大模型面试必备04——BERT 论文逐段精读
参考视频:【BERT 论文逐段精读【论文精读】】 https://www.bilibili.com/video/BV1PL411M7eQ/?
一、资料整理
bert论文地址:BERT: Pre-training of Deep Bidirectional Transformers (arXiv)
参考视频:【BERT 论文逐段精读【论文精读】】 https://www.bilibili.com/video/BV1PL411M7eQ/?share_source=copy_web&vd_source=9fe9e3d550891e4a38f66eead88c8b40
二、学习笔记
标题

1.背景与贡献
-
背景:
-
BERT(Bidirectional Encoder Representations from Transformers)诞生前,NLP领域缺乏统一的深度预训练模型。ELMo(芝麻街系列文章)使用RNN结构且非端到端,GPT基于单向Transformer,无法捕捉双向上下文。
-
计算机视觉领域通过ImageNet预训练模型提升下游任务性能,而NLP领域需要类似突破。
-
-

-
核心贡献:
-
双向上下文建模:通过掩码语言模型(MLM)实现双向信息捕捉,解决了GPT单向性的限制。
-
通用预训练框架:模型仅需简单微调即可适配多种任务(如分类、问答),无需复杂结构调整。
-
规模化训练:验证了大模型(如BERT-Large)在大数据(BooksCorpus + Wikipedia)上的有效性,推动后续模型规模化趋势。
-

-


2. 模型架构

-
基础结构:
-
基于Transformer编码器,无解码器部分。()
-
分两个版本:
-
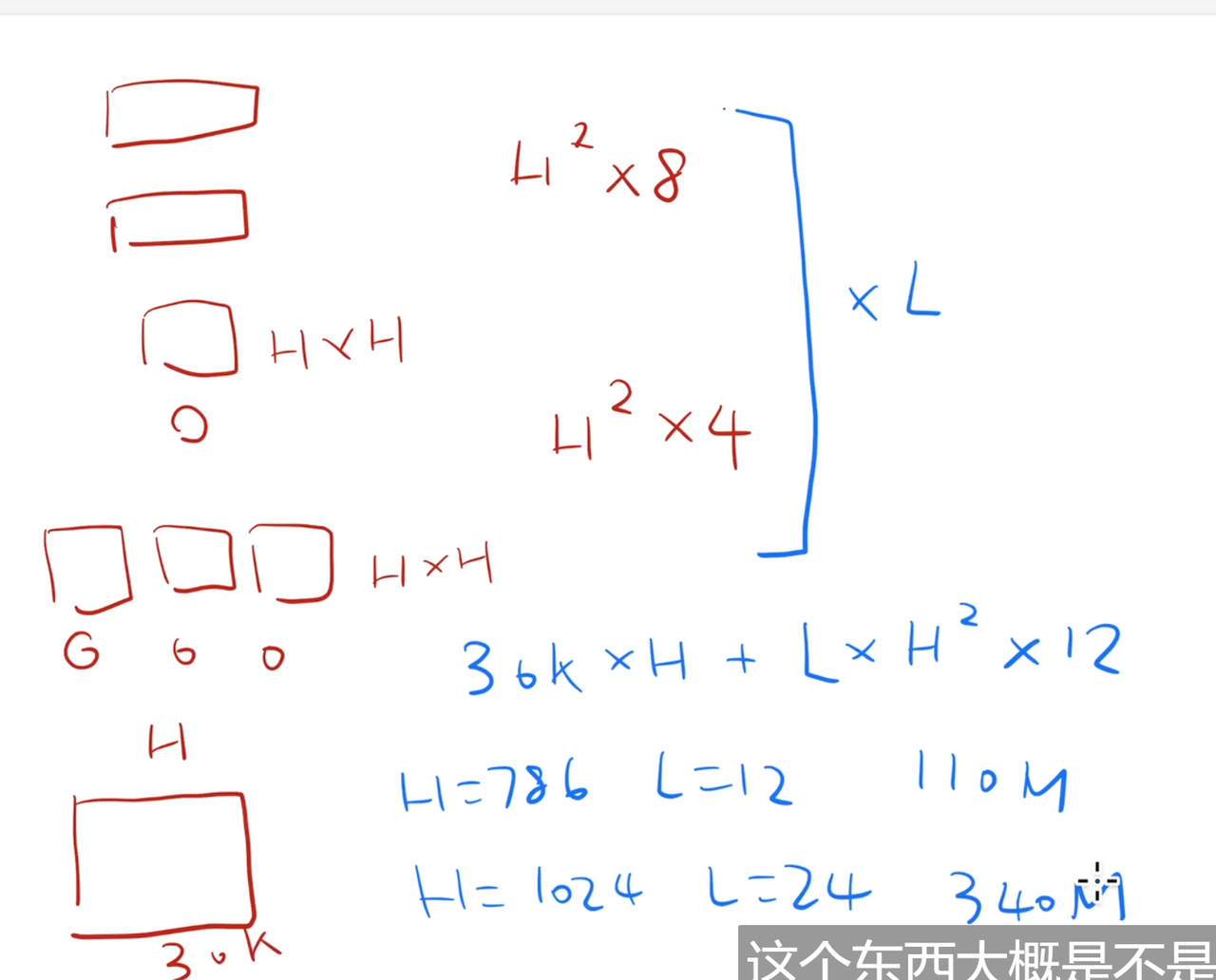
BERT-Base:12层,768隐藏维度,12个注意力头(1.1亿参数)。
-
BERT-Large:24层,1024隐藏维度,16个注意力头(3.4亿参数)。
-
-
-
输入处理:
-
没有解码器部分,因此将两个句子合成一个序列输入到模型中。
-
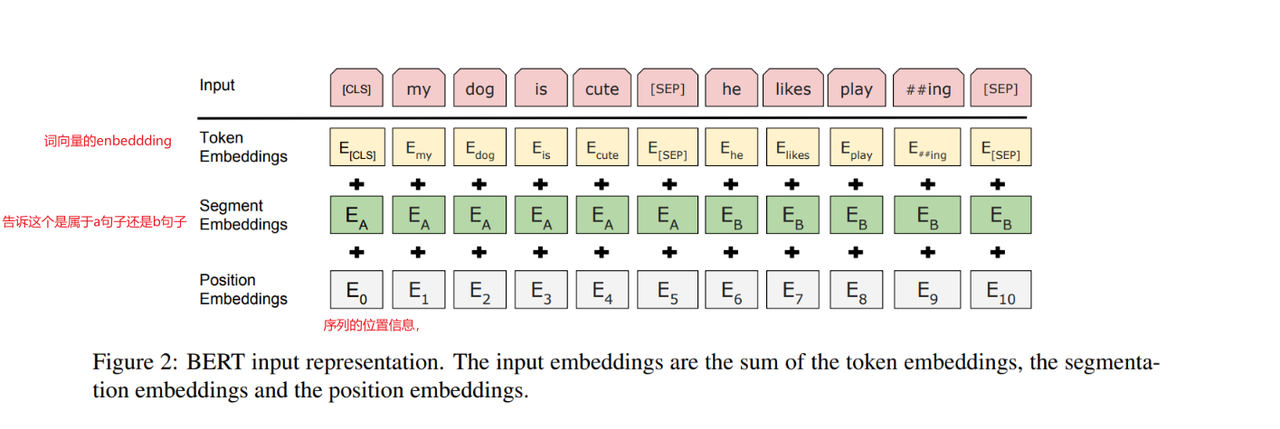
Token嵌入:使用WordPiece分词(词的子序列,可理解成词根)(3万词表),解决未登录词问题。
-
位置嵌入:学习位置编码,替代Transformer的固定位置编码。
-
段嵌入:区分句子A和句子B(用于句子对任务)。
-
特殊标记:
-
[CLS]:用于分类任务的聚合表示。 -
[SEP]:分隔句子对。 -
[MASK]:预训练时掩盖部分Token。
-
-
3. 预训练任务
-
掩码语言模型(MLM):
-
随机掩盖15%的Token,其中:
-
80%替换为
[MASK]。 -
10%替换为随机Token。
-
10%保留原Token。
-
-

