大模型持续学习
当前的生成式模型是静态的,无法更新知识。如果直接微调,会对原来的知识造成灾难性遗忘,这显然是不符合真实场景需求的。因此生成式模型需要有持续学习的能力。现有的持续学习综述大多关注传统的判别模型,或者只局限于某一种生成模型(如仅LLM)。本文目标是提供一个统一的视角,系统地分析和总结不同生成模型(LLM, MLLM, VLA, diffusion)在持续学习方面的研究现状、关键方法和未来方向,为该领域
文章目录
Continual Learning for Generative AI: From LLMs to MLLMs and Beyond
- 2025.8
abstract
- 当前的生成式模型是静态的,无法更新知识。如果直接微调,会对原来的知识造成灾难性遗忘,这显然是不符合真实场景需求的。因此生成式模型需要有持续学习的能力。
- 现有的持续学习综述大多关注传统的判别模型,或者只局限于某一种生成模型(如仅LLM)。本文目标是提供一个统一的视角,系统地分析和总结不同生成模型(LLM, MLLM, VLA, diffusion)在持续学习方面的研究现状、关键方法和未来方向,为该领域的研究者提供一个全面的参考。
method
- 评判一个生成模型的“终身学习”能力,要看它在学习新东西时,是否学得好(整体性能)、忘得少(遗忘评估)、还能举一反三(泛化能力)。
持续学习的几种范式
-
基于架构的方法 (Architecture-based Methods):比如PEFT 更新,lora等方式,引入新知识特定的参数模块,只更新这部分参数
-
正则化学习:
- 参数空间正则:通过kl loss等,约束对旧知识参数变更较大的改动
- 特征空间正则:知识蒸馏的方法,新模型的输出和旧模型的输出保持一致
-
温故知新学习/基于回放的方法 (Replay-based Methods):学习新知识的时候,把旧知识的内容也混合一定比例进去。(旧知识可能是原来的训练数据,也可能是旧模型生成的数据)
-
总结:这几种方法在不同的生成模型上都有使用,但是不同的生成模型侧重的方法有所不同。
述持续学习的训练和评估流程
- 训练:训练样本以任务序列的形式(Task 1, Task 2, …, Task T)依次到来。模型在学习第 t 个任务时,只能访问当前任务的数据集 D𝑡。旧任务的数据通常是受限或完全不可访问的。
- 评估方式:我们用 𝑎_𝑡,𝑘 表示模型在训练完任务 t 后,在任务 k 上的性能。
- 整体性能:
- Average Accuracy (Avg):衡量模型在所有已学习任务上的平均表现。数值越高越好。
- Last Accuracy (Last): 衡量模型在当前任务上的最终表现。
- 遗忘评估
- 遗忘度量 (Forgetting Measure, FM): 计算模型在学习新任务后,在旧任务上性能下降的程度。FM越低,说明遗忘越少,性能越好。
- 向后迁移 (Backward Transfer, BWT): 衡量学习新任务对旧任务性能的平均影响。
