强化学习-笔记
定义:是智能体在与环境交互中来实现目标的一种算法,这里的强化是强化智能体的策略 — 让策略更倾向于选择高价值动作最终实现累积奖励期望的最大化。基本过程:智能体agent看到状态St,采取动作At施加到环境中,得到奖励rt,同时环境转移为St+1,简称sars。关键要素:感知、决策、奖励。
目录
1.3 马尔可夫决策过程(Markov decision process)-MDP
一、基础篇
1.1 初探
什么是强化学习
定义:是智能体在与环境交互中来实现目标的一种算法,这里的强化是强化智能体的策略 — 让策略更倾向于选择高价值动作最终实现累积奖励期望的最大化。
基本过程:智能体agent看到状态St,采取动作At施加到环境中,得到奖励rt,同时环境转移为St+1,简称sars。
关键要素:感知、决策、奖励
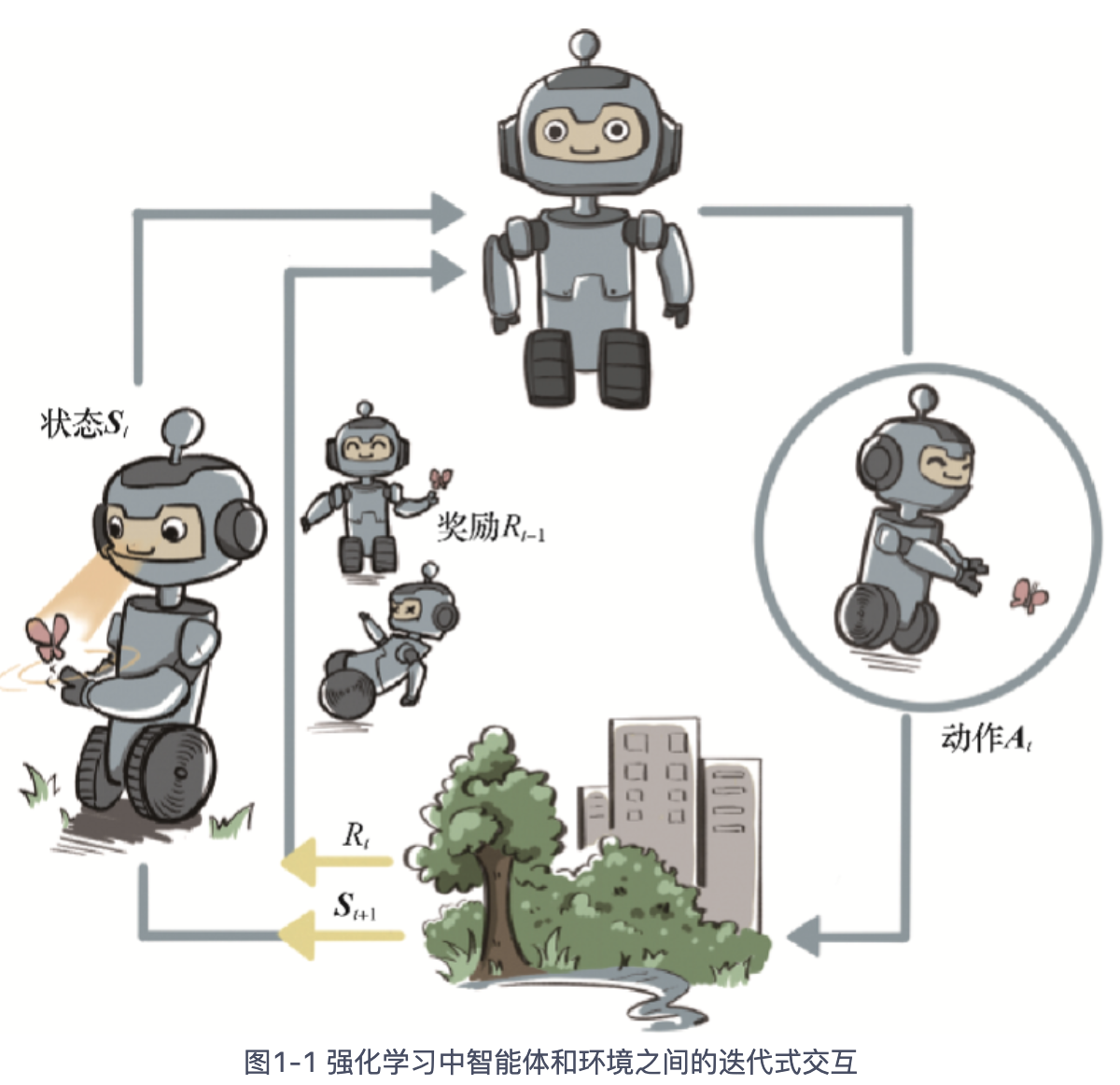
强化学习的环境
与智能体进行交互的环境是一个动态的随机过程,其未来状态的分布由当前状态和智能体决策的动作来共同决定,并且每一轮状态转移都伴随着两方面的随机性:一是智能体决策的动作的随机性,二是环境基于当前状态和智能体动作来采样下一刻状态的随机性。
对于一个随机过程,其最关键的要素就是状态以及状态转移的条件概率分布。这就好比一个微粒在水中的布朗运动可以由它的起始位置以及下一刻的位置相对当前位置的条件概率分布来刻画。环境的下一刻状态的概率分布由当前状态和智能体的动作来共同决定,用最简单的数学公式表示则是:
![]()
强化学习的目标
即使环境和智能体策略不变,智能体的初始状态也不变,智能体和环境交互产生的结果也很可能是不同的,对应获得的回报也会不同。因此,在强化学习中,我们关注回报的期望,并将其定义为价值(value),这就是强化学习中智能体学习的优化目标。
价值的计算有些复杂,因为需要对交互过程中每一轮智能体采取动作的概率分布和环境相应的状态转移的概率分布做积分运算。强化学习和有监督学习的学习目标其实是一致的,即在某个数据分布下优化一个分数值的期望。不过,经过后面的分析我们会发现,强化学习和有监督学习的优化途径是不同的。
强化学习的数据
监督学习和强化学习在数据层面的区别:
监督学习:训练数据静态不变
强化学习:训练数据只有在智能体采取动作后才能被观测到,并且智能体策略不同、采取的动作不同,看到的环境数据都是不同的。
因此,在RL中有占用度量的概念,即state-action的联合分布。占用度量=策略,改变策略即改变占用。一个策略对应的价值其实就是一个占用度量下对应的奖励的期望,因此寻找最优策略对应着寻找最优占用度量。
强化学习的独特性
|
类型 |
数据 |
目标 |
本质 |
|---|---|---|---|
|
监督学习 |
静态 |
损失最小 |
优化模型 拟合label |
|
强化学习 |
动态 |
奖励最大 |
优化模型 拟合策略 |
监督学习拟合label;强化学习拟合策略。强化学习也有最优轨迹的概念,但是最优轨迹不一定唯一,而最佳策略是唯一的。
共性:优化某个分布下的期望,监督学习的分布是指(固定特征, 预测)联合分布,强化学习的分布是指(随机特征, 动作)联合分布。
1.3 马尔可夫决策过程(Markov decision process)-MDP
马尔科夫是环境建模思想
价值函数是MP中S的评估工具
强化学习是建模价值函数 以此 提高采样价值的算法
贝尔曼方程是强化学习损失计算的理论基础
TD和MC是两种强化学习的思路
价值函数与马尔科夫奖励过程(MRP)是 「评估工具」 与 「评估对象」 的紧密关联关系 ——MRP 是定义了状态转移、即时奖励的 “基础模型”,而价值函数是专门用于量化 MRP 中 Gt 的核心工具,二者共同构成了 “描述状态规律” 到 “评估状态价值” 的完整逻辑链。
1.3.2 马尔科夫过程
如果一个随机过程的当前状态只取决于上一时刻的状态时,该随机过程被称为具有马尔可夫属性,成为马尔科夫过程,也被成为马氏链。用公式表示为:
![]()
也就是说,当前状态是未来状态的充分统计量。需要明确的是,具有马尔可夫性并不代表这个随机过程就和历史完全没有关系。因为St本身就和历史有关。
MDP通常用<S,P> 表示,其中S是状态集合,P是转移概率。例如一个6状态的MDP如图所示:
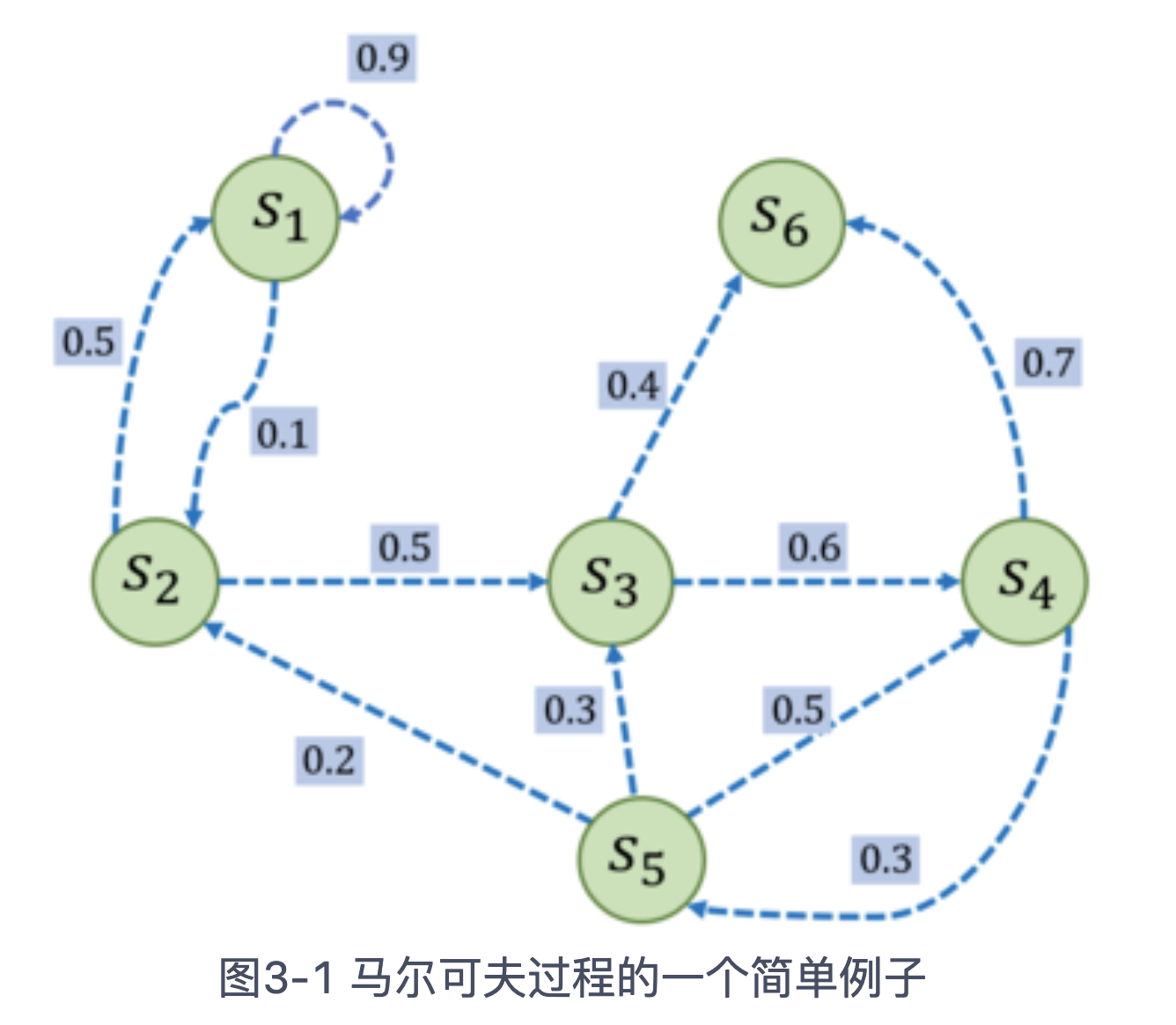
解释:S3的出度=2,40%的概率转到S6,60%的概率转到S4。具体而言,其转移矩阵为:

