企业级智能问答系统踩坑实录:RAG老是达不到效果的优化方案
摘要:本文探讨了大模型智能问答系统的开发难点与优化方案。针对多场景混合查询问题,作者从纯RAG技术转向智能体解决方案。最初按三个场景建立知识库导致效果不佳,后改为按数据结构类型划分:一个处理结构化数据(条件查询),一个处理非结构化数据(语义查询),通过type字段区分场景。这种双知识库架构结合智能体工具调用,有效解决了场景判断不准和查询效果差的问题,简化了技术实现并显著提升了系统性能。
由于大模型技术的复杂性,再加上不同业务场景的特殊需求,导致大模型应用的开发难度很大;但大模型应用开发最难的不是做出来而是要做好。
这次还以作者手里的智能问答项目来说,记录一下智能问答系统的踩坑记录,从怎么都达不到想要的效果,到能够很好的满足业务场景。
从作者这些年的开发经验来看,很多时候开发技术栈是有限的,遇到问题更多的是思路问题而不是纯粹的技术问题。
智能问答系统的优化方案
在介绍解决方案之前先来再简单介绍一下项目背景。
作者手里的这个项目是一个智能问答场景,但根据业务类型又区分为三个不同的子场景,并分别对应三种不同的知识问答。业务需求上要求这三个子场景使用同一个入口,并最好能不需要人工区分场景(如三个子菜单或下拉框),能够让系统根据问题智能判断不同的场景并选择不同的文档。
业务架构如下所示:
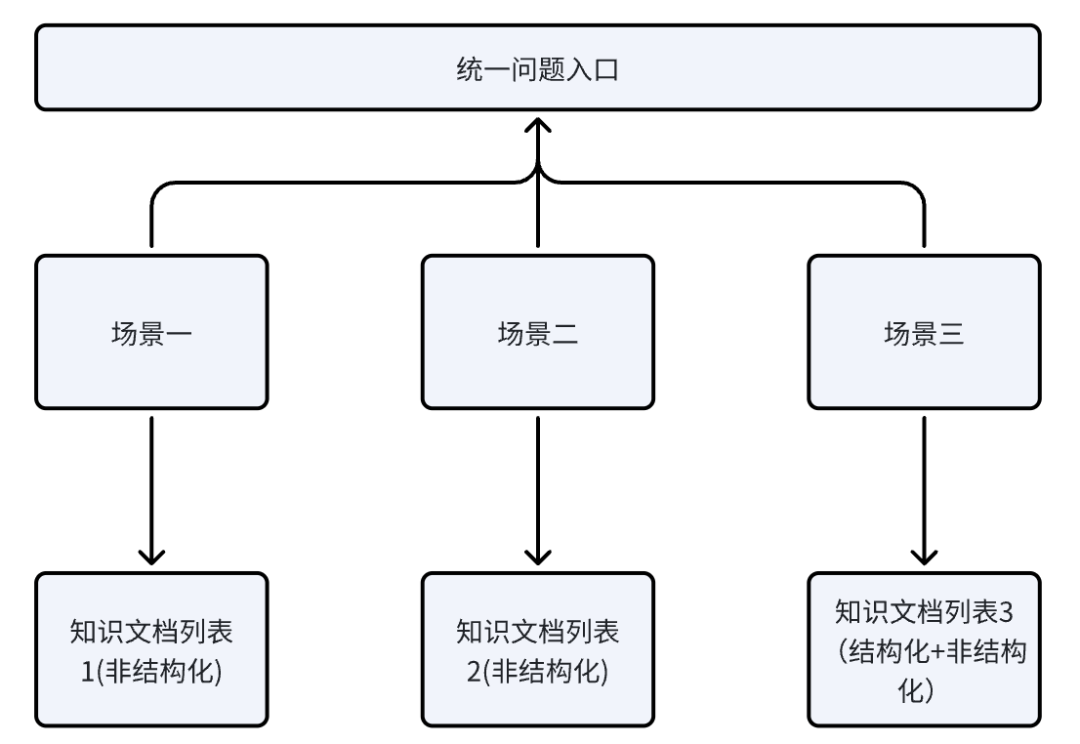
但这里有几个问题,场景1和场景2除了知识文档不同,其它的都很相似,文档类型也都是word,pdf这种非结构化数据;但场景3比较特殊,它的主要功能是查数据,而且文档类型是结构化+非结构化数据。
说到场景3可能有些人不是很理解这有什么特殊的地方,下面我们就来解释一下场景3的特殊点。
先说查数据,在之前的文章中有提到过查数据这个问题;在RAG增强检索中,检索和增强是分开的,并且没有限制检索的方式是相似度语义检索还是基于传统的数据库结构化检索。
但在基于自然语言的对话中,如果使用相似度语义检索很简单,直接把问题和知识转换成向量,然后进行相似度匹配就行了;但如果要使用传统的条件筛选,这就需要使用智能体(agent)技术了。
所以这个就是基于语义检索的缺陷问题,无法实现条件匹配;而智能体可以让模型理解用户的问题,然后生成查询条件调用接口或生成SQL进行条件检索。
第二个问题是,场景3的知识文档是结构化数据+非结构化数据;结构化数据需要使用条件筛选,非结构化数据需要使用语义匹配,这样才能达到最好的效果;虽然理论上把结构化数据转换成markdown或html格式,也可以实现相似度检索,但这种方式在实操检验中效果并不好。
所以说,怎么用技术解决这个问题?技术架构应该怎么做?
