Boosting Few-shot Fine-grained Recognition with Background Suppression and Foreground Alignment
通过经验揭示了显著提高小样本任务性能的两个关键点,一是减弱背景干扰,二是对准前景响应。提出的少样本细粒度识别方法通过引入背景激活抑制、前景对象对齐、局部到局部相似度度量和双重相似性推断机制,显著提高了少样本细粒度分类任务的性能。实验结果验证了方法的有效性和普适性,为少样本细粒度识别领域提供了新的思路和解决方案。
通过背景抑制和前景对齐促进少样本细粒度识别
摘要
小样本学习和细粒度识别的主要挑战有以下两个方面:首先,缺乏标记样本使得学习到的模型容易过拟合。其次,它还受到背景差异以及数据集的类间差异较小,类内差异较大的影响。为了解决这一具有挑战性的任务,我们提出了一个两阶段背景抑制和前景对齐框架,该框架由背景激活抑制 (BAS)模块、前景对象对齐 (FOA)模块和局部到局部 (L2L)相似性度量组成。具体而言,引入 BAS 模块生成前景掩膜进行定位,以减弱背景干扰,增强优势前景目标。接着FOA模板根据每个支持样本对查询样本的校正重建每个支持样本的特征映射,解决了支持 -查询图像对之间的不对齐问题。为了使所提出的方法能够捕获混淆样本中的细微差异,我们提出了一种新的 L2L 相似性度量,以进一步测量嵌入空间中一对对齐空间特征之间的局部相似性。
核心任务
少样本细粒度识别(FS-FGR):在少样本学习(仅提供少量标记样本)的设置下,识别属于同一超类下的多个细粒度子类(例如不同种类的鸟类、犬类、汽车型号等),需同时克服少样本学习的过拟合问题和细粒度识别的类内方差大、类间差异小的挑战。
不足与创新点:
创新点
