基于强化学习DDPG算法的ACC自适应巡航控制器设计
动作空间代表Agent可以采取的行动。对于ACC系统,自车的加速度就是我们的动作。代码分析:这里用函数定义了一个数值型的动作空间,大小为[1 1]也就是一维,下限为-2,上限为2,并给它起了个名字叫,这样在后续训练中,Agent输出的动作(加速度值)就会在这个范围内。
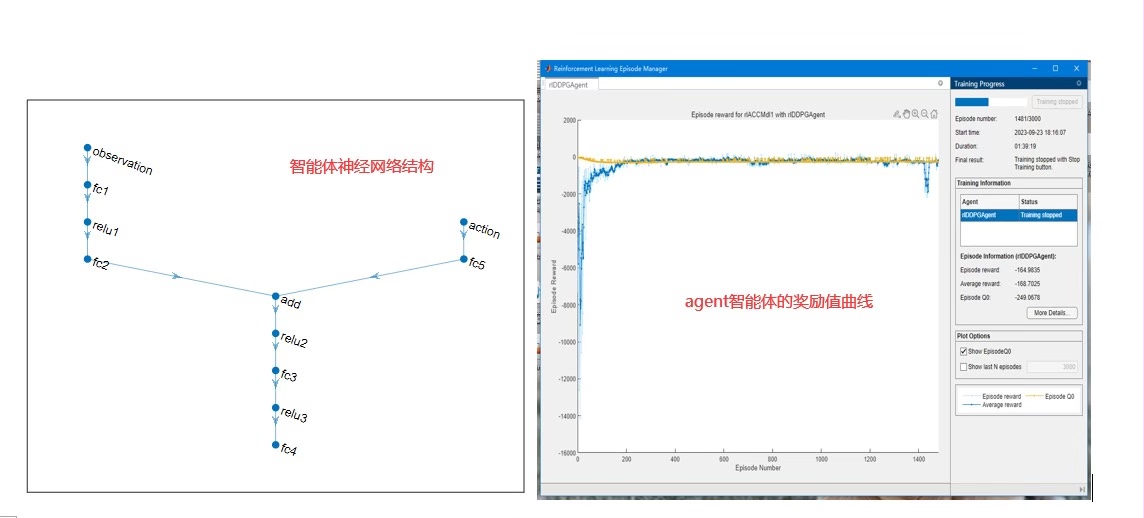
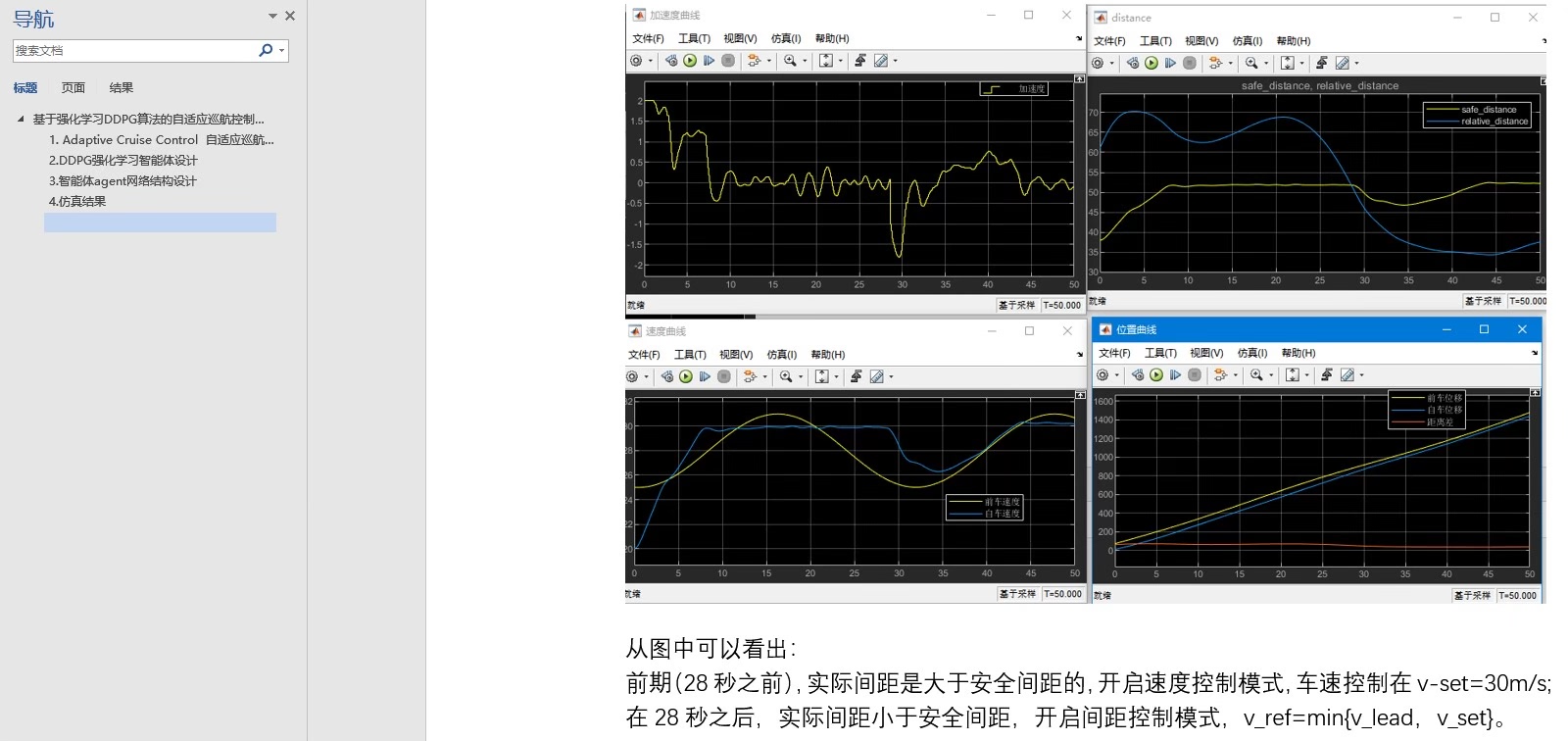
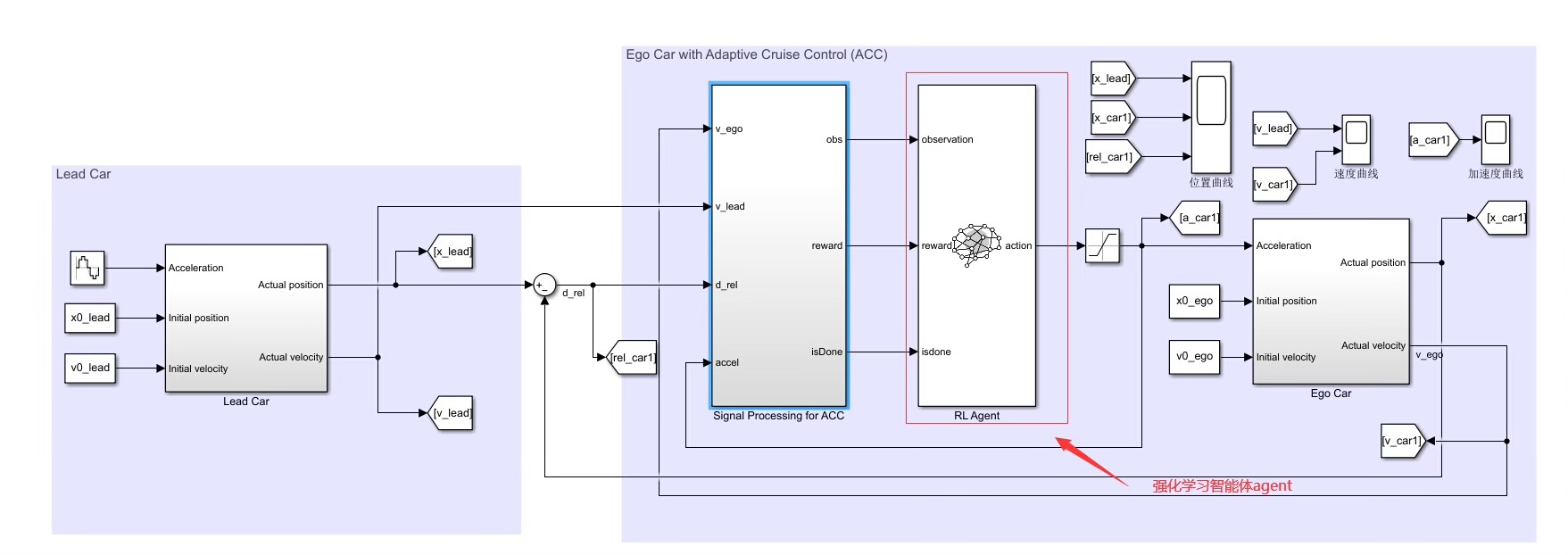
基于强化学习 DDPG 算法实现的acc 自适应巡航控制器设计 配有说明文档 基于simulink 中的强化学习工具箱,设计agent 的奖励函数,动作空间,状态空间,训练终止条件 设置领航车的速度和位移曲线,然后自车的加速度基于 acc 逻辑用ddpg agent 来控制。 模型比较简单,适用于初学强化学习算法的入门资源,可改写成强化学习的车辆队列协同控制。

在自动驾驶领域,自适应巡航控制(ACC)是一项关键技术。今天咱们就来聊聊基于强化学习DDPG算法实现的ACC自适应巡航控制器设计,这可是个有趣且适合强化学习入门的小项目,还配有说明文档哦,非常友好~
一、基于Simulink强化学习工具箱的基础设置
1. 设计Agent的奖励函数
奖励函数在强化学习中起着关键作用,它指导Agent学习到期望的行为。比如,咱们希望自车能稳定跟车,避免碰撞且保持合适车距。假设当前自车与领航车的距离为 $d$,速度差为 $\Delta v$。可以设计如下简单的奖励函数:
function reward = calculateReward(d, dv)
target_distance = 50; % 目标距离
target_speed = 30; % 目标速度,假设领航车以这个速度稳定行驶
distance_reward = -abs(d - target_distance);
speed_reward = -abs(dv);
reward = distance_reward + speed_reward;
end代码分析:这个函数里,distancereward 部分是根据当前距离与目标距离的差值计算的,差值越大奖励越低,这样鼓励自车尽量保持在目标距离。speedreward 类似,是根据速度差来计算,鼓励自车与领航车速度接近。最终奖励是两者之和,综合考虑了距离和速度因素。
2. 定义动作空间