MDP采样:给定一个MDP和一个任意状态,我们可以基于P矩阵得到一个序列,即采样。
1.3.3 马尔科夫奖励过程
在MDP的基础上增加奖励和奖励的折扣因子,则构成马尔科夫奖励过程(MRP),MRP用<S,P,r,γ>表示,其中r表示奖励,γ表示折扣因子:
- S是有限状态的集合。
- P是状态转移矩阵。
- r是奖励函数,某个状态的奖励 指转移到该状态时可以获得奖励的期望。
- γ是折扣因子(discount factor),γ的取值范围为0-1。
在此基础上,我们定义奖励回报Gt为(注意这里的Rt是样本值,不是期望):
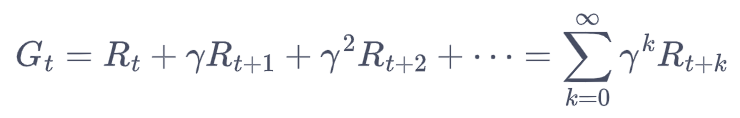
我们在上述例子的基础上增加奖励,可以获得MRP的示意图如下:
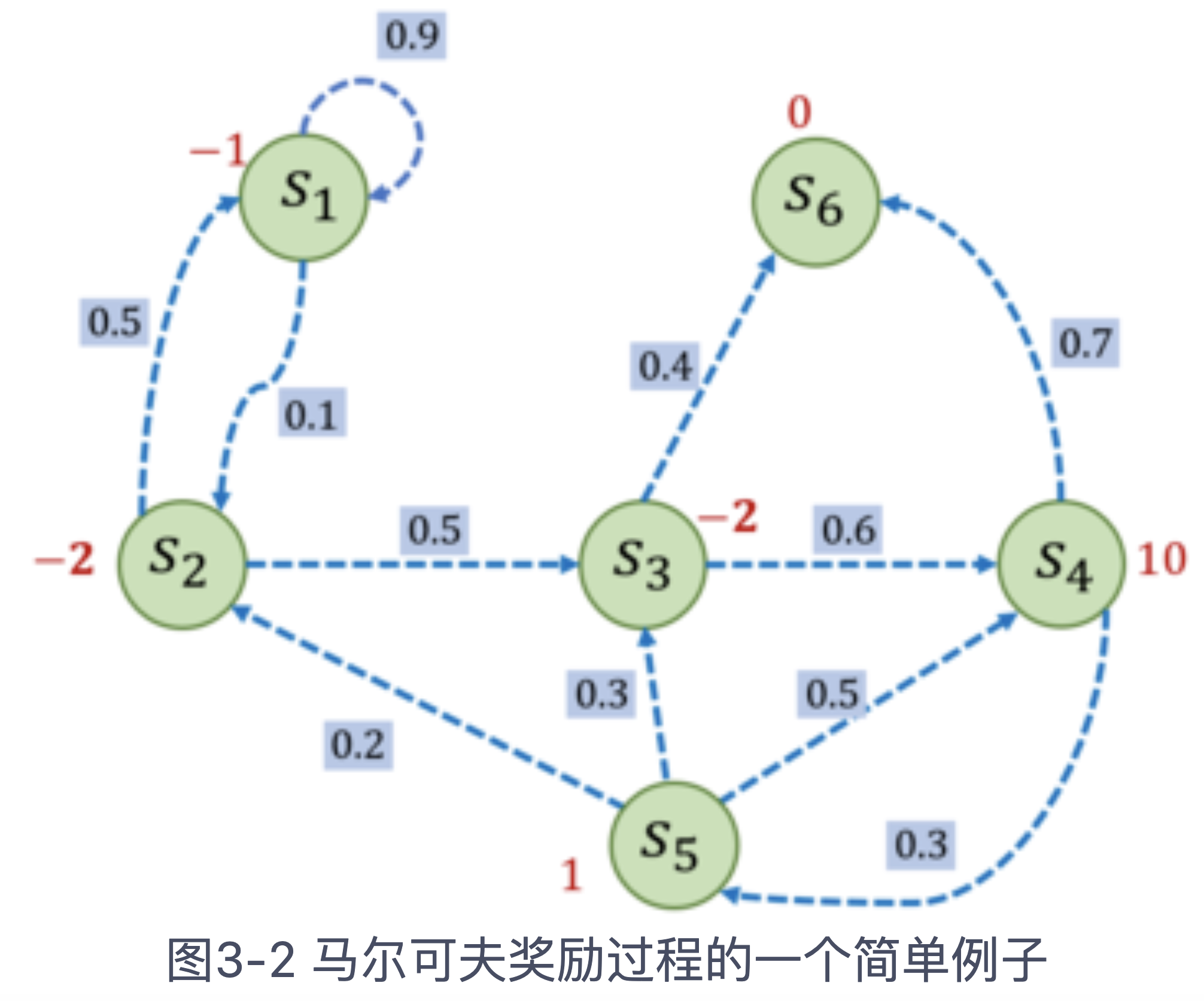
假设我们采样到一个MDP链为s1-s2-s3-s6,折扣因子=0.5 可以计算S1的回报为:
-1 + 0.5*-2 + 0.5*0.5*-2 + 0 = -1 -1 -0.5 = -2.5
假设我们采样到一个MDP链为s1-s2-s3-s4-s6,折扣因子=0.5 可以计算S1的回报为:
-1 + 0.5*-2 + 0.5*0.5*-2 + 0.5*0.5*0.5*10 + 0 = -1 -1 -0.5 = -1.25
可以看到,采样到不同序列,计算的状态不会差异很大。某个状态回报Gt的期望值就定位为该状态的价值Value。所有状态的价值一起构成成价值函数V(S),输入为S,输出为V。
小结:Rt(单步奖励)->Gt(累计奖励)->V(s)(状态价值),这里的一个重点在于基于Gt定义回报,而不是r(s)-即单步,也不是整个链条的累计和,是一个累计衰减求和。
价值函数
价值函数的定义为:
![]()
即以s为出发点,能获得的回报的期望。将Gt展开,可以得到其转移公式。
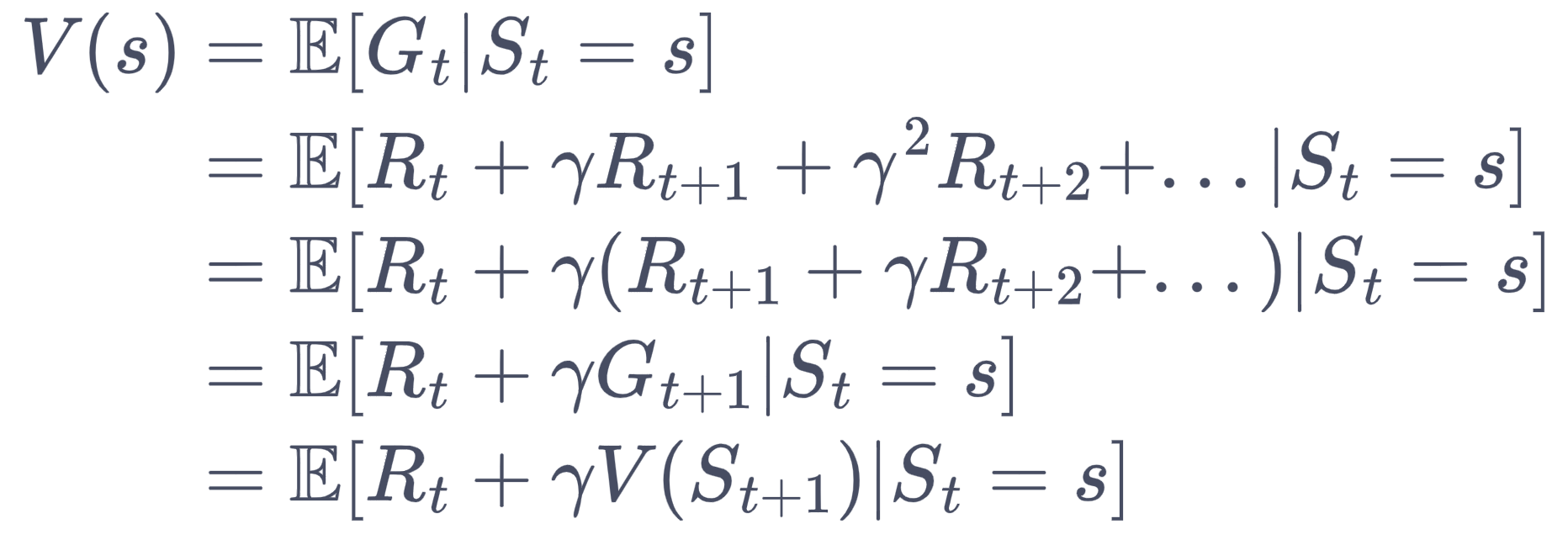
Rt的期望用r(s)表示,进一步把对V(St+1)的期望分解为加权求和:
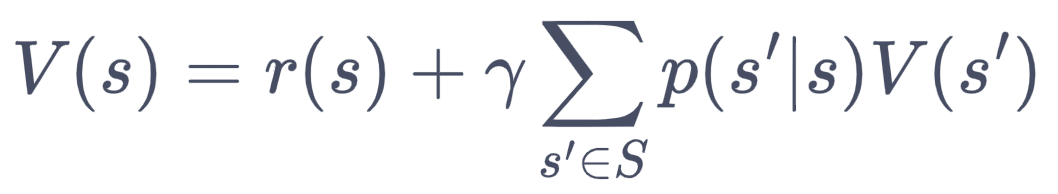
注意这里的s和s'的状态空间是相同的。上式就是贝尔曼方程,写成矩阵形式就是:
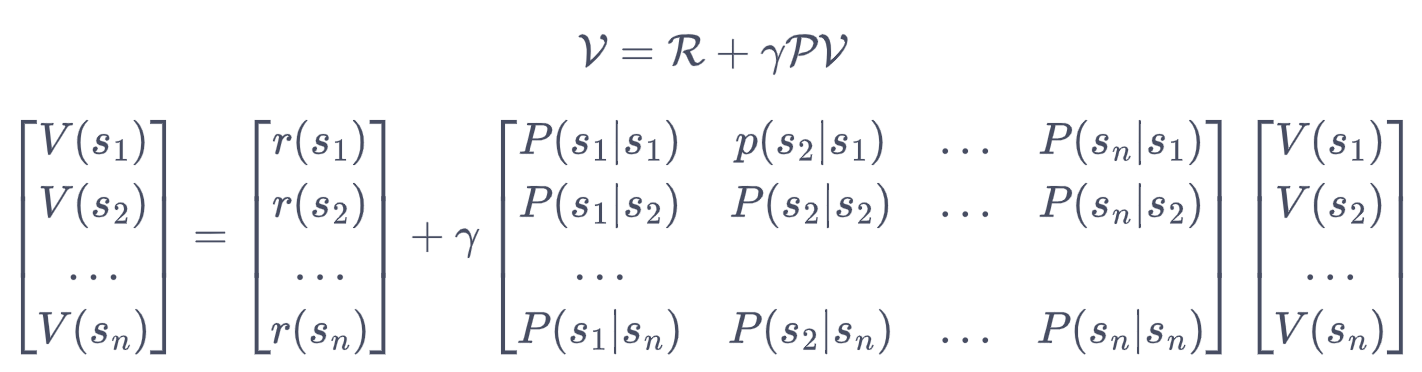
解析法求解结果为:
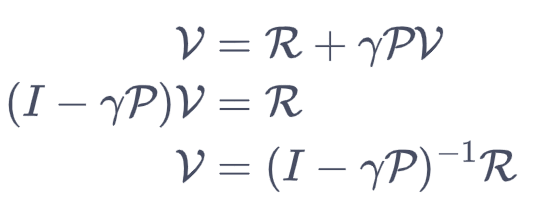
使用计算机,可以计算价值函数为:
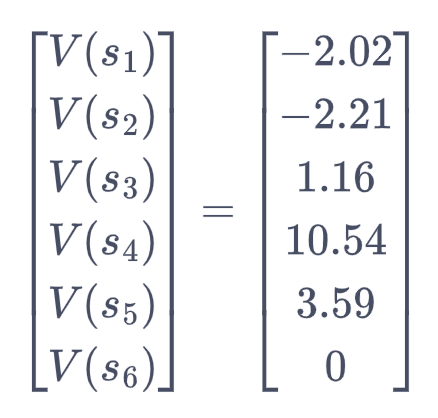
可以做一个简单的验证,例如计算S4的价值
V(S4) = r(S4) + 0.5*[70%*V(S6) + 30%*V(S5) ]= 10 + 0.5(0 + 1.077) =10.5385
1.3.4 马尔科夫决策过程
上述MP、MRP过程都是自发的随机过程,如果引入一个外界刺激来共同推进这个随机过程,就有了马尔科夫决策过程(MDP)这个外界的刺激被称为智能体的动作(action)。MDP由5元组构成<S, A, P, r, γ>。
- S 是状态的集合;
- A是动作的集合;
- γ 是折扣因子;
- r(s,a) 是奖励函数,此时奖励可以同时取决于状态S和动作A,在奖励函数只取决于状态时,则退化为MRP;
- P(s'|s,a) 是状态转移函数,表示在状态执行动作之后到达状态的概率。
MDP是一个不断进行的过程,智能体和环境之间的交互过程如图所示:
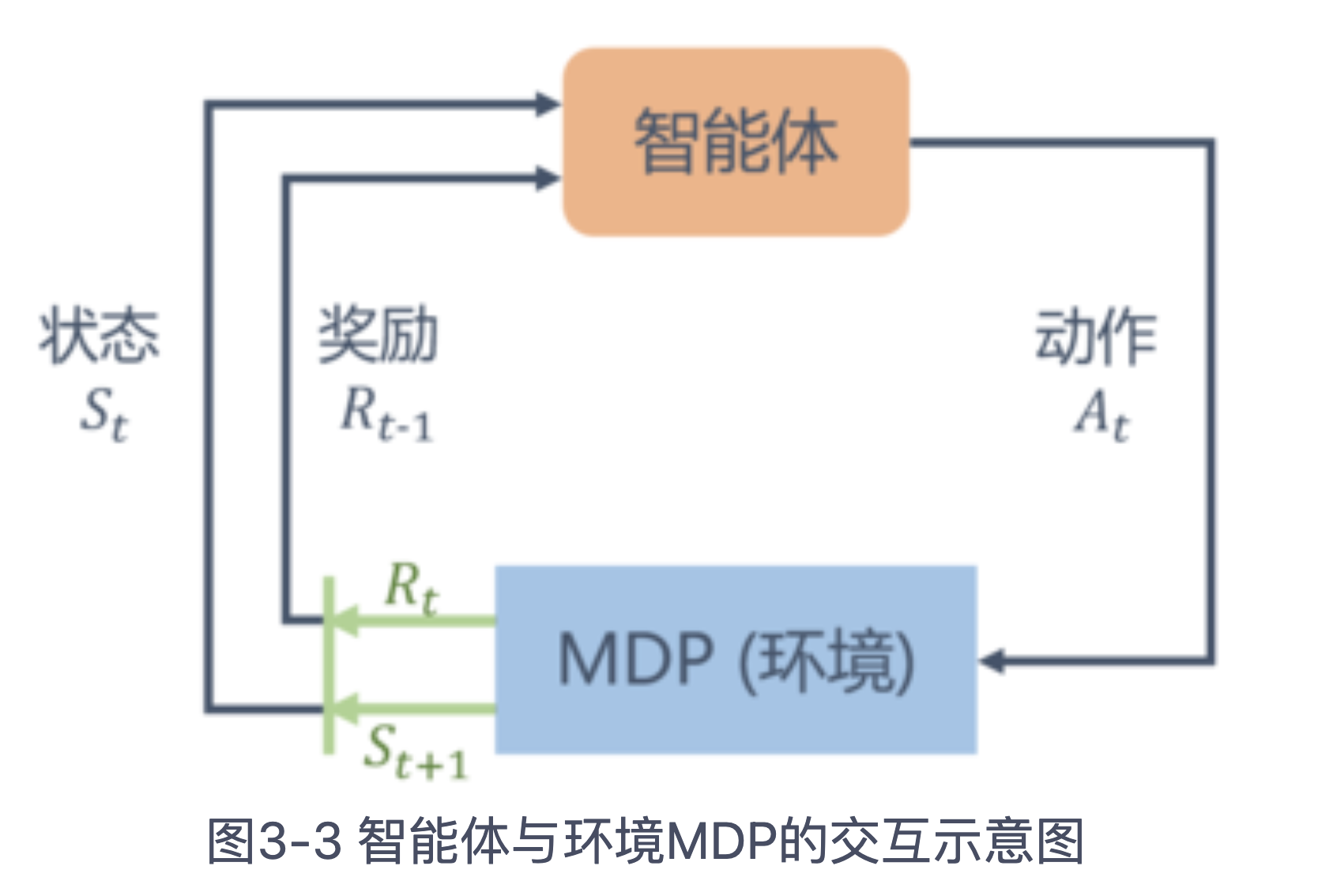
在状态St时,智能体选择状态At;基于P矩阵到达St+1,并且得到奖励Rt。智能体的目标是最大化累计奖励Gt(等价于最大化价值),智能体基于环境状态采取动作成为策略(policy)
一般而言,采样序列是连续的St,At,Rt,St+1,Rt是到达St+1之后得到的,所以很难说是对SA的奖励还是St+1的奖励,还是简单的理解为数据序列中的一个点位即可,后面进入到强化学习时,就是根据这些数据序列训练的,并不需要关注奖励的归属问题,只要能把奖励最大化即可。
策略:策略的数学形式是一个条件概率,用π表示,表示在状态s下采取动作a的概率 即![]()
策略是一个函数, MDP 中可以定义类似MRP的价值函数。但此时的价值函数与策略有关,这意味着对于两个不同的策略来说,它们在同一个状态下的价值也很可能是不同的。这很好理解,因为不同的策略会采取不同的动作,从而之后会遇到不同的状态,以及获得不同的奖励,所以它们的累积奖励的期望也就不同,即状态价值不同。
状态价值函数:MDP中的V表示基于策略的状态价值函数,表示从状态s出发,遵循策略π能获得的回报期望。
![]()
动作价值函数:![]() ,表示在MDP中智能体遵循策略π时,从当前状态s出发并采取动作a能获得的回报期望,即:
,表示在MDP中智能体遵循策略π时,从当前状态s出发并采取动作a能获得的回报期望,即:
![]()
(基于Q前推)考虑到S是S,A的积分(这里是加权求和的形式),可以得到V分解为Q如下:
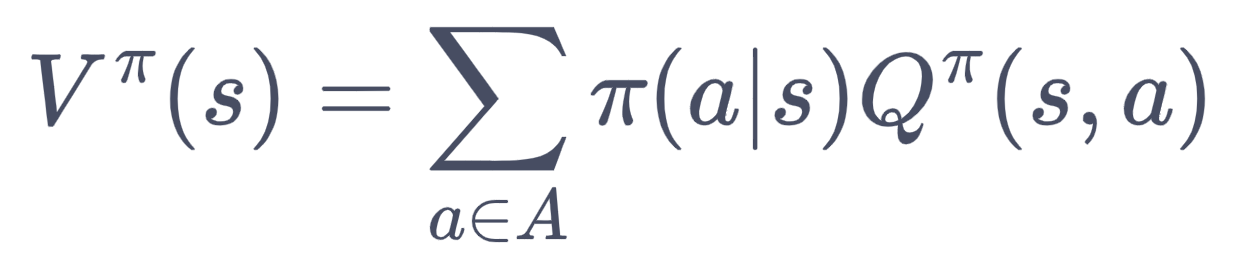
(基于Q后推)同时s,a的后继是下一个s,因此可以把Q分解为V如下:
![]()
这里的Q,r,V都是期望。
1.3.5 贝尔曼期望方程
回顾一下MRP中的贝尔曼方程
在MDP环境中,将s,s'拆分(s,a)的积分即可,相当于把一个高维的表达下探为(A空间)个低维的表达,每个低维的表达乘以一个权重系数,可以得到:
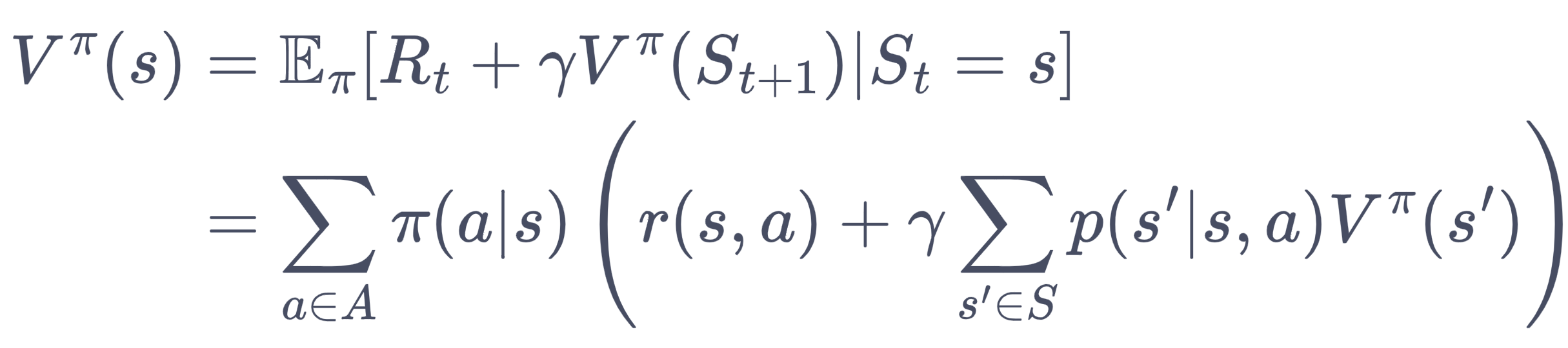
MRP的样本序列是srsr,MDP的样本序列是sarsar,所以MRP中r是s的函数,MDP中r是sa的函数。
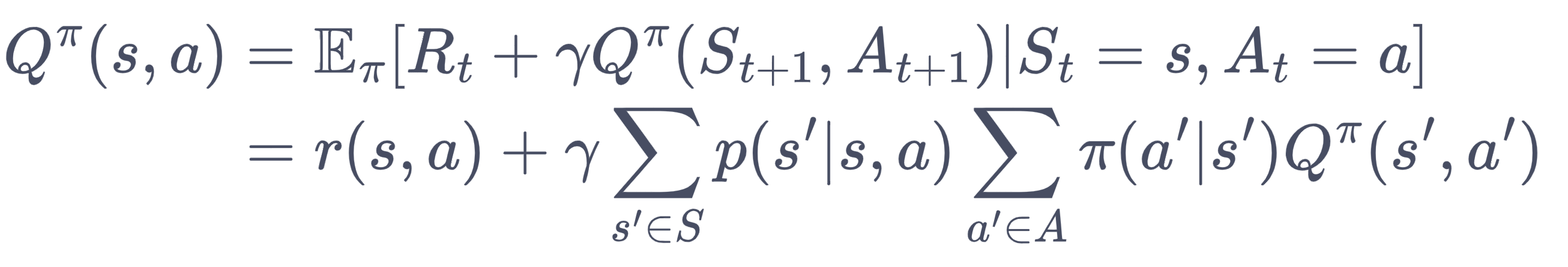
此处应该补充一个tree图[🔗]。

