AI大模型-基本介绍(一)RAG、向量、向量数据库
1. RAG是什么,解决了什么问题2. RAG的工作流程3. 向量是什么,解决了什么问题4. 向量数据库是什么,解决了什么问题5. 向量数据库的工作流程6. 主流的向量数据库有哪些,如何选型
RAG
RAG是什么
-
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合了检索系统和大语言模型(LLM)的技术架构,目的是为了解决传统生成模型在
知识准确性、时效性、可控性等方面的局限 -
通俗的讲法:大模型相当于是一个博学但健忘、且不联网的顾问;通过一个外接数据库(即
向量数据库),解决了两个核心痛点:信息过时和事实性错误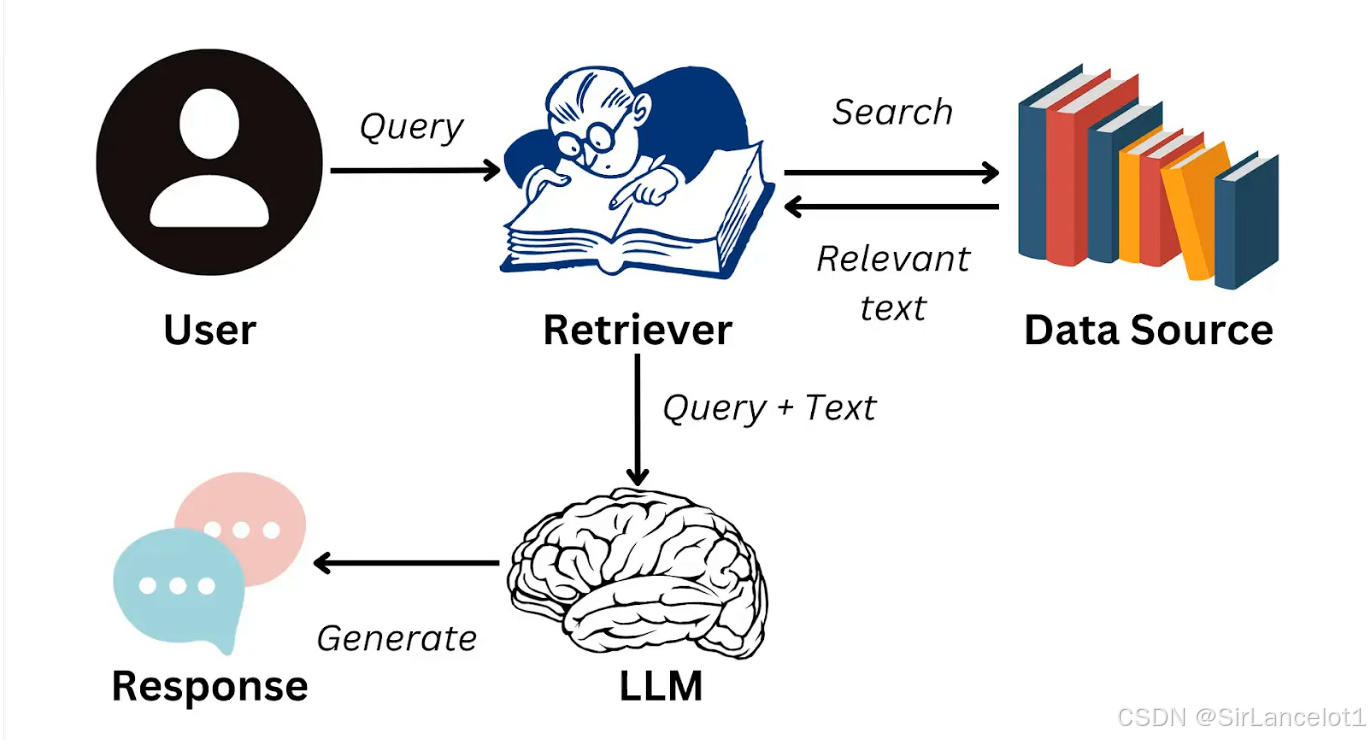
RAG解决了什么问题
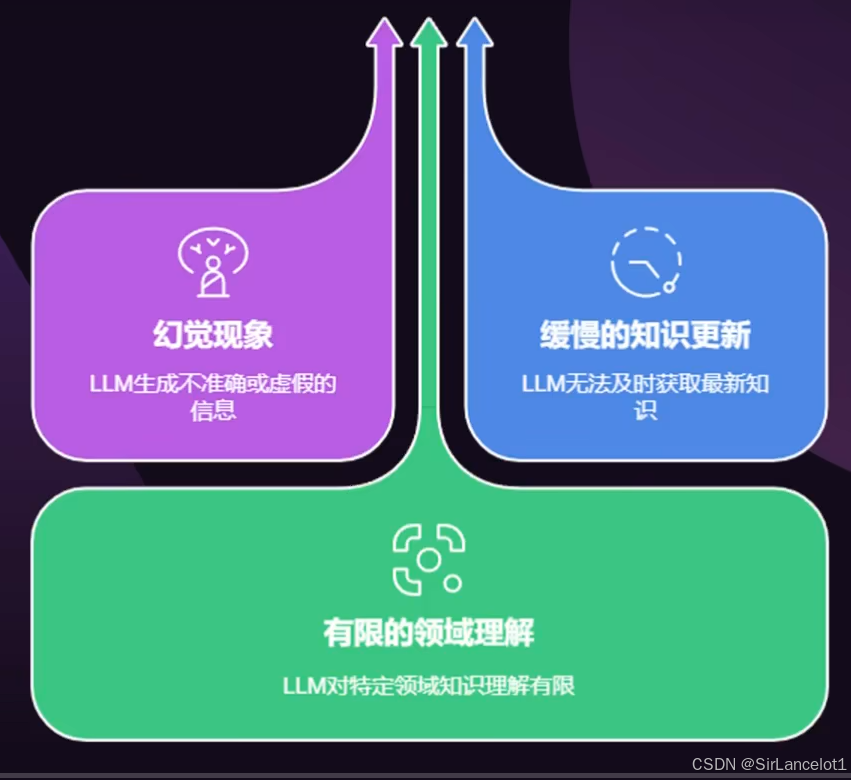
知识过时
- 传统生成模型问题
- 大模型的训练所使用的数据有截止日期,超过截止日期的新信息,大模型都无法获知
- RAG解决
- 在实时更新的
外部知识库中,检索最新资料作为答案依据
- 在实时更新的
AI幻觉
- 传统生成模型问题
- 大模型依赖于训练所用静态数据,会捏造看似合理但是完全错误的内容
- RAG解决
- 用检索的文本来约束大模型的生成内容,确保信息有据可依,大幅提高答案准确性
缺乏领域知识
- 传统生成模型问题
- 对于冷门和领域知识,传统生成模型缺乏足够的训练数据,导致回答质量低
- RAG解决
- 通过检索机制获取相关文档和内容,弥补生成模型本身不足,提升对领域知识的回答能力
溯源与可信度