- 两阶段框架:文章提出了一个两阶段的背景抑制和前景对齐框架,包括背景激活抑制(BAS)模块和前景对象对齐(FOA)模块。这一创新设计旨在分别处理背景干扰和支持-查询样本之间的错位问题。背景激活抑制(BAS)模块:BAS模块生成前景掩码进行定位,以减弱背景干扰并增强主要前景对象,从而提高模型在处理细粒度样本时的鲁棒性。前景对象对齐(FOA)模块:FOA模块根据支持样本与查询样本的匹配关系重建特征图,解决支持-查询图像对之间的错位问题。这有助于提高模型在少样本情况下的对齐能力。
- 局部到局部(L2L)相似度度量:提出了一种新的L2L相似度度量方法,用于进一步衡量嵌入空间中对齐局部特征之间的相似性,以捕捉细微差别。
- 双重相似性推断:为了提高模型的鲁棒性,文章同时使用原始图像和精细化图像推断特征图的成对相似性。这种双重相似性推断方法可以更好地处理背景干扰问题。
不足之处
- 模型复杂性:虽然提出的框架在性能上有所提升,但增加了模型的复杂性,可能导致计算和存储开销的增加。在实际应用中,这可能会限制模型的部署和使用。
- 数据集依赖:尽管在多个流行的细粒度基准数据集上进行了广泛实验,但在更大规模和更多样化的数据集上的泛化性能尚未得到验证。特别是,实际应用中的数据分布可能与实验数据集存在显著差异。
- 背景生成和对齐准确性:尽管提出了BAS和FOA模块,但生成的前景掩码和特征图的对齐准确性可能会受到一些噪声和异常值的影响,从而影响整体性能。
- 没有彻底消除对标注的依赖:尽管方法中没有直接依赖手动标注的边界框(bounding boxes),但这种方法仍然间接地依赖于高质量的初始训练数据。如果初始数据中的噪声较多,可能会影响模型的训练效果。

小样本细粒度的主要挑战:背景差异,以及横向观察类间差异较小,类内差异较大。
研究动机
- 背景干扰问题:细粒度图像中,不同子类可能具有相似背景(如不同鸟类均处于天空、草地背景),这些背景会掩盖子类间的细微差异,影响识别准确性。虽然人工标注边界框可去除背景,但违背了少样本学习 “减少标注负担” 的初衷。
