跟着Nature Ecology&Evolution学作图:R语言ggmsa包展示多序列比对结果
这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。上面的代码是写了一个简单的循环,做了四个数据的
论文
https://www.nature.com/articles/s41559-022-01771-6#code-availability
论文没有权限下载
但是查看数据代码链接的时候发现github主页上提供了论文的下载链接
论文中的图做的都非常好看,而且提供数据和代码,我们可以找来学习
数据代码链接
https://github.com/sebepedroslab/chromatin-evolution-analysis
今天的推文我们学习一下论文中提供的画多序列比对的代码。我没有在论文中找到对应的图,只是github的链接里有数据和代码
论文中国提供的代码
library(stringr)
library(seqinr)
library(msa)
library(Biostrings)
list_ali = list(
"data/20220620/archaeal_Ntails/tails_archaea-sub-MXKK.g.fasta",
"data/20220620/archaeal_Ntails/tails_archaea-sub-mcl1.g.fasta",
"data/20220620/archaeal_Ntails/tails_archaea-sub-mcl2.g.fasta",
"data/20220620/archaeal_Ntails/tails_archaea-sub-mcl4.g.fasta"
)
for (i in 1:length(list_ali)) {
fai = list_ali[[i]]
ali = Biostrings::readAAMultipleAlignment(fai, format = "fasta")
# plot alignment
msa::msaPrettyPrint(
ali, askForOverwrite=FALSE,
shadingMode = "functional",
shadingModeArg = "chemical",
showConsensus = "none",
showLogo = "none",
shadingColors = "blues",
logoColors = "chemical",
psFonts = TRUE,
paperWidth = 32, paperHeight = 10,
output = "pdf",
file = sprintf("%s.colour.pdf",basename(fai)))
}
这里作图用到的是msa这个R包
读取多序列比对的数据使用的是Biostrings这个R包
