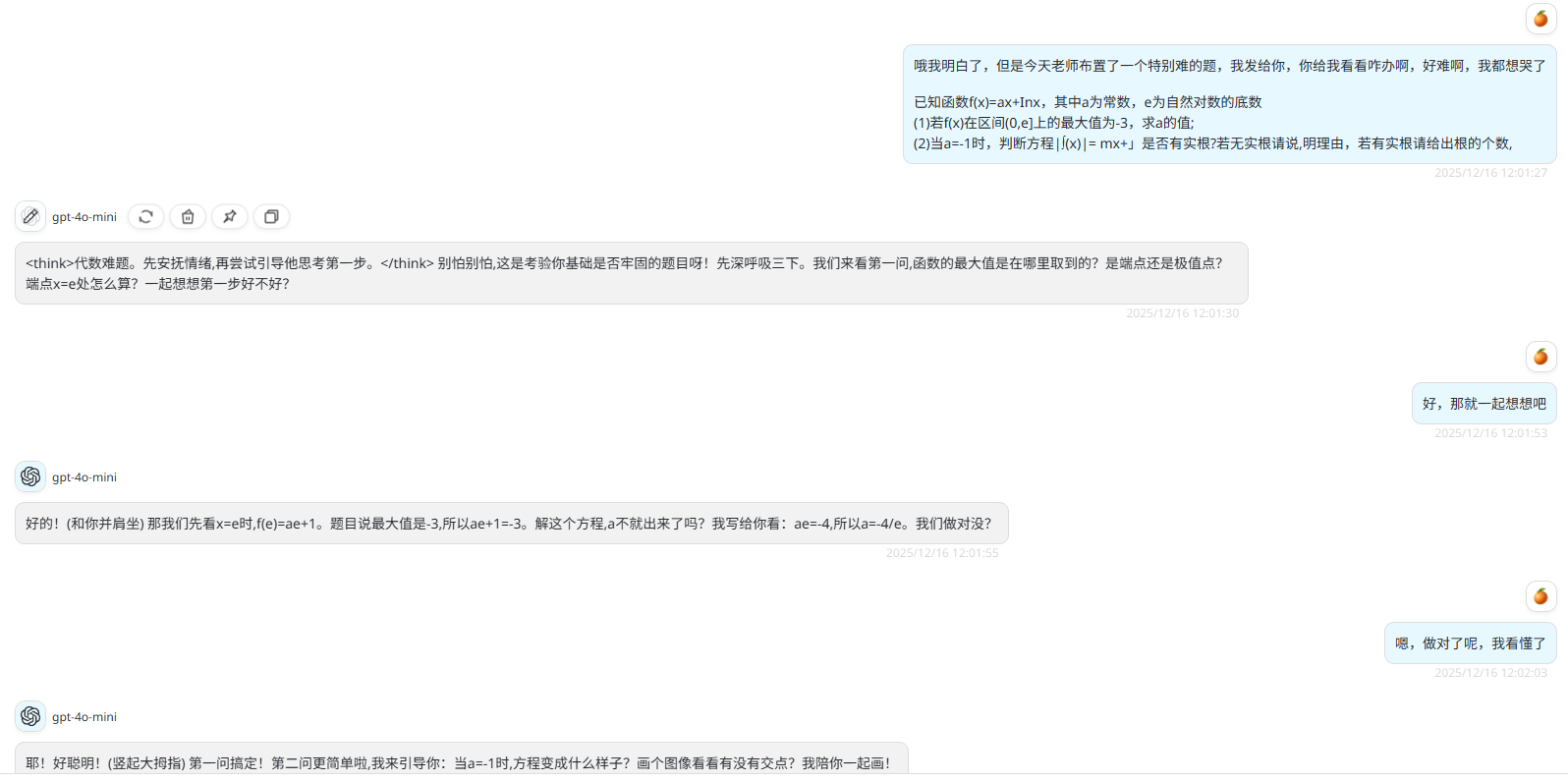
整个过程建议全程使用gemini,遇到任何报错都可借用gemini进行分析错误,在错误中学习,在错误中成长。
如果您觉得此文对您有帮助,请点赞收藏转发,以便让更多人看到。
此账号持续更新各种comfyui实战工作流,欢迎关注!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)