1.3.6 贝尔曼最佳方程
最优策略: 强化学习的目标通常是找到一个策略(S->A),使得智能体从初始状态出发能获得最大的期望回报。在有限状态和动作集合的MDP中,至少有一个策略不低于其他任何策略,我们把这个策略记为最优策略,记为π*(s)
最优状态价值函数:最优策略可能有多个,他们的状态价值都是相同的。即:
![]()
![]()
两者之间的关系是:
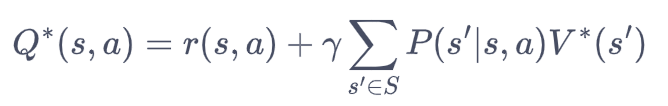
![]()
最优方程:
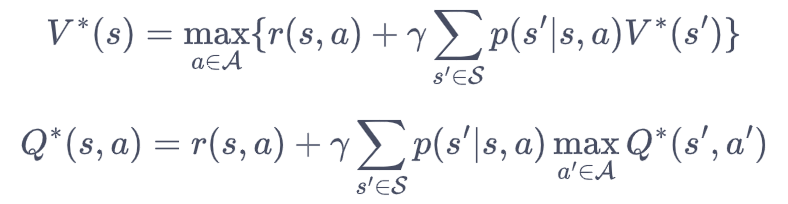
如何理解策略最优与s'的随机性?最优策略难道不是确定性的到达下一个状态吗?
在最优策略下,后续状态 s'仍然是随机的,其随机性本质上源于环境的不确定性,而非策略本身 —— 最优策略仅能 “最优地应对随机性”,却无法消除环境固有的随机转移特性。要理解这一点,需要结合强化学习中 “策略” 与 “环境转移” 的核心分工,具体拆解如下:
1. 先明确两个核心概念:策略的确定性 vs 环境的随机性
在强化学习的马尔可夫决策过程(MDP)中,“状态转移” 由两个独立环节决定,二者的随机性来源完全不同:
| 概念 | 定义 | 随机性来源 | 最优策略能否控制? |
|---|---|---|---|
| 策略 π(a|s) | 给定当前状态 s 时,选择动作 a 的概率分布(或确定性选择)。 | 策略本身(随机策略有随机性,确定性策略无) | 能(最优策略可选择 “确定性” 或 “随机” 形式) |
| 环境转移 P(s'|s,a) | 给定当前状态 s 和动作 a 时,转移到下一个状态s'的概率分布。 | 环境固有属性(如游戏中的随机暴击、机器人传感器噪声、路况的不可预测性) | 不能(环境是智能体的外部客观存在,无法干预) |
2. 最优策略的本质:“选最优动作”,但无法控制环境转移
最优策略的核心目标是:在环境转移随机的前提下,通过选择 “长期收益最大的动作”,让累积回报(如折扣回报 G_t)达到最大值。它解决的是 “选什么动作最优”,而非 “让下一个状态确定”。
例子 1:确定性最优策略 + 随机环境
假设你在玩一款 “吃豆人” 游戏(MDP 环境):
- 当前状态 s:你在某个格子,前方有 10% 概率出现 “能量豆”(+100 分),90% 概率是空格子(+0 分);左侧格子 100% 是普通豆子(+10 分)。
- 最优策略:选择 “向前走”与左侧期望收益相等;若能量豆概率提升到 11%,向前走的期望收益 11>10,成为唯一最优动作。此时,即使你执行 “向前走” 这个确定性最优动作,下一个状态 s'仍然是随机的(10% 到 “能量豆格子”,90% 到 “空格子”)—— 因为环境转移 P(s'|s),是随机的,策略无法改变这一点。
例子 2:随机最优策略 + 随机环境
假设你在玩 “石头剪刀布”(简化为 MDP):
- 当前状态 s:对手每次出拳是随机的(1/3 石头、1/3 剪刀、1/3 布)。
- 最优策略:你也以 1/3 概率出石头、1/3 剪刀、1/3 布(这是 “纳什均衡” 对应的最优随机策略,能保证长期期望收益不低于对手)。
此时,不仅环境转移(对手的出拳)是随机的,策略本身(你的出拳)也是随机的 —— 但这种随机性是 “最优的”(若你固定出石头,对手会一直出布,你会持续亏损)。即便如此,下一个状态 s'(比如 “你出石头,对手出布”)依然是随机的,无法确定。
1.3.7 占用度量
状态访问分布:首先我们定义 MDP 的初始状态分布为,在有些资料中,初始状态分布会被定义进 MDP 的组成元素中。我们用![]() 表示采取策略使得智能体在t时刻状态为s的概率,所以我们有
表示采取策略使得智能体在t时刻状态为s的概率,所以我们有![]() ,然后就可以定义一个策略的状态访问分布(state visitation distribution):
,然后就可以定义一个策略的状态访问分布(state visitation distribution):
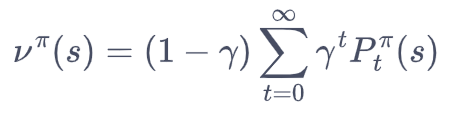
其中,是用来使得概率加和为 1 的归一化因子。状态访问概率表示一个策略和 MDP 交互会访问到的状态的分布。需要注意的是,理论上在计算该分布时需要交互到无穷步之后,但实际上智能体和 MDP 的交互在一个序列中是有限的。不过我们仍然可以用以上公式来表达状态访问概率的思想,状态访问概率有如下性质:
![]()
占用度量:它表示动作状态对被访问到的概率:
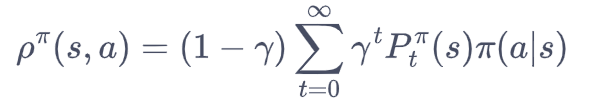
二者之间存在如下关系:
![]()
定理1:占用度量相同是策略相同的充要条件。
![]()
定理2:给定占用度量,则唯一确定策略(联合分布 除以 边缘概率得到该状态下采取某动作的概率->即策略)
占用度量相同 vs 策略相同 vs 状态访问分布相同的关系?
① 策略相同 <==> 占用度量相同
② 策略相同 ==> 状态访问分布相同,分布相同不代表策略相同,例如田忌赛马,3匹配都被访问1次,但是顺序不同,策略不同。考虑更一般的 MDP 场景,假设有一个状态s,动作空间为{a1,a2}。策略π1:π1(a1∣s)=0.6,π1(a2∣s)=0.4;策略π2:π2(a1∣s)=0.3,π2(a2∣s)=0.7。如果 MDP 的转移概率使得,从s出发,选择a1后以0.5的概率回到s,选择a2后以76的概率回到s。经过计算,可能会发现这两个不同策略下,状态s的访问分布是相同的,但策略本身明显不同。
③ 占用度量相同 ==> 状态访问分布相同,同②。
1.4 经典算法
1.4.1 蒙特卡洛算法(MC)
MC也被称为统计模拟方法,运用MC方法时,我们首先进行重复随机抽样,然后同统计的方法计算我们的目标值。例如基于采样方法计算圆的面积:
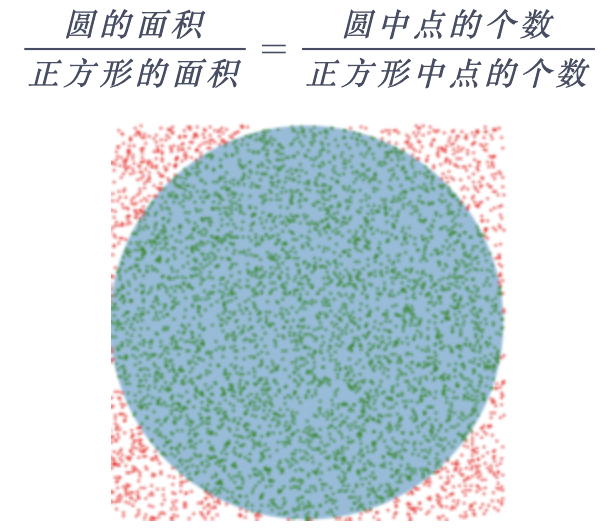
现在,我们介绍如何使用MC估计状态价值函数V(S),recall that V(s)的定义为回报的期望:
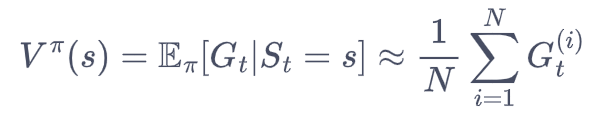
执行以下操作:
① 数据采样:sars.....
② 估计更新:用N(s)表示状态s出现的次数,M(s)表示状态s的累计回报。遍历每个采样链条的每个实践步,对于St:
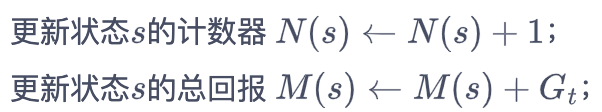
最终:
![]()
采样示例:
第一条序列
[('s1', '前往s2', 0, 's2'), ('s2', '前往s3', -2, 's3'), ('s3', '前往s5', 0, 's5')]
第二条序列
[('s4', '概率前往', 1, 's4'), ('s4', '前往s5', 10, 's5')]
第五条序列
[('s2', '前往s3', -2, 's3'), ('s3', '前往s4', -2, 's4'), ('s4', '前往s5', 10, 's5')]
# 对所有采样序列计算所有状态的价值
def MC(episodes, V, N, gamma):
for episode in episodes:
G = 0
for i in range(len(episode) - 1, -1, -1): #一个序列从后往前计算
(s, a, r, s_next) = episode[i]
G = r + gamma * G
N[s] = N[s] + 1
V[s] = V[s] + (G - V[s]) / N[s]
timestep_max = 20
# 采样1000次,可以自行修改
episodes = sample(MDP, Pi_1, timestep_max, 1000)
gamma = 0.5
V = {"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0}
N = {"s1": 0, "s2": 0, "s3": 0, "s4": 0, "s5": 0}
MC(episodes, V, N, gamma)
print("使用蒙特卡洛方法计算MDP的状态价值为\n", V)① 这里使用的是增量方法计算状态均值;
② 逆向方法计算链条上的回报,遇到什么状态就更新什么状态的估计值。
使用蒙特卡洛方法计算MDP的状态价值为
{'s1': -1.228923788722258, 's2': -1.6955696284402704, 's3': 0.4823809701532294, 's4': 5.967514743019431, 's5': 0}1.4.2 动态规划算法(DP)
将问题拆解为子问题,完美对齐贝尔曼方程
动态规划(dynamic programming)的基本思想是将待求解问题分解成若干个子问题,先求解子问题,然后从这些子问题的解得到目标问题的解。动态规划会保存已解决的子问题的答案,在求解目标问题的过程中,需要这些子问题答案时就可以直接利用,避免重复计算。
不同于 蒙特卡洛方法和时序差分算法,基于动态规划的这两种强化学习算法要求事先知道环境的状态转移函数和奖励函数,也就是需要知道整个马尔可夫决策过程。无法将其运用到很多实际场景中。另外,策略迭代和价值迭代通常只适用于有限马尔可夫决策过程,即状态空间和动作空间是离散且有限的。
策略提升指引方向:只要最佳的动作存在占用,那么以终点为中心,最优策略按照波次外延
策略评估提供基础:有了策略评估才知道不同子状态孰优孰劣
策略评估对齐 critic模型,策略提升对齐actior模型。
环境介绍
悬崖漫步(Cliff Walking)是一个非常经典的强化学习环境,它要求一个智能体从起点出发,避开悬崖行走,最终到达目标位置。如图 4-1 所示,有一个 4×12 的网格世界,每一个网格表示一个状态。智能体的起点是左下角的状态,目标是右下角的状态,智能体在每一个状态都可以采取 4 种动作:上、下、左、右。如果智能体采取动作后触碰到边界墙壁则状态不发生改变,否则就会相应到达下一个状态。环境中有一段悬崖,掉入悬崖或者达到目标状态是终止状态。每一步的奖励都是 −1(即鼓励最快到达目标),掉入悬崖的奖励是 −100。
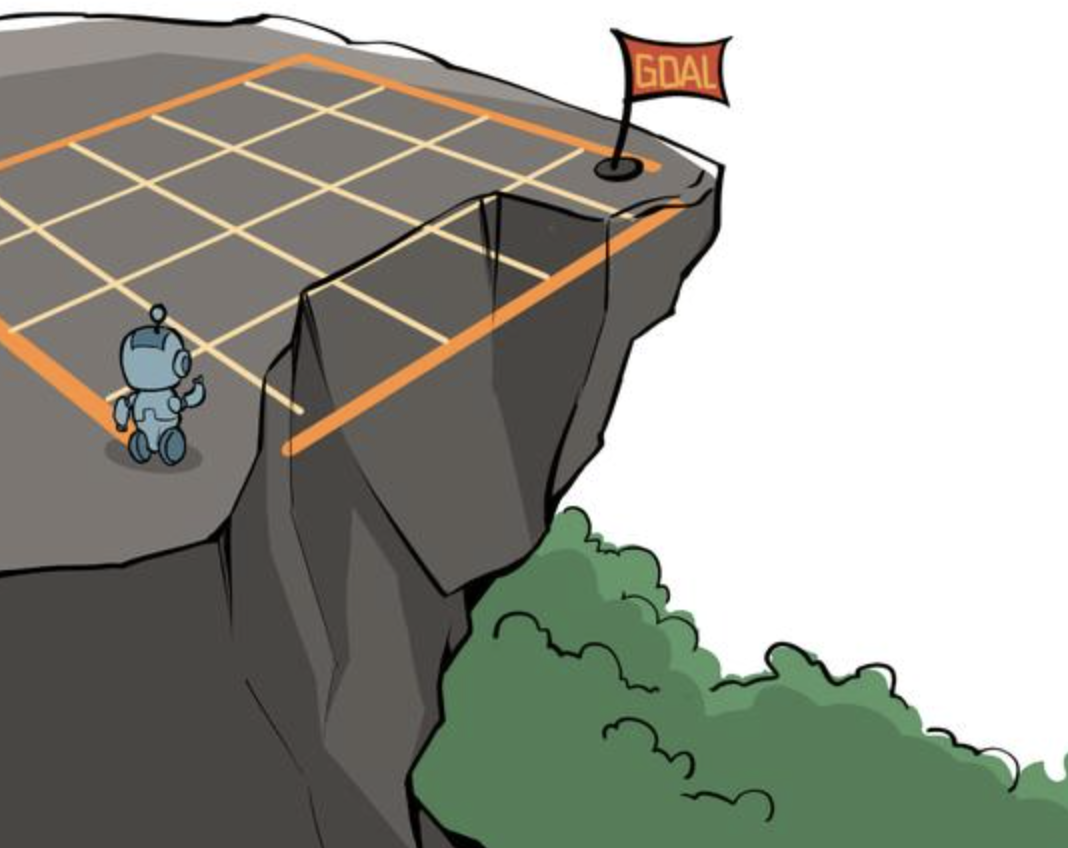
策略评估
策略评估就是迭代critic model,即迭代V(S),基于DP思想+贝尔曼期望方程,我们把对S的估计转移为下一状态的估计,具体而言:
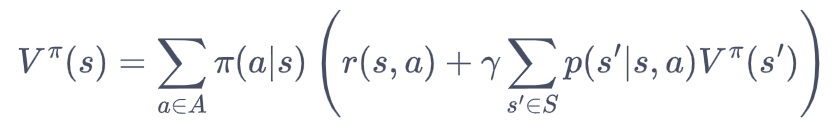
更一般的,考虑所有的状态,就变成了用上一轮的状态价值函数来计算当前这一轮的状态价值函数,即
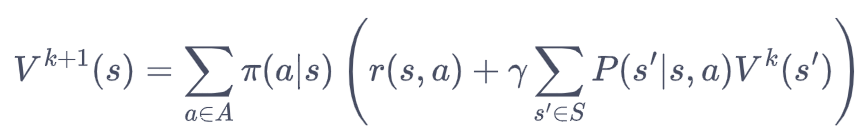
可以证明,随着迭代次数的增加,V会逐渐收敛到Vπ,这与初始值无关。
策略提升
经过策略评估,我们可以知道每个状态的价值。进一步,我们会想到一个问题:如何基于一直的策略评估来优化已有的策略π呢?要解决这个问题,首先要定义什么叫做更优:假设智能体在状态s下采取某个动作a,之后的策略依旧遵循π,此时得到动作价值回报记为Q(s, a),如果满足Q(s, a)>=V(s),则说明在状态s下采取动作a会比原来的策略得到更高的期望回报。
以上假设只是针对一个状态,现在假设存在一个确定性策略,在任意一个状态s下,都满足
![]()
于是,在任意状态下,我们有:
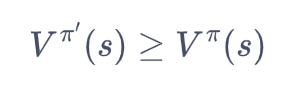
这就是策略提升定理,于是我们可以直接贪心地在每一个状态选择动作价值最大的动作,也就是:
![]()
策略迭代
总体来说,策略迭代算法的过程如下:对当前的策略进行策略评估,得到其状态价值函数,然后根据该状态价值函数进行策略提升以得到一个更好的新策略,接着继续评估新策略、提升策略……直至最后收敛到最优策略
![]()

