Meta AI 推出 Matrix:2–15 倍性能提升,用去中心化框架革新合成数据生成
面对这一挑战,Meta AI的研究人员推出了一款名为 Matrix 的革命性框架,它通过彻底的去中心化设计,实测能带来。它启示我们,通过精巧的工程架构,可以充分释放现有算力的潜力,解决 AI 大规模应用中的根本性问题。这是 Matrix 性能飞跃的关键!在传统批处理系统(如 Spark)中,一个批次的所有任务必须“齐步走”,而在 Matrix 中,每个“编排器”任务都是一个独立的状态机,它们在 “
📌 前言
在大模型快速演进的时代,高质量的合成数据已成为训练和评估AI 系统的“燃料”。然而,传统的数据生成方式往往受限于集中式处理架构,导致算力浪费、效率低下,最终成为AI研究的瓶颈。面对这一挑战,Meta AI的研究人员推出了一款名为 Matrix 的革命性框架,它通过彻底的去中心化设计,实测能带来 2–15 倍 Token 吞吐提升,为未来的复杂合成数据生成流程提供了一条真实可落地的新路径。
来源:https://arxiv.org/pdf/2511.21686
🎯 核心痛点:为何抛弃“中央总控”?
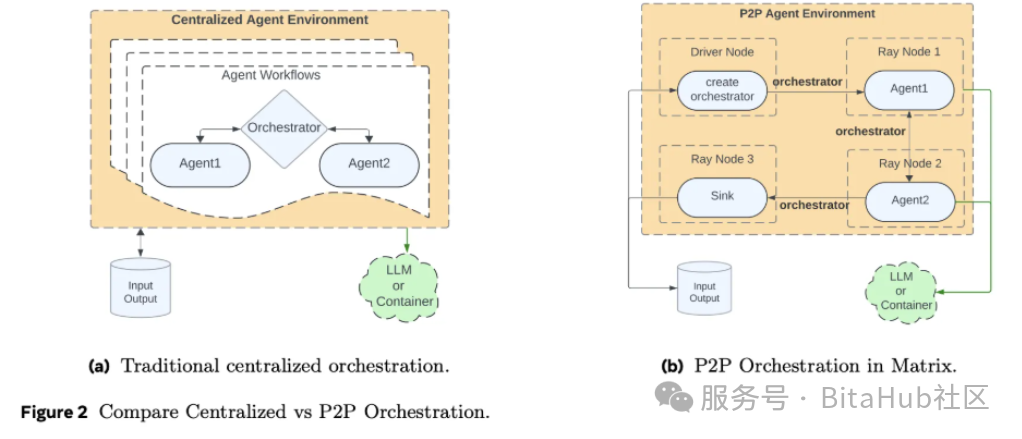
想象一下,目前绝大多数多智能体合成数据框架,都像一个大公司的“中央总控室”。所有的任务调度、数据流转、状态管理,都由这个“总指挥”统一处理。这种模式虽然直观,但一旦任务量井喷(比如需要生成数万甚至数十万并发的对话或工具调用链),弊端便暴露无遗:
-
性能瓶颈:所有请求都涌向中央节点,造成严重系统拥堵。
-
算力浪费:GPU算力大量消耗在等待调度上,而非实际计算。
-
扩展性不足: 难以应对大规模、多样化的任务需求。
这些问题在生成大规模合成对话、工具轨迹、推理链时尤为严重。结论是:这个“总指挥”,已经跟不上了!
🔄 Matrix 的破局:去中心化“对等代理“网络
Matrix 的核心思想简单而精妙:“化整为零,自主协作”。它用一套消息驱动机制,彻底取代了传统的中央控制器。
来源:https://arxiv.org/pdf/2511.21686
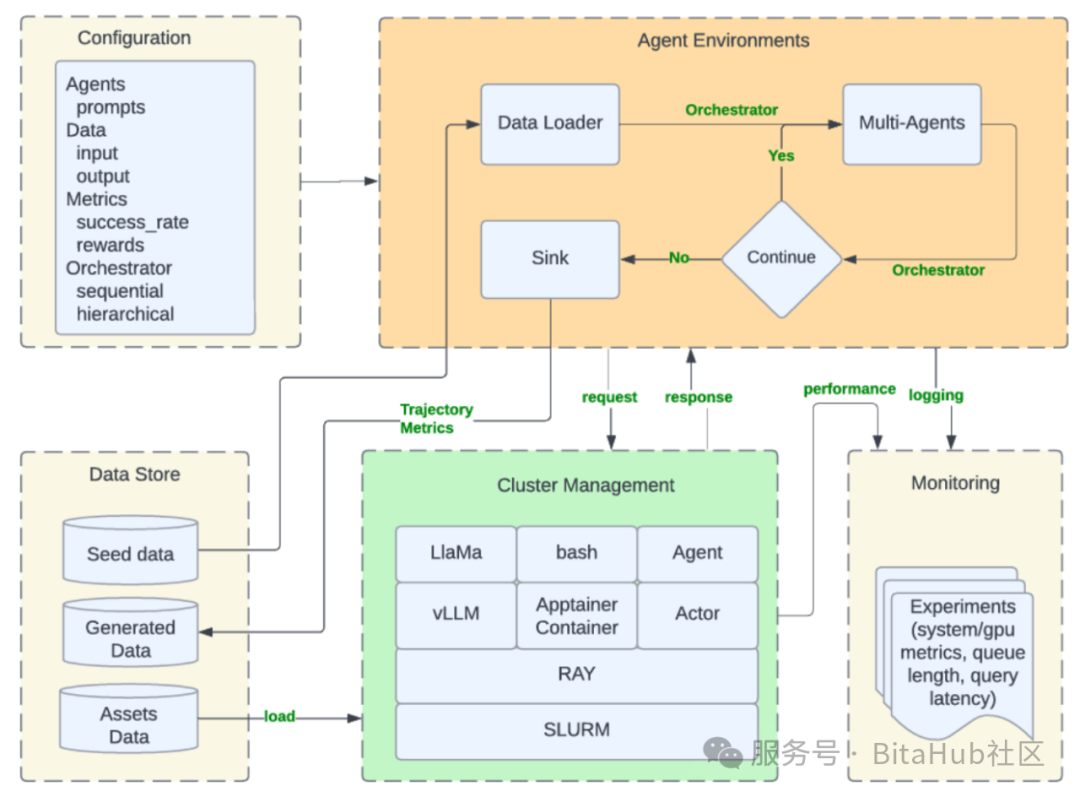
1. 一切皆消息:可携带状态的“编排器”
Matrix 将每个任务的控制流(下一步该做什么)和数据流(当前状态、对话历史等),全部封装在一个名为 “Orchestrator(编排器)” 的对象里。
这个“编排器”就像一个随身携带的“任务档案袋”,记录了任务从开始到结束所需的一切信息,不再需要向中央总部反复汇报。
2. 无状态代理与分布式队列
系统中的每个智能体都是“无状态的”,它们大脑空空,不记事,只负责执行特定逻辑(如“生成对话”、“调用工具”)。它们的工作流程如同高效的流水线:
-
从分布式队列中“取”一个“编排器”消息。
-
根据消息里的指令,执行自己的任务。
-
更新“编排器”中的状态,并直接“推”送给队列中的下一个代理。
没有中央调度器参与主循环,每个任务都是独立推进。
3. 告别”批次同步“,实现”行级推进“