- 传统生成模型
- 无法知道回答的信息来源是哪里
- RAG解决
- 可以提供引用来源,让回答可追溯、核查,提升可信度
上下文长度限制
- 传统生成模型问题
- 生成模型对输入的上下文长度有限制,过长的信息AI会进行截断处理
- RAG解决
- 通过检索方式灵活引入外部信息,突破上下文限制
个性化于定制化需求
- 传统生成模型问题
- 在一些信息安全有要求的业务领域,以及类似企业业务分析、医疗诊断等场景,用户需要基于特定定制的领域与知识进行问答。
- 生成模型依赖于训练时所使用的的静态数据,且公网的信息无法支撑
- RAG解决
- 通过检索用户提供的私有知识库、特定领域文档,满足定制化需求
成本与效率
-
传统生成模型问题
- 为了学习新知识,重新训练和微调大模型成本巨大
-
RAG解决
- 只需要更新外置数据库,不需要重新训练大模型。实现低成本、高效率的更新
RAG工作流程
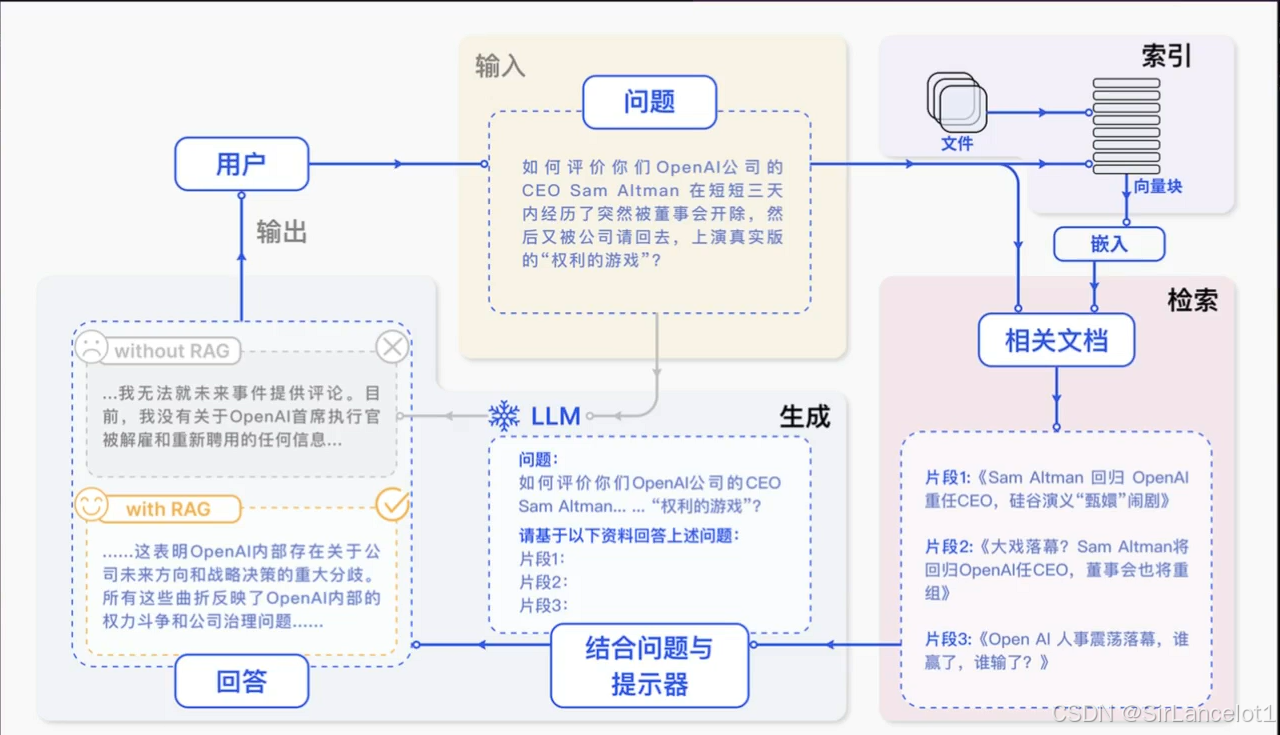
RAG 如何工作:一个三步流程
以一个智能客服回答“公司最新产品政策” 为例:
-
检索:
- 当你提问时,系统不会直接让大模型凭空回答,而是先将你的问题(例如:“最新退货政策是什么?”)转换成向量
- 在公司的政策文档数据库(即外部知识库,通常用我们之前讨论的向量数据库构建)中进行语义搜索,找到最相关的几段原文。
-
增强:
- 将检索到的相关原文片段(例如:“2024年新版政策规定,商品支持30天内无理由退货…”)作为可靠的参考资料,和你的原始问题一起,组合成一个新的、信息更丰富的“提示”。
-
生成:
- 将这个带有参考依据的“提示”发送给大模型,指令其基于给定的资料进行回答。大模型最终生成类似这样的答案:“根据公司2024年最新政策,您购买的商品在30天内可享受无理由退货…”,并可能引用具体条款。
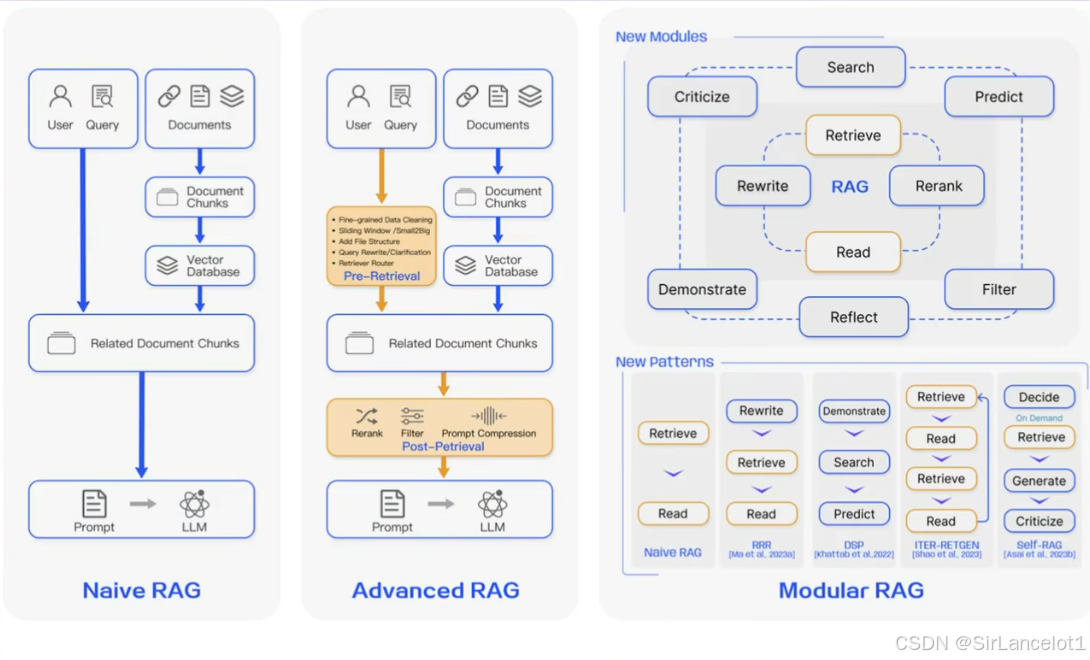
Naive RAG、Advanced RAG、Modular RAG
向量
向量是什么
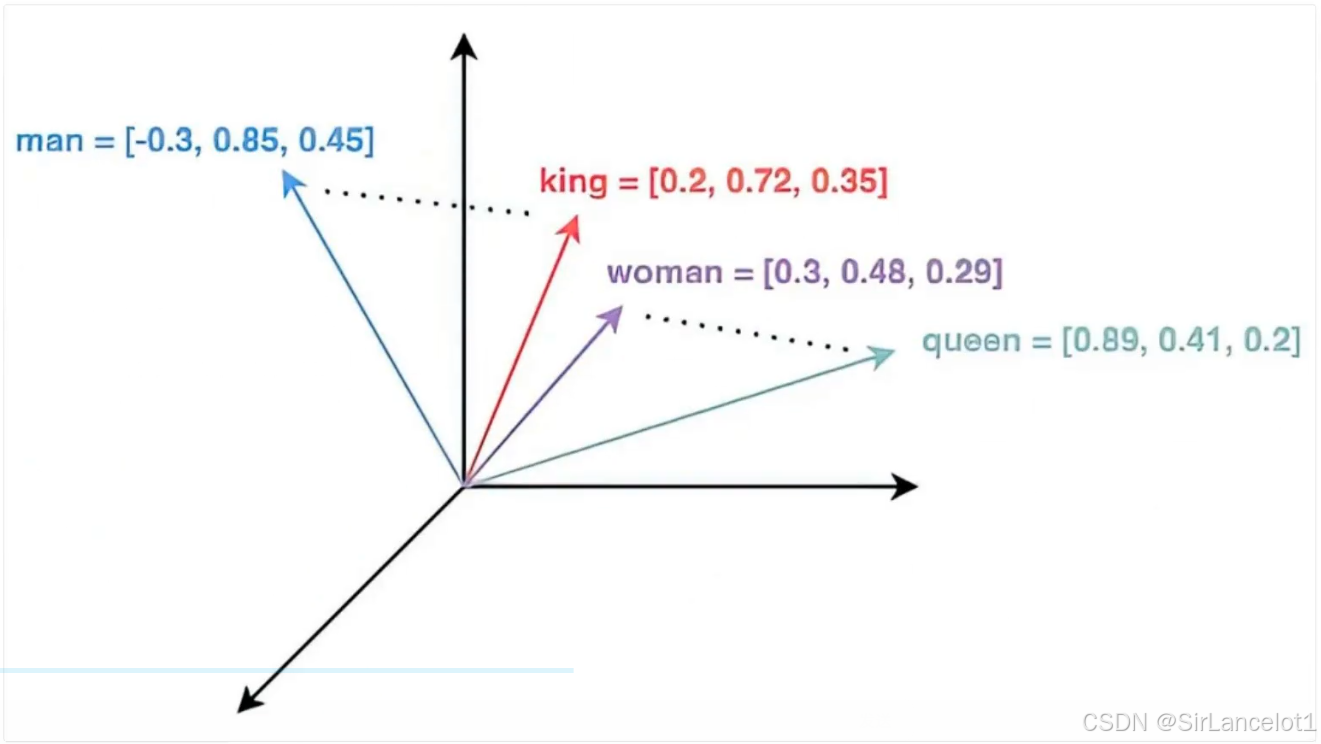
-
在计算机和数据科学领域,向量是一串数字(序列)的集合,是用来帮助机器理解和表达自然语义的通用语言
- 即让自然语义中的事物,通过数字让计算机理解和表达
-
想象一下,我们如何向一个外星人描述“苹果”?
你可以说:它是圆的、红色的、甜的、有梗的…
在机器世界里,我们可以用一串数字来代表这些特征:[0.9, 0.8, 0.7, 0.6, …]
第一个数字 0.9 可能代表“圆度”
第二个数字 0.8 可能代表“红色程度”
第三个数字 0.7 可能代表“甜度”
……
这一串数字[0.9, 0.8, 0.7, …]就是一个向量。它把“苹果”这个复杂对象,转换成了机器可以计算和处理的数学形式。同样,“香蕉”会被转换成另一串不同的数字[0.3, 0.2, 0.9, …]。
“嵌入” 是这个转换过程的名字。我们通过一个叫作 “嵌入模型” 的AI工具,把文本、图片等转换成向量。
向量解决了什么问题
理解与表达信息
- 让自然语义中的事物,通过数字让计算机理解和表达
计算相似性
-
可以通过数字(向量),来计算事物的相似度、关联度
- 两句话的向量很接近,说明他们的意思差不多
- 两个图片的向量很接近,说明他们的图片内容很相似