问题:由于状态价值是随机初始化的,有没有可能价值估计不准导致策提升贪心错误呢?
确实有可能提升错误。针对这一问题,RL 领域已形成成熟的解决方案,核心思路是 “减少价值估计误差” 和 “降低策略对估计误差的敏感度”,主要方法包括:
改进价值估计的准确性
- 双网络结构(Double DQN)
- 时序差分误差裁剪(TD Error Clipping)
- 经验回放(Experience Replay)
优化策略选择的鲁棒性
- e-贪心策略
- 乐观初始化
- 策略正则化
直接优化策略而非依赖价值(策略梯度方法) 如 PPO、A2C 等方法。
价值迭代
策略迭代的效率比较慢,原因在于策略评估需要进行多轮。但是存在这种可能:策略评估后,再进行N次迭代,其策略提升的方向(收益做大化)都是相同的。现在这么操作:
每次都基于贝尔曼最优方程进行状态价值评估。即:
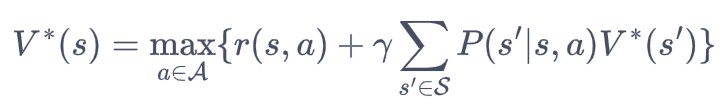
我也不知道哪个action是最好的,我就全一次,然后用最大的值作为我的价值。而不是策略迭代中的期望值。
这实际相当于:状态评估->策略迭代->交替进行,每一次都是朝着收益最大化方向迭代
无论是策略迭代 还是 价值迭代,都是选择最优子路径(即next state),区别在于前者是多次评估,后者是1次评估;前者是贝尔曼期望方程,后者是贝尔曼最优方程。似乎后者的效率更高。
策略迭代:会在过程中得到一个策略,策略会指导策略评估(即价值评估),在悬崖环境中,如果某个方向的价值低,那么策略就不会采样这个方向(贪心),这样会降低一定的计算量。也就是评估与迭代是一起逐渐收敛的。
价值迭代:实际没有学到一个策略,纯纯暴力计算,但是由于使用最优方程,可能收敛的更快。在收敛之后,自动阐述一个策略。
两者相比,有点类似 基于过程 vs 基于状态。
1.4.3 时序差分算法(TD)
在网格世界或者悬崖环境中,我们没有采样任何数据就可以计算训练得到策略。这是因为环境信息完全可知(例如转移概率),我们基于DP算法就可以计算每个状态的价值/策略。这就好比在在深度学习语境中,如果已知数据的分布律,我们不需要任何实际样本,也可以让模型收敛。[已知x、y关系,逐渐收敛f即可,f就是模型]。
在大部分的RL场景下,我们并不知道真实环境的转移概率,也就无法进行动态规划,这个时候智能体只能和环境交互来得到样本数据进行学习,这种方式被称为无模型的的强化学习。注意这里的无模型是无环境模型,而不是无agent模型。
这里主要介绍2种无模型的算法:sarsa、Q-learning,两者都是时序差分算法。
时序差分算法是增量更新算法,其核心保障在于单步奖励的可靠性。具体公式如下:
![]()
α后面的部分被称为Td误差(Td-error),实际上Td算法同时包括了蒙特卡洛 + DP的思想。
SARSA算法
有了上述TD算法可以直接进行RL模型训练了吗?答案是否定的,因为在无模型学习中,我们需要和环境交互来采样数据,可以我们现在没有转移概率,需要采取什么策略呢?聪明的你一定想到了贪心,但是贪心是最佳的吗?甚至是合理的吗?答案是否定的,因为贪心可能错过最优解。在前文的策略迭代中,我们没有去深思这个问题。一般的做法是采取e-贪心策略,即以e的概率随机,1-e的概率贪心。
有了价值估计算法、策略算法,我们就可以闭环训练了。具体公式为:
![]()
这被称为sarsa算法,因为模型迭代需要使用到:
s:当前状态
a:当前动作
r:即时奖励
s:下一状态
a:下一动作
连起来就是sarsa。

ps:这里确实是q策略模型,而不是v价值模型。
Q-learning算法
Q算法和sarsa的区别进在于最佳分支 vs 所有分支
![]()
也就是说,Q算法使用最佳的next state来更新模型。如何get所有actiaon的结果呢?并不是需要在相同时刻采样所有的actiaon,而是利用离线更新的思想,利用Q-table/模型中的max估计即可。
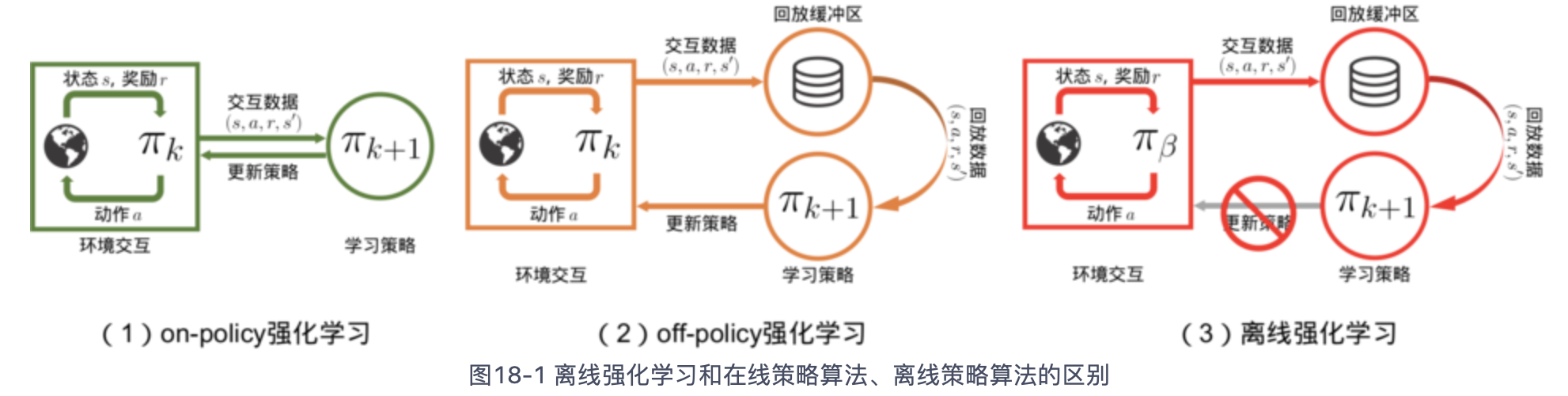
在线策略算法 vs 离线策略算法
在线:实时使用的数据 一定是 实时采样数据
离线:实时使用的数据 不一定是 实时采样数据 ,例如经验回放池,但是要求数据要一直更新。不能是一个封闭的集合。如果是封闭集合,则被称为离线强化学习。
小结
本节介绍了经典的无模型算法:基于时序产分思想的sarsa和Q算法,两者的区别仅在于后继状态的价值估计方法(类似平均池、最大池)。时序差分的核心思想在于用分支状态的价值来更新当前状态的价值,在环境是有限SA集合时,这两个算法都非常好用。
二、进阶篇
2.1 DQN
跳过
2.2 策略梯度算法
2.2.1 Reinforce
DQN是基于值函数的方法,他学习一个值函数,然后间接的导出一个策略(贪心类算法),RL中另外一类算法是基于策略的算法,也就是说模型会直接学习一个策略。
策略梯度
我们基于神经网络对策略建模,输入为state,输出为动作分布。我们的目标是最大化期望回报,因此目标函数就是:
![]()
theta是策略模型的参数。
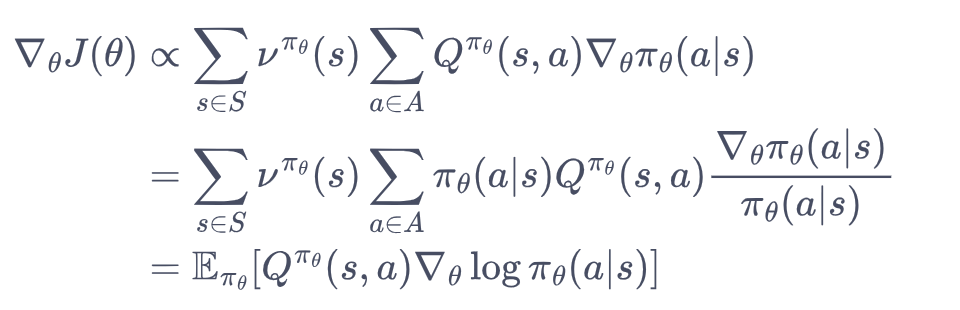
理解:把期望回报,转化为state、action的联合积分。
第一层积分: 遍历初始状态s
2层:遍历actiaon
目标导数 = Q价值 * 概率微分,Q需要与概率微分同号
思考1:目标状态是对初始状态的估计,为啥在公式里面转化为对所有状态的微分了呢?而且状态是有很多个的,只需要2重积分就够了吗?
第一个问题:基于贝尔曼方程,可以把S0的价值分解到全量状态,实际推导中会转化到访问分布
第二个问题:这里不是有2步的意思,而是所有的状态-所有的动作都参与到。
思考2:上面的公式,为什么要做除法转化呢?
因为增加条件概率后,可以形式化为期望的形式。从而构建loss函数
思考3:如何理解上述微分?
微分表示增量,即为了提高目标,我们要让A最大化。如何让A增大呢?=>价值与概率微分同号。
如果Q是pos那么log概率增大,如果Q是neg,log概率减小。
思考4:如何理解策略梯度这4个字?
基于上述公式,可以看到目标的微分最终转化到了策略的微分(即策略梯度),权重是动作价值。
思考5:如何设计loss呢?
loss是需要求微分的对象,把这个给到框架,框架自动计算微分迭代。问题变成我们需要对什么求微分?显然是对策略,即:
loss = -1 * Q(实数) * 策略(即动作概率 -> 即模型输出)

思考4:如何计算Q值?
从定义来看,Q是在状态s下采取动作能得到的回报期望。实际运行时我们可以可以使用MC来收集奖励来建模Q,即:
在后续的学习中,我们可以有更多Dqn来建模Q。

