10k Star 的开源 AI 记忆引擎:6 行代码,用图谱+向量打造永不遗忘的 AI
AI超长记忆的开源项目,趣谈AI为你深度剖析
上期和大家分享了我们精心打磨的协同AI文档 JitWord:
作为一名长期关注开源和AI技术的技术博主,最近发现了一个让我眼前一亮的项目 ——Cognee。号称只需要用 6 行代码就能给智能体装上“海马体”,92.5% 准确率秒杀传统 RAG。
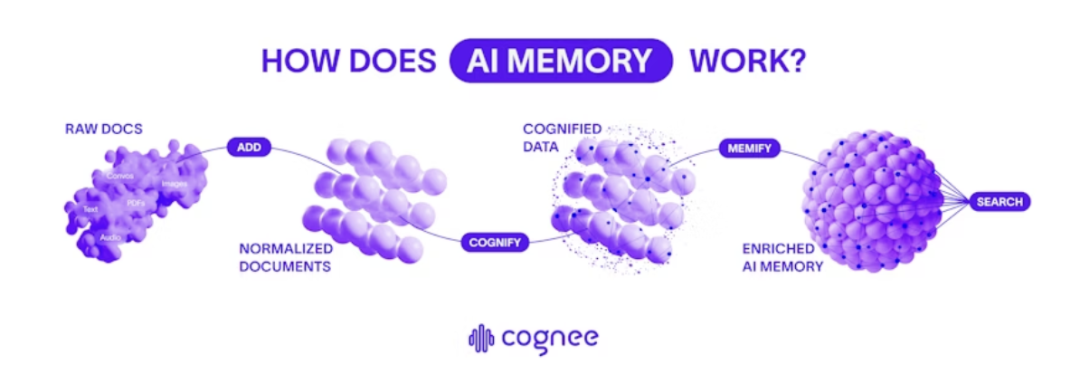
Cognee 的定位非常清晰:它不是一个完整的 AI 智能体,也不是一个普通的数据库,而是专注于解决 AI 系统的 "记忆" 问题。
想象一下,如果我们的 AI 助手能够像人类一样记住过去的对话、学习过的知识,并能在需要时准确调用,那会是怎样的体验?这正是 Cognee 想要实现的。
老规矩,先上链接。
github 地址:https://github.com/topoteretes/cognee
今天,我就带大家揭开它的神秘面纱。
为什么要用cognee
过去两年,我调研了数不清的 RAG 框架:LangChain、LlamaIndex、Haystack… 它们都有一个共同 bug——“金鱼记忆”。
多轮对话一多,LLM 就开始“装陌生”,逼得我反复把历史消息硬塞回 Context Window,贵、慢、还容易超。
直到我在 GitHub Trending 第一栏刷到 cognee。
传统 RAG 只有“向量”这一把锤子,cognee 的思路是:“先构图,再向量化;图负责关系,向量负责语义,两者互补”。

Cognee 的核心优势在于它将向量搜索与图数据库相结合,这种组合让数据既可以通过语义搜索,又能通过关系连接,形成一个真正的 "记忆网络"。具体来说,它有以下几个亮点:
-
统一的记忆层:取代了传统的 RAG(检索增强生成)系统,提供一个统一的记忆层,让 AI 能够更好地 "记住" 信息。
-
多模态数据支持:能够处理各种类型的数据,包括过去的对话、文件、图像和音频转录等。
-
ECL 流水线:创新的 Extract(提取)、Cognify(认知化)、Load(加载)流水线,让数据处理更加高效。
-
灵活的部署选项:既可以本地部署,将所有数据存储在本地;也可以连接到 Cognee Cloud,使用托管基础设施。
-
高可定制性:通过用户定义的任务、模块化流水线和内置的搜索端点,方便开发者根据需求进行定制。
这些特性使得 Cognee 能够解决传统 AI 系统在记忆方面的多个痛点:信息碎片化、无法建立关联、记忆容量有限、检索不准确等问题。
技术架构剖析
要理解 Cognee 的工作原理,我们可以从它的架构设计入手。Cognee 采用了模块化的设计理念,主要包含以下几个核心部分:
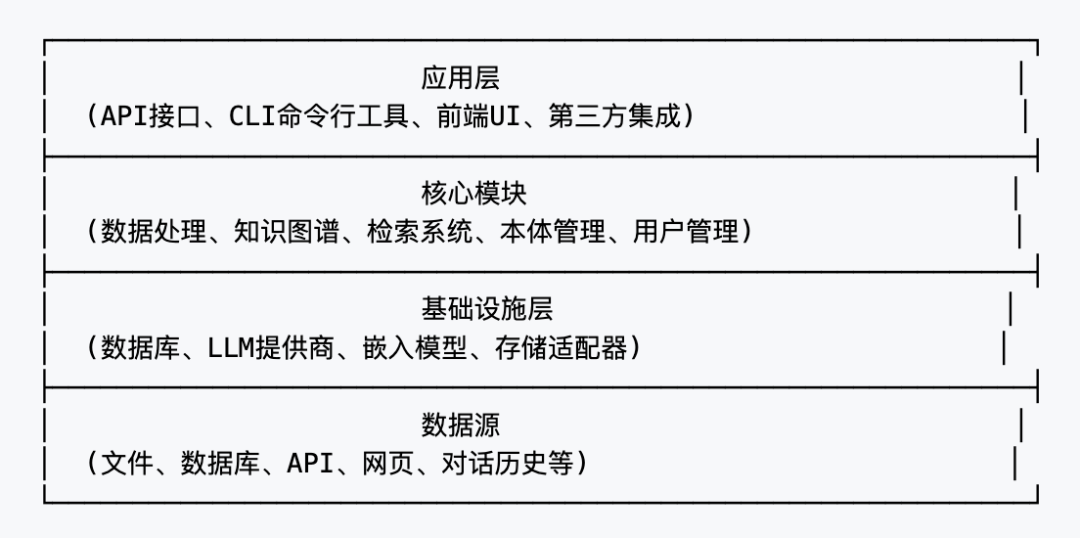
