Canvas-to-Image:多控制信号,让AI“看懂”你的创作草图
Canvas-to-Image是一种创新的图像生成技术,由Snap公司联合多所高校开发。该技术通过将多种控制信号(如人物身份、姿态、布局等)统一编码为单张RGB画布图像,使扩散模型能够直接解读并生成符合用户意图的高质量图像。其核心创新包括多任务画布设计、6M规模的数据集构建和联合训练策略。实验表明,该方法在身份保留(ArcFace 0.592)、控制依从性(Control-QA 4.875)等指标
项目主页:https://snap-research.github.io/canvas-to-image/
论文链接:https://arxiv.org/abs/2511.21691
前言
Canvas-to-Image 是一项于 2025年11月26日 发布在 arXiv 上的前沿图像生成技术(论文编号:arXiv:2511.21691v1),由 Snap 公司联合弗吉尼亚理工学院(Virginia Tech)和加州大学默塞德分校(UC Merced) 的研究团队共同提出。这项技术旨在解决当前扩散模型在多模态、组合式控制下的局限性,提出了一种全新的“统一画布”范式。
Canvas-to-Image 将多种异构控制信号(如人物身份、姿态、空间布局、文本提示等)统一编码为一张 RGB 画布图像,作为扩散模型的单一输入。模型通过视觉-空间推理直接“读懂”这张画布,并生成高度保真、符合用户意图的图像。
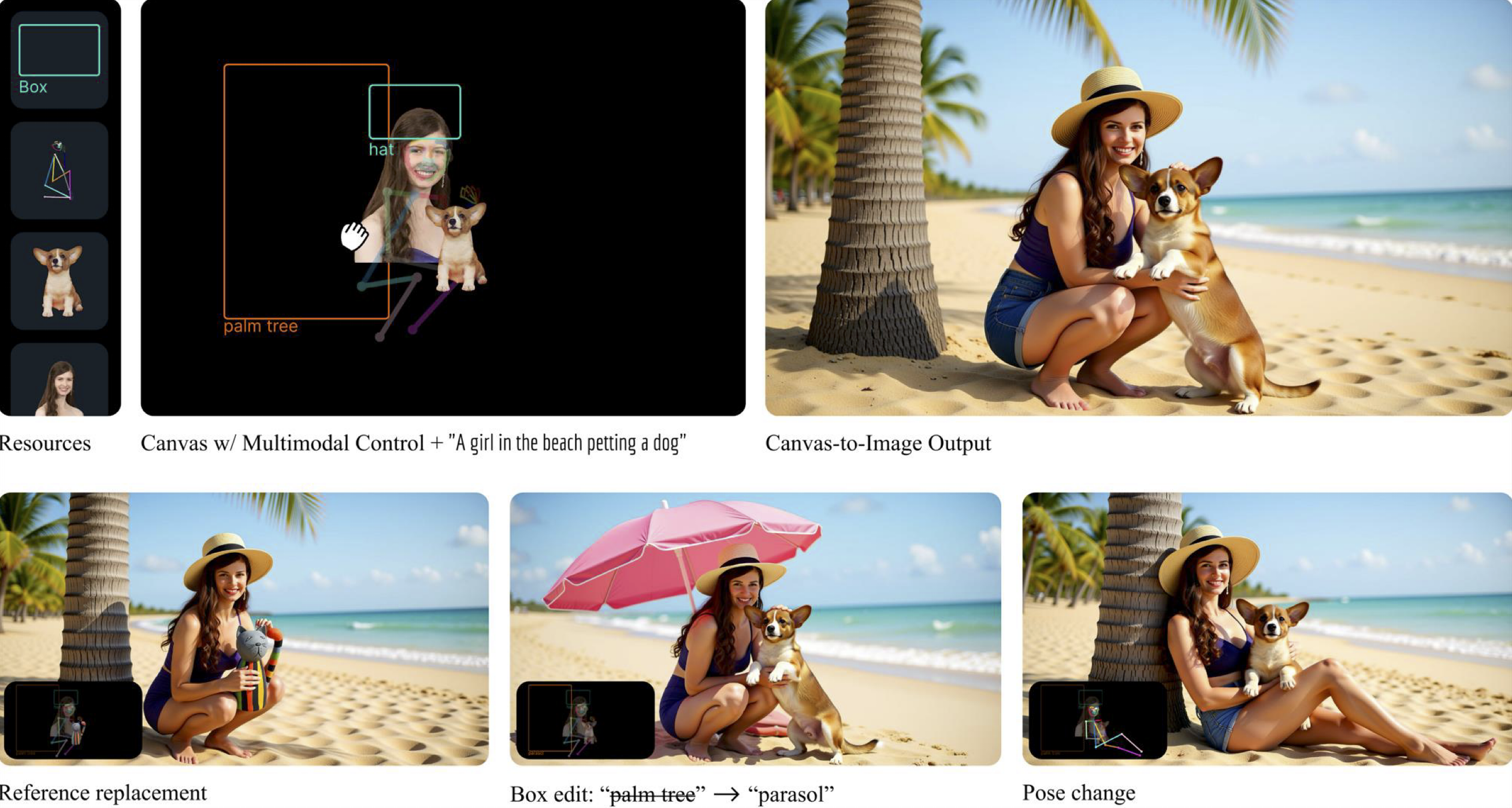
主要有三种画布模式:
1)空间画布(Spatial Canvas)
- 用户将人物参考图碎片贴到画布指定位置。
- 模型据此安排人物在最终图像中的空间关系。
- 适用于多人合影、精确排布等场景。
2)姿态画布(Pose Canvas)
- 在空间画布基础上叠加半透明 OpenPose 骨架线。
- 同时控制身份 + 动作姿态。
- 支持自然动作生成,避免僵硬或失真。
3)方框画布(Bounding Box Canvas)
- 仅用边界框 + 文本标签(如“人物1”、“狗”)定义布局。
- 最抽象但最灵活,适合概念草图式创作。
- 结合 CreatiDesign 数据集增强语义理解。




1. 一段话总结
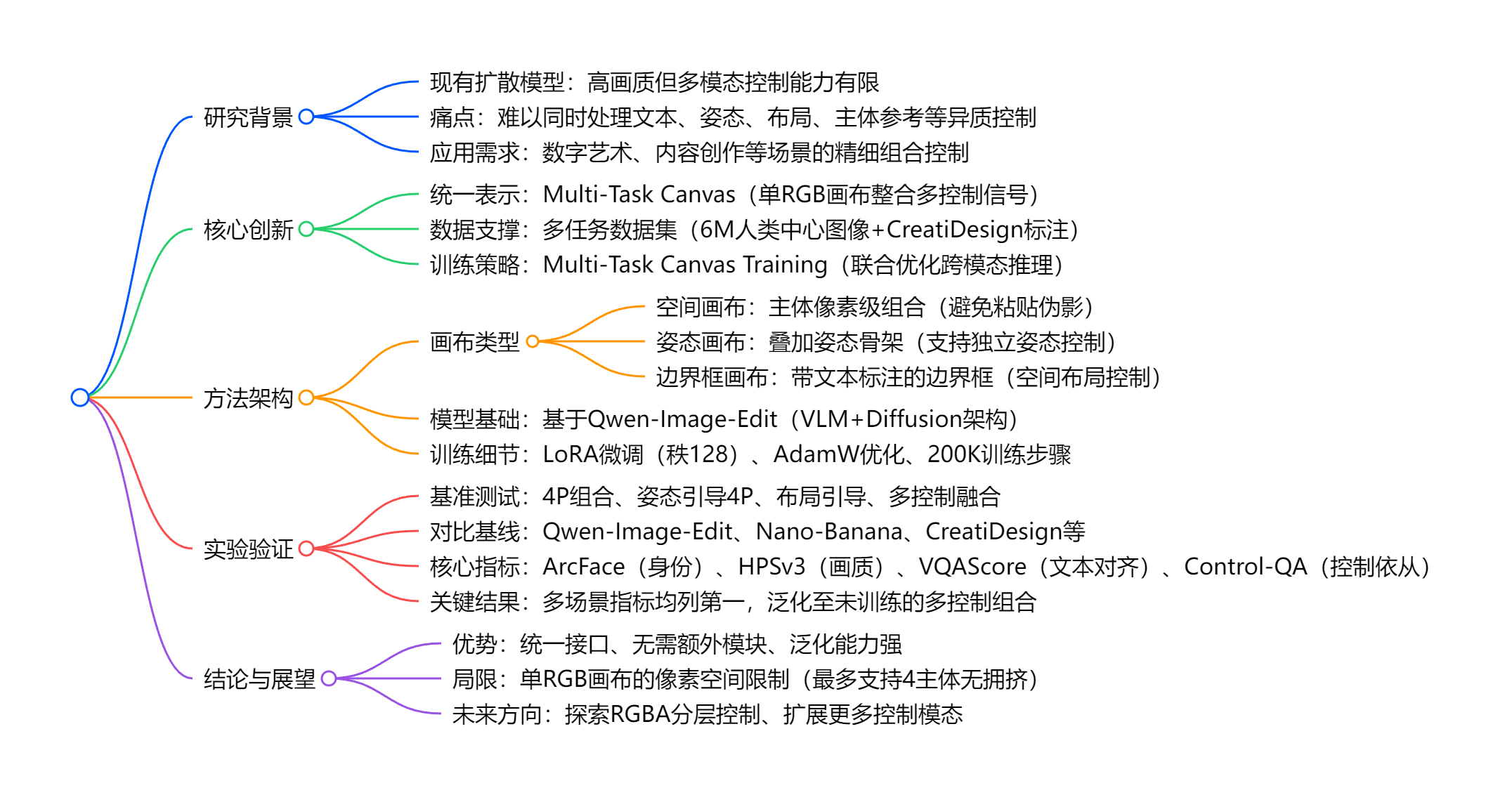
