seekdb × AI 平台-打造真正的全链路:AI 应用开发者的“全能数据库”
OceanBase开源了首款AI原生数据库seekdb,整合了向量、文本和结构化数据的混合搜索能力,大幅简化AI应用开发。该数据库通过单引擎实现多模态数据统一处理,支持RAG应用、AI Agent记忆体等功能,并兼容MySQL协议和主流AI框架。其轻量级特性支持嵌入式部署,显著降低开发门槛。seekdb的推出改变了传统"三库拼装"的复杂架构,为AI应用提供统一的数据处理解决方案
11月18日,OceanBase开源了其首款AI原生数据库seekdb,这款专注于为AI应用提供高效混合搜索能力的数据库,正在悄然改变AI应用的开发方式。

AI 应用的核心不是模型本身,而是数据能否被高效检索、理解和关联。然而,在很长一段时间里,AI 应用的开发都被一种繁琐的“三库拼装架构”所束缚:
- 关系型数据库存元数据
- 向量数据库存 embedding
- 搜索引擎(ES)做全文检索
|
数据类型 |
旧工具 |
目的 |
|
元数据(结构化) |
MySQL / PostgreSQL |
记录文档信息、对话记录等 |
|
文本全文检索 |
Elasticsearch |
文本倒排检索 |
|
向量检索 |
Milvus / Chroma |
语义召回 |
开发者不得不同时维护三个完全不同的系统,自己拼接召回链路,再用应用层逻辑做精排,导致:
- 架构复杂
- 成本高
- 数据不一致
- 查询链路冗长且低效
- 开发和调试体验差
11 月 18 日,OceanBase 发布开源的 seekdb,正是要改变这一切。
它通过统一向量、文本、结构化/半结构化数据,把原本分裂的检索能力全部合并进一个数据库,让 AI 应用第一次可以用一种方式、一个引擎处理所有数据。
一.什么是seekdb?
seekdb(OceanBase seekdb)是一款AI原生混合搜索数据库,它统一了向量(vector)、文本(text)、结构化(structured)与半结构化数据(semi-structured),在一个单引擎中支持混合检索。简单来说,它是一个像SQLite一样可嵌入、像Elasticsearch一样做全文检索、像向量数据库一样做embedding搜索,又能支持结构化/半结构化查询的"全能型"数据库。
1.1seekdb 如何改变开发方式?
seekdb 提出了一套新的 AI 数据范式:
“一个数据库 = 向量库 + 全文库 + 文档库 + SQL 事务库 + AI 推理引擎”
它实现的是 从数据到检索、从模型到推理的全链路统一。
AI 框架过去存在一个巨大的缺口:
✔ 模型能力强
❌ 数据检索能力弱