-
这种相似性计算在很多任务中都很重要,比如搜索、推荐、分类
向量数据库
RAG与向量数据库的关系
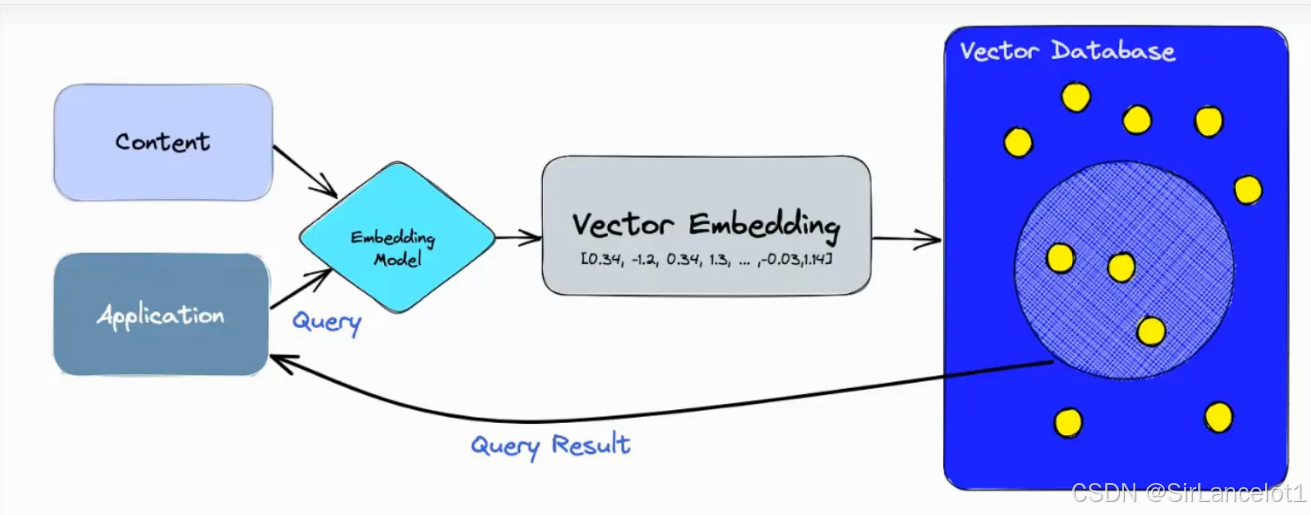
向量数据库的作用
- 高效存储、索引检索非结构化数据(比如文本、图像、音视频)转换为的向量,以便快速找到最相似、最相关的结果
- 将非结构化数据转换为向量,进行查询
- 将非结构化数据转换为向量,进行保存
- 计算向量之间相似度,评估相似度和相关度
工作流程
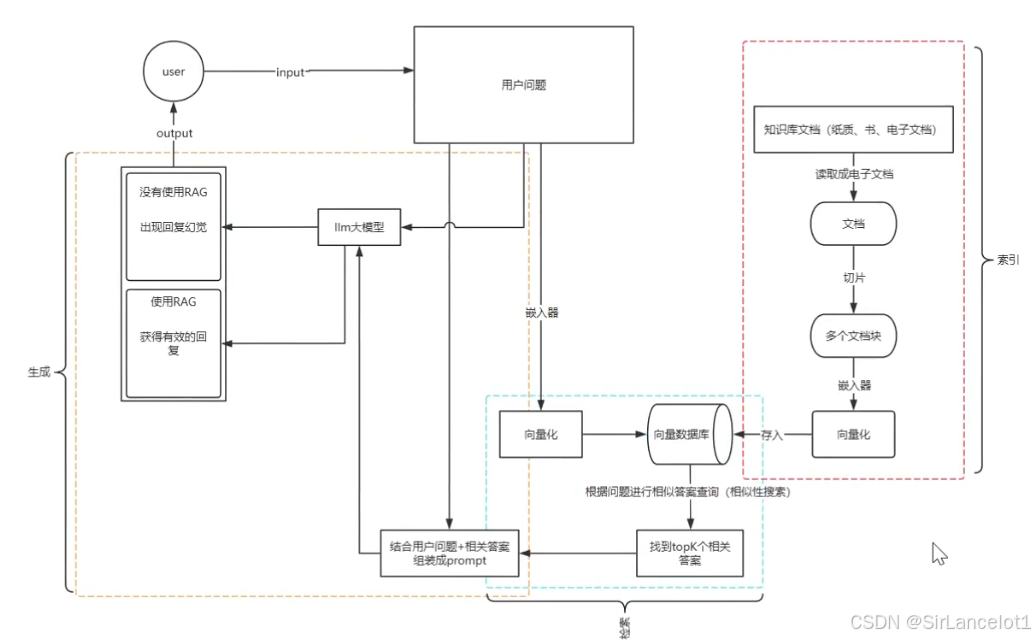
向量数据库-保存流程
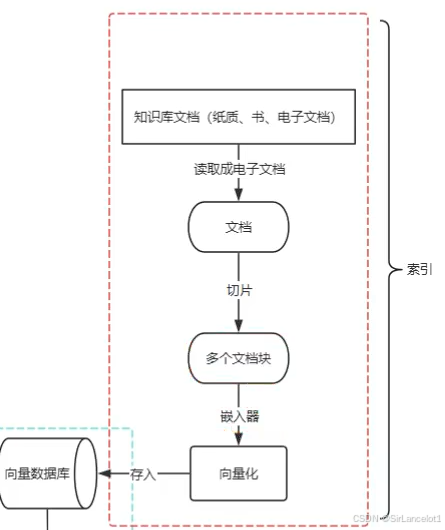
文档提取
- 从各种格式的源文件中(PDF、PPT、markdown、xml、json、txt等)提取出纯文本内容,尽可能保留元数据
- 解析文件格式:使用专门的库或工具处理PDF、Word、PPT、Excel、HTML、Markdown等不同格式,提取其中的文字、表格(转化为文本格式)、图片中的文字(OCR技术)等。
- 提取元数据:同时提取文档的标题、作者、章节、创建日期、文件路径等信息。这些元数据在后续的过滤和溯源中至关重要。
常用工具:PyPDF2、pdfplumber、python-docx、BeautifulSoup、Tesseract(OCR)等,或集成化框架如LangChain、LlamaIndex的文档加载器。
文本切片
- 文本切片,也叫文本分块,是整个流程里最核心、对最终效果影响最大的步骤
- 文本切片指的是,将提取出来的长篇文本,按照一定策略切割成更小的、语义更完整的片段,以便后续转化为向量