- 前景错位问题:同一细粒度子类的对象可能存在姿态、视角、位置等差异,导致支持样本与查询样本的前景特征在嵌入空间中错位,无法有效匹配局部 discriminative 特征。
- 现有方法缺陷:现有 FS-FGR 方法多依赖全局特征或复杂注意力机制,要么无法捕捉局部细微差异,要么引入过多参数导致效率低下,且未同时解决背景干扰和前景错位问题。
解决的问题
- 背景干扰问题:无需人工标注边界框,通过 BAS 模块自动生成前景掩码,裁剪并放大前景区域,去除背景干扰,保留细粒度判别特征。
- 前景错位问题:通过 FOA 模块计算支持 - 查询样本的语义相关矩阵,对支持特征进行空间变换,实现前景特征对齐,解决姿态 / 位置差异导致的匹配误差。
- 特征粒度矛盾:设计 L2L 局部相似性度量,聚焦对齐后的局部特征匹配,同时保留全局分类分支约束背景抑制模块,兼顾分类鲁棒性与定位敏感性。
- 模型鲁棒性不足:采用 “原始图像 + 优化图像” 双阶段特征融合,利用两者的相似性分数联合决策,提升模型对未见过样本的泛化能力,缓解少样本场景的过拟合。
框架模型:
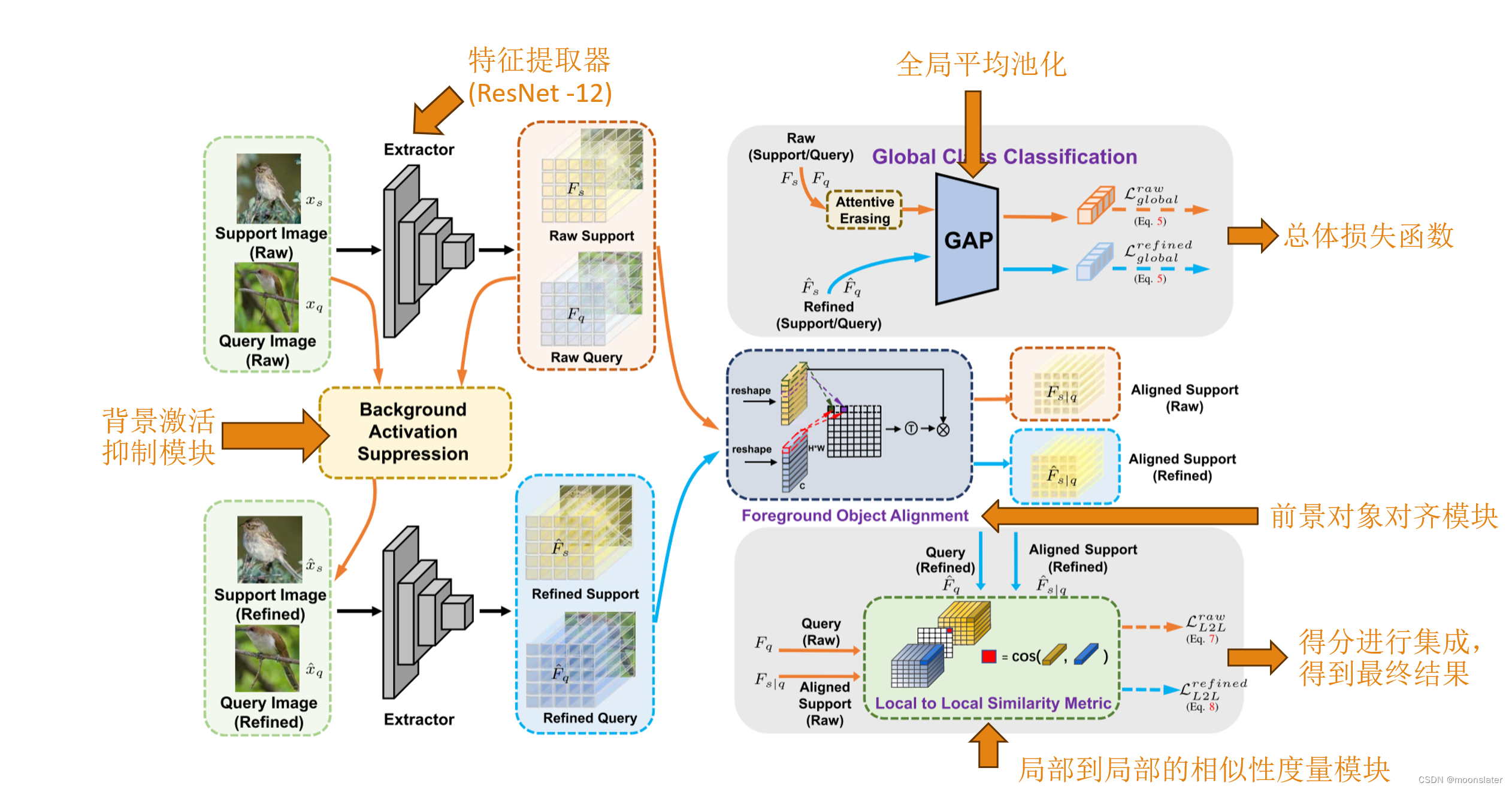
细化阶段的输入由基于原始阶段输入的背景激活抑制模块生成。两个阶段具有相同的结构,除了全局分类器外,所有参数都是共享的。每个阶段由一个前景对象对齐 (FOA) 模块、一个全局分类器和一个基于 L2L 的相似性比较器组成.
整体模型框架通过组合BAS、FOA和L2L相似度度量,提供了一个系统化的方法来处理少样本细粒度识别中的关键挑战。具体来说,BAS模块负责减弱背景干扰,FOA模块解决特征对齐问题,L2L相似度度量提高了对细微特征差异的捕捉能力,而双重相似性推断则进一步增强了模型的鲁棒性。
全局分类损失(GCC)的计算流程
- 约束 BAS 模块:通过优化 “原始特征→优化特征” 的分类损失,强迫 BAS 模块生成 “前景更准确、背景干扰更少” 的优化图像 —— 如果 BAS 的前景定位不准,优化特征的分类损失会变大,从而反向调整 BAS 的掩码生成逻辑;