- BWT > 0 (正迁移): 学习新知识反而提升了旧任务的性能(非常好!)。
- BWT < 0 (负迁移): 学习新知识损害了旧任务的性能,即发生了遗忘。
- 迁移能力:zero-shot,对未见任务的零样本泛化能力保持得如何。例如文本生成用BLEU,图像生成用FID等。
- 整体性能:
几类生成模型基于不同持续学习范式的工作
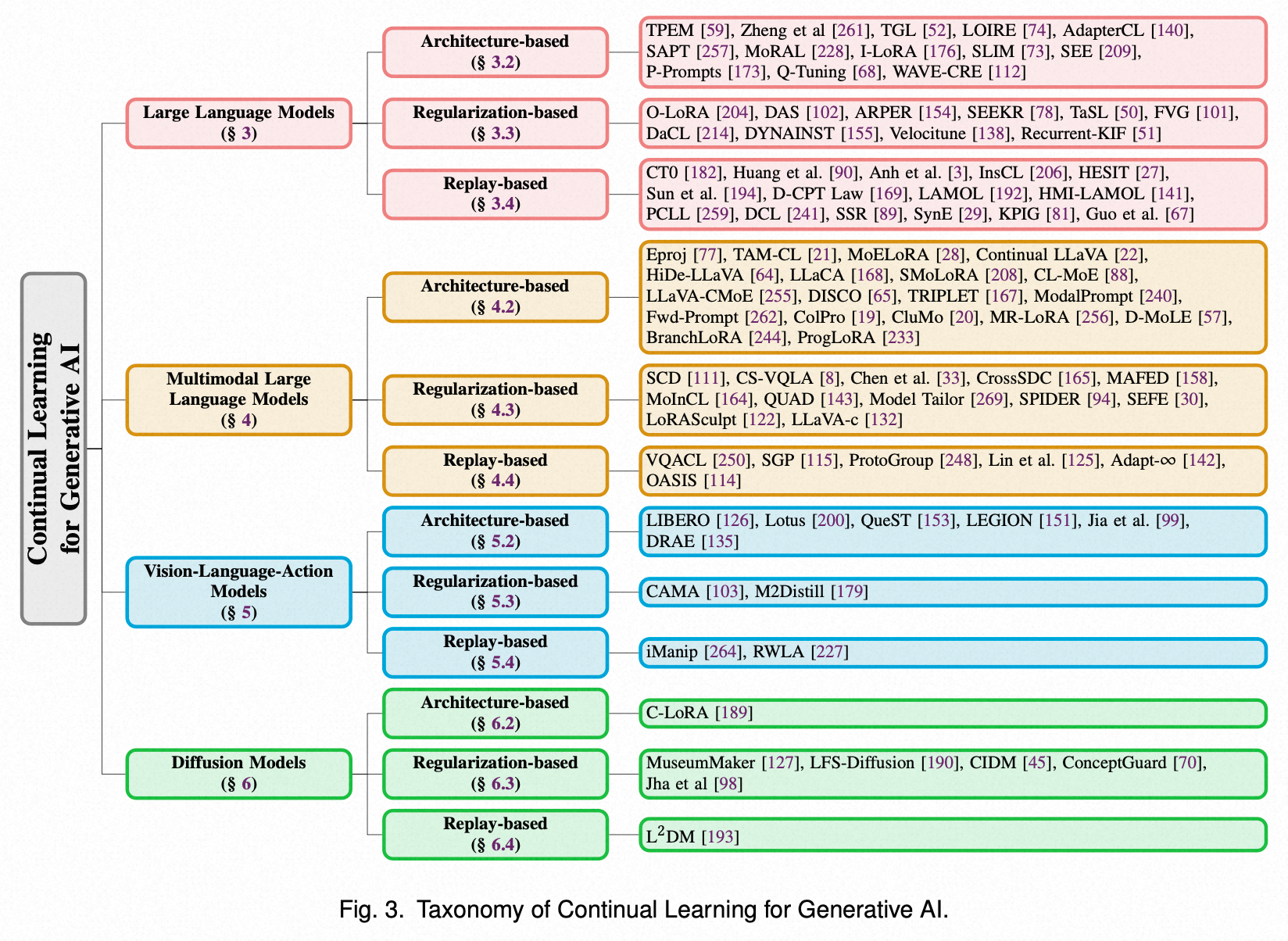
- LLM
MLLM(Multimodal Large Language Models)
- 基于架构扩展的方法,尤其是专家混合(MoE)模型,占据主导地位,即为新任务训练新的、轻量级的LoRA模块,并由一个“路由器”来智能调度。这就像给模型配备了一个可扩展的“插件工具箱”。然而,论文一针见血地指出,当前研究大多忽略了多模态的独特性,未能深入探讨不同模态知识如何被遗忘以及它们之间复杂的相互作用。
VLA(Vision-Language-Action Models)
核心应用领域:机器人。
-
VLA模型是利用大模型(通常是视觉-语言模型)来理解指令和环境,并预测机器人需要执行的动作。持续学习在VLA中的目标是让机器人能够像人一样,在动态变化的环境中不断学习和掌握新技能,而不会忘记已经学会的旧技能(例如,学会了“捡起苹果”后,去学习“拧瓶盖”,不能把捡苹果的技能忘了)。
-
VLA的持续学习越来越倾向于采用混合策略(Hybrid Strategies),即综合运用多种方法。论文特别强调了一个关键挑战:在VLA模型中,负责生成动作策略的组件比负责理解视觉和语言的对齐模块更容易发生灾难性遗忘(即容易忘记怎么做,而不是做什么)。如何动态协调不同组件的学习,是该领域一个亟待解决的难题。
学习原理
- A c t i o n = π ( V i s i o n , L a n g u a g e , S t a t e ) Action = π (Vision, Language, State) Action=π(Vision,Language,State)
- 输入 (Input):
- 视觉 (Vision): 通常是机器人摄像头捕捉到的实时图像或视频流。这告诉机器人“看到了什么”。
- 语言 (Language): 人类用户给出的自然语言指令,例如“请帮我把桌上的苹果递过来”。这告诉机器人“要做什么”。
- 本体状态 (Proprioceptive State): 机器人自身的物理状态,如关节的角度、末端执行器(夹爪)的位置和速度等。这告诉机器人“自己现在是什么姿态”。
- 输出 (Output):
- 动作 (Action): 一系列低级的控制指令,用于驱动机器人执行器。这个动作的格式有很多种,常见的有:
- 末端执行器位姿 (End-Effector Pose): 预测机器人手臂末端在下一个时间步应该移动到的三维空间位置(x, y, z)和姿态(旋转)。
- 关节角度 (Joint Angles): 直接预测机器人每个关节应该转动的角度。