- 这些切片后的片段,是向量数据库存储和检索的基本单元
向量化(嵌入)
向量数据库选型
| 产品名称 | 类型 / 托管方式 | 核心特点 | 典型适用场景 |
|---|---|---|---|
| Milvus | 开源 / 可托管 | 专为AI设计,支持十亿级向量规模,社区生态活跃。 | 大规模语义搜索、推荐系统、RAG应用。 |
| Pinecone | 全托管云服务 | 无需运维,开箱即用,支持实时索引更新,内置GPU加速。 | 需要快速验证和低延迟的实时推荐系统。 |
| Weaviate | 开源 / 可托管 | 支持图向量混合查询,内置模块集成LLM,适合RAG和知识图谱。 | 智能问答、知识图谱构建、多模态搜索。 |
| Qdrant | 开源 / 可托管 | 基于Rust开发,性能出色,支持强大的过滤功能。 | 电商推荐、内容安全过滤等需要复杂过滤的场景。 |
| Vespa.ai | 开源 / 可托管 | 被GigaOm评为顶级产品,强调在检索中融合向量、文本和结构化数据。 | 需要复杂、可定制的搜索和排序功能的大规模应用。 |
| Chroma | 开源 | 专为LLM应用设计,集成了文档分块和嵌入生成,开发者友好。 | 快速搭建RAG管道、开发基于自定义知识的ChatGPT应用。 |
| 腾讯云 VectorDB | 全托管云服务 | 国内云厂商产品,支持亿级数据实时更新,集成对象存储。 | 国内企业有合规要求或已在腾讯云生态内的项目。 |
| PGVector | PostgreSQL扩展 | 作为PostgreSQL插件,支持ACID事务,可同时处理结构化数据和向量。 | 已有PostgreSQL,需增加简单向量搜索功能的应用。 |