注意这里的:
![]()
最后一长串是框架计算的微分,给到模型,如何转化为loss呢?把微分算子拿到α前面就是了。
2.2.2 DDPG算法
进阶篇介绍的算法大都是在线策略算法,例如策略梯度、AC、PPO,此类算法的样本效率比较低。与之相对应的是DQN代表的离线策略算法,在DQN中,我们对Q建模,但是他只能处理动作空间有限的环境(需要选择一个最大的Q),无法处理动作空间无限的环境,是否有离线策略 + 连续环境的算法呢?DDPG(深度确定性策略梯度, deep deterministic policy gradient)就是一个。
为什么叫做确定性呢?因为action不是从分布采样,而是一个确定的值(实际会增加一个随机噪声来提高探索。)
与策略梯度定理类似,我们可以推导出确定性策略梯度定理:
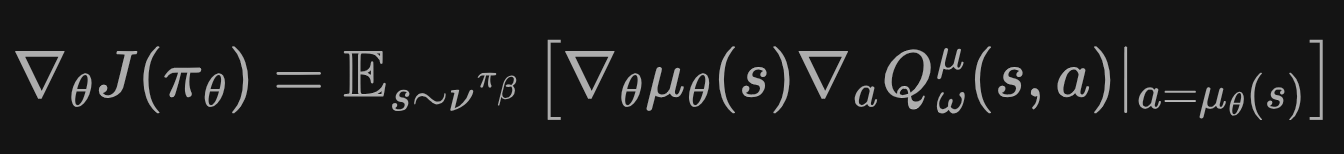
π是收集数据的行为策略,u是一个输出确定动作的网略。可以这么理解这个定理:
① 我们想找到一个让Q最大的动作,先对u输出的动作求导,再根据链式法则对策略网络求导。
例如y=sin(x^2),dy=-cos(x^2) * 2x,我们想让y最大,即dy最大,即 loss=cos(x^2) * 2x
同理,q = critci(s, action), action=actor(s), dq=Q对action求微分*action对网络求微分。
因此,实际ddpg的actor-loss设计为:
actor_loss = -torch.mean(self.critic(states, self.actor(states)))
内心os:分析微分计算过程好像没意义,因为这是框架内部的事情,我们只要把要最大化的目标赋值给loss即可。那为啥策略梯度不是那么简单的loss呢?因为策略梯度没有critic,没法直接对齐loss,需要推导。那为啥PPO、SAC 不是这么算呢?后面再统一比较下。
DDPG有3个点需要注意:
① 添加噪声
② 2个策略网络(主网络+目标网络) + 2个价值网络(主网络+目标网络),DDPG 中 Actor 也需要目标网络因为目标网络也会被用来计算目标Q值。也就是说Q的目标是由两个目标网络计算的。
③ 模型使用软更新而不是基于时间步更新。
整体流程如下:

2.3 Actor-Critic
书接上文,使用MC来估计回报期望固然无偏,但是也存在2个缺点:
1、方差大(时间步太多),需要等episode完毕才能更新模型
2、未采用优势函数思想,可能收敛慢
本章介绍的A-C算法会同时训练一个价值网络和一个策略网略,我们把策略梯度写成下面这个更加一般的形式:
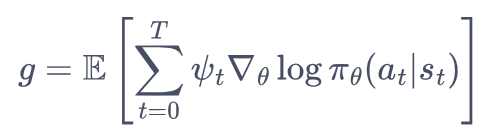
pusai t表示的是s-a的策略价值,这个策略价值的建模方式有多种:

方式6是基于价值函数的优势函数。
思考1:如何计算策略损失?
按照2.2的方法,策略梯度为 优势函数 * log 概率梯度,损失为 优势函数 * log 概率。损失是对谁求微分,梯度是微分的结果,是迭代的小增量。
思考2:如何计算critic损失?
critic的目标是拟合V(s)和V(s+1),本质驱动为环境的实际奖励,所以其loss/目标是:
![]()
也就是,对状态的预测越准越好,进一步可以计算其梯度为:
![]()
因此,整个伪代码为:

种类的deita t实际就是优势。
总结:actior-critic算法是基于值函数与基于策略函数的叠加,critic基于actior采样得到的数据学习哪些状态是好,哪些状态是差,总之是学习到了V(s)的预估。critic预估的越准,策略函数越能采用到更优的选择。随着Actor的演化,其采样到的数据的分布也在变化,这需要critic适应新的分数。
2.4 TRPO
学前小故事(一看一个不吱声) => 周瑜变成诸葛亮(假设更强)
他俩都爱下象棋,周瑜胜率是90%,诸葛亮胜率是93%。周瑜想进步,于是拿到诸葛亮的实战棋谱。他怎么学习的呢?不是直接背下来,而是先实践,再迭代:
① 在诸葛亮的Tx盘面,周瑜用一副新的象棋对齐Tx,然后自己下,胜率是90%。
② 在诸葛亮的Tx+1盘面,周瑜用一副新的象棋对齐Tx,然后自己下,胜率是91%。
咦,周瑜一看,行啊,下次再遇到Tx盘面,我就按照小诸葛的策略走At,这样我就进入到Tx+1,胜率可以提高耶。
这就是策略提升训练,也就是说是实实在在的优势(Advantage)驱使我学习。
一句话总结:
① 不见兔子(优势)不撒鹰(策略迭代)
② 按照我的路径来,你的人生会更爽,没有优势不要钱。
为什么人很难迭代呢?因为即时奖励是负的,例如你去上一个培训班,你会变得更强,但是你的即时奖励是你花出去的钱,是负值。也会牺牲自己的娱乐时间,都是负向的,熬过一段时间才能有正收益。所以,等待,一直是人生的必修课。
或许,成功的人和普通人的区别就在于,他们做的选择是长期有利的,而不是短期享受。天呢,正强化学习也在塑造我们的任职啊。
2.4.1 预备知识
- 重要性采样
权重 = 样本在目标分布的概率 / 样本在提议分布的概率
理解:如果某个样本在目标分布的概率很大,但是在提议分布的概率很小,通过加权来修正。
所以 重要性采样,相当于对样本的权重做出调整,调整的依据就是样本在两个分布的概率比。
- KL散度

TRPO的KL散度是:
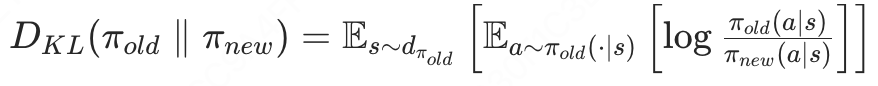
理解:在s-a空间中,旧策略 和 新策略 的概率分布差异(距离)
描述在旧策略的状态分布下,新旧策略对动作选择的概率差异,确保策略更新不 “突变”。
- S0的含义
S0表示t=0 时刻的初始状态(可能有多种),服从初始状态分布,与时间无关但并非单一固定状态。核心定义:“初始时刻的状态集合” “0” 仅表示 “轨迹的起始时刻(t=0)”,不代表 “某个特定状态”。轨迹概率的构成:策略 + 环境动力学 + 初始状态分布。
在强化学习中,s的下标是时间的编号,即便s0和s5的state是一样的,也不会把s5记为s0,但是在状态-动作的占用度量时,如果s-a相同,会被加和。
- V(s)的理解(最重要):价值不是状态的属性,而是策略的量化。因为相同的状态,不同的模型会给出不同的价值判断。
2.4.2 核心:目标函数推导
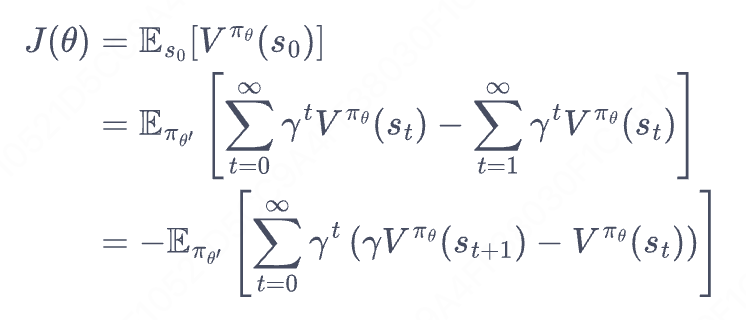
第一个等号:定义。我们把J(theita)理解为周瑜的胜率。S0表示初始盘面,π(theita)表示周瑜,Vπ(S0)表示在周瑜的策略下,盘面S0的累计收益期望,可以理解为胜率。
第二个等号:
① 理论: 括号内部是级数恒等展开(作差后只剩下V(S0))
② 理解:teita'表示诸葛亮,在诸葛的盘面上,让周瑜下棋,并计算累计收益。结合①可以发现这里作差后,只剩下S0,由于S0分布和人没有关系,因为即便在诸葛亮的盘面,计数作差后得到的还是周瑜在S0的胜率。因为都是周瑜的胜率,因此第二个等号成立。
第三个等号:重组。
新旧策略的目标函数之间的差距:
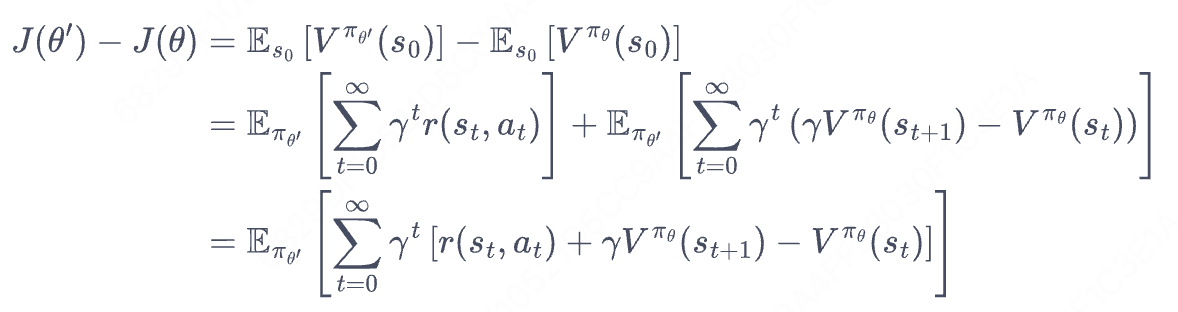
第一个等号:定义
第二个等号:即上面的推导
第三个等号:重组
理解:拆解诸葛亮的胜率-周瑜的胜率=>在诸葛亮的盘面上,让周瑜下棋(平行空间,而不是原地操作),优势=诸葛亮获得的即时奖励(即st下采取at获得的奖励,系统决定奖励大小) + 周瑜St+1的胜率-周瑜St的胜率。这里的核心是Action-T,这是诸葛亮走的,呼应前面的小故事。当然,严谨的理解,应该把J理解为累计收益,理解为胜率为了便于理解。
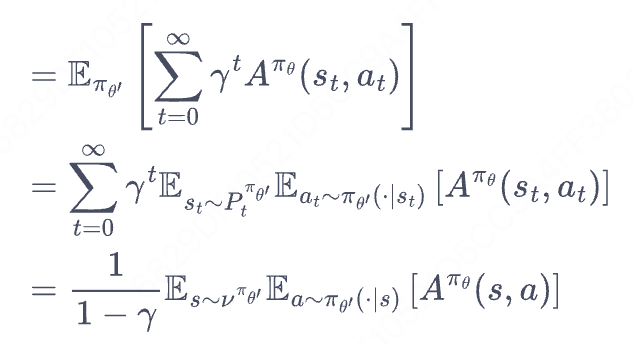
注1:新策略采样数据,即诸葛亮盘面。
注2:最后一个等号把时域转化为“频域”(state),把之前散落在各个时间步的状态概率整合为频域的一个单点,需要用到变换公式(下图))。
![]()
只要我们能让A为正值,就能让策略单调提升。
直接求解该式是非常困难的,因为新策略是需要求解的,但我们又要用它来收集样本。把所有可能的新策略都拿来收集数据,然后判断哪个策略满足上述条件的做法显然是不现实的。于是 TRPO 做了一步近似操作,对状态访问分布进行了相应处理。具体而言,忽略两个策略之间的状态访问分布变化,直接采用旧的策略的状态分布,定义如下替代优化目标:
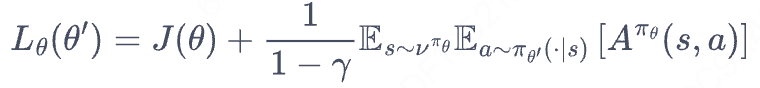
理解:当新旧策略非常接近时,状态访问分布变化很小,这么近似是合理的。L(theita)对应J(theita),表示替代目标/松弛目标。其中,动作仍然用新策略采样得到,我们可以用重要性采样将动作分布替换为旧策略进行处理:
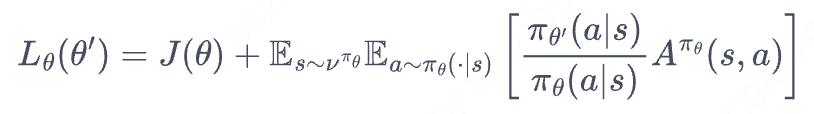
为啥期望的系数没了?先不纠结。
最终整理目标为:
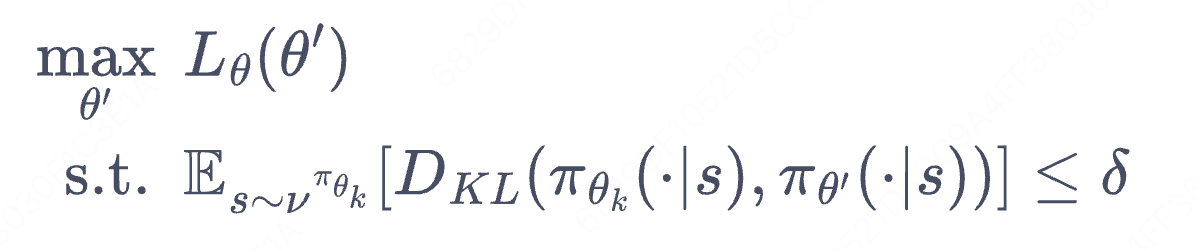
注1:KL散度让状态访问分布接近。这样才能保证推理链合理(第一个近似)。
注2:优势体现在商,优势函数本身没有新策略模型,实际上自始至终都只有一个模型。新模型是旧模型的迭代,是下个step的自己。hhh
2.4 PPO
在TRPO的推导中,核心点在于优势函数大于0。这里的优势函数经过KL约束 + 重要性采样已经转化为旧策略。即:
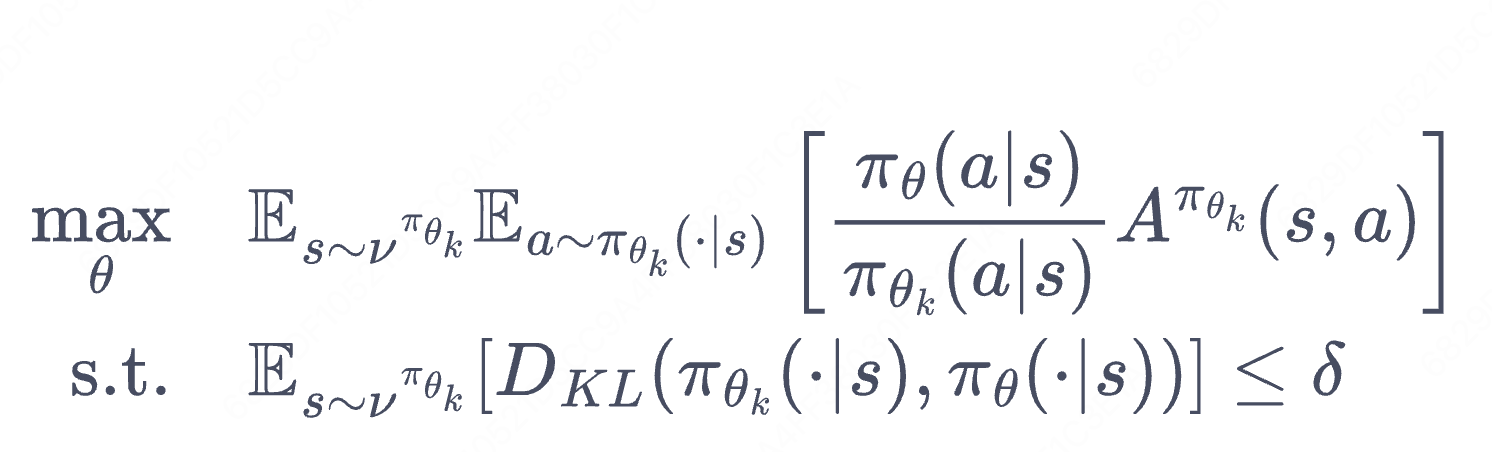
PPO 的优化目标与 TRPO 相同,但 PPO 用了一些相对简单的方法来求解。具体来说,PPO 有两种形式,一是 PPO-惩罚,二是 PPO-截断,我们接下来对这两种形式进行介绍。
2.4.1 PPO-惩罚
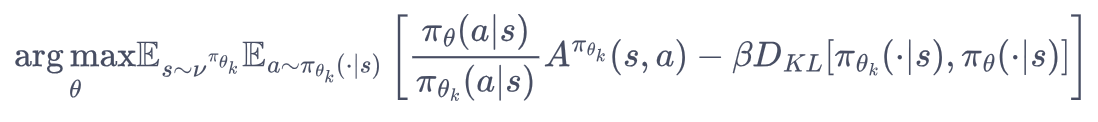