动作空间代表Agent可以采取的行动。对于ACC系统,自车的加速度就是我们的动作。比如设定加速度范围为 $[-2, 2] m/s^2$,在Simulink里可以这样定义:
actionInfo = rlNumericSpec([1 1],'LowerLimit', -2,'UpperLimit', 2);
actionInfo.Name = 'Acceleration';代码分析:这里用 rlNumericSpec 函数定义了一个数值型的动作空间,大小为 [1 1] 也就是一维,下限为 -2,上限为 2,并给它起了个名字叫 Acceleration,这样在后续训练中,Agent输出的动作(加速度值)就会在这个范围内。
3. 确定状态空间
状态空间包含了Agent做出决策所需的环境信息。对于ACC系统,我们可以把自车速度、领航车速度、两车之间的距离作为状态。在Simulink里定义如下:
stateInfo = rlNumericSpec([3 1],'LowerLimit', [-Inf; -Inf; 0],'UpperLimit', [Inf; Inf; Inf]);
stateInfo.Name = 'ACC_State';代码分析:这里定义了一个三维的状态空间,分别对应自车速度、领航车速度和两车距离。速度理论上没有上下限(用 [-Inf; Inf] 表示),距离下限为 0(不能为负),上限无穷大。同样给状态空间起了个名字 ACC_State。
4. 设定训练终止条件
训练终止条件决定什么时候停止训练。比如,当两车距离小于安全距离(设为10米)时,认为发生碰撞,训练终止;或者当训练步数达到一定值(设为1000步)也终止训练。可以这样实现:
function done = checkTermination(state)
safety_distance = 10;
global step_count;
max_steps = 1000;
if state(3) < safety_distance || step_count >= max_steps
done = true;
else
done = false;
end
step_count = step_count + 1;
end代码分析:函数接收当前状态 state,先判断两车距离 state(3) 是否小于安全距离,同时检查全局变量 step_count 是否达到最大步数。如果满足其中一个条件,就返回 true 表示训练要终止,否则返回 false,并更新步数。
二、领航车与自车控制设置
1. 设置领航车的速度和位移曲线