上面的代码是写了一个简单的循环,做了四个数据的图,我试着做其中一个图,但是遇到了报错
Error in texi2dvi(texfile, quiet = !verbose, pdf = identical(output, "pdf"), :
unable to run pdflatex on 'tails_archaea-sub-MXKK.g.fasta.colour.tex'
LaTeX errors:
! Paragraph ended before \inf@@get was complete.
<to be read again>
\par
l.26 ...cal/Temp/RtmpagEAWD/seq397c6ecb2093.fasta}
! Misplaced alignment tab character &.
\msfline ->\par &
& & & @
l.26 ...cal/Temp/RtmpagEAWD/seq397c6ecb2093.fasta}
! Misplaced alignment tab character &.
\msfline ->\par & &
& & @
l.26 ...cal/Temp/RtmpagEAWD/seq397c6ecb2093.fasta}
! Misplaced alignment tab character &.
\msfline ->\par & & &
& @
l.26 ...cal/Temp/RtmpagEAWD/seq397c6ecb2093.fasta}
搞不懂是什么原因
R语言里做多序列比对的图还有更好的选择使用 ggmsa 这个R包
安装
devtools::install_github("YuLab-SMU/ggmsa")
这里R语言必须是4.1以上的
输入数据是比对好的fasta文件的路径
作图代码
library(ggmsa)
fai<-"data/20220620/archaeal_Ntails/tails_archaea-sub-MXKK.g.fasta"
pdf(file = "aligned_fasta.pdf",width = 9.4,height = 4)
ggmsa(fai)+
geom_seqlogo() + geom_msaBar()
dev.off()
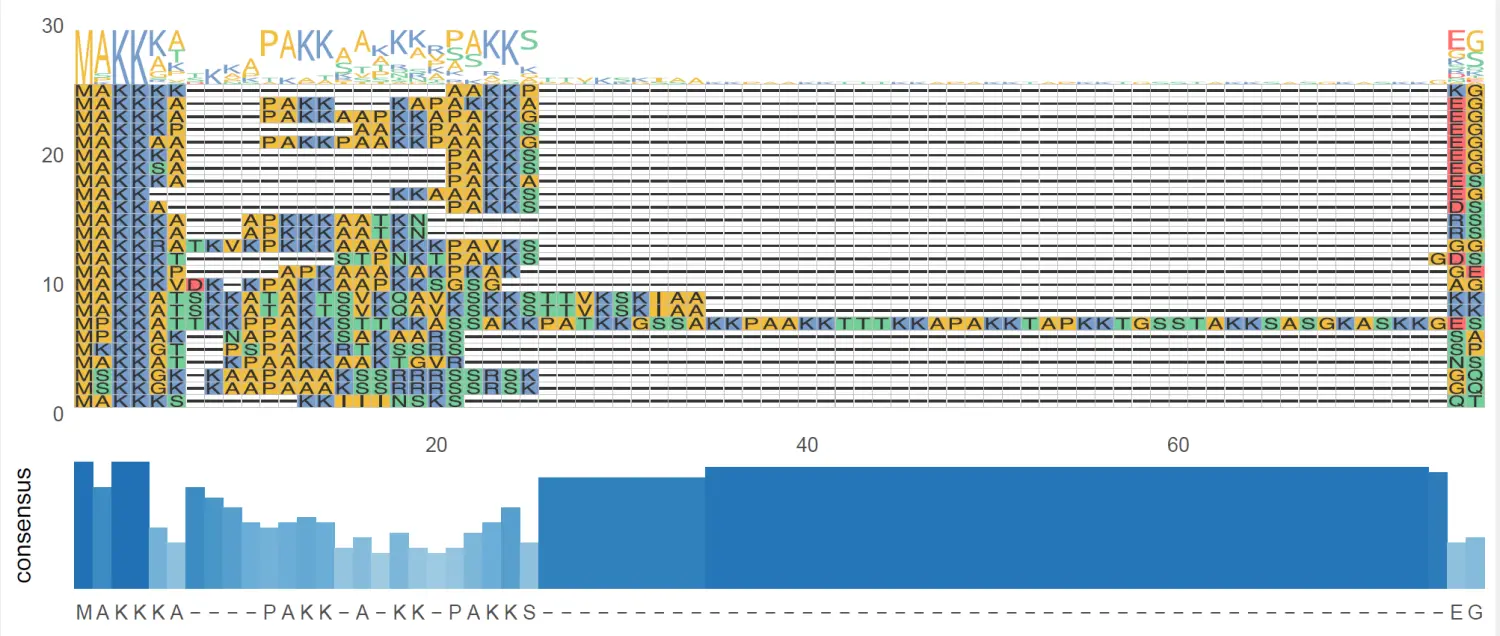
image.png
这个我认为比论文中提供的代码出图要好看的多
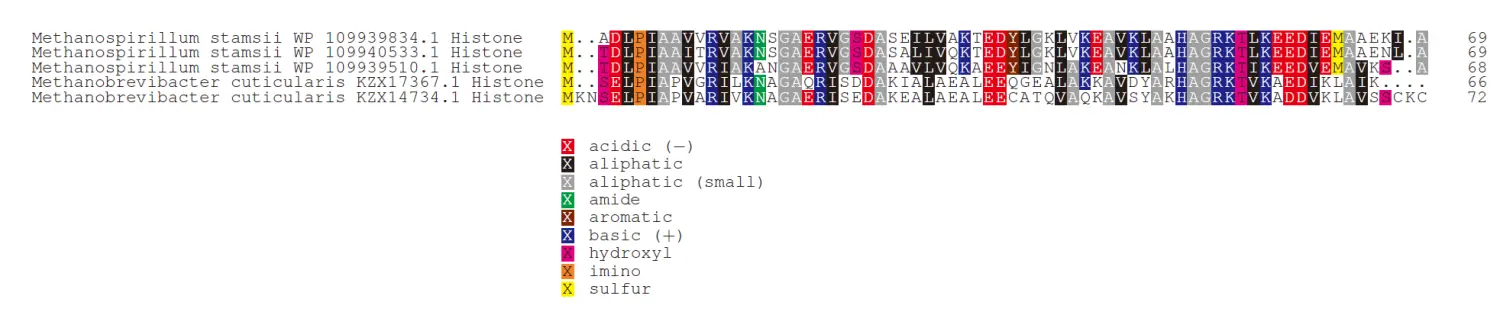
这个是论文中的代码出的图
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 5
5 0
0- 0



 已为社区贡献229条内容
已为社区贡献229条内容

所有评论(0)