AI预研场景
- 核心目标是快速验证想法,构建原型
- 选型侧重上手速度、开发体验、社区生态
- 推荐
- Chroma
- PGVector
- Milvus Lite
- OceanBase seekdb
Chroma
- 专为LLM应用设计,与LangChain等框架集成极佳,极大简化从文档加载、向量化、检索的整个过程,构建RAG原型最快的向量数据库
- 相比Milvus轻量很多,学习和部署门槛低
PGVector
- 熟悉PostgreSQL团队最平滑的选择,作为插件使用,可以在SQL环境下处理向量,可以实现结构化数据和向量数据的联合查询
- 学习成本低,与PostgreSQL现有系统集成简单
Milvus Lite
- 主流开源向量数据库Milvus的轻量级单机版,API与集群版一致,便于后续升级
Pinecone
- 全托管云服务,基本闭源(部分托管服务免费)
- 无需运维,开箱即用,支持实时索引更新,内置GPU加速
- 适用于需要快速验证和低延迟的实时推荐系统
OceanBase
- 主打一体化混合搜索和极简部署(pip install一键安装),适合想尝试AI原生数据库的团队
实际业务交付场景
- 核心目标是系统稳定上线,支撑业务
- 选型侧重性能、可靠性、扩展性、企业支持
- 推荐
- Milvus(可搭建集群)
- Vespa.ai
- Qdrant/Weaviate
- 主流云厂商托管服务(如腾讯云VectorDB、百度VectorDB、火山引擎VikingDB等)
Milvus
-
核心优势
