用变分自编码器生成图像:从原理到实践
VAE为我们打开了生成式AI的大门,展示了如何通过学习数据的潜在结构来创造新内容。虽然它在图像逼真度上可能不如GAN,但其结构化的潜在空间和良好的数学基础使其在许多应用中更具优势。关键要点潜在空间是图像生成的“密码本”VAE通过概率编码引入连续性和结构化概念向量让我们能够“编辑”图像语义自监督学习是未来AI发展的重要方向完整代码已准备,读者可以直接运行实验。如果你对VAE的实现细节或扩展应用感兴趣
用变分自编码器生成图像:从原理到实践
带你探索生成式AI的奥秘:如何让计算机学会创造逼真图像
01 图像生成的革命
如今最激动人心的人工智能应用之一无疑是图像生成。想象一下,计算机不仅能识别图片,还能创造出前所未见的全新图像——这听起来像是科幻小说,但今天这已成为现实。
无论是想象中的风景、虚构的人物,还是从未存在过的动物,AI都能通过学习潜在视觉空间来实现。这一领域的核心就是:将真实图像编码到潜在空间中,再从中采样来生成新图像。
02 潜在空间:图像的“压缩表示”
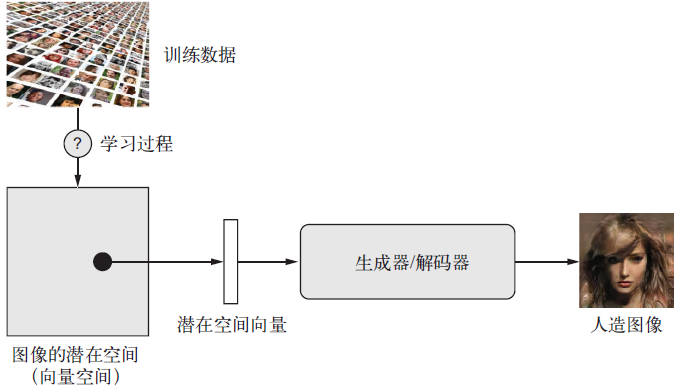
图像生成的关键在于找到图像的低维潜在空间。你可以将其理解为图像的“压缩表示”:
- 潜在空间是一个向量空间,其中每个点都对应一张有效图像
- 学习一个映射函数(解码器),将潜在点转换为图像像素
- 新图像本质上是训练图像的智能插值
03 两种主流技术对比
在图像生成领域,有两种主流技术各具特色:
变分自编码器(VAE)
- 优势:学习结构良好、连续的潜在空间
- 特点:空间中的方向对应数据的有意义变化
- 应用:非常适合图像编辑和概念操作
生成式对抗网络(GAN)
- 优势:生成极其逼真的图像
- 特点:潜在空间可能不够结构化和连续
- 应用:追求最高图像质量的任务

04 概念向量:图像编辑的“魔法棒”
潜在空间的真正魅力在于概念向量。某些方向代表了原始数据中有意义的变化:
- 微笑向量:让任何人脸绽放笑容
- 眼镜向量:添加或移除眼镜
- 性别向量:改变面部性别特征