❌ 缺少统一的存储引擎
seekdb 完全补上了这个缺口。
结果是:
- LangChain / LlamaIndex 的 RAG 链路变短
- Dify 可以把 seekdb 作为元数据库 + 向量数据库
- HuggingFace embedding 流程更简单
- AI Agent 有了真正的“长期记忆体”
生态反向增强了 seekdb 的价值,它也在增强生态本身。
从更深层的角度看,seekdb 的价值并不仅仅在于“整合了多种能力”,而在于它 重新定义了 AI 应用的数据组织方式。传统 AI 应用往往依赖多个外部系统拼接能力,而 seekdb 将所有关键能力收敛到同一引擎后,使得应用层不再需要负责数据融合、索引管理、模型调用调度等复杂逻辑。开发者只需面向一个数据库,就能获得跨文本、向量、结构化数据的统一检索能力。这种范式转变,让应用从“外部编排”走向“库内协同”,显著降低了心智负担,也让 AI 系统具备了更强的一致性和可维护性。更重要的是,随着 LangChain、Dify、Cursor 等生态的反向适配,seekdb 不再只是一个数据库,而成为 AI 应用开发框架的底层基座,推动整个行业从碎片化架构向统一化数据范式演进。
1.2 核心特性
- AI原生混合搜索能力:支持向量、全文、标量及空间地理数据的统一混合搜索,通过粗排+精排机制,保持毫秒级响应,支持百亿级向量检索。
- 极简部署:最低只需1核CPU、2GB内存即可运行,支持pip一键安装,Docker部署,以及嵌入式模式,真正做到开箱即用。
- 开发者友好:提供Python SDK、MySQL兼容协议,支持Navicat等常用数据库管理工具,兼容30余种主流AI框架,包括FastGPT、RAGFlow、LangChain、Dify等。
- AI Function功能:内置AI函数,可以在数据库内直接调用大模型或向量模型,完成数据的嵌入和推理,实现真正的"AI原生"。

部署层面,它同时支持嵌入式与服务器两种模式,嵌入式模式可直接集成至 Python 应用,极大降低个人开发的接入门槛;核心能力上,其多模数据与索引层全面兼容向量、文本、JSON、GIS 等多类型数据,内置 HNSW/IVF 向量索引、BM25 全文索引、混合索引、JSON 索引及主键 / 二级索引、GIS 索引等丰富索引体系,并结合索引量化、多分词器适配等优化手段,保障各类数据的高效检索;
多模计算层则针对混合负载场景深度优化,不仅支持向量、全文、标量条件的混合搜索以提升 RAG 场景查询精度,还提供 AI Function 实现库内实时推理,同时具备完整的 ACID 事务、MVCC 多版本并发能力,搭配智能查询优化器、自适应执行引擎与灵活的 PL UDF 功能,可适配多样化业务需求;