2.4.2 PPO-截断
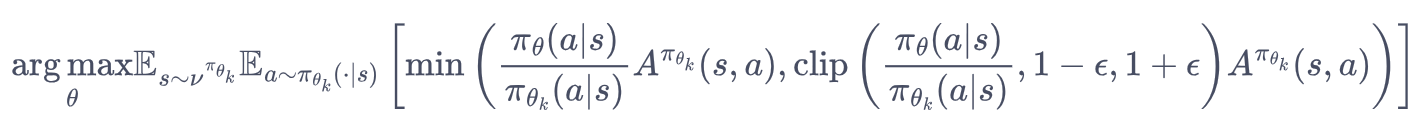
这里有2项:
第一项:原始PPO权重;
第二项:带有上下界 的权重;边界以为这新旧策略的差异小。
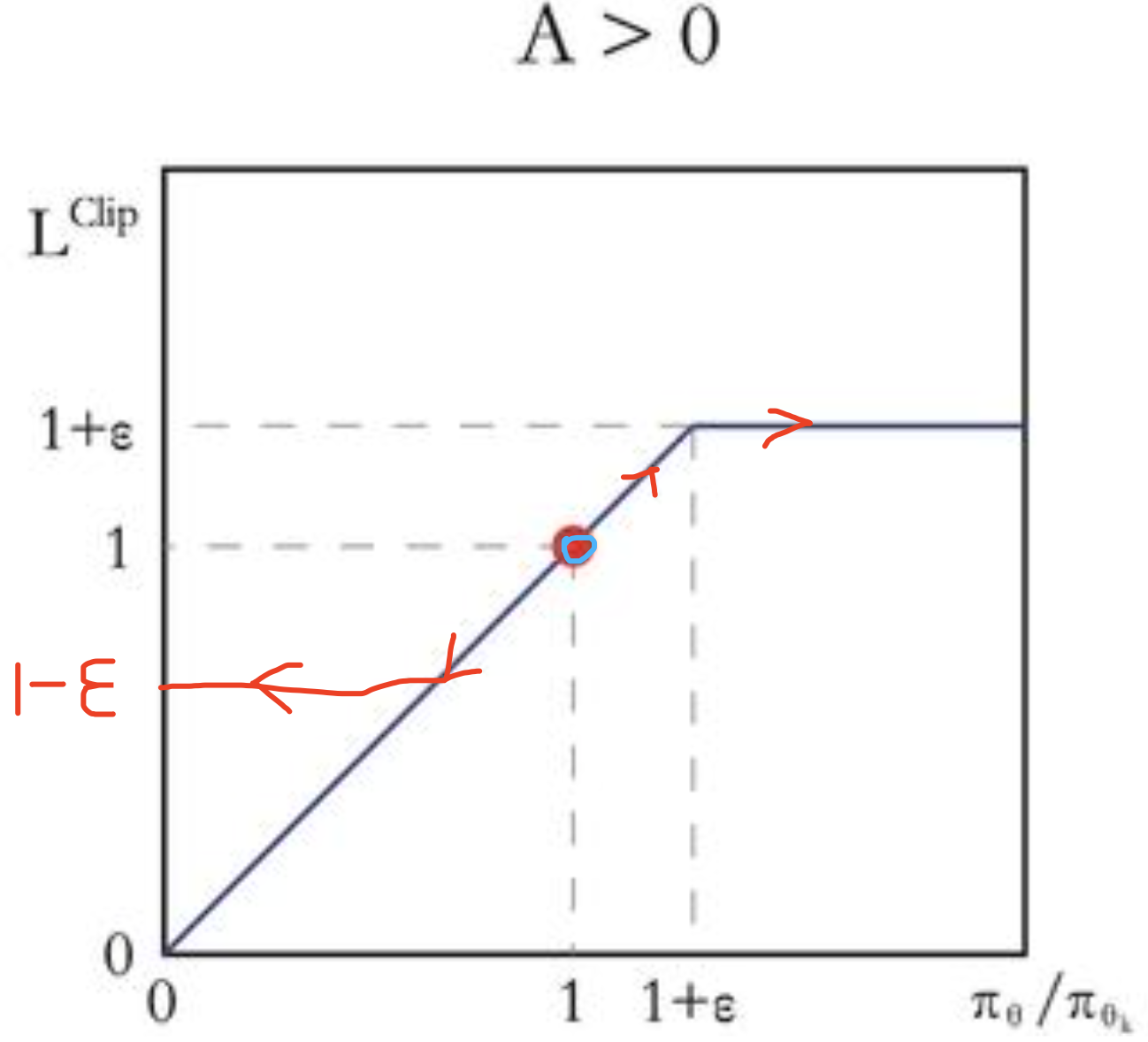
2.4.3 训练示例
推演训练过程如下:
从公式来看,只需要单步即可更新。
![]()
step1:在时间步t,我们算出旧策略的动作概率
step2:在时间步t,我们算出新策略的动作概率
step2:基于奖励数据 + critic模型,计算时间t的优势A
step2:max目标函数
什么是新策略模型?
旧模型迭代一次就变成了新策略模型。
从下面的代码可以看出:
① 采样一次数据
优势A只会计算一次、旧策略的动作概率只会计算1次。
策略模型多次迭代,每次迭代都会计算actor-loss、critic-loss。
注意:采样1个序列,然后更新完模型,再采样一个序列。因此优势实在一个episode里面结算的。
但是计算Critic的时候,是batch计算的,这个batch是不同时间步构建的。
小结:优势计算,轨迹粒度;critic优化,step粒度。
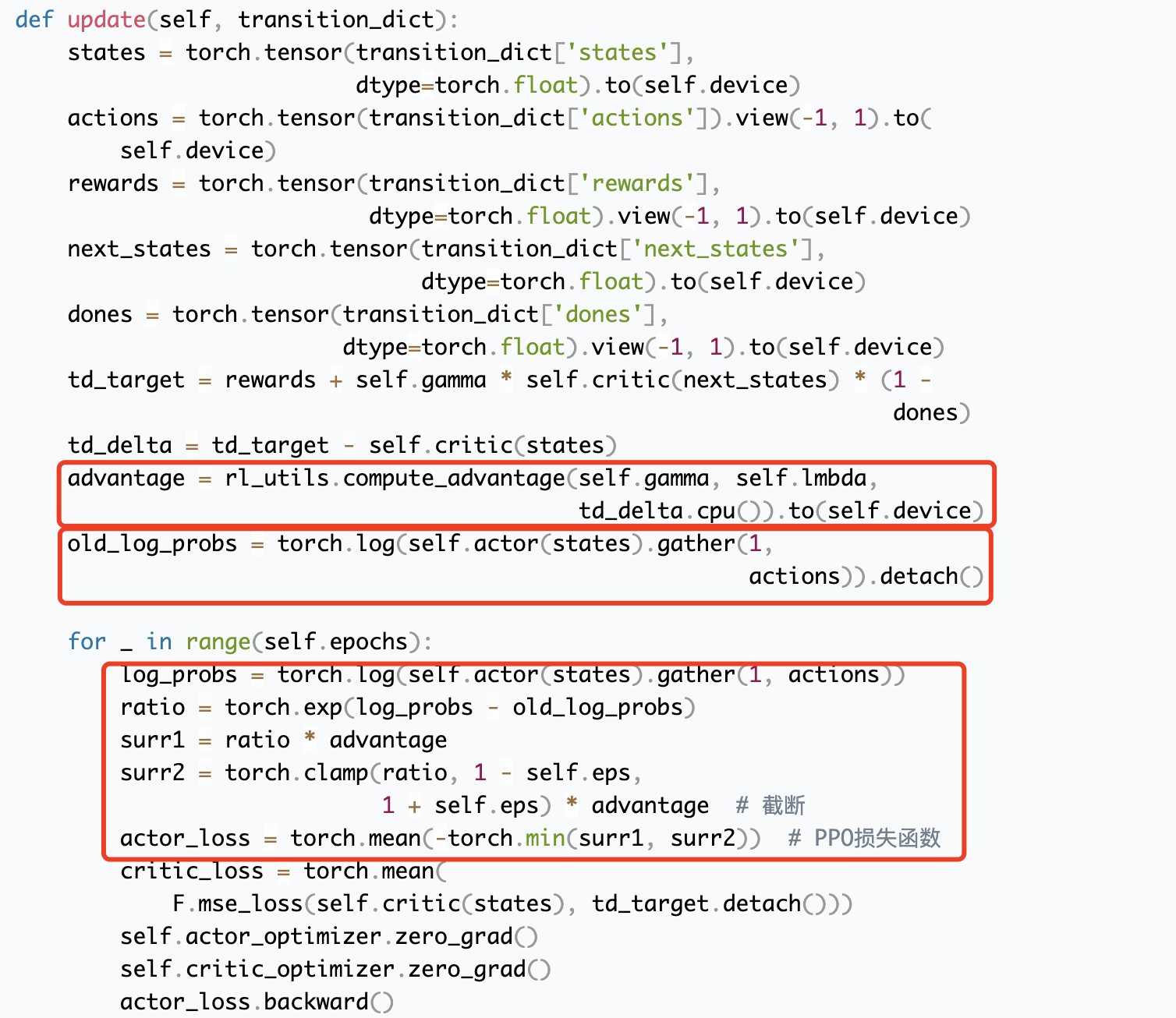
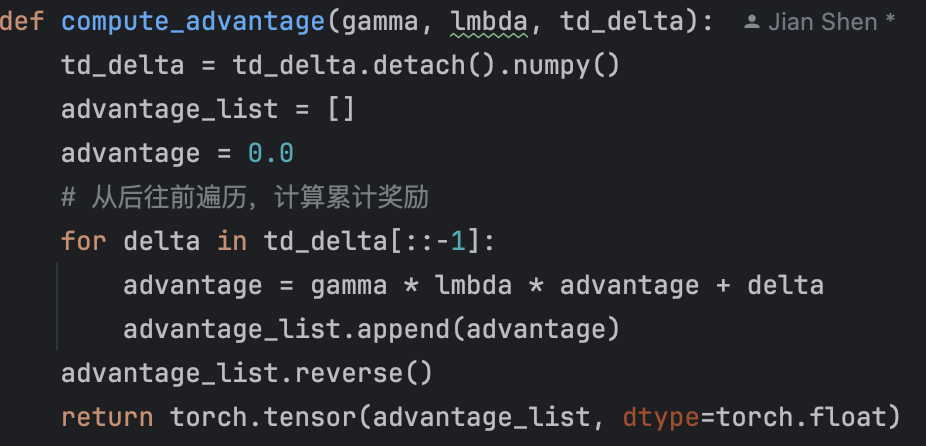
PPO 和 REINFORCE 的联系与区别:



总结:在原始策略梯度上增加了KL约束,防止模型训练震荡。
2.5 SAC
强化学习界的平衡思想(防止策略一家独大)
熵的定义
![]()
在强化学习中,我们可以使用H(π(.|s))来表示策略π在状态s下的随机程度。
最大熵强化学习:模型学习的目标除了最大化奖励外,还要最大化策略的熵。也就是说既要奖励大,又要动作不那么集中。熵本身已经成为目标函数的一部分,此时强化学习的目标是:
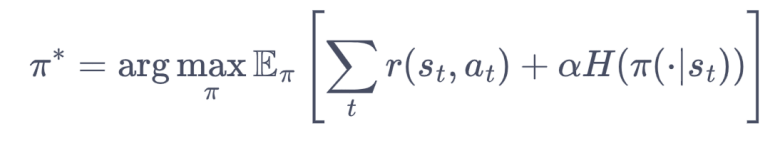
即奖励最大化+熵最大化。其中α是熵增的权重。
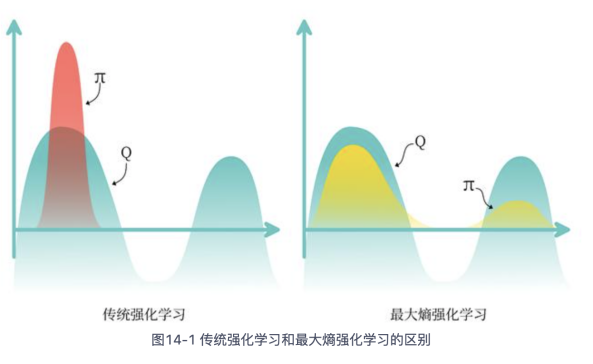
“防止策略贪心”这在之前的算法中也有看到过,例如e-贪心来采样action。但是这个策略的核心是防止模型陷入局部最优解(拓展了采样空间)。
从形式上来看最大熵学习和e-贪心都是反贪心的策略,区别在于:
① 生效阶段:e-贪心主要在训练阶段生效(推理阶段 ε 趋近于 0),最大熵在训练+推理阶段都有效
② 生效方式:e-贪心拓展模型的训练样本空间,最大熵通过在目标函数中加入熵正则项,让策略本身具备 “探索 + 鲁棒性”,随机性是策略的固有属性。
普通的强化学习是让策略集中到大Q的action,而SAC则给小Q留了一定的概率。
可是为什么呢?难道是Q不准?
最大熵的核心设计目标 —— 通过策略随机化提升鲁棒性(应对环境噪声、Q 值估计误差)和探索效率(发现潜在更优动作)。Critic 输出的 Q 值是模型基于已有数据的 “估计值”,不是环境中动作价值的 “真实值”。哪怕当前 Q 值 6:4,也可能是数据不足、噪声干扰导致的误判,真实价值可能是 4:6,这种 “估计与真实的偏差” 是客观存在的。
SAC策略迭代:
回顾一下1.4.2算法,策略迭代一般包括两个步骤=策略评估 + 策略提升。暂时不知道为啥这里的SAC算法也用这一套,而不是像Actor-Critic一样直接优化呢?
策略评估:计算每个状态的价值,怎么计算呢?由于对目标做了修正,相应的状态价值也变成
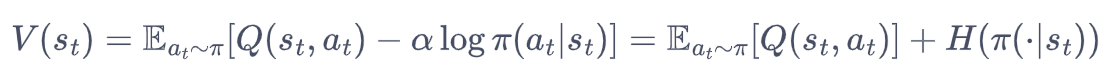
即(动作价值 + 动作熵)的整体期望。这里的期望等价于加权求和,权重就是动作概率。评估完毕(收敛)后,启动策略提升流程。
策略提升:
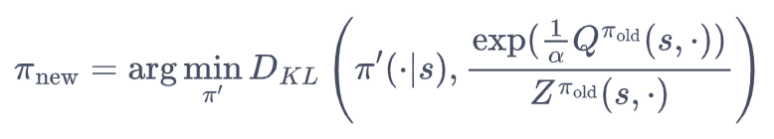
即我们的目标策略具备这样的特征:
① 和目标分布的的KL散度是最小的
② 如何定义目标分布?
我们希望找到新策略 π',使得 “回报 + 熵” 的目标最大化。从数学上,这等价于最小化策略 π'与 “最优导向分布” 的差异。
对单步情况(多步可通过贝尔曼方程递归扩展),目标函数的局部优化可转化为:
![]()

