Agentic RAG 新手指南
Agentic RAG 将 ReACT 的推理能力与 Agent 的任务执行能力相结合,创建一个动态和自适应的系统。与遵循固定 pipeline 的传统 RAG 不同,Agentic RAG 通过使用 ReACT 根据用户查询的上下文动态协调 Agent,引入了灵活性。
大语言模型 (LLMs) 几乎完全改变了我们获取和理解信息的方式。这些先进的 AI 系统经过大量数据的训练,对于识别语言的模式和意义不在话下。借助 LLM,人们不论是探索新想法、学习新事物,还是快速高效地找到答案都变得比以前更容易。 早期的传统 LLM 完全依赖于其静态训练数据中提供的知识,常常导致“幻觉”,也就是经常给出莫名其妙的回答,这也就催生了检索增强生成 (RAG) 的概念。
RAG 的工作流程
RAG 的核心是为 LLM 提供一个外接的可靠知识库,基于它们在训练期间学习的信息以及通过访问实时更新的数据,来提高其响应质量。而这个可靠知识库则一般由 AI 数据库来担任。
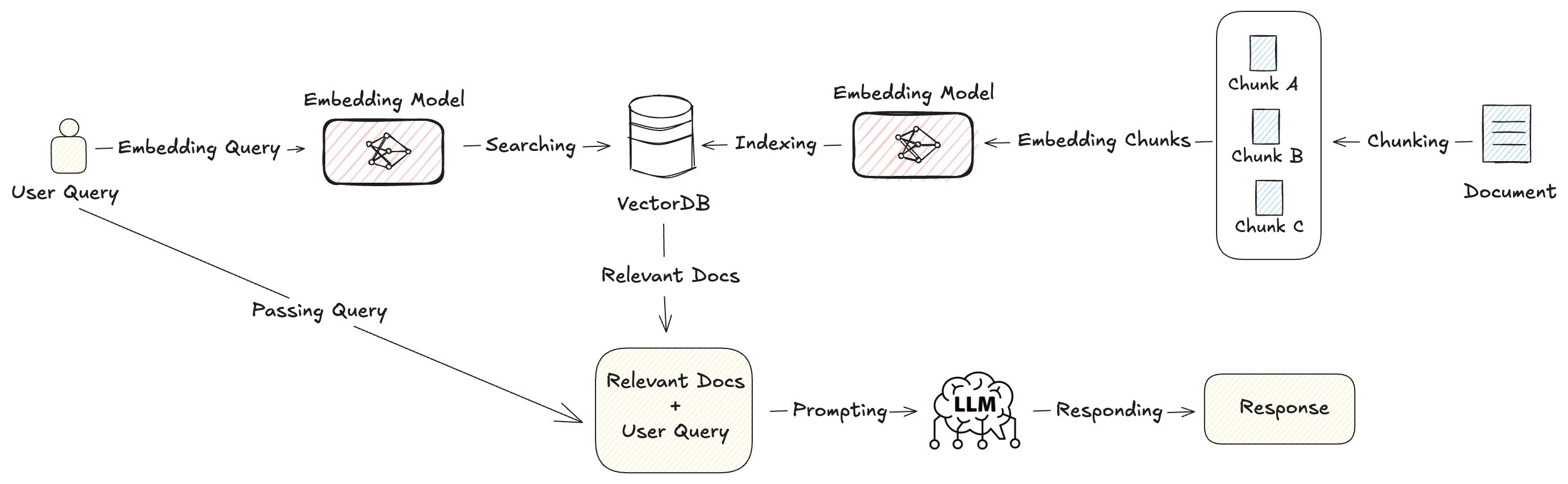
如上图所示,我们看到 RAG 的工作流程主要分为两个部分,即检索和生成:
-
检索(Retrieval):检索器在外部知识库中搜索与用户查询最相关的文档片段。当用户的查询转换为向量后,将其与数据库中存储的数据进行比较,检索出最相似的文档并根据与查询的相关性进行排名,确保 LLM 得到准确和最新的信息。
-
生成(Generation):在检索到相关文档后,LLM 使用检索到的信息和其预训练知识来生成回复。
毫无疑问,具备了外部知识库的 RAG 会显著增强 LLM 响应的准确性和质量。然而,初级 RAG 仍旧以静态方式运行,也就是说,每当用户发出查询时,都会遵循相同的过程。这种一致性虽确保了可靠性,但限制了系统在特定上下文或场景中动态适应的能力。
那么,如何破这种局限性?我们需要更高级的 RAG 方法,如 ReACT (推理与行动) 和 Agentic RAG。这些策略通过增加以下环节来帮助系统更好地响应用户查询:
-
