独立创作者怎么做AI电影?它做到了把做电影这件事,还给创作者本身
我做过很多“看起来很电影”的 AI 片段,但有一次我突然意识到:它们像电影,却不是电影。后来我干脆用 3 个完全不同的项目去做验证,结果很明确:即梦的生视频能力能进国内第一梯队、音频也在国内 TOP,这对我来说不是“听说”,而是在实操里反复成立的事实。如果你认真做过独立创作者怎么做 AI 电影,你一定懂那个卡点:画面能卷到很高,但这一步,才是门槛。真正的分水岭,是你能不能一个人把。
我做过很多“看起来很电影”的 AI 片段,但有一次我突然意识到: 它们像电影,却不是电影。
后来我干脆用 3 个完全不同的项目去做验证,结果很明确:即梦的生视频能力能进国内第一梯队、音频也在国内 TOP,这对我来说不是“听说”,而是在实操里反复成立的事实。
如果你认真做过独立创作者怎么做 AI 电影,你一定懂那个卡点: 画面能卷到很高,但作品成立这一步,才是门槛。 真正的分水岭,是你能不能一个人把画面 + 声音 + 情绪 + 叙事跑成一个闭环,而即梦AI:
画面 + 环境音 + 人声对白 + 音乐,是一起生成的,真正实现音画一体。 下面这 3 个案例,就是我从失败到成功的实测过程:
一、案例一:剧情短片|“画面成立,但永远像哑片”
项目背景(真实)
类型:剧情向 AI 电影短片
时长:约 1 分钟
场景:夜晚城市 + 单人心理独白
目标:让观众在 30 秒内进入人物情绪
第一套方案是怎么失败的
一开始,我用的是非常典型、也非常“看起来专业”的 工具组合流:
用生图模型定角色外形和夜景氛围
用视频模型生成运镜和人物动作
用单独的配音工具录心理独白
最后在剪辑软件里贴环境音和配乐
问题很快暴露出来:
画面里的人物情绪是压抑、内收的
但声音永远像是“事后补上去的解释”
情绪点永远慢半拍
成片看起来更像是:
画面很好,但在“被解说”,而不是在“发生”。
被迫换方案后,我只改了一件关键的事
12 月 16 日,我开始用即梦视频 3.5 Pro(Seedance 1.5 Pro)重新跑这个项目。
我刻意没有换分镜、没有换故事, 只做了一个决定:
👉 不再把声音当后期。
我在即梦里实际使用的提示词(完整示例)
这是我当时用来生成核心片段的提示词结构(简化后仍可直接用):
人物:成年男性,独处状态
场景:夜晚城市街道,昏暗路灯,轻微雨后反光
画面:缓慢推进镜头,人物低头行走,情绪压抑
叙事状态:内心独白,非对外讲话
人物对白:
低声、克制的心理独白
语速偏慢,中间有短暂停顿
情绪逐渐从压抑转为疲惫
环境音:
远处车辆经过声
偶尔的风声
城市夜晚的低频背景噪音
音乐:
极弱存在感
低沉、持续铺底
随人物情绪缓慢推进