- 支持超大规模的RAG场景:从数以亿计的文档中快速、准确地检索相关知识
- 多模态和跨模态搜索:图文互搜、视频内容检索
- 支持混合查询(向量+标量)
-
缺点
- 架构复杂度高
- 资源消耗较大
- 运维要求相对高,虽然自动扩展降低了日常运维难度,但维护一个分布式Milvus集群仍然需要具备一定的云原生和分布式系统知识。选择全托管云服务是降低运维负担的有效方式
-
适用场景
- 海量人脸/图像库检索
- 大规模推荐系统
- 多模态搜索。
Weaviate
-
开源,AI原生的向量数据库,集成了AI模型和强大搜索引擎的系统
-
核心优势
- 强大的混合搜索,支持向量相似性搜索与关键词过滤(BM25),结构化属性过滤深度融合,实现语义理解+精准匹配
- 模块化与AI原生,通过模块集成,可轻松使用内置或第三方模型(如OpenAI、Hugging Face)自动将数据向量化,无需额外编写ETL代码。最新版本支持在RAG中动态切换生成模型
-
缺点
- 架构复杂度、资源消耗相对较高,由于其模块化设计和丰富的功能,相较于一些极简的向量存储方案,Weaviate对计算和内存的资源需求更高
- 社区规模相对较小
-
适用场景
- 复杂RAG系统:需要结合语义搜索和精准关键词过滤来提升检索质量
- 知识图谱与智能问答:支持以对象-属性的方式存储数据,便于构建带有关系的知识体系并进行查询
- 电商与内容平台搜索:混合搜索能力非常适合商品检索、内容推荐等需要同时理解用户意图和匹配精确规格的场景
Qdrant
-
高性能向量相似性搜索的开源向量数据库
-
核心优势
- 专注于向量相似性搜索,擅长处理严格条件过滤的复杂查询。
-
缺陷