推理
-
决策
-
任务执行
在 Agentic RAG 这样的高级系统中,这些环节将逻辑思维与简单行动结合在一起,使任务执行更加准确和灵活。
什么是 ReACT
ReACT,即“推理与行动”,是 LLM 工作方式的突破。与传统模型快速给出答案不同,ReACT 帮助 AI 逐步思考问题。这种称为链式思维 (CoT) 的方法使模型能够更有效地解决复杂任务。
2022 年的一篇研究论文展示了如何将推理与行动结合使 AI 更聪明。传统模型在处理复杂问题时常常遇到困难,但 ReACT 改变了这一点。它帮助 AI 暂停、批判性思考并提出更好的解决方案。
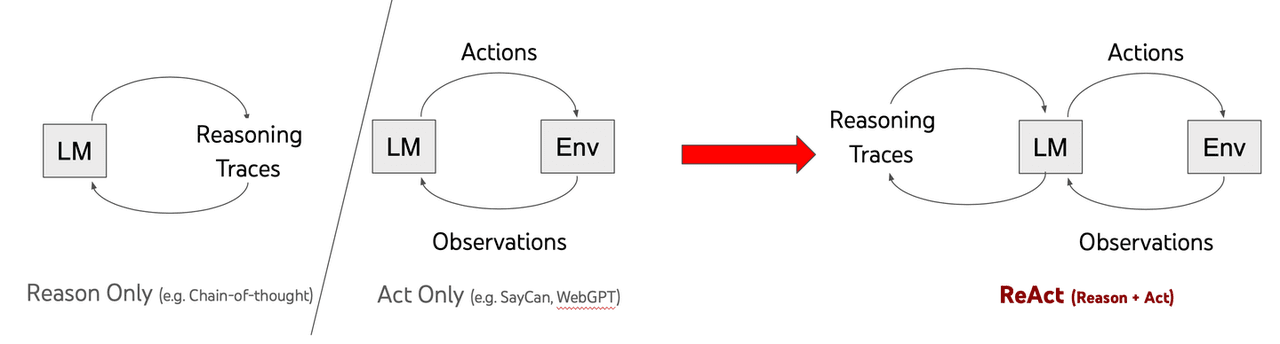
ReAct 的方式与传统 LLM 工作方式的关键区别在于解决问题的方法。ReACT 驱动的模型并不急于给出答案,而是系统性地分解问题。这样,LLM 在处理现实世界问题时会更加具有适应性和可靠性。
通过教导 AI 在行动之前进行推理,ReACT 正在推动人工智能的边界。它不仅仅是拥有信息——而是智能地使用这些信息。
ReACT 如何工作
ReACT 通过将系统化的推理过程与可操作的步骤相结合,增强了 LLM 的能力。该框架通常包括以下环节:

-
推理分析:用户发出查询后,LLM 首先将用户的查询分解,识别需要检索的知识点。然后制定策略,并决定是否需要外部信息或工具。
-
行动执行:根据推理,AI 采取行动,例如与外部工具交互、检索特定数据或访问 API。
-
观察:行动后,AI 获取行动结果(如检索到的文档、API 返回的数据),并将其整合到思维过程。
-
迭代改进: ReACT 可以使 AI 在执行步骤的过程中细化其推理,调整推理路径,不断循环思考、行动和观察来决定是否继续检索或生成最终答案。
这种逐步推理类似于人类解决复杂问题的方式,确保最终响应经过深思熟虑且与上下文相关。
什么是 Agent
ReACT 专注于模型内部的推理,Agent 则承担在模型外部执行特定任务的角色。Agent 具备自主性,会根据模型提供的指令行动,使系统能够与外部工具、API、数据库互动,甚至执行复杂的多步骤工作流。