Canvas-to-Image 是一款针对扩散模型的统一多模态组合图像生成框架,核心创新在于将文本提示、主体参考、姿态约束、边界框布局等异质控制信号编码为单个 Multi-Task Canvas(多任务画布)(RGB图像格式),通过专门构建的多任务数据集和 Multi-Task Canvas Training(多任务画布训练) 策略,使模型无需额外模块即可实现跨模态推理,在多主体组合、姿态控制、布局约束及多控制融合场景中,显著提升了 身份保留(ArcFace最高0.592) 和 控制依从性(Control-QA最高4.875),性能全面超越Qwen-Image-Edit、Nano-Banana等现有主流方法,且能泛化到训练中未见过的多控制组合场景。
2. 思维导图(mindmap)
3. 详细总结
一、研究背景与核心问题
- 技术现状:现代扩散模型(如SDXL、FLUX)能生成高画质、多样化图像,但在 多模态组合控制 上存在短板——现有方法仅能处理单一控制类型(如ControlNet侧重姿态、GLIGEN侧重布局),无法同时满足文本、主体、姿态、布局的联合约束。
- 现有方案缺陷:
- 主体注入方法(如IP-Adapter)缺乏空间控制;
- 布局引导方法(如CreatiDesign)无法整合特定姿态/主体;
- 混合控制尝试(如StoryMaker、ID-Patch)依赖复杂模块组合,泛化差、仅支持人脸注入。
- 核心目标:构建统一框架,无需额外模块即可同时处理异质控制信号,实现高保真的组合图像生成。
二、核心创新与方法细节
| 创新方向 | 具体内容 | 关键优势 |
|---|---|---|
| 1. Multi-Task Canvas(多任务画布) | 将所有控制信号编码为单RGB图像: - 空间画布:跨帧采样主体+背景组合; - 姿态画布:半透明姿态骨架叠加; - 边界框画布:带文本标签的边界框 |
统一像素空间,模型直接解读,无需架构修改 |
| 2. 多任务数据集 | - 内部数据集:6M人类中心图像(1M独特身份,跨帧采样); - 外部补充:CreatiDesign数据集(边界框+命名实体标注); - 采样策略:均匀分布各任务类型,平衡监督 |
支持异质控制信号与目标图像的对齐,保障联合训练效果 |
| 3. 多任务训练策略 | - 输入:画布(VLM编码+VAE latent)+文本提示+任务指示符([Spatial]/[Pose]/[Box]); - 损失函数:Task-aware Flow-Matching Loss; - 微调方式:LoRA微调注意力/调制层(冻结前馈层) |