接口层面,seekdb 兼容 MySQL 原生驱动,提供基于 SQL 的多模数据统一查询语言,还封装了更易用的向量库 / 混搜 SDK,适配 LangChain、LlamaIndex、Dify 等近 30 种应用开发框架,并通过 MCP Server 实现与 AI 生态的无缝对接,为开发者提供从数据存储、检索到 AI 协同的全链路解决方案。
1.3seekdb能做什么?
1. 构建高效RAG应用
seekdb完美解决了传统RAG应用中数据架构复杂的问题。过去,为了实现精准检索,通常需要维护三套完全不同的系统:MySQL/PostgreSQL存元数据、Milvus/Chroma存向量、Elasticsearch做全文检索。这种拼图式架构不仅维护成本高,还难以保证事务一致性。
seekdb通过将向量、文本、结构化/半结构化数据全部整合在一个数据库中,一条SQL语句就能完成多路召回和精排,大大简化了RAG应用的开发和维护。
2. AI Agent的记忆体
seekdb能同时存储结构化的对话记录和非结构化的向量记忆,非常适合用来给AI Agent做长期记忆。无论是个人助手还是企业级智能客服,都能借助seekdb实现更智能、更连贯的交互体验。
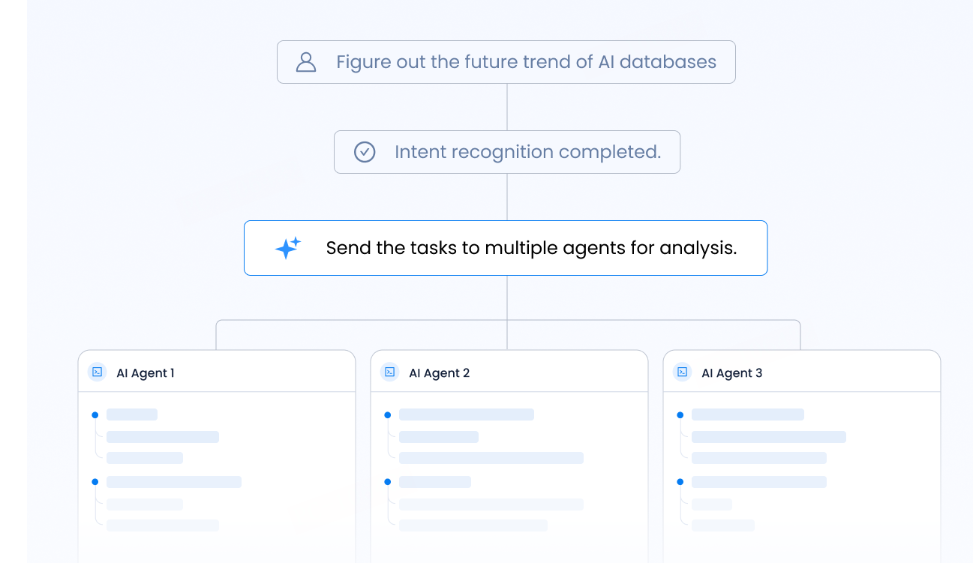
3. 本地知识库与边缘AI应用
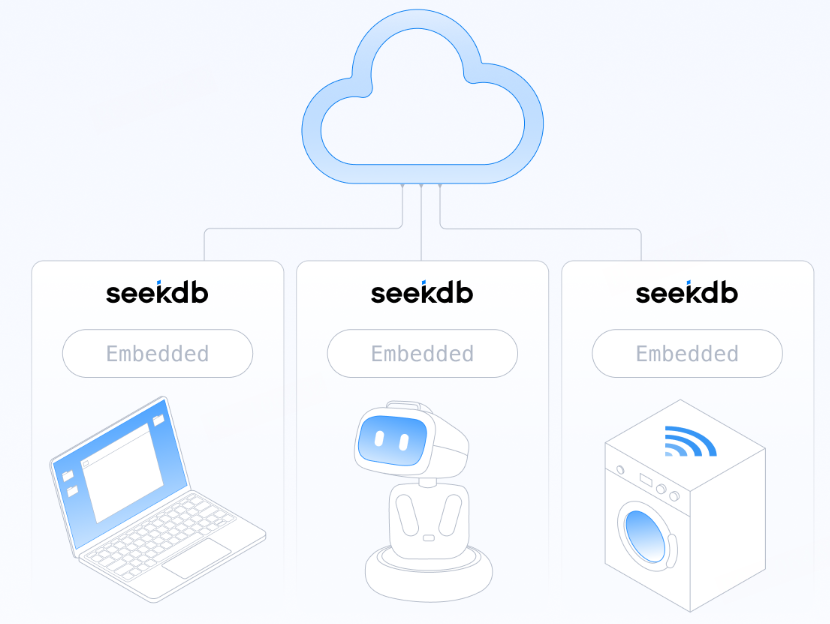
由于其轻量级特性,seekdb特别适合个人或小团队的本地知识库,以及资源受限的边缘设备上的AI应用。无论是手机、车机还是工业网关,都能轻松运行seekdb,实现本地化的智能检索。
4. 语义搜索引擎
seekdb的Semantic Index语义搜索功能,结合向量相似度和全文检索,能够实现更精准的搜索结果,特别适合需要理解用户意图的搜索场景。
二.如何玩转seekdb?
2.1快速上手
seekdb的安装和部署极其简单,支持多种方式:
Python SDK安装:
pip install pyseekdb
Docker部署:
docker run -d --name seekdb -p 2881:2881 oceanbase/seekdb:latest编写简单demo调用初步尝试
import pyseekdb
from pyseekdb import DefaultEmbeddingFunction, HNSWConfiguration
client = pyseekdb.Client()
collection = client.create_collection(name="notes")