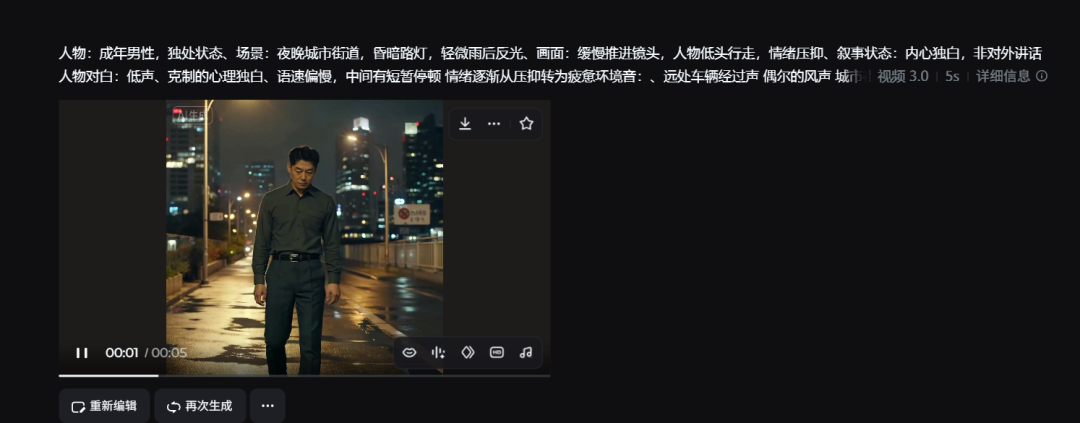
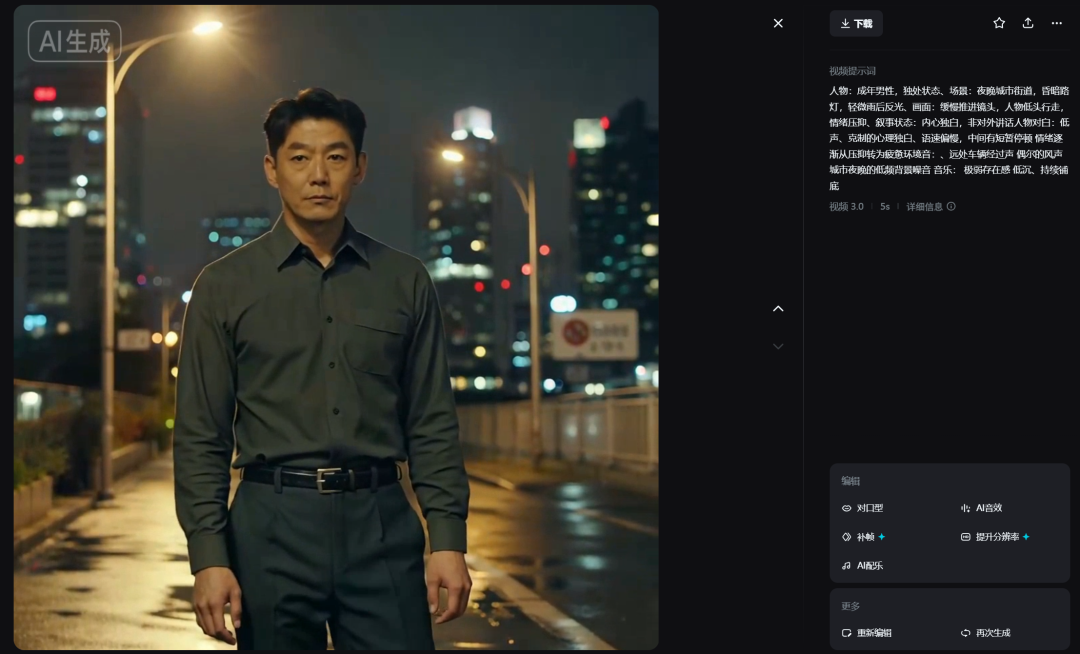
成片变化发生在哪?
生成结果出来的那一刻,我非常清楚地意识到差别:
人声不是“配上去的”,而是从画面里长出来的
环境音不是装饰,而是在帮观众判断空间
音乐不再抢情绪,而是托住情绪
第一次出现这种感觉:
声音不再解释画面,而是参与叙事。
这也是我第一次觉得,这条 AI 剧情短片不再像“哑片 + 解说”, 而是真的开始接近“电影语言”。

二、案例二:世界观短片|“风格统一,但改一次就全崩”
项目背景
类型:科幻世界观 AI 电影概念片
内容:同一人物,多镜头情绪变化
要求:
人物形象稳定
声音风格统一
氛围连续、不中断
这是典型的*世界观先于剧情”的项目,非常考验工具稳定性。
第一套方案的问题在哪里
画面阶段其实已经很好了,但一到修改就彻底失控:
改一句台词
重新配音
再对口型
再调环境音比例
再整体回听
一次小改,半天直接没了。
那一刻我意识到一个现实问题:
独立创作者真正扛不住的,不是生成失败,而是修改成本指数级上升。
换方案后,我在即梦里是这样跑的
在 视频 3.5 Pro(Seedance 1.5 Pro) 下,我刻意把“世界观”写进提示词,而不是只写画面。
我实际使用的核心提示词结构:
人物:同一男性角色,冷静、理性气质 世界观:未来城市,科技高度发展但情绪压抑 画面:中远景切换,镜头稳定、克制 情绪变化:冷静 → 犹疑 → 决断 人物对白: 语气冷静、理性 语速稳定,句尾略微下沉 不同镜头情绪有轻微变化,但声音基调一致 环境音: 持续的城市低频环境音 不同场景有细微变化,但不突兀 音乐: 同一主题旋律 根据情绪强弱调整音量和节奏