刚开始由于业务需求不明确,也没现在这么复杂,并且对业务和技术了解不深;所以作者选择的是使用纯RAG技术解决来实现这个功能,并且基础的技术架构是根据三个子场景,创建三个不同的知识库,也就是三张表(数据量不大,也就几万条)。
技术架构如下所示,是通过把非结构化数据转换成markdown这种半结构化数据保存到向量库中;而结构化数据,采用markdown+元数据的方式进行保存。
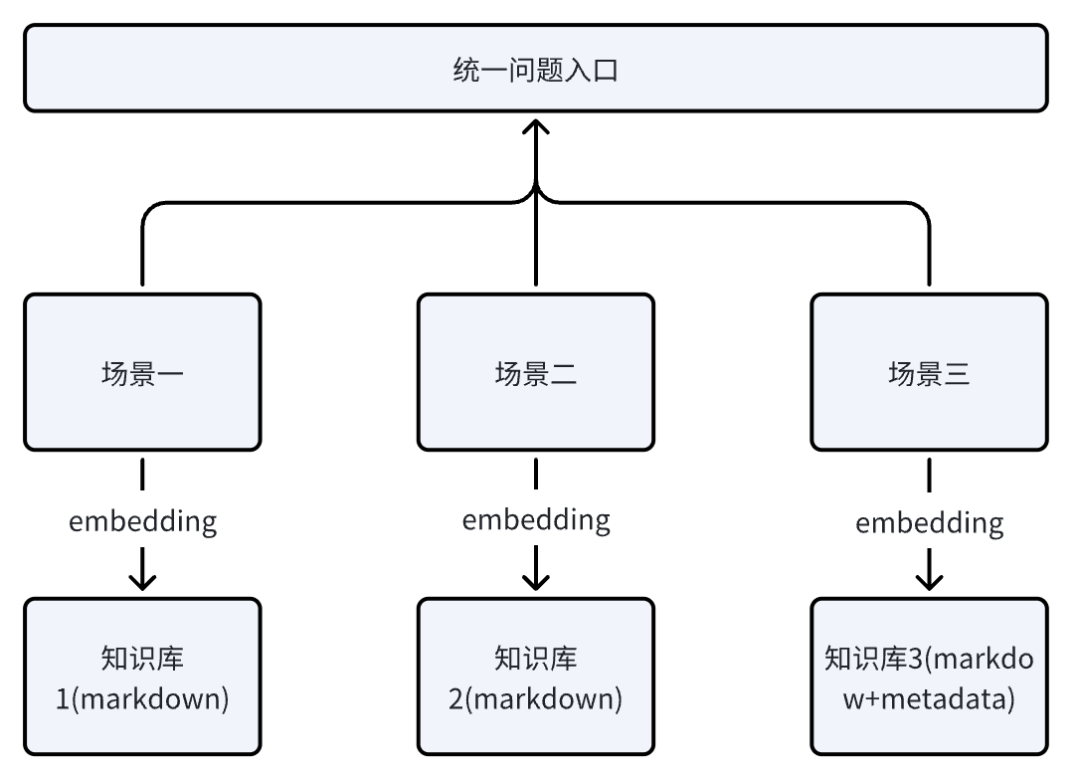

但是,经过实测发现这种效果很差,用户那边一直反馈效果不理想,甚至会胡编乱造;而从技术的角度来看就是,文档召回率和准确率都不足,虽然使用了很多种召回优化的手段,但都没有达到想要的效果,特别是三个场景区分不清楚。
这时作者区分三个子场景的实现原理是,根据用户问题先去三个知识库中分别检索相关数据,然后再重排序之后,找到其中相关性最高的,这个文档在哪个知识库,就是那个子场景。但由于文档召回率和准确率不足,导致场景判断也出现偏差。
所以,这时想的是既然纯RAG或者说相似度检索解决不了问题,那么我们就用智能体去解决。
但说起来简单,但等到真正把技术和业务结合的时候才发现,好像远远没有那么简单。
首先的问题就是,设计几个智能体,从哪个维度设计智能体?