# 添加文档
docs = ["今天跑了10公里,状态不错。", "Mapbox的polyline编码可以有效减少地址长度。"]
ids = ["run1", "map1"]
metas = [{"tag": "run"}, {"tag": "map"}]
collection.add(ids=ids, documents=docs, metadatas=metas)
# 查询
query = "跑步 状态"
res = collection.query(query_texts=query, n_results=2)2.2与Dify集成
最新的Dify 已正式兼容MySQL数据库,这意味着我们可以把Dify的元数据库和向量数据库都切换成seekdb。只需修改.env文件中的配置:
# 如果既作为元数据库又是向量数据库
DB_TYPE=mysql
# 如果仅作为向量数据库
VECTOR_STORE=oceanbase注意配置
# 设置数据库类型为 mysql, 并且修改元数据库连接信息
DB_TYPE=mysql
DB_USERNAME=root
DB_HOST=seekdb
DB_PORT=2881
DB_DATABASE=test
# 设置向量存储为 OceanBase
VECTOR_STORE=oceanbase
# 修改OCEANBASE的连接信息为seekdb的对应连接信息
OCEANBASE_VECTOR_HOST=seekdb
OCEANBASE_VECTOR_USER=root
# 修改 COMPOSE_PROFILES 为 seekdb
COMPOSE_PROFILES=seekdb使用 Docker Compose 即可一键构建并启动 Dify 服务,只需执行以下命令:
docker compose up --build -d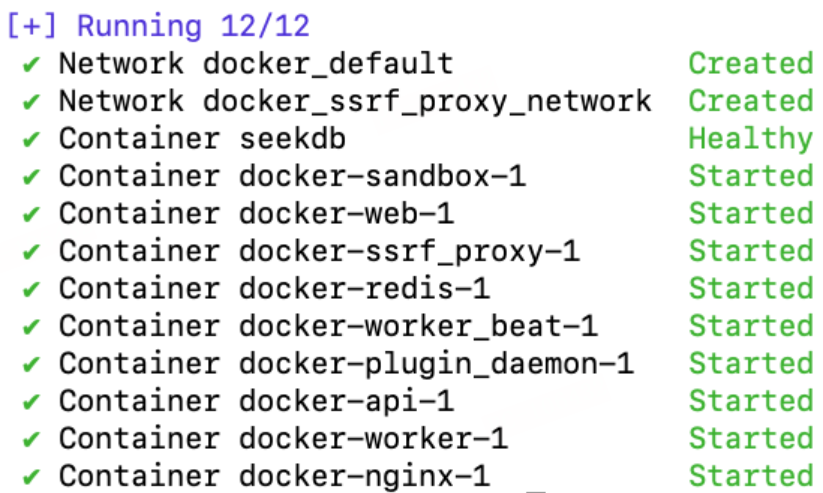
容器启动后会自动执行数据库初始化和迁移。通过查看 api 服务的日志,确认迁移成功。
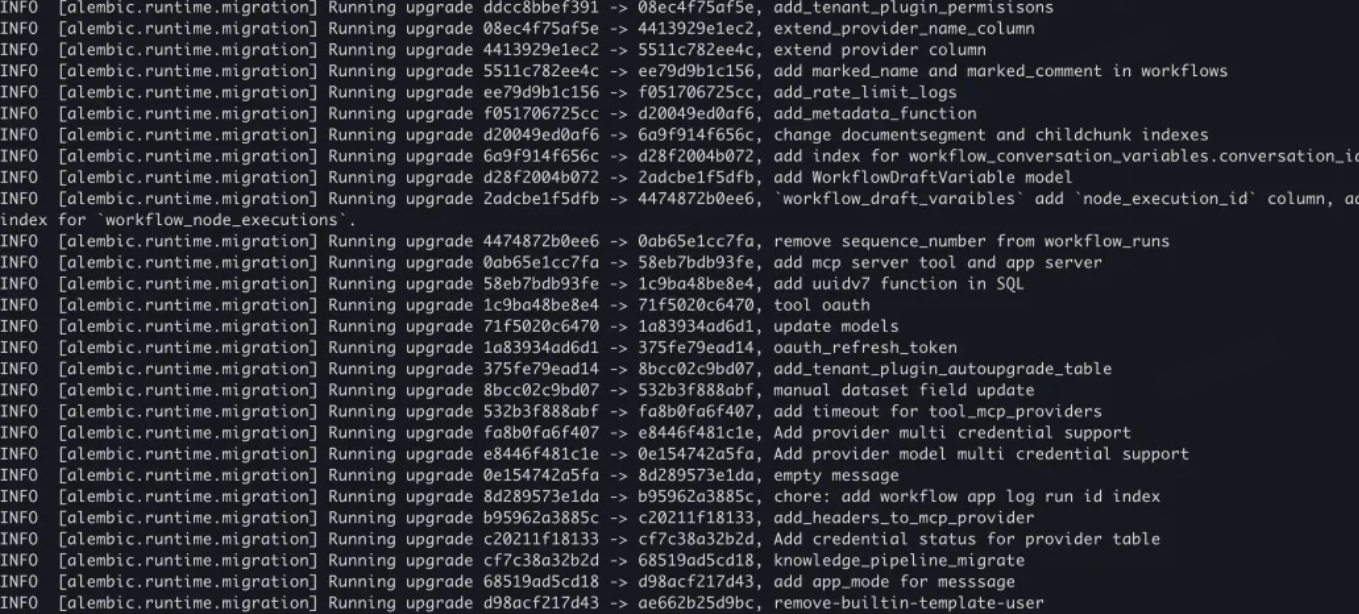
访问 Dify 控制台: 打开浏览器访问 http://localhost。
启动之后,dify会帮seekdb设置一个默认密码:difyai123456
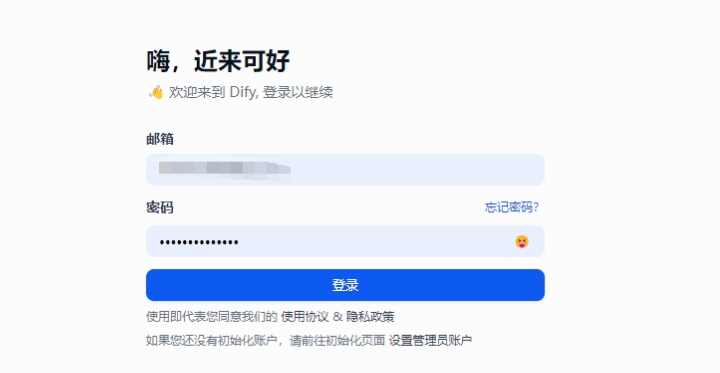
配置成功后,即可创建知识库,正常使用了!
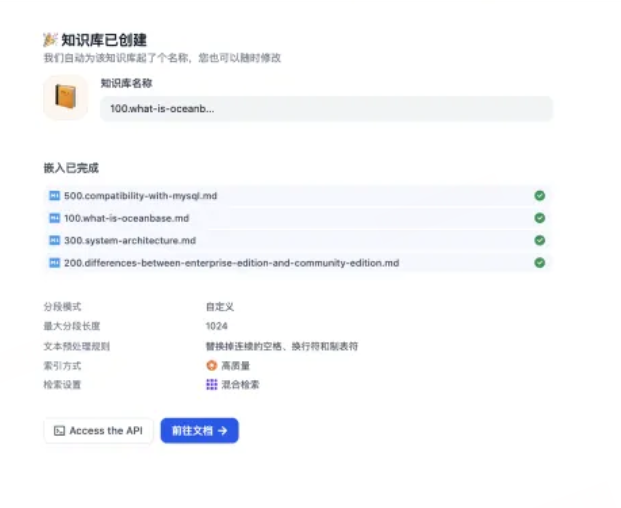