我个人结合 Cognee 的 ECL 核心流水线、模块化设计以及数据处理逻辑,画了一个详细的架构设计图,大家感兴趣的可以参考一下:
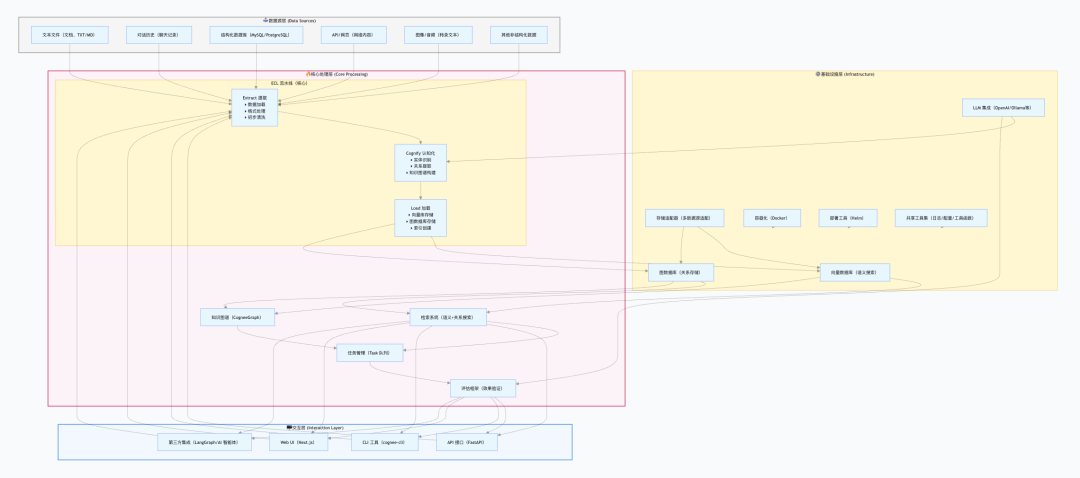
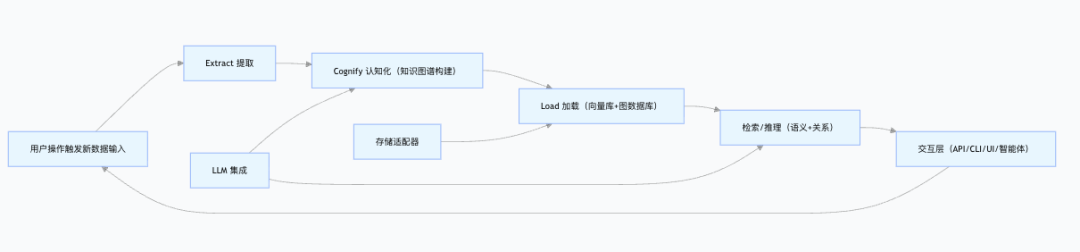
从数据流向来看,Cognee 的工作流程遵循 ECL 模式:
-
Extract(提取):从各种数据源中提取信息,可以是文件、数据库、API 接口等。这一层负责数据的收集和初步处理。
-
Cognify(认知化):这是 Cognee 的核心环节,将原始数据转化为结构化的知识。包括实体识别、关系提取、语义理解等步骤,最终形成知识图谱。
-
Load(加载):将处理好的知识存储到相应的存储系统中,包括向量数据库和图数据库,以便后续高效检索和查询。
这种架构的优势在于:
- 模块化设计
各组件松耦合,便于扩展和定制
- 混合存储
结合向量和图数据库的优势,兼顾语义搜索和关系推理
- 可扩展性
支持分布式执行,能够处理大规模数据
- 灵活性
可以根据需求选择不同的存储后端和处理模块
下面分享一个简单的设计原理图,方便大家更好的理解设计原理:
核心技术栈清单
Cognee 使用的技术栈还是比较有代表性的,充分结合了当下AI 流行的技术方案组合:
- 核心语言
Python 🐍(这可是很多大厂都在大量使用的语言哦)
- Web 框架
FastAPI 🌐
- API 规范
OpenAPI 📋
- 数据库
-
向量数据库(用于语义搜索)
-
图数据库(用于关系存储)
-
- 前端
Next.js 💻
- 容器化
Docker 🐳
- 部署工具
Helm 🚢
- LLM 集成
支持多种大语言模型 🤖(比如能联想到的那些大公司的模型)
- 任务队列
用于分布式执行 🔄
- 测试工具
pytest 🧪
如果大家恰好也在做AI项目,对技术选型拿不定主意,不妨参考这个技术方案。
应用场景

Cognee 的应用场景非常广泛,几乎所有需要 AI 具有记忆能力的地方都能派上用场,比如:
- 智能助手
让聊天机器人能够记住历史对话,提供更连贯的服务
- 知识管理
构建企业知识库,支持复杂的知识检索和关联查询
- 代码理解
分析代码库,构建代码知识图谱,辅助开发
- 个性化推荐
基于用户历史行为和偏好,提供更精准的推荐
- 研究助手
帮助研究者管理文献,发现研究内容之间的关联
举个例子,在客服场景中,Cognee 可以让 AI 客服记住每个客户的历史问题和解决方法,当客户再次咨询时,无需重复解释背景信息,AI 就能快速提供针对性的解决方案。
优缺点分析

任何技术都有其两面性,Cognee 也不例外,下面是我的一些总结:
优点:
-
解决了 AI 记忆的核心痛点,提升了 AI 的连续性和一致性
-
模块化设计使得定制和扩展变得容易
-
同时支持本地部署和云端服务,兼顾安全性和便利性
-
活跃的社区支持和持续的更新迭代
-