- 辅助注意力擦除:注意力擦除后,模型需要用 “不完整的原始特征” 做分类,这会强迫模型关注前景的更多区域(而不是只依赖局部特征),提升前景特征的完整性;
- 补充局部损失:和之前的 L2L 局部损失配合,既保证 “局部特征能精准匹配细粒度差异”,又保证 “全局特征能稳定区分不同类别”,让模型学习更鲁棒的特征。
背景激活抑制(BAS)模块
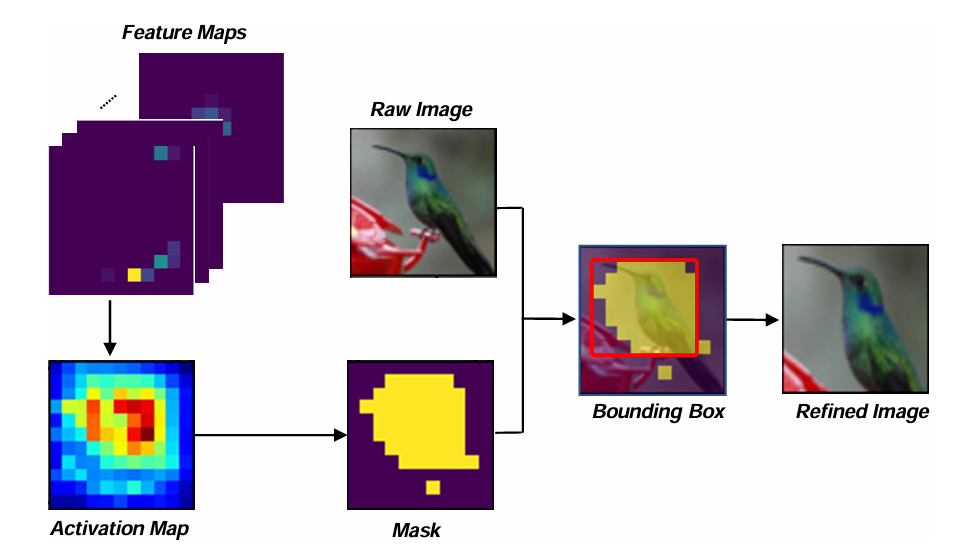
- 输入特征图(Feature Maps):从原始图像(比如蜂鸟图)提取的多通道特征图;
- 生成激活图(Activation Map):对特征图做通道级聚合,得到 “激活图”—— 图中颜色越亮的区域,代表特征响应越强(对应前景对象);
- 生成前景掩码(Mask):通过阈值筛选激活图,把低响应的背景区域抑制(设为 0),保留高响应的前景区域(设为 1),得到前景掩码;
- 生成优化图像(Refined Image):用前景掩码在原始图像上框出前景边界框(Bounding Box),裁剪并放大前景区域,最终得到 “去除背景干扰的优化图像”。
注意力擦除
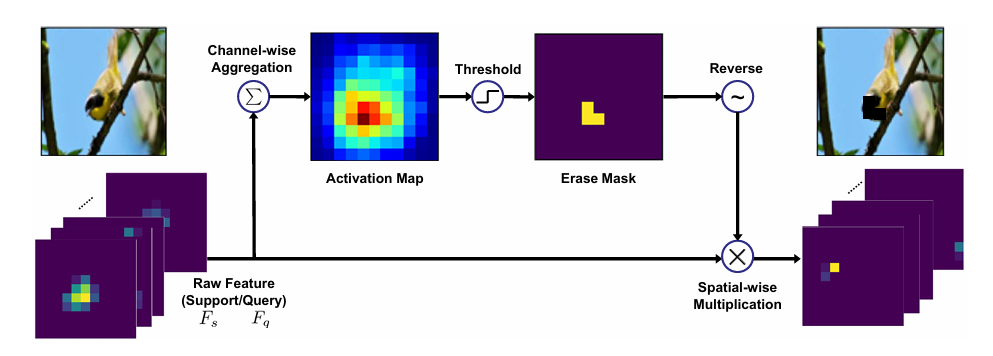
注意力擦除图。在第二阶段,为了鼓励网络最小化整个图像的背景激活和整体激活的比例,在输入到全局分类器之前擦除激活高于阈值的原始特征区域,这有助于探索前景的整个范围。核心是 “避免模型过度聚焦局部特征,强迫学习完整前景”
这是 BAS 模块中辅助提升前景完整性的策略,核心是 “避免模型过度聚焦局部特征,强迫学习完整前景”:
- 通道级聚合 + 生成激活图:和 BAS 模块一样,先从原始图像提取特征,生成激活图;
- 生成擦除掩码(Erase Mask):对激活图设一个高阈值(比如最大激活值的 85%),把激活值超过阈值的区域标记为 “要擦除的区域”,得到擦除掩码;