领航车的行驶情况直接影响自车的控制。我们可以简单设定领航车以一定的速度曲线行驶。比如,开始以 $20m/s$ 的速度匀速行驶,到50秒时开始以 $0.5m/s^2$ 的加速度加速:
time = 0:0.1:100; % 时间范围0到100秒,步长0.1秒
v_lead = zeros(size(time));
for i = 1:length(time)
if time(i) < 50
v_lead(i) = 20;
else
v_lead(i) = 20 + 0.5 * (time(i) - 50);
end
end
s_lead = cumsum(v_lead * 0.1); % 根据速度计算位移代码分析:先定义了时间数组 time,然后初始化领航车速度数组 vlead。通过循环,按照设定的速度曲线给 vlead 赋值。最后根据速度和时间步长,利用 cumsum 函数计算出领航车的位移 s_lead。
2. 自车加速度控制
自车的加速度基于ACC逻辑由DDPG Agent来控制。在训练好Agent后,就可以用它来实时决策自车加速度。假设已经训练好的Agent名为 trainedAgent,在每个时间步这样获取自车加速度:
state = [self_speed; lead_speed; distance]; % 获取当前状态
action = step(trainedAgent, state);
acceleration = action{1};代码分析:首先构建当前状态数组 state,包含自车速度、领航车速度和两车距离。然后用 step 函数让训练好的Agent根据当前状态给出动作,这个动作就是自车加速度,存储在 acceleration 里,用于后续自车的运动控制。
三、模型特点及拓展
这个模型整体比较简单,非常适合初学强化学习算法的同学作为入门资源。从代码和设置来看,各个部分逻辑清晰,容易理解。而且它还有拓展潜力,可以改写成强化学习的车辆队列协同控制。在车辆队列协同控制中,可以将多辆车的状态都纳入状态空间,同时动作空间可能需要调整为多辆车的加速度控制等,奖励函数也需要重新设计以考虑整个队列的稳定性、安全性等因素。这样就可以从简单的ACC控制拓展到更复杂且实用的车辆队列协同场景啦。
希望这篇博文能帮助大家对基于强化学习DDPG算法的ACC自适应巡航控制器设计有更清晰的认识,一起在强化学习的道路上愉快探索吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 29
29 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)