如果给每个场景都单独设计一个智能体,那在不主动区分场景的情况下,我怎么知道调用那个智能体呢?
如果从场景的维度的维度设计智能体,那怎么解决相似度查询和条件查询的问题,工具上怎么设计,怎么实现,怎么匹配?
这个问题大家可以先思考一下,然后再看下面的解决方案。
所以,现在新的解决方案是什么样的呢?
解决方案
首先,作者刚开始就陷入了一个思维误区,那就是知识库为什么要根据三个场景建立三个知识库,不能从其它维度建立知识库吗?
既然三个场景无法区分,并且知识文档分为结构化和非结构化文档,并且只有第三种场景才有结构化文档;那么我们就可以从结构化和非结构化的角度来建立知识库。
因此,作者就创建了两个知识库,一个知识库用来保存第三种场景的结构化数据;这样就可以完全使用条件查询或者组合条件(标量)查询和相似度查询;而另外一个知识库专门用来保存非结构化文档,并且使用type字段来区分三种不同的场景。
这样业务逻辑就简单多了,而且实现智能体时也简单多了;只需要实现两个工具即可,一个是条件查询工具,另一个是相似度查询工具;简单来说就是两个知识库各实现一个查询工具即可。
然后在工具介绍中告诉模型,需要查数据的使用条件查询工具,需要匹配概念,语义的使用相似度查询工具。
这样在调用相似度查询工具时,再根据工具的返回结果中的type字段来判断到底属于哪个子场景。
如下图所示:
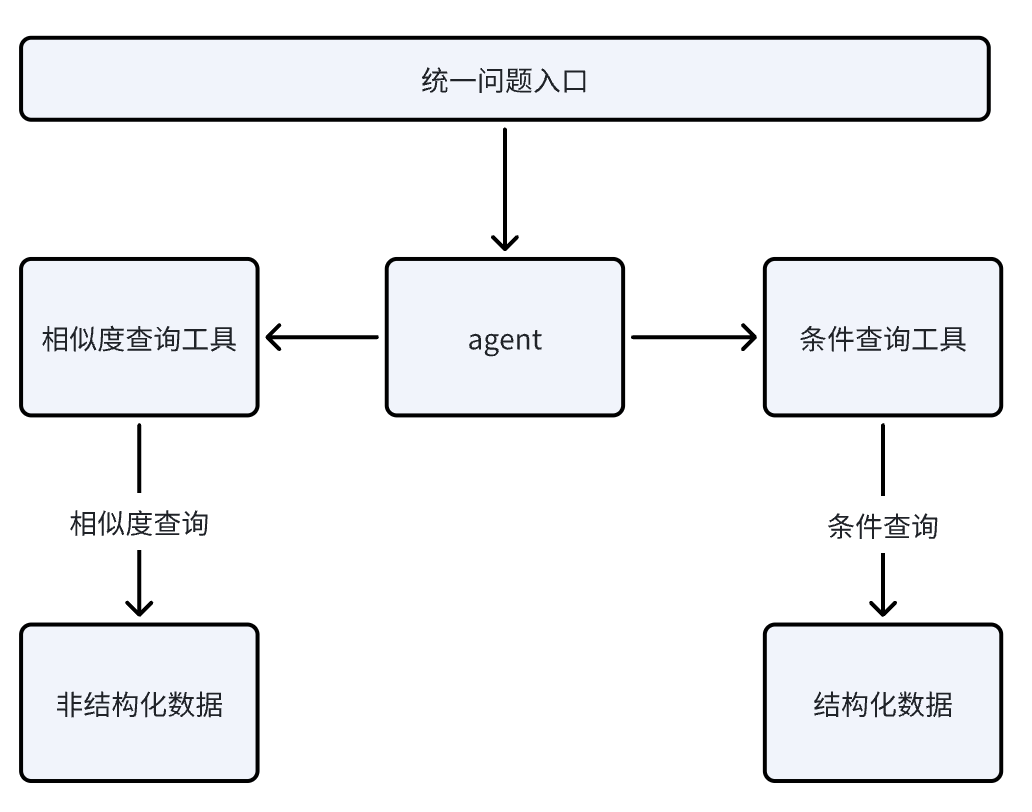
这样就完美解决了结构化文档和非结构化文档的混合查询问题,以及不同场景的判断问题。最重要的是其在技术实现上也变得简单了好多。
而且,经过实际测试,其效果远比之前的纯相似度检索效果要好上许多。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)