- 特征擦除:用擦除掩码和原始特征图做空间级相乘(Spatial-wise Multiplication),把原始特征中 “过度激活的局部区域” 擦除;
- 输出优化特征:擦除后的特征图再输入全局分类器,强迫模型去关注前景的其他区域,从而学习到更完整的前景特征。
前景对象对齐(FOA)模块:
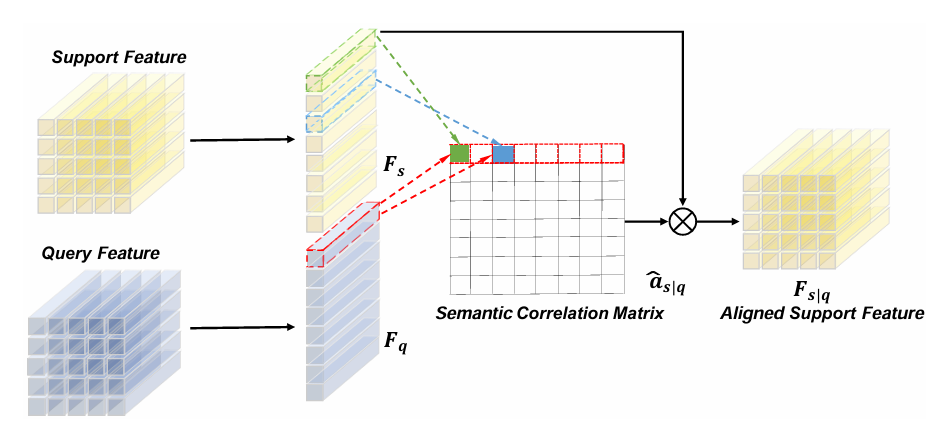
- 目标:解决支持样本与查询样本之间的错位问题,确保特征对齐。
- 机制:FOA模块根据支持样本与查询样本的匹配关系,重建支持样本的特征图,以对齐查询样本的特征图。
- 输入特征:原始的支持特征(\(F_s\),黄色块)和查询特征(\(F_q\),蓝色块)—— 此时二者的前景特征(比如图中绿色 / 蓝色小方块)因姿态差异,在特征图中的位置是错位的;
- 计算语义相关矩阵:通过计算支持特征与查询特征的局部语义相似度,生成 “语义相关矩阵”(图中网格)—— 矩阵中每个位置的数值代表支持特征块与查询特征块的匹配程度;
- 特征对齐:用这个相关矩阵对支持特征做空间变换(矩阵相乘),将支持特征中与查询特征匹配的区域 “移动” 到对应位置;
- 输出对齐后的支持特征:得到与查询特征空间对齐的支持特征(\(F_{s|q}\)),此时二者的前景特征在特征图中位置一致,避免了错位。
局部到局部(L2L)相似度度量:
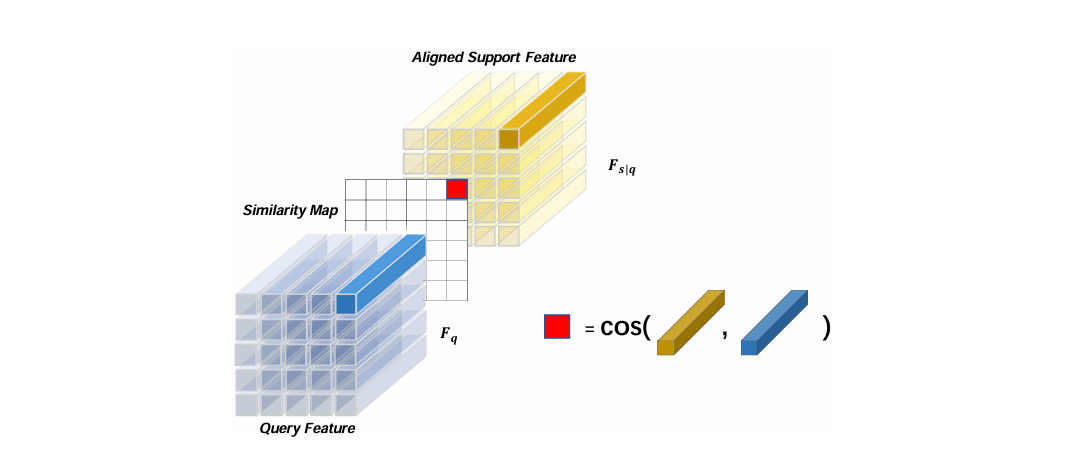
- 目标:进一步衡量嵌入空间中对齐局部特征之间的相似性,以捕捉细微差别。
- 机制:L2L相似度度量方法通过比较对齐后的局部特征,提高模型识别细粒度差异的能力。
- 输入对齐后的特征:FOA 模块输出的 “对齐后支持特征”(\(F_{s|q}\),黄色块)和查询特征(\(F_q\),蓝色块)—— 此时二者的前景特征已在空间上对齐;
- 逐元素计算余弦相似度:对对齐后的支持特征和查询特征,按 “局部特征块”(图中黄色 / 蓝色小方块)逐点计算余弦相似度(图中红色块代表 cos 计算);