-
迫使模型利用双向上下文预测被掩盖的Token,解决预训练与微调输入不一致问题。
-
下一句预测(NSP):
-
输入句子对(A+B),50%概率B为A的下一句,50%为随机句子。
-
目标:判断B是否为A的后续,提升句子关系建模能力(如问答、推理任务)。
-

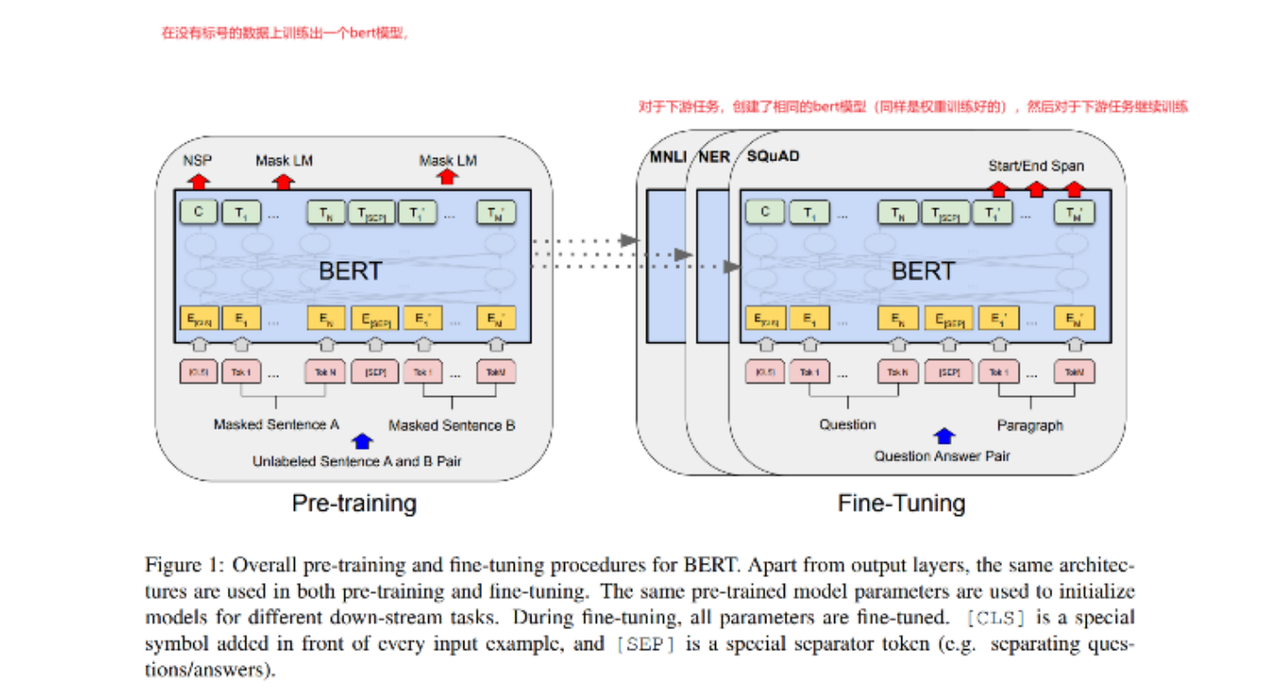
4. 微调方法
-
适配不同任务:
-
单句分类(如情感分析):取
[CLS]的输出向量加分类层。 -
句子对任务(如推理):拼接句子A+B,通过
[CLS]分类。 -
序列标注(如NER):对每个Token的输出向量分类。
-
问答任务(如SQuAD):预测答案在文本中的起止位置。
-
-
训练细节:
-
微调耗时短(GPU数小时至一天),学习率较低(如5e-5),Batch Size较小(如32)。
-
所有参数参与微调,仅需添加任务特定输出层。
-
-
模型参数的计算(强烈推荐)
-
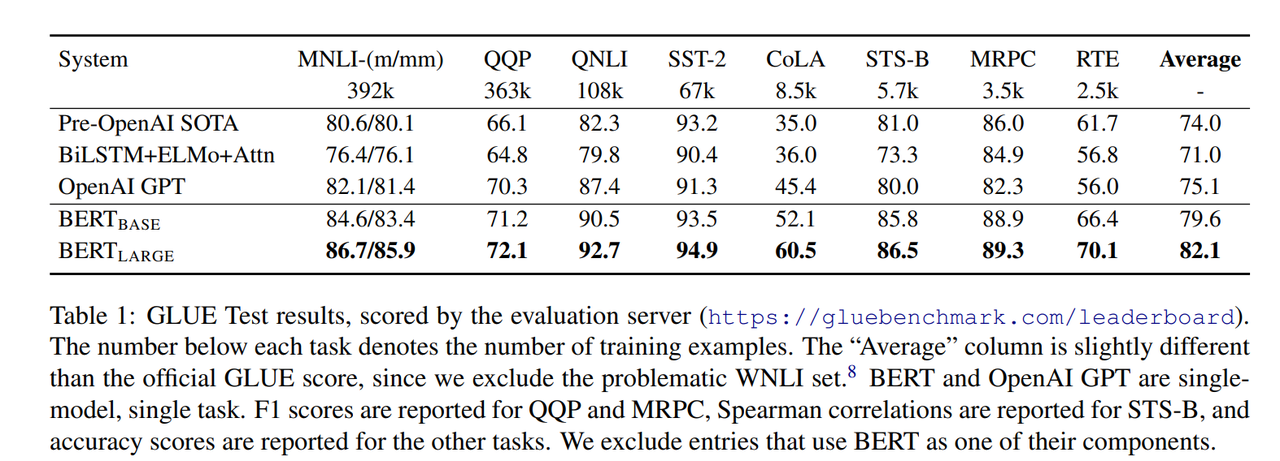
5. 实验结果
-
SOTA性能:
-
GLUE基准:平均提升7.7%,涵盖文本分类、相似度、推理等任务。
-
SQuAD问答:F1提升至93.2(v1.1)和83.1(v2.0)。
-
命名实体识别(CoNLL-2003):F1达92.4。
-
-
消融实验:
-
移除NSP任务导致QA和推理任务性能显著下降。
-
单向模型(如GPT式)效果弱于双向结构。
-
大模型(BERT-Large)显著优于小模型,验证规模效应。
-
-
6. 影响
-
双向性的价值:MLM任务使模型捕获完整上下文,超越ELMo的双向LSTM拼接。
-
预训练范式革新:统一框架适配多任务,推动NLP进入“预训练+微调”时代。
-
局限与后续发展:
-
生成任务支持不足(需解码器结构),后续工作如BART、T5弥补。
-
模型规模持续扩大(如GPT-3),但BERT奠定了基础架构思想。
-
7. 启示
-
简单有效的设计:BERT成功源于对现有技术(Transformer、MLM)的巧妙整合,而非完全创新。
-
工程实践重要性:大规模训练(TPU集群)和数据处理(长文本序列)是关键支撑。
-
研究社区影响:开源模型和代码(https://github.com/google-research/bert)加速NLP应用与研究。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)