此外,seekdb还原生支持 MySQL 协议,因此可以直接使用 Navicat 进行连接和管理。作为一款经典且功能强大的数据库可视化工具,Navicat 能够让开发者以更直观的方式浏览数据表、执行查询以及调试接口,大幅提升整体开发与调试效率。
2.3 作为MCP Server
作为 MCP Server 使用,能够无缝接入 Trae、Claude Code、Cursor 等任意支持 MCP 协议的工具或平台。这使得系统不仅具备数据访问能力,还能在多种 AI 辅助开发环境中扩展其自动化能力与上下文集成能力,显著提升开发体验与工作效率。

添加并配置 MCP Servers。在界面中点击 Add Custom MCP,然后填写对应的配置文件。
填写完成后点击「确认」即可。需要注意:
path/to/your/mcp-oceanbase/src/oceanbase_mcp_server必须替换为 oceanbase_mcp_server 目录的绝对路径;OB_HOST、OB_PORT、OB_USER、OB_PASSWORD、OB_DATABASE则需分别替换为你自己的数据库连接信息。
确保所有参数填写正确后,即可正常连接并使用 MCP Server。
{
"mcpServers": {
"oceanbase": {
"command": "uv",
"args": [
"--directory",
"/path/to/your/mcp-oceanbase/src/oceanbase_mcp_server",
"run",
"oceanbase_mcp_server"
],
"env": {
"OB_HOST": "***",
"OB_PORT": "***",
"OB_USER": "***",
"OB_PASSWORD": "***",
"OB_DATABASE": "***"
}
}
}
}
三. 生态互补:seekdb 与 AI 平台的共生关系
随着 AI 开发从“模型为中心”逐渐转向“数据与检索驱动”,seekdb 在 AI 生态中扮演着一个越来越关键的角色。它不仅是一个混合搜索数据库,更是连接 AI 工具、模型框架与应用系统的 统一数据基础设施。这一特性让 seekdb 与各类 AI 平台形成了天然的共生关系:平台需要高效的多模数据能力,而 seekdb 正好提供了它们长期缺失的统一数据库引擎。
3.1 AI 平台的能力补全:让框架更高效,让数据库更智能
在 LangChain、LlamaIndex、Dify、HuggingFace 等主流 AI 开发框架中,数据处理链路往往是分裂的:
结构化信息由 SQL 数据库存储、向量由向量库存储、文本检索依赖搜索引擎,各组件之间需要额外逻辑进行融合。这种分布式“拼装式架构”不仅增加复杂度,也容易成为性能瓶颈。