注:这里是求偏导,这是求和符号消失的原因。
如何理解这个目标分布?
可以从softmax温度系数的角度理解,a很小的时候,Q最大的action主导;a很大的时候,分布较为平缓。
SAC
有了上面的策略迭代介绍,下面给出SAC的损失函数:
2个价值网络(主网络+目标网络),1个策略网络。在double-DQN中,模型通过将最佳动作的选择集中到训练网络中缓解估计偏高的问题。SAC则直接使用2个价值网络并取最小值作为目标。则价值网络的目标为:
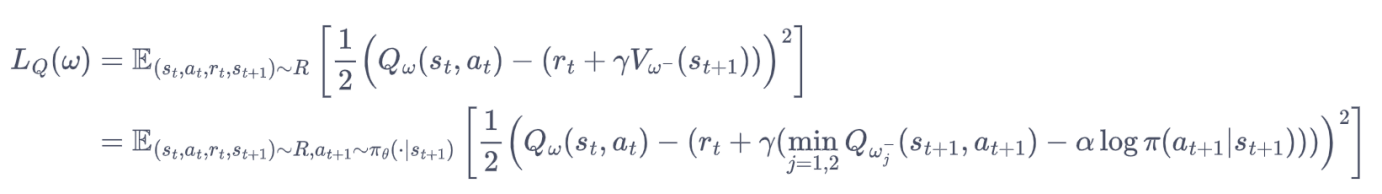
① 价值网络的目标还是均方误差形式
② 可以看到,这里也有训练网络和目标网络的概念,Q的td目标是由目标网络给出的,并且取了一个最小值。(这里使用2个网络取最小值的方法感觉比double-dqn等方法更直接)
③ 总共有4个价值网络=主网络1+主网络2+目标网络1+目标网络2,主网络随时更新,目标网络定期同步,误差计算使用目标网络,策略选择使用主网络。主网络输出状态价值用于迭代策略网络
策略损失由KL散度得到,化简后得到:
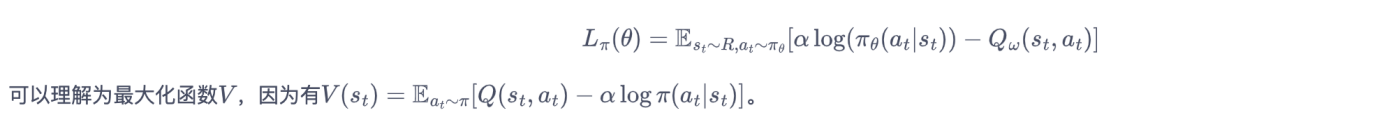
理解:策略评估完成后,策略函数拟合分布为最大熵分布。
问题:好像直接写出这个损失函数容易理解,先推到目标函数为KL散度,再化简的必要性是什么?如果跳过 “KL 散度推导” 直接写损失函数,会丢失 **“为什么要这样设计损失” 的理论逻辑 **,导致算法看似 “凭空出现”,缺乏对 “最大熵策略、策略更新约束” 等核心思想的解释。
重参数技巧:
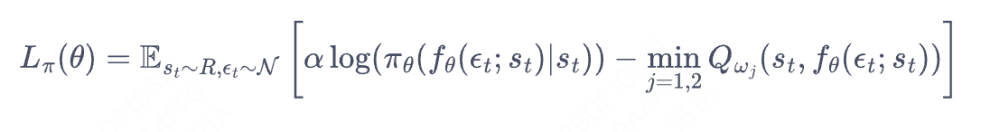
对于连续sa为连续场景的时候,使用冲参数,f是采样的action。e是噪声。
这里是难点,也就是使用重参数技巧采样并计算分布变换后的对数概率密度。
自动调整熵的权重:
给熵设定一个参考值H,低于H则增大熵,超过H则降低熵。将熵的损失函数建模为:
![]()

三、前沿篇
3.1 模仿学习
3.2 模型预测控制(MPC)
一句话总结:谋定而后动,三思而后行。
基于是否构建环境模型帮助智能体决策,可以把强化学习算法分为
- 无模型方法(model-free)
- 基于模型的方法(model)
3.2.1打靶法
首先,让我们用一个形象的比喻来帮助理解模型预测控制方法。假设我们在下围棋,现在根据棋盘的布局,我们要选择现在落子的位置。一个优秀的棋手会根据目前局势来推演落子几步可能发生的局势,然后选择局势最好的一种情况来决定当前落子位置。
假设:一个好的动作会带来最近若干步的奖励最大。即目标为:
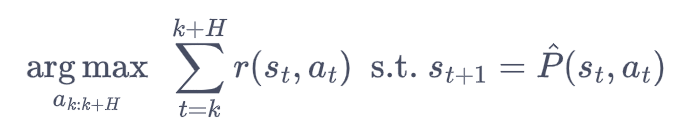
理解:
H是推演的长度,argmax表示选择一个奖励最高的动作序列,动作序列由环境模型输出。
该方法的关键是如何生成一系列候选动作序列。我们把生成候选动作序列的过程称为打靶(shooting)🏹🏹🏹🏹🏹🏹🏹🏹
随机打靶法
假设我们要生成N个序列,每个序列H步。对于H步的每个step,都是从当前环境中随机采样一个action。
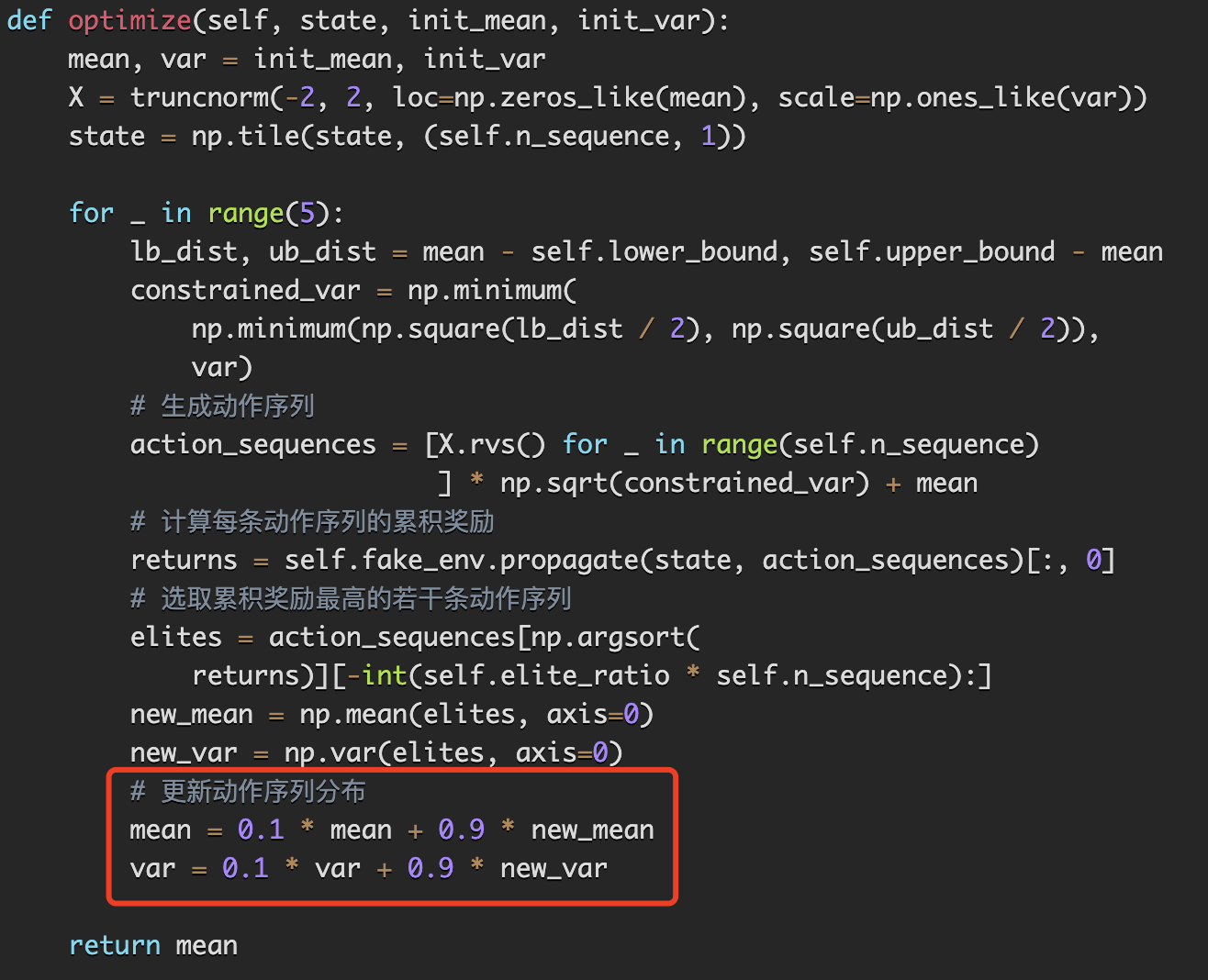
交叉熵打靶法
交叉熵方法(CEM)是一种进化算法,具体而言,它的核心思想是维护一个带参数的分布,根据采样的结果以及获得的奖励来更新参数,使得高奖励的动作可以被更高概率的采样到,伪代码如下:

3.2.2 PETS算法
带有轨迹采样的概率集成:probilistic ensembles with trajectory sampling。
在PETS中,环境模型采样集成学习 + 交叉熵的方法进行模型预测控制。
假设:
环境/系统优两种不确定性:偶然不确定性、认知不确定性。
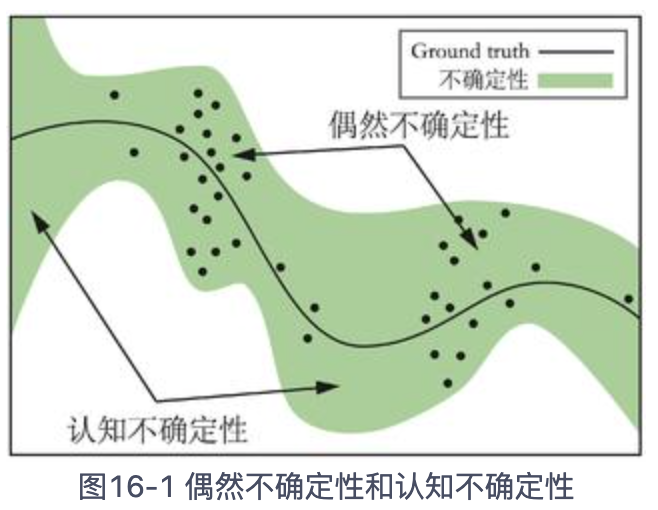
认知不确定:对于没有见过的情景,模型可能预测错误。
偶然不确定:对于训练过的场景,由于系统的偶然性,模型任然可能预测错误。
偶然不确定性
为了缓解偶然不确定性,我们让环境模型get到s-a后,输出下一个状态的分布,而不是偶一个确定的状态。即:
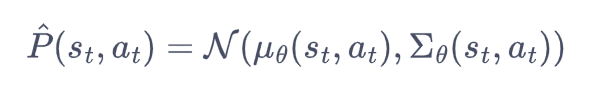
均值和方差都可以用神经网络来模拟。神经网络的损失函数为:
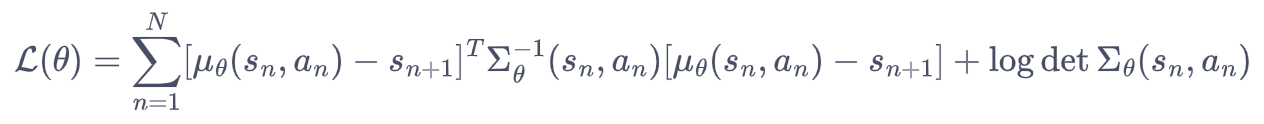
损失函数理解:
PETS 损失 = 高斯负对数似然
= 让网络同时学习「下一状态最可能在哪」和「我对这个预测有多不确定」,为后面的模型预测控制(MPC)提供「既准又自知」的动力学模型。


|
项 |
名称 |
作用 |
梯度行为 |
|
Mahalanobis 残差 |
拟合误差 |
让预测均值 贴近真实;误差越大、权重越大 |
同时回传均值和方差 |
|
log-det 正则 |
熵正则 |
防止网络把方差 无限放大 来「躺平」;鼓励给出「自信但不自负」的不确定性 |
只回传方差 |
与「普通 MSE」的区别
MSE:只优化均值,方差固定 → 无法表达不确定性。
PETS 损失:均值和方差一起学 → 得到异方差(heteroscedastic)噪声模型,方差大的区域 MPC 会自动更谨慎。
在 PETS 整体框架中的角色
训练阶段:用上述损失训练 5~7 个独立网络(ensemble),每个网络输出 ( s^ ,Σ)。
规划阶段(MPC):
用 ensemble 采样多条动力学轨迹。
方差大的地方轨迹发散 → 不确定性高 → 奖励折扣大,从而策略自动「远离」没见过或噪声大的区域。
认知不确定性
这样我们就得到了一个由神经网络表示的环境模型。在此基础之上,我们选择用集成(ensemble)方法来捕捉认知不确定性。具体而言,我们构建多个网络框架一样的神经网络,它们的输入都是状态动作对,输出都是下一个状态的高斯分布的均值向量和协方差矩阵。但是它们的参数采用不同的随机初始化方式,并且当每次训练时,会从真实数据中随机采样不同的数据来训练。
有了环境模型的集成后,MPC 算法会用其来预测奖励和下一个状态。具体来说,每一次预测会从多个模型中挑选一个来进行预测,因此一条轨迹的采样会使用到多个环境模型,如图 16-2 所示。
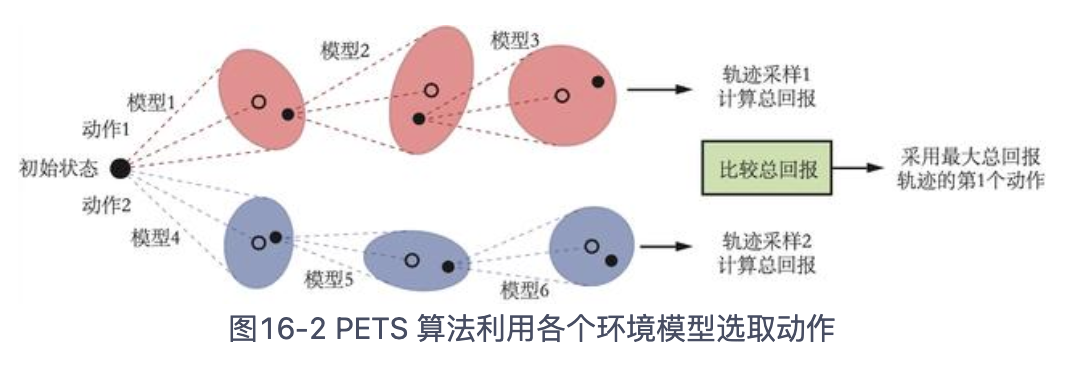
图解:采样模型->采样动作...直到采样H个动作。循环N次。
图中的实心点表示(均值+方差)-采样到的动作,虚心点表示(均值)未被采样的动作。
点击链接查看和 Kimi 的对话 https://www.kimi.com/share/d2jjsr6fn02bjbm8dcog
总结:在以往的RL算法中,策略模型如何选择下一步的动作呢?一般是策略网络直接输出的。随着策略网络的逐渐优化,选择的动作也逐渐最优。
MPC算法,对于当前状态s,模型会选择若干个动作进行序列推演(有点像现在大火的GRPO),并选择最佳动作与真实环境交互。
MPC中,没有actor模型,也没有critic模型,只有环境模型。动作使用交叉熵采样,经环境模型评估经历后,选择最优序列的第一个动作 作为实际选择的动作-环境模型的输入是s-a,输出是奖励+下一个状态。
3.3 基于模型的策略优化(MBPO)
一句话总结:学而不思则罔,思而不学则殆。
通俗理解:如果你学一门技术,那么可以把想象和实践结合起来,因为瞎实践,可能做很多无用功,但是不实践单纯想像可能一到实操就懵逼。所以好的办法是现在脑海中模拟要做的事情,考虑不同的情况,然后到现实中去修正。这样知行合一,加速训练。
MBPO算法的两个观察点:
- 随着推演步数的增加,模型的累计误差会变大
- 必须平衡推演步数增加 带来的 累计误差 与 策略更优
基于此,MBPO提出分支推演概念(branched rollout):只使用模型来访问过的真实状态开始进行较短步数的推演。
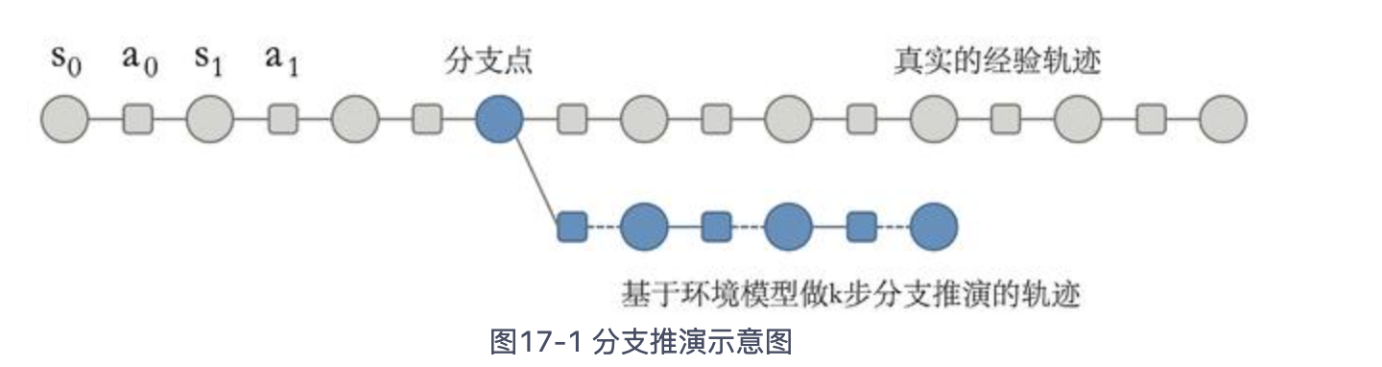
注1:agent与环境交互得到真实state->基于state启动分支推演收集环境模型数据->基于模型数据训练策略模型->...
注2:核心在于学习出一个环境模型,然后生成训练数据