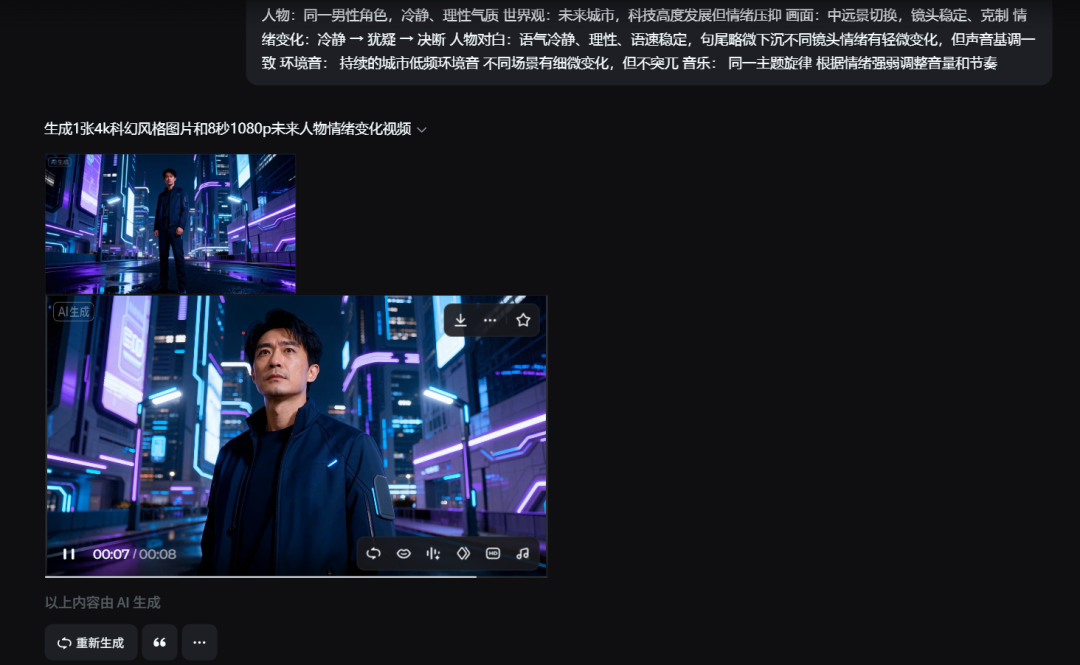

修改阶段发生了什么变化?
后来我刻意测试“最容易崩的情况”:
只改一句台词
不改画面结构
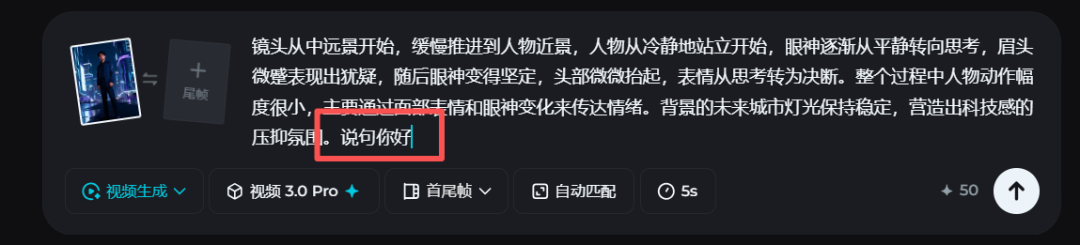

结果是:
直接重出该镜头
声音与画面自动重匹配
人物语气、环境氛围保持一致


这是我第一次真正感受到:
AI 视频不是在“堆素材”,而是在“理解场景约束”。
三、案例三:商业向短片|“不是不好看,是太费人”
项目背景
类型:剧情型产品短片 / 商业广告片
要求:
有故事
有对白
有情绪
最重要:能交付
旧流程的真实问题(非常残酷)
商业项目最怕两件事:
时间不可控
成片不稳定
而旧流程下,我的真实状态是:
一条片子至少 4–5 个工具
每一步都要“确认一次没翻车”
自己反复返工
最致命的不是累,而是:
你根本没精力打磨故事,全在救流程。
新流程下,我是这样用即梦跑的
这一次,我直接采用“一次成片思路”:
1️⃣ 先定美术基调2️⃣ 用视频 3.5 Pro生成视频,增加对白,环境音,音乐的提示词3️⃣ 对白、环境音、配乐同步生成
我用过的一条商业向提示词示例:
产品:科技类消费产品
场景:室内夜晚,极简空间
画面:人物使用产品,镜头节奏稳定
叙事:生活化对话,自然发生
人物对白:
日常语气,不念稿
有停顿,有呼吸
情绪从平静到认可
环境音:
室内安静空间感
细微环境声,不喧宾夺主
音乐:
商业感弱
稳定铺底
突出节奏而非旋律


