【技术教程】如何使用 ONLYOFFICE 自定义 AI 功能,实现图片内容智能描述
通过使用 ONLYOFFICE 的 AI 智能体,您不仅可以执行常规编辑器操作,还能根据自身需求添加自定义功能。本文将逐步介绍如何创建 describeImage 函数,并解释它如何将图像转换为标题、说明文字以及易访问的替代文本。
通过使用 ONLYOFFICE 的 AI 智能体,您不仅可以执行常规编辑器操作,还能根据自身需求添加自定义功能。本文将逐步介绍如何创建 describeImage 函数,并解释它如何将图像转换为标题、说明文字以及易访问的替代文本。

关于 ONLYOFFICE
ONLYOFFICE 是一个国际开源项目,专注于高级和安全的文档处理和协作。全球超过 1500 万用户,是在线办公领域的创新者。
ONLYOFFICE 文档是一套功能全面的在线办公套件,它集成了文本文档、电子表格、演示文稿、可填写表单以及PDF 编辑器,并确保与微软 Office 格式高度兼容 。并提供数百种格式化和样式工具,以及多种协作功能。
该套件支持在 Windows、Linux 和 macOS 桌面上运行,同时也提供适用于 Android 和 iOS 的移动应用,用户可通过网页浏览器、桌面客户端或移动应用随时随地访问和编辑文件 。
函数设计
为使函数能被 ONLYOFFICE AI 引擎识别调用,我们将其定义为 RegisteredFunction 。这一定义包含函数名称、预期参数及演示用法的示例提示语。
let func = new RegisteredFunction({
name: "describeImage",
description:
"Allows users to select an image and generate a meaningful title, description, caption, or alt text for it using AI.",
parameters: {
type: "object",
properties: {
prompt: {
type: "string",
description:
"instruction for the AI (e.g., 'Add a short title for this chart.')",
},
},
required: ["prompt"],
},
examples: [
{
prompt: "Add a short title for this chart.",
arguments: { prompt: "Add a short title for this chart." },
},
{
prompt: "Write me a 1-2 sentence description of this photo.",
arguments: {
prompt: "Write me a 1-2 sentence description of this photo.",
},
},
{
prompt: "Generate a descriptive caption for this organizational chart.",
arguments: {
prompt:
"Generate a descriptive caption for this organizational chart.",
},
},
{
prompt: "Provide accessibility-friendly alt text for this infographic.",
arguments: {
prompt:
"Provide accessibility-friendly alt text for this infographic.",
},
},
],
});运行逻辑
call 方法包含了用户调用函数时执行的实际功能:
- 获取选中的图片 - 使用 GetImageDataFromSelection ,从文档中获取图片并且过滤掉占位符图片,以确保有意义的 AI 结果。
- 构建 AI 提示 - 用户的指令与所选图片的上下文相结合,以创建一个清晰且可操作的提示。
- 验证 AI 模型兼容性 - 只有支持视觉能力的模型(如 GPT-4V 或 Gemini )可以处理图片。如果用户当前模型无法处理图片,会对用户进行提醒。
- 向 AI 发送请求 - 图片和提示通过 chatRequest 发送给 AI 引擎,实时收集生成的文本。
- 将 AI 生成的文本插入文档 - 函数会检测是否选中了图片,并适当地插入结果。
- 错误处理 - 函数会妥善处理未选中图像、模型不支持、AI 异常等情况,向用户输出清晰的提示信息。
1. 获取选中的图像
在 ONLYOFFICE 中,文档内的图像被称为 drawings 。如需处理用户选中的图像,我们将使用 ONLYOFFICE 插件 API :