思考1:环境模型的训练数据是什么?就是用真实环境数据基于交叉熵训练的吗?
训练数据就是「真实环境里采到的 (s,a,s') 过渡样本;训练目标通常是「最小化−log p(s'|s,a)」,也就是交叉熵损失。注意:
• 这里的交叉熵是「状态转移分布的负对数似然」,不是分类任务里那种 one-hot 标签的交叉熵。
• 实际工程里还会加一些 trick:固定方差、截断梯度、ensemble(MBPO 用 7 个独立网络做 ensemble 来提高稳健性)。
所以总结:
环境模型的训练数据 = 真实环境采到的 (s,a,s');
训练方式 = 最大化 log-likelihood,即最小化交叉熵损失(或 MSE,如果直接预测确定性下一状态)。
示例:
3.4 离线强化学习
一句话总结:理解优于背诵

3.4.1 先看一组有趣的对比实验
第一个实验,作者使用 DDPG 算法训练了一个智能体,并将智能体与环境交互的所有数据都记录下来,再用这些数据训练离线 DDPG 智能体。第二个实验,在线 DDPG 算法在训练时每次从经验回放池中采样,并用相同的数据同步训练离线 DDPG 智能体,这样两个智能体甚至连训练时用到的数据顺序都完全相同。第三个实验,在线 DDPG 算法在训练完毕后作为专家,在环境中采集大量数据,供离线 DDPG 智能体学习。这 3 个实验,即完全回放、同步训练、模仿训练的结果依次如图所示:
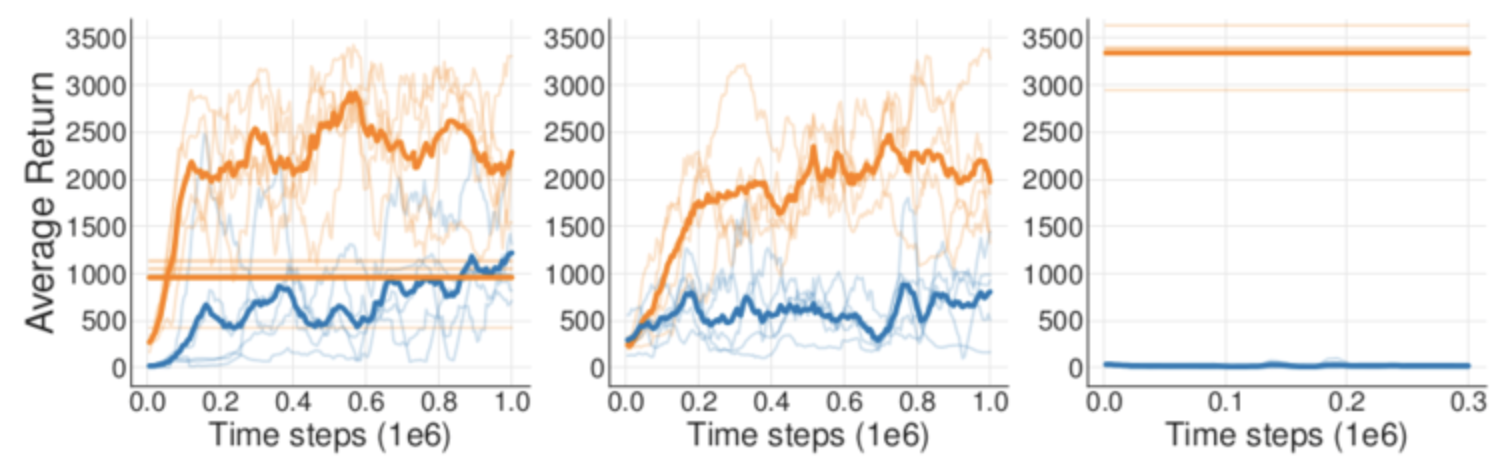
关键:OOD,理解实验误差的关键在于离线模型不是直接利用经验数据硬训练模型,离线模型也会有采样策略,如果策略结果是经验数据中没有的,那他不会放弃这个动作,而是导致了误差累积。(细节看代码理解)
实验1:完全回放,虽然离线模型拿到了在线模型的所有训练数据,但是离线训练的时候可能遇到经验数据未采样到的数据,导致训练受限。
实验2:同步训练,即便顺序一样,不代表离线模型能拿到需要的数据,效果也会差。
实验3:模仿训练,数据的 “行为策略分布” 和 “数据与模型训练阶段的匹配度” 完全不同,效果最差。实验1是从弱到强的全生命周期数据,实验3只有最强数据。
结论:如果想让离线强化学习算法学得好,就要尽量减少外推误差。怎么做呢?=>批量限制策略(batch constraint policy)此类算法有3个目标:
t1:动作拟合,即 选择和离线数据距离近的动作
t2:状态拟合,即 选择和离线数据接近的状态
t3:最大化价值函数
注:一般而言,模型的step函数是随机采样的,这里的限制的含义,就是在经验数据的内部采样。
3.4.2 BCQ算法
总结:无法与环境交互,导致数据不完备(奖励、next state、nextaction),导致只能自己造一些数据并估计价值进行训练。
对于Q-learning,分为离散环境和连续环境,离线环境比较简单,我们直接限制动作即可:
![]()
可以证明,如果D数据完备,BCQ也能收敛到最佳模型。
对于连续环境,我们不能限制模型到某个固定的a,因此需要引入动作的拟合策略:
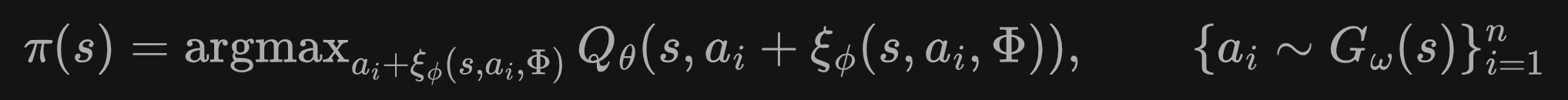
其中G负责生成动作,episilon负责生成扰动(for多样性),完整的伪代码如下:

理解:
1.在Q-learning中,需要完整的s1a1r1s2a2完整序列来训练模型,但是在离线RL算法中,我们无法保证模型在s2状态下认为a2价值最高(随机性),为了让模型能继续训练
2.只采样s1a1r1s2,让VAE生成一系列动作,让扰动模型分别添加扰动,这样就有了一系列候选动作a2',基于{a2'}计算Q的目标值
3. VAE网络训练:真实动作和生成动作距离最小化 + KL散度,即动作更真;
4. Q网络训练:基于目标值,计算均方误差并最小化,即估计更准;
5. 扰动网络训练:最大化扰动的收益,即 扰动后的更好。
3个网络各司其职:一个负责造action(类似actor),一个负责价值迭代(critic),扰动网络的价值是让模型尽量采样到高价值的动作(只有采样到,才能学习到),并且是在安全区内探索,类似TRPO。
3.4.3 保守Q-learning
todo
3.5 目标导向的强化学习
简介
在现实场景中,agent可能要完成很多类似但不同的任务,例如叠衣服的机器人,它所面对的衣服的类型、位置、折叠方法有可能不同,再比如网格世界中,我们的Goal可以设定在不同的位置。但是我们训练的模型可能并于适应目标的变化,例如网格世界,策略和目标是强绑定的。本节要学习的目标导向的强化学习算法GoRL可以学习一个策略,使其在不同目标下都可以work。
问题定义
有别与一般的马尔科夫过程MDP,使用扩充后的元组![]() 来表示目标导向的强化学习MDP,其中:
来表示目标导向的强化学习MDP,其中:
S:状态空间
A:动作空间
P:转移概率
rg:目标相关的奖励
G:目标空间
fayi:状态空间->目标空间的映射,一般是恒等变化或者mdp
奖励函数一般形式
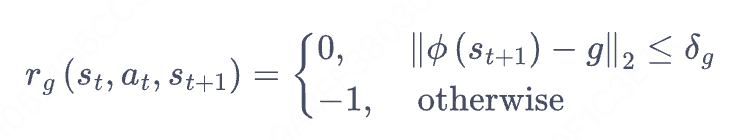
在目标导向强化学习中,由于对于不同的目标,奖励函数是不同的,因此状态价值函数V也是基于目标的,动作状态价值Q函数同理。
目标
定义v0为环境中初始状态s0与目标g的联合分布,那么 GoRL 的目标为优化策略π(a|s,g),使以下目标函数最大化:
![]()
HER算法
在实际的强化学习中,reward往往非常稀疏,模型学习较慢,HER算法通过调整目标,尽量在失败中优化模型,是一种经典的GoRl算法,其伪代码如下:


理解:除了保存上述5元组,还会保存完整的轨迹-trajectory,目标转换时,会从trajectory中采样一个future目标。奖励函数和目标强关联,在原始的目标下该4元组的奖励可能是-1,在新的目标下可能是非负数。
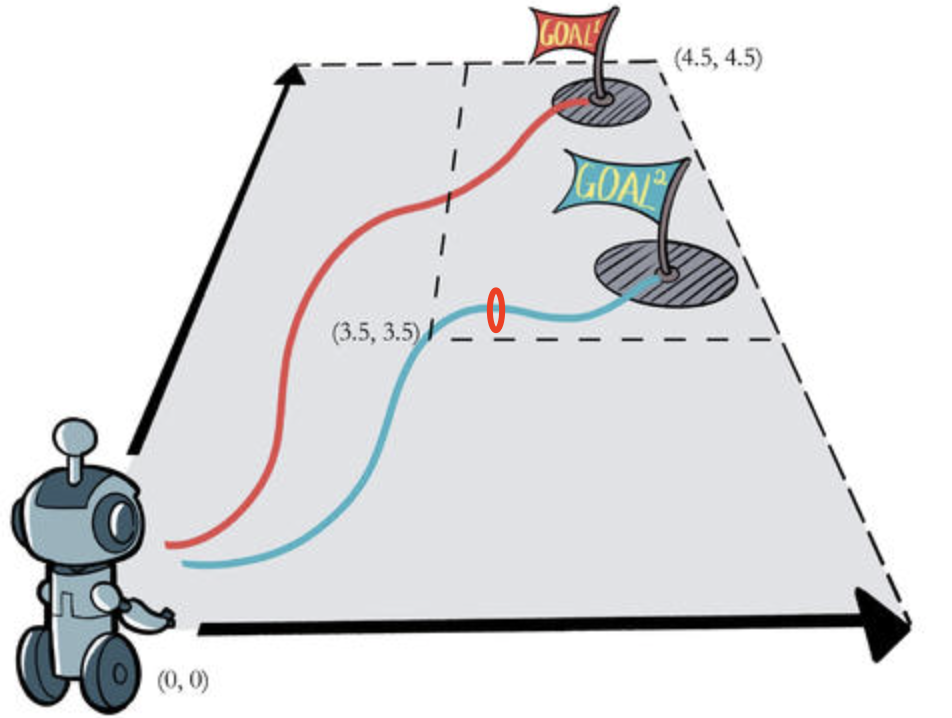
训练过程中,假设目标是Goal2,到达3.5-3.5位置的时候是有意义的,但是奖励是-1,如果我们采样一个新的目标,例如红色点位,那么失败点位变成有效点位。
3.6 多智能体入门
本节之前的RL都是单智能体强化学习算法,如果环境中还有别的智能体一起交互训练,那么任务则上升为多智能体强化学习(multi-agent reinforcement learning,MARL)。
难点:
① 环境非稳态:从任意智能体的视角来看,由于别的智能体的加入,即便在相同state下,采取相同的cation,奖励也可能不同。
② 可能是多目标的,同时训练和评估的复杂度会增加。
问题建模
用5元组表示多智能强化学习问题(NSARP):
N:智能体的数量
S:所有智能体的状态集合
A:所有智能体的动作集合
R:所有智能体的奖励集合
P:环境的状态转移概率
求解范式
完全中心化:把多个智能体决策当做一个超级智能体的决策,把所有智能体的动作当做超级智能体的动作,在这样的范式下,可以认为环境依然是稳态的。缺点是复杂问题,会造成维度爆炸。
完全去中心化:以单个智能体为研究单元,好处是不会维度爆炸,缺点是环境非稳态,训练的收敛性不能得到保证。
IPPO算法
完全去中心化算法也被称为独立算法(independent learning),由于对于单个智能体算法进行PPO训练,因此被称为独立PPO算法,即IPPO算法。具体而言,本节使用PPO阶段进行实验。算法流程如下:

3.7 多智能体进阶
本节介绍一种进阶多智能体训练方法:中心化训练去中心化执行(centralized training with decentralized execution,CTDE),如何理解呢?
中心训练:训练的时候会使用全局信息
去中心执行:执行的时候不使用全局信息,单个智能体基于独立的策略网络执行
通俗理解:一个足球队在训练时会有一个教练指导每个球员如何协作,比赛的时候没有教练了。
CTDE算法主要分为两种,一种是值函数方法,例如VDA、Qmix等,另外一种是AC算法,例如MADDPG、COMA等。本节介绍MADDPG算法。
训练方法介绍:
每个智能体都用DDPG算法进行寻俩

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)