seekdb 的多模态统一让这一切变得异常简单:
- 一条 SQL 完成全文 + 向量 + 元数据混合搜索
- 同库存储结构化、半结构化与embedding
- AI Function 直接在库内做 embedding / 推理
- MySQL 协议兼容、低成本替换传统数据库
于是,在这些平台中:
- LangChain / LlamaIndex 的 RAG 召回链路变短
- Dify 可以同时把 seekdb 作为元数据库 + 向量数据库
- HuggingFace 的 embedding 流程无需额外外部向量库
- 企业系统可以更低成本构建 Agent 的长期记忆体
seekdb 以数据库的身份补全了 AI 框架长期缺失的“统一数据引擎”,而这些框架又放大了 seekdb 的生态影响力,互相成就。
3.2 与 MCP 生态深度融合:让数据库成为 AI 工具的“插件能力”
Model Context Protocol(MCP)的兴起,让 AI 模型能够像插件一样调用外部系统。seekdb 提供官方 MCP Server,使其能直接接入 Cursor、Claude Code、Trae 等新一代 AI IDE 与工具。
这意味着:
- AI 工具能主动读取数据库结构
- 自动生成 SQL、调试索引、分析存储
- 在编程环境中直接对 seekdb 做查询/写入
- 作为 Agent 的上下文“外部大脑”实时使用
换句话说,数据库第一次变成了 AI 可直接操控的外部能力。MCP 工具因此获得强大的数据访问能力,而 seekdb 则获得更深层次的生态入口,从一个“存储系统”跃升为“AI 开发工具链的组成部分”。未来,随着 MCP 被更多平台采用,seekdb 将成为更多 Agent、IDE 与 AI 工具的默认后端存储。

四.结语
seekdb的出现,标志着AI应用开发进入了一个新的阶段。它不仅解决了多模态数据融合的技术难题,更通过极简的部署方式和友好的开发体验,降低了AI应用的开发门槛。无论是个人开发者还是企业团队,都能借助seekdb快速构建高效、智能的AI应用。
现在,OceanBase正在举办seekdb征文活动,邀请开发者分享使用seekdb的创新实践和体验。参与活动不仅能展示自己的技术实力,还有机会赢取丰厚奖励。详情请访问:https://open.oceanbase.com/blog/23850586944
让我们一起探索seekdb的无限可能,共同推动AI应用的创新与发展!
- GitHub仓库:https://github.com/oceanbase/seekdb

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)