学习跨控制类型的共享语义,泛化至多控制组合场景 |
三、实验设置与关键结果
-
实验配置:
- 硬件:32块NVIDIA A100 GPU;
- 训练参数:学习率5×10⁻⁵,有效批次32,训练200K步骤;
- 评价指标:ArcFace(身份保留)、HPSv3(画质)、VQAScore(文本对齐)、Control-QA(控制依从,1-5分)、PoseAP(姿态准确率)。
-
核心实验结果(定量Top1):
| 测试场景 | ArcFace(身份) | HPSv3(画质) | Control-QA(控制依从) |
|---|---|---|---|
| 4P组合 | 0.592 | 13.230 | 4.000 |
| 姿态引导4P组合 | 0.300 | 12.899 | 4.469 |
| 布局引导组合 | - | 10.874 | 4.844 |
| 多控制融合组合 | 0.375 | 12.251 | 4.281 |
| ID-物体交互组合 | 0.551 | 9.787 | 4.875 |
- 定性结论:
- 无粘贴伪影:优于Nano-Banana的像素复制问题;
- 姿态精准:严格遵循OpenPose骨架,优于ID-Patch的姿态偏移;
- 多控制融合:同时满足身份、姿态、布局约束,优于Qwen-Image-Edit的单一控制偏向。
四、 ablation研究(关键验证)
| ablation变量 | ArcFace(4P组合) | HPSv3 | VQAScore | 结论 |
|---|---|---|---|---|
| 仅训练空间画布 | - | - | - | 无法处理姿态/布局控制 |
| 移除文本分支 | 0.492 | 11.652 | 0.830 | 身份保留显著下降 |
| 移除图像分支 | 0.469 | 12.708 | 0.888 | 语义对齐能力弱化 |
| 解冻前馈层 | 0.560 | 12.485 | 0.858 | 画质与文本对齐下降 |
| 移除任务指示符 | 0.522 | 12.605 | 0.856 | 出现任务混淆(如背景文本伪影) |
五、局限与未来方向
- 局限:单RGB画布的像素空间有限,主体数量过多(>4个)时易拥挤,影响模型解读;
- 未来方向:探索RGBA分层控制(增加Alpha通道)、扩展非人类主体的组合能力、提升复杂场景的光照一致性。