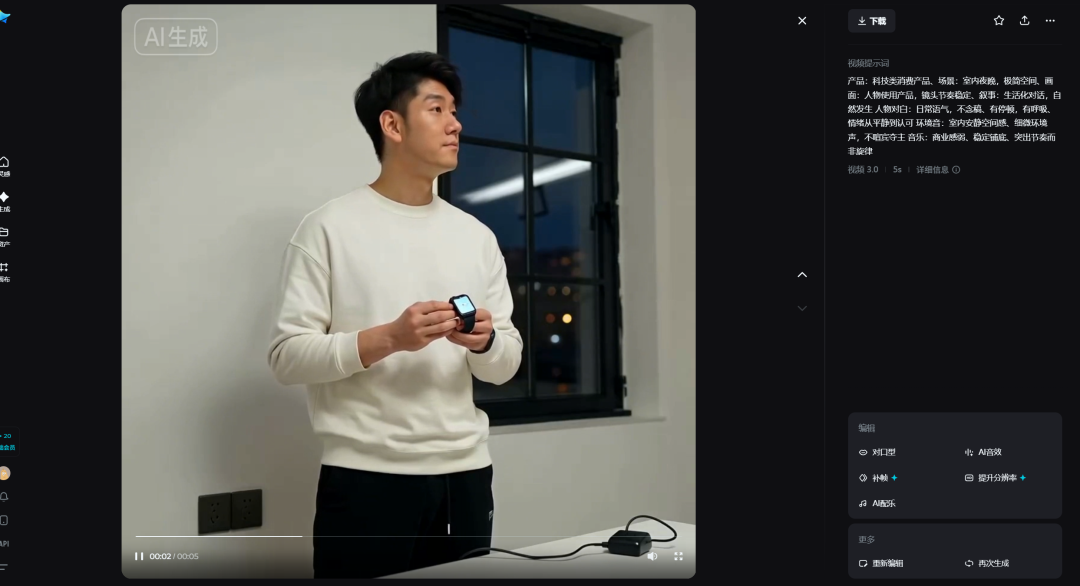

成片后最大的变化是什么?
最直观的感受只有一句话:
它不是“效果更炫”
而是 稳定、可复用、能量产
这也是我第一次真正理解,为什么有人会说它更像:
“一站式 AI 电影工作流”,而不是单点工具。
三个案例跑完,我确认的一件事
不是所有 AI 视频工具,都值得你把时间投进去。 但当 画面 + 声音 + 情绪 + 叙事 被放进同一轮生成逻辑里时, 独立创作者才第一次有机会,把精力真正用在“创作本身”。

四、三种案例跑完后的统一结论
我把 3 个项目放在一起,对比非常明显:
|
关键维度 |
传统方案 |
视频 3.5 Pro |
|
音画关系 |
后期拼 |
生成即同步 |
|
修改成本 |
极高 |
明显降低 |
|
情绪连贯性 |
靠剪辑 |
模型内完成 |
|
独立可行性 |
勉强 |
真实可行 |
|
成片属性 |
像作品草稿 |
像完成片 |
这时我才真正确认一件事:
当生视频能力跻身国内第一梯队,同时音频能力做到国内 TOP,AI 才第一次真正适合独立创作者做电影。

五、回到最初的问题:独立创作者怎么做AI电影?
现在如果再问我独立创作者怎么做AI电影, 我的答案会非常务实:
-
不要迷信“工具数量”
-
不要迷信“单点画质”
-
先看它能不能让你一个人跑完完整流程

在我目前跑过的方案里,即梦视频 3.5 Pro,确实是少数能:
-
同时覆盖生图 + 生视频
-
自动生成环境音、人声对白、音乐配乐
-
把音画一体做到可交付水平
并且,把“做电影”这件事,还给创作者本身,的方案之一。
它不是终点, 但它让我第一次相信:独立创作者,不再只是“AI 拼装工”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)