let imageData = await new Promise((resolve) => {
window.Asc.plugin.executeMethod(
"GetImageDataFromSelection",
[],
function (result) {
resolve(result);
}
);
});- GetImageDataFromSelection:ONLYOFFICE 插件的内置方法,用于将当前选中的图像提取为Base64编码字符串;
- 返回结果为对象,典型格式如下:
{
"src": "data:image/png;base64,iVBORw0K...",
"width": 600,
"height": 400
}其中 src 字符串包含 Base64 格式的完整图像数据,可直接发送至支持图像输入的 AI 模型。
关键注意事项:
- 若未选中任何图像,imageData 为 null;
- 用户可能选中占位符或空白矩形(例如,ONLYOFFICE 使用白色矩形作为空白图像占位符)。我们通过比对其 Base64 编码来过滤此类无效图像:
const whiteRectangleBase64 = "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVR42mP8/5+hHgAHggJ/PchI7wAAAABJRU5ErkJggg==";
if (imageData.src === whiteRectangleBase64) {
console.log("describeImage: Image is white placeholder");
await insertMessage("Please select a valid image first.");
return;
}2. 图像预处理(适配 AI 输入)
AI 模型通常要求图像以 URL 或 Base64 编码数据的形式输入(一般置于 image_url 字段中)。在本函数中,我们将图像与文本提示词整合为结构化数组:
let messages = [
{
role: "user",
content: [
{ type: "text", text: argPrompt },
{
type: "image_url",
image_url: { url: imageData.src, detail: "high" },
},
],
},
];- type: "text"传入提示词指令(例如:“生成描述性文字”);
- type: "image_url"传入图像数据,AI 引擎可据此分析图像并生成相关文本;
- detail: "high"可选参数,用于提示模型以全分辨率处理图像。
转换逻辑:
- ONLYOFFICE 提供的 src 为 Base64 字符串;
- AI 模型支持 Base64 数据或可访问的URL,此处直接使用 Base64 格式以避免上传至外部服务器;
- 将图像封装为符合 AI 对话请求 API 的对象格式,支持单条消息中包含多种内容类型。
3. 向 AI 发送请求
完成图像和提示词的结构化处理后,调用ONLYOFFICE AI 插件引擎发送请求:
let requestEngine = AI.Request.create(AI.ActionType.Chat);
await requestEngine.chatRequest(messages, false, async function (data) {
console.log("describeImage: chatRequest callback data chunk", data);
if (data) {
resultText += data;
}
});- AI.ActionType.Chat:支持发送对话式消息,实现提示词与图像的联合分析;
- 回调函数实时收集 AI 返回的文本片段;
- 发送请求前需验证所选 AI 模型是否支持视觉功能,仅特定模型(GPT-4V、Gemini 等)可处理图像:
const allowVision = /(vision|gemini|gpt-4o|gpt-4v|gpt-4-vision)/i;
if (!allowVision.test(requestEngine.modelUI.name)) {
console.warn("describeImage: Model does not support vision", requestEngine.modelUI.name);
await insertMessage(
"⚠ This model may not support images. Please choose a vision-capable model (e.g. GPT-4V, Gemini, etc.)."