- 离散化动作 (Discretized Actions): 将连续的动作空间划分为有限个“动作桶”,模型预测选择哪个桶。例如,向上移动1cm、向左移动1cm、夹爪闭合50%等。
- 动作 (Action): 一系列低级的控制指令,用于驱动机器人执行器。这个动作的格式有很多种,常见的有:
- 核心建模思想:序列到序列的预测 (Sequence-to-Sequence Prediction)
- 将图像、指令和机器人状态进行编码(tokenize),拼接成一个长的输入序列。然后像大语言模型一样,自回归地(autoregressively)生成代表动作的token序列。最后,再通过一个“动作解码器”(Action De-tokenizer)将这些动作token转换回机器人可以执行的连续控制信号。
这个建模方式的革命性在于:它统一了“理解”和“行动”,让机器人控制可以充分利用大语言模型强大的序列处理和推理能力。
- 将图像、指令和机器人状态进行编码(tokenize),拼接成一个长的输入序列。然后像大语言模型一样,自回归地(autoregressively)生成代表动作的token序列。最后,再通过一个“动作解码器”(Action De-tokenizer)将这些动作token转换回机器人可以执行的连续控制信号。
数据构造
-
人类专家采集
- 视频流 (Egocentric Vision): 人类操作员佩戴VR设备,模拟机器人“眼中”看到的一切。
- 机器人本体状态数据 (Proprioceptive State): 每个时间点的关节角度、夹爪状态等。
- 操作员的动作指令 (Operator’s Actions): 操作员在每个时间点施加给机器人的控制信号。
- 任务的语言描述 (Language Annotation): 在数据采集后,为每一段演示配上自然语言指令,例如“把红色的积木放到蓝色的碗里”。
-
仿真模拟:建立一个虚拟的、物理精确的模拟环境。具体包括
- 物理引擎 (Physics Engine): 模拟重力、摩擦力、碰撞、流体等物理规律。例如,MuJoCo, PyBullet, Isaac Gym。
- 3D渲染引擎 (3D Rendering Engine): 生成逼真的视觉图像,模拟摄像头的输入。
- 机器人模型 (Robot Model): 机器人的精确三维模型,包含其几何形状、质量、关节限制等。
- 传感器模型 (Sensor Models): 模拟各种传感器,如摄像头、深度相机、力/力矩传感器等,并能模拟传感器的噪声。
- 可交互的环境 (Interactive Environment): 包含各种可被机器人操纵的物体(桌子、杯子、积木等)。
-
数据集要求
- 大规模、多样化的数据集以保证泛化性。
- 数据集需要覆盖不同的机器人、不同的环境、不同的物体和不同的任务。
- 同一任务需要采集若干条,比如Google的RT-X数据集就汇集了来自多家机构的超过100万条机器人操作轨迹。
- 仿真环境安全,成本低,高效率
- 始终和真实世界始终存在差距—>更加逼真的环境,域随机化提高鲁棒性,使用RL训练;先sim,再基于真实训练