这是 Matrix 性能飞跃的关键!在传统批处理系统(如 Spark)中,一个批次的所有任务必须“齐步走”,而在 Matrix 中,每个“编排器”任务都是一个独立的状态机,它们在 “行级别” 上自主推进(Row-level progress),互不干扰。这极大地减少了因任务长短不一造成的等待时间,并实现了更高效的容错——单条轨迹失败不会拖累整个批次。
🛠️ 强大技术栈与系统优化
🔧 基础设施与工具链
Matrix 并非空中楼阁,它完全构建在成熟的开源技术之上,展现了卓越的工程能力:
-
基础底座:运行在 Ray 集群之上,利用其分布式 Actor 和队列能力。
-
模型服务:通过 Ray Serve 高效暴露 vLLM 和 SGLang 后端的 LLM 节点,也能兼容外部 API(如 Azure OpenAI)。
-
工具隔离:复杂的工具调用通过 Apptainer 容器进行沙盒隔离,安全又稳定。
-
配置管理:使用 Hydra 管理复杂的角色、资源和 I/O 模式配置。
-
实时监控:集成 Grafana,实时监控队列长度、Token 吞吐量和 GPU 利用率。
此外,Matrix 还引入了消息卸载机制。当对话历史过长时,会将其存入 Ray 的对象存储,消息中仅保留轻量级的引用 ID,极大降低了网络带宽压力。
📚 实战检验:三大场景下的卓越性能
💡 案例一:多智能体协作推理
-
任务:模拟两个 LLM 智能体讨论问题并达成共识。
-
🎯 结果:在 31 个 A100 节点上,Matrix 生成了约 20 亿 Token,耗时约 4 小时。而基线系统在最优配置下仅生成 6.2 亿 Token,耗时 9 小时。
Matrix 实现了 6.8 倍的 Token 吞吐量提升,且答案正确率几乎一致。
💡 案例二:网页推理数据清洗
-
任务:从 2500 万网页中,筛选、评分并提取高质量的问答对和推理链。
-
🎯 结果:Matrix 达到了每秒 5853 个 Token 的处理速度。相比之下,采用 Ray Data 的批处理基线仅为每秒 2778 个 Token。
这带来了 2.1 倍的纯系统架构层面的性能增益。
💡 案例三:工具调用轨迹生成
-
任务:模拟客服场景中,智能体与工具、数据库交互解决问题的完整轨迹。
-
🎯 结果:在 13 个 H100 节点上,Matrix 在 1.25 小时内生成了 22,800 条轨迹,吞吐量高达每秒 41,000 个 Token。而单节点的基线仅为每秒 2654 个 Token。
Matrix 的性能优势高达 15.4 倍,且平均奖励分数保持不变。
💡 核心启示
Matrix 的诞生,标志着一个重要趋势:卓越的系统设计,正成为与模型架构创新同等重要的性能驱动力。它成功地将多智能体合成数据生成,从一系列定制的脚本,升级为一个可扩展、高效率、鲁棒的运行时平台。
对于广大 AI 研究者和开发者而言,Matrix 不仅是一个强大的工具,更是一种全新的设计范式。它启示我们,通过精巧的工程架构,可以充分释放现有算力的潜力,解决 AI 大规模应用中的根本性问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)