4. 关键问题与答案
问题1:Canvas-to-Image如何解决现有方法无法同时处理多异质控制信号的核心痛点?
答案:核心解决方案是“统一表示+联合训练”。① 统一表示:将文本提示、主体参考、姿态骨架、边界框布局等异质信号编码为单张RGB格式的Multi-Task Canvas,使所有控制信号处于同一像素空间,模型无需额外模块即可直接解读;② 联合训练:基于专门构建的多任务数据集(6M人类中心图像+CreatiDesign标注),通过Multi-Task Canvas Training策略微调扩散模型,让模型学习不同控制类型的共享语义和空间依赖,而非依赖任务特定启发式规则,最终实现跨模态联合推理,自然泛化到多控制组合场景。
问题2:在关键性能指标上,Canvas-to-Image相较于主流基线模型有哪些显著优势?
答案:在四大核心场景中,Canvas-to-Image的关键指标均显著领先:① 多主体身份保留:4P组合场景中ArcFace得分0.592,远超Qwen-Image-Edit(0.258)、Nano-Banana(0.434);② 控制依从性:多控制融合场景Control-QA得分4.281,布局引导场景达4.844,高于CreatiDesign(4.844,并列)、Qwen-Image-Edit(3.813);③ 画质与文本对齐:HPSv3最高13.230(4P组合),VQAScore最高0.935(布局引导),兼顾性能与生成质量;④ 姿态精准度:PoseAP 0.5达70.167,在姿态引导场景中平衡了姿态保真与身份保留,优于ID-Patch的姿态偏移问题。
问题3:Canvas-to-Image的适用场景与当前局限是什么?未来可如何突破?
答案:① 适用场景:数字艺术创作、广告设计、多主体内容生成等需要同时控制“主体身份、空间布局、姿态动作、文本对齐”的场景,支持最多4个主体的无拥挤组合;② 当前局限:依赖单RGB画布的像素空间,主体数量超过4个时易拥挤,影响模型对控制信号的解读精度;③ 突破方向:一是采用RGBA分层控制(增加Alpha通道),扩展画布的信息密度,支持更多主体/控制信号;二是扩展训练数据的多样性,覆盖非人类主体(如物体、动物)的组合场景;三是优化光照与阴影一致性模型,进一步提升生成图像的真实感融合效果。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)