- 大规模、多样化的数据集以保证泛化性。
训练方式
- VLA实际就是模仿学习 (Imitation Learning),实现人类的行为克隆 (Behavioral Cloning, BC)。
- 训练流程:
- 预训练 (Pre-training): VLA模型通常不会从零开始训练。它的视觉编码器和语言模型部分会使用在海量互联网数据上预训练好的权重进行初始化(例如,使用预训练的CLIP和LLaMA)。这为模型提供了强大的基础视觉和语言理解能力。
- 行为克隆微调 (BC Fine-tuning): 使用采集到的机器人演示数据集,对整个VLA模型进行端到端的微调。模型学习将视觉和语言理解能力“接地”到具体的物理动作上。
- 部署与推理 (Deployment & Inference): 训练完成后,将模型部署到机器人上。在运行时,模型接收实时的摄像头图像和用户指令,然后自回归地生成动作序列,驱动机器人执行任务。
仿真环境的训练—>强化学习 (RL)
- 如果训练数据完全依赖于人类遥操作,就很难大批量的扩展以及泛化;因此通过强化学习,将训练效率的瓶颈从“人力”转移到了“算力”上。
- RL算法(如PPO, SAC)是数据驱动的。它们需要大量的“经验”(即 (state, action, reward, next_state) 元组)来学习。这些经验的来源是谁并不重要,只要它们来自与环境的交互即可。
- 实践操作:
- 启动成千上万个并行的仿真环境: 现代GPU物理仿真库(如NVIDIA的Isaac Gym)可以在单个GPU上同时运行数千个独立的、物理精确的机器人仿真。
- 一个“大脑”,成千上万个“身体”: 所有这些仿真环境中的虚拟机器人都由同一个中央策略网络(“大脑”)来控制。
- 并行收集经验: 在每个时间步,中央策略网络接收来自数千个仿真环境的状态,并为它们分别输出动作。然后,这数千个机器人同时执行动作,并各自获得一个奖励和下一个状态。
- 批量更新: 将这数千条并行收集到的“经验”打包成一个巨大的批次(batch),用于更新中央策略网络的参数。
Diffusion
- 总结:在扩散模型的持续学习中,基于正则化的方法是当前的主流。这主要是因为个性化定制任务的特点:每个新概念的训练数据极少(通常只有3-5张图片),任务间的差异相对较小。在这种情况下,通过正则化来保护模型强大的基础生成能力,同时微调少量参数来适应新概念,是一种非常有效且高效的策略。此外,论文也指出,该领域缺乏统一的评估基准和量化指标,是阻碍其发展的一个重要因素。
- L _ P D M = L _ m a i n + λ ∗ L _ p r i o r L\_PDM = L\_main + λ * L\_prior L_PDM=L_main+λ∗L_prior,其中 L _ m a i n L\_main L_main是新任务, L _ p r i o r L\_prior L_prior是旧任务

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)