这个神奇的过程只需三步:
- 将图像投影到潜在空间
- 沿着概念向量方向移动
- 解码回图像空间
05 VAE工作原理揭秘
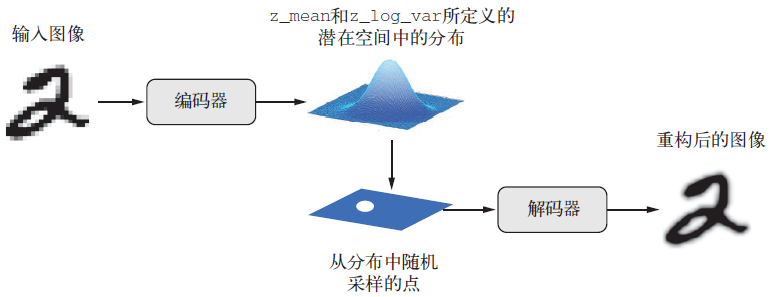
与传统自编码器不同,VAE引入了概率思维:
核心创新:不产生固定编码,而是生成分布的参数(均值和方差)
工作流程:
- 编码器将图像转换为潜在分布的参数(z_mean, z_log_var)
- 随机采样从分布中抽取潜在点:z = z_mean + exp(0.5*z_log_var)*ε
- 解码器将潜在点重构为图像
双重损失函数:
- 重构损失:确保解码图像接近原始输入
- 正则化损失(KL散度):鼓励潜在分布接近标准正态分布
06 用Keras实现VAE
让我们动手实现一个生成MNIST手写数字的VAE:
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
# 编码器网络
encoder_inputs = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(32, 3, activation="relu", strides=2, padding="same")(encoder_inputs)
x = layers.Conv2D(64, 3, activation="relu", strides=2, padding="same")(x)
x = layers.Flatten()(x)
x = layers.Dense(16, activation="relu")(x)
z_mean = layers.Dense(latent_dim, name="z_mean")(x)
z_log_var = layers.Dense(latent_dim, name="z_log_var")(x)
采样层的关键代码:
class Sampler(layers.Layer):
def call(self, z_mean, z_log_var):
batch_size = tf.shape(z_mean)[0]
z_size = tf.shape(z_mean)[1]
epsilon = tf.random.normal(shape=(batch_size, z_size))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
训练自定义逻辑:
class VAE(keras.Model):
def train_step(self, data):
with tf.GradientTape() as tape:
# 编码
z_mean, z_log_var = self.encoder(data)
# 采样
z = self.sampler(z_mean, z_log_var)
# 解码
reconstruction = self.decoder(z)
# 计算损失
reconstruction_loss = ... # 重构损失
kl_loss = ... # KL散度损失
total_loss = reconstruction_loss + kl_loss
# 反向传播
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
return {"loss": total_loss, ...}
07 生成与探索潜在空间
训练完成后,我们可以从潜在空间采样生成新图像:
# 生成潜在空间图像网格
def plot_latent_space(decoder, n=30):
figure = np.zeros((28*n, 28*n))
grid_x = np.linspace(-2, 2, n)
grid_y = np.linspace(-2, 2, n)[::-1]
for i, yi in enumerate(grid_y):
for j, xi in enumerate(grid_x):
z_sample = np.array([[xi, yi]])
digit = decoder.predict(z_sample, verbose=0)[0].reshape(28, 28)
figure[i*28:(i+1)*28, j*28:(j+1)*28] = digit
plt.imshow(figure, cmap="Greys_r")
plt.show()

08 VAE的独特优势
通过实验结果,我们可以看到VAE的几个显著特点:
- 连续过渡:潜在空间中相邻点解码为相似图像
- 平滑插值:不同数字之间可以平滑过渡
- 结构良好:特定方向对应特定数字变化
- 可控生成:通过操作潜在点精确控制输出
09 实际应用与扩展
VAE不仅在图像生成上有用,还可应用于:
- 数据增强:生成训练数据变体
- 异常检测:重构误差高的样本可能是异常
- 风格迁移:分离内容和风格表示
- 半监督学习:利用未标注数据
10 结语:生成式AI的未来
VAE为我们打开了生成式AI的大门,展示了如何通过学习数据的潜在结构来创造新内容。虽然它在图像逼真度上可能不如GAN,但其结构化的潜在空间和良好的数学基础使其在许多应用中更具优势。
关键要点:
- 潜在空间是图像生成的“密码本”
- VAE通过概率编码引入连续性和结构化
- 概念向量让我们能够“编辑”图像语义
- 自监督学习是未来AI发展的重要方向
完整代码已准备,读者可以直接运行实验。如果你对VAE的实现细节或扩展应用感兴趣,欢迎在评论区留言讨论!
思考题:如果我们将VAE应用于人脸生成,如何设计才能确保生成的人脸既多样化又符合真实人脸的特征分布?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)