- 专注于向量相似性搜索,不提供内置的文本分词和词法搜索引擎(如BM25),其全文检索能力需通过Payload的精确匹配或外接其他系统实现
- 查询能力= 向量检索 + 基于Payload的标量过滤。
-
适用场景
- 实时推荐、广告系统、需要复杂业务规则过滤的检索
Vespa.ai
-
可以处理海量数据的全文搜索引擎和向量数据库,实时、集成的一体化平台
-
核心优势
- 全功能集成,省去了组合多个专用系统(如搜索引擎、向量库、推理引擎)的复杂性与延迟开销。
- 混合搜索能力,世界领先的全文搜索引擎和强大的向量数据库,支持将关键词、向量、属性过滤等多种查询方式无缝结合(即混合搜索)
- 极致扩展与低延迟,面向海量数据,设计目标是处理数十亿级别的动态数据,且仍然能保证延迟低于100ms
-
缺点
- 学习曲线陡峭:功能强大也意味着系统复杂,需要学习其特有的配置、Schema和查询语言。
- 运维复杂度:自托管部署需要管理分布式集群,对运维团队有较高要求(云托管服务可缓解此问题)。
- 相对小众:相较于Elasticsearch等更普及的工具,社区和资源相对较小。
-
适用场景
- 需要低延迟、复杂AI排序的在线服务
- 对检索相关性和响应速度有严苛要求的智能推荐与个性化系统
- 融合搜索与导航的复杂应用:例如电商网站,需要同时支持关键词搜索、向量搜索(如图搜图)、属性筛选和个性化排序。
- 面向生产环境、追求极致的“一体化AI应用引擎”。
- 希望用统一系统简化技术栈的团队
- 需要低延迟、复杂AI排序的在线服务

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)