);
return;
}4. 将 AI 输出插入文档
接收 AI 生成结果后,需将文本插入 ONLYOFFICE 文档。逻辑处理两种场景:
- 已选中图像:在图像后插入段落;
- 未选中图像:在当前光标位置后插入段落。
async function insertMessage(message) {
console.log("describeImage: insertMessage called", message);
Asc.scope._message = String(message || "");
await Asc.Editor.callCommand(function () {
const msg = Asc.scope._message || "";
const doc = Api.GetDocument();
const selected =
(doc.GetSelectedDrawings && doc.GetSelectedDrawings()) || [];
if (selected.length > 0) {
for (let i = 0; i < selected.length; i++) {
const drawing = selected[i];
const para = Api.CreateParagraph();
para.AddText(msg);
drawing.InsertParagraph(para, "after", true);
}
} else {
const para = Api.CreateParagraph();
para.AddText(msg);
let range = doc.GetCurrentParagraph();
range.InsertParagraph(para, "after", true);
}
Asc.scope._message = "";
}, true);- Api.GetSelectedDrawings()获取当前选中的图像(drawings);
- Api.CreateParagraph()创建新的段落对象;
- InsertParagraph(para, "after", true)在选中图像或当前段落的后方插入生成文本;
- 确保无缝集成:AI 输出始终出现在符合上下文逻辑的位置。
5. 边缘场景与错误处理
部分特殊场景需额外处理:
未选中图像——提示用户先选中图像。
AI 模型不支持——发送请求前向用户发出警告。
AI 返回空结果——通知用户无法生成描述。
意外错误——使用嵌套 try/catch 语句安全终止正在进行的编辑器操作:
} catch (e) {
try {
await Asc.Editor.callMethod("EndAction", ["GroupActions"]);
await Asc.Editor.callMethod("EndAction", [
"Block",
"AI (describeImage)",
]);
} catch (ee) {
}确保即使 AI 或插件在运行过程中出现故障,文档仍能保持稳定状态。
最终成果
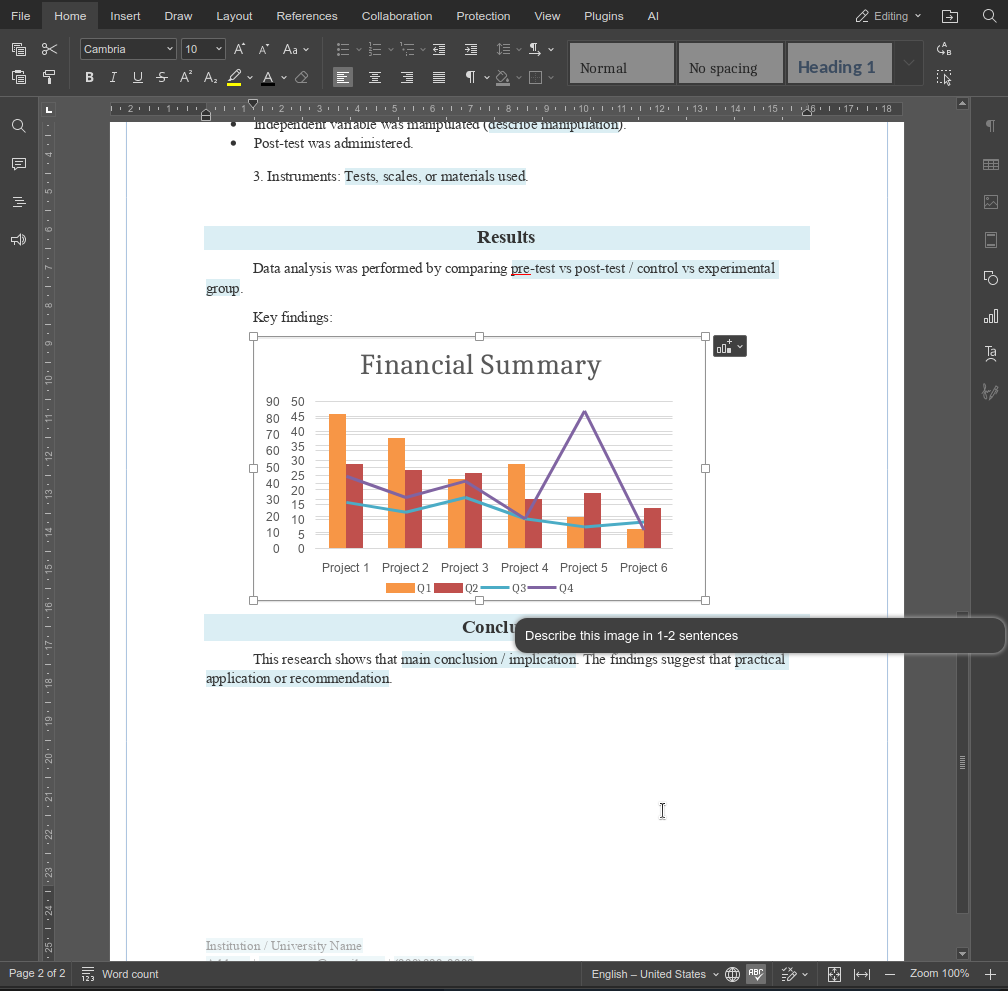
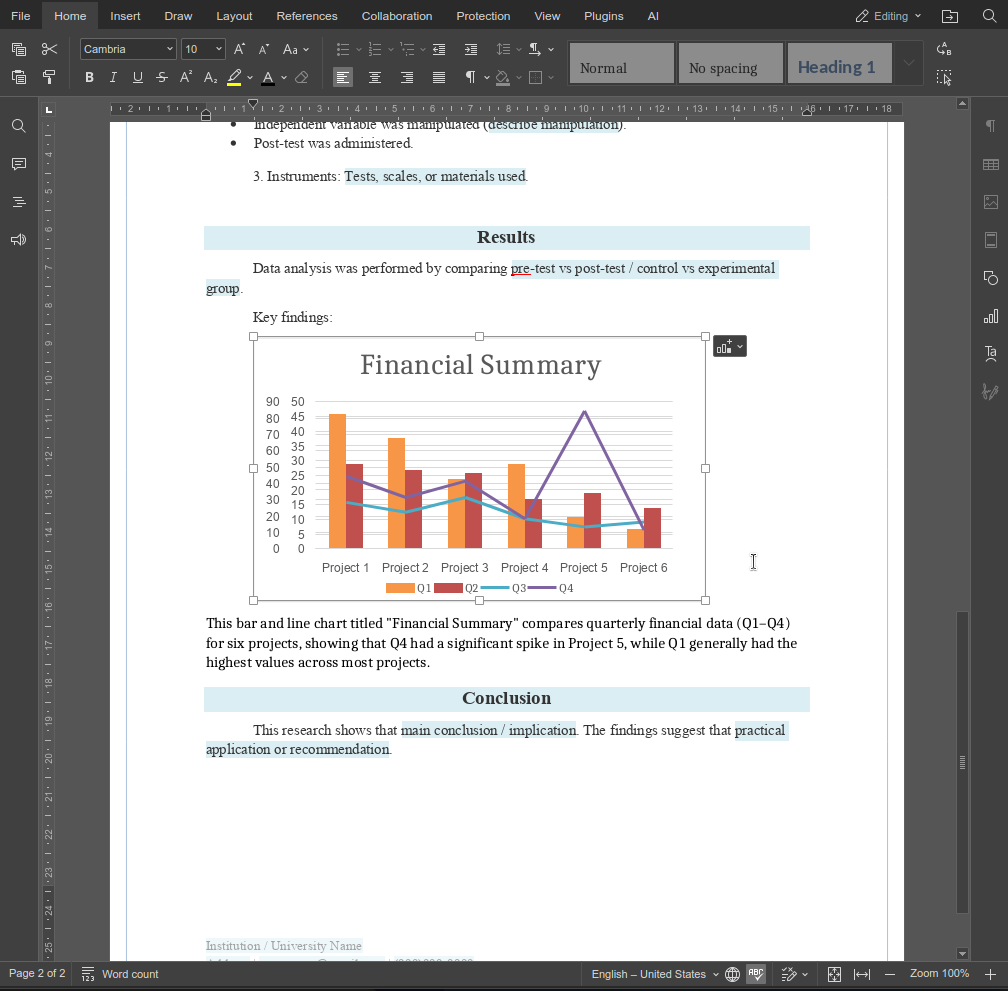
describeImage 函数展示了自定义功能如何以小而精的方式扩展 AI 助手的能力。通过将清晰的提示词与感知上下文的逻辑相结合,您可以构建直接融入真实工作流的特色功能,而非通用的 AI 操作。
欢迎大家尝试开发专属自定义函数,打造更贴合自身工作流需求的 AI 助手,探索智能化办公的更多可能性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)