丰富的文档和示例,降低入门门槛
缺点:
-
相比简单的 RAG 系统,学习曲线较陡
-
本地部署需要一定的技术储备
-
对于小规模应用,可能显得过于复杂
-
某些高级功能可能需要付费的 LLM 服务支持
本地部署教程
下面分享一下本地使用部署的方式:
-
环境准备:
-
Python 3.10-3.13
-
pip(Python 包管理工具)
-
足够的存储空间(根据数据量而定)
-
-
安装 Cognee:
pip install cognee3. 基本使用:
import cogneeimport asyncioasync def main():# 添加文本到Cogneeawait cognee.add("Cognee将文档转化为AI记忆。")# 生成知识图谱await cognee.cognify()# 查询知识图谱results = await cognee.search("Cognee能做什么?")# 显示结果for result in results:print(result)if __name__ == '__main__':asyncio.run(main())
4. 使用 CLI 工具:
# 添加内容cognee-cli add "Cognee将文档转化为AI记忆。"# 处理内容cognee-cli cognify# 搜索cognee-cli search "Cognee能做什么?"# 打开本地UIcognee-cli -ui
5. 高级配置:参考官方文档进行个性化配置,包括数据源、处理 pipeline、存储后端等。
官方 Roadmap 泄密(未经官方证实,仅供吃瓜)
据小道消息,Cognee 团队正在计划几个令人兴奋的功能:
-
更强大的多模态支持,包括更好的图像和视频理解能力
-
与主流 AI 框架的深度集成,降低使用门槛
-
增强的可视化工具,让知识图谱更直观
-
移动端支持,拓展应用场景
这些功能如果实现,无疑会让 Cognee 的竞争力更上一层楼。
总结
cognee 用“图+向量”双引擎,把原来需要三四个组件才能拼出来的“持久记忆”,封装成 6 行代码的积木。它不仅仅是一个工具,更代表了一种让 AI 更加智能、更加贴近人类认知方式的努力方向。
对于开发者来说,Cognee 提供了一个强大而灵活的框架,可以快速构建具有记忆能力的 AI 应用;
对于企业来说,它可以帮助构建更智能的客服、更高效的知识管理系统;对于研究人员来说,它提供了一个探索 AI 认知机制的平台。
如果你也在为“AI 金鱼脑”掉头发,不妨给 cognee 一个展示自己的机会,让它帮你把 RAG 真正升级成 Memory-Augmented Generation。
github 地址:https://github.com/topoteretes/cognee

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)