- 生成相似度图:所有局部特征块的相似度结果组成 “相似度图”,最终的总相似度是这些局部相似度的总和。
实验
实验设置
- 数据集:
- CUB-200-2011(鸟类):200 类,11788 张图像,划分 100 类为基础类、50 类为验证类、50 类为新类。
- Stanford Dogs(犬类):120 类,20580 张图像,划分 70 类为基础类、20 类为验证类、30 类为新类。
- Stanford Cars(汽车):196 类,16185 张图像,划分 130 类为基础类、17 类为验证类、49 类为新类。
- 评估指标:平均准确率(Accuracy),带 95% 置信区间,测试 2000 个 episode(每个 episode 包含支持集与查询集)。
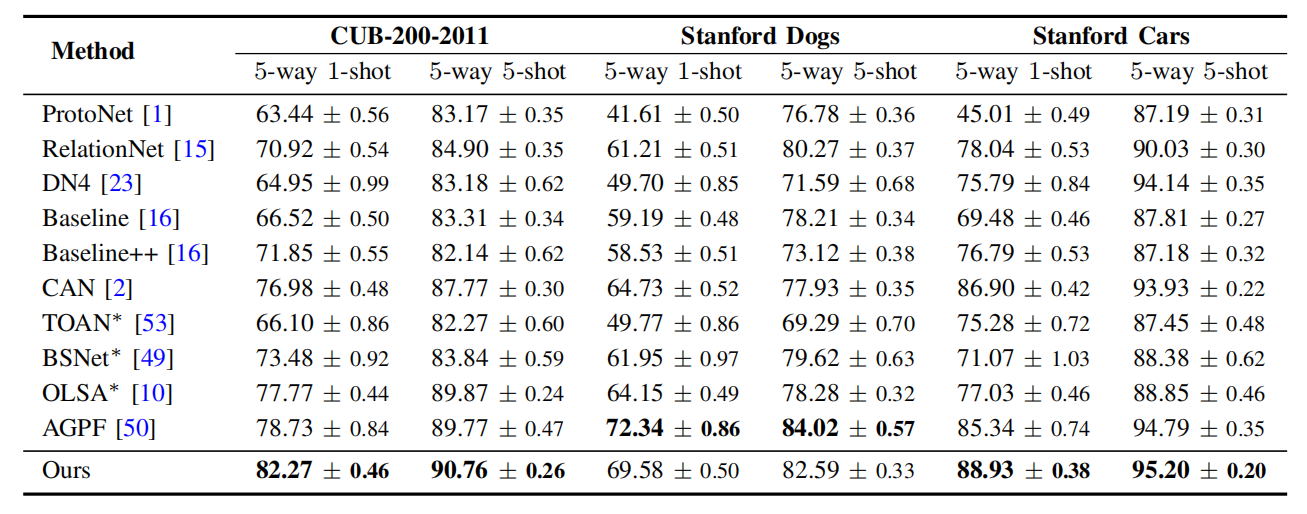
- 基线与对比方法:包括传统 FSL 方法(ProtoNet、RelationNet、DN4)与专用 FS-FGR 方法(TOAN、BSNet、OLSA、AGPF),确保公平对比。
结论与局限性
- 结论:本文提出的两阶段框架通过 BAS、FOA、L2L 模块,有效解决 FS-FGR 的背景干扰与前景错位问题,在多个基准数据集上实现 SOTA 性能,且效率优异,为少样本细粒度识别提供通用解决方案。
- 局限性:
- BAS 模块对小目标、非中心目标的定位精度不足,优化图像可能包含低激活背景区域。
- 浅层骨干(如 Conv-64)的特征表达能力弱,难以适配前景分布,导致 5-shot 性能低于部分方法。
- 未来方向:优化 BAS 模块的定位精度(如结合高分辨率特征图),探索更轻量的特征对齐策略,适配更多细粒度场景(如视频、3D 目标)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)