Agent 如何工作
-
任务识别:LLM 通常在 ReACT 推理的指导下,确定给定任务所需的 Agent。例如,关于最近天气状况的查询可能会激活一个数据检索 Agent 来获取实时天气更新。
-
执行:选定的 Agent 执行任务。这可能涉及查询数据库、抓取网页内容、调用 API 或执行计算。
-
反馈循环:一旦任务完成,Agent 将结果返回给 LLM 以进行进一步推理或响应生成。
-
链式多 Agent 协作:在更复杂的场景中,可以按顺序协调多个 Agent。例如,一个 Agent 检索原始数据,另一个 Agent 处理数据,第三个 Agent 可视化或格式化最终输出。
Agent 与模块化
Agent 在设计上是模块化的,这意味着它们可以根据不同的应用进行定制,比如:
-
检索 Agent: 从向量数据库或知识图谱中获取数据。
-
摘要 Agent: 将检索到的信息浓缩为要点。
-
计算 Agent: 处理需要计算或数据转换的任务。
-
API 交互 Agent: 与外部服务集成以获取实时更新。
这种模块化方法提升了灵活性和可扩展性,随时可以添加新的 Agent 以满足特定需求。
什么是 Agentic RAG
Agentic RAG 将 ReACT 的推理能力与 Agent 的任务执行能力相结合,创建一个动态和自适应的系统。与遵循固定 pipeline 的传统 RAG 不同,Agentic RAG 通过使用 ReACT 根据用户查询的上下文动态协调 Agent,引入了灵活性。这使得系统不仅能够检索和生成信息,还能够根据上下文、不断变化的目标和与之互动的数据采取合适的行动。
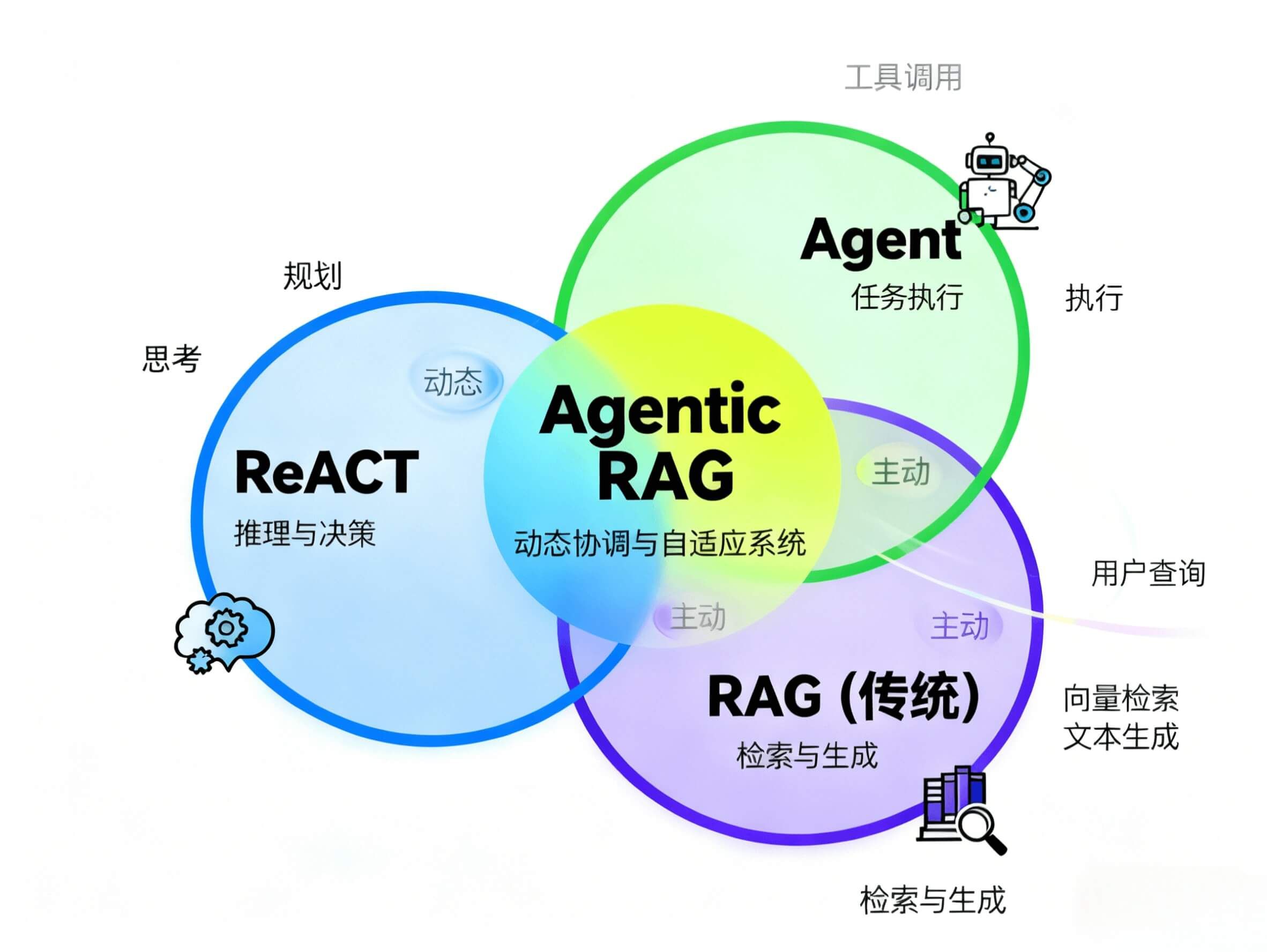
这些进步使 Agentic RAG 成为一个更强大和灵活的框架。模型不再仅限于被动响应用户查询;相反,它可以主动规划、执行并调整其方法以独立解决问题。如此,系统能够处理更复杂的任务,动态适应新挑战,并提供更具上下文相关性的响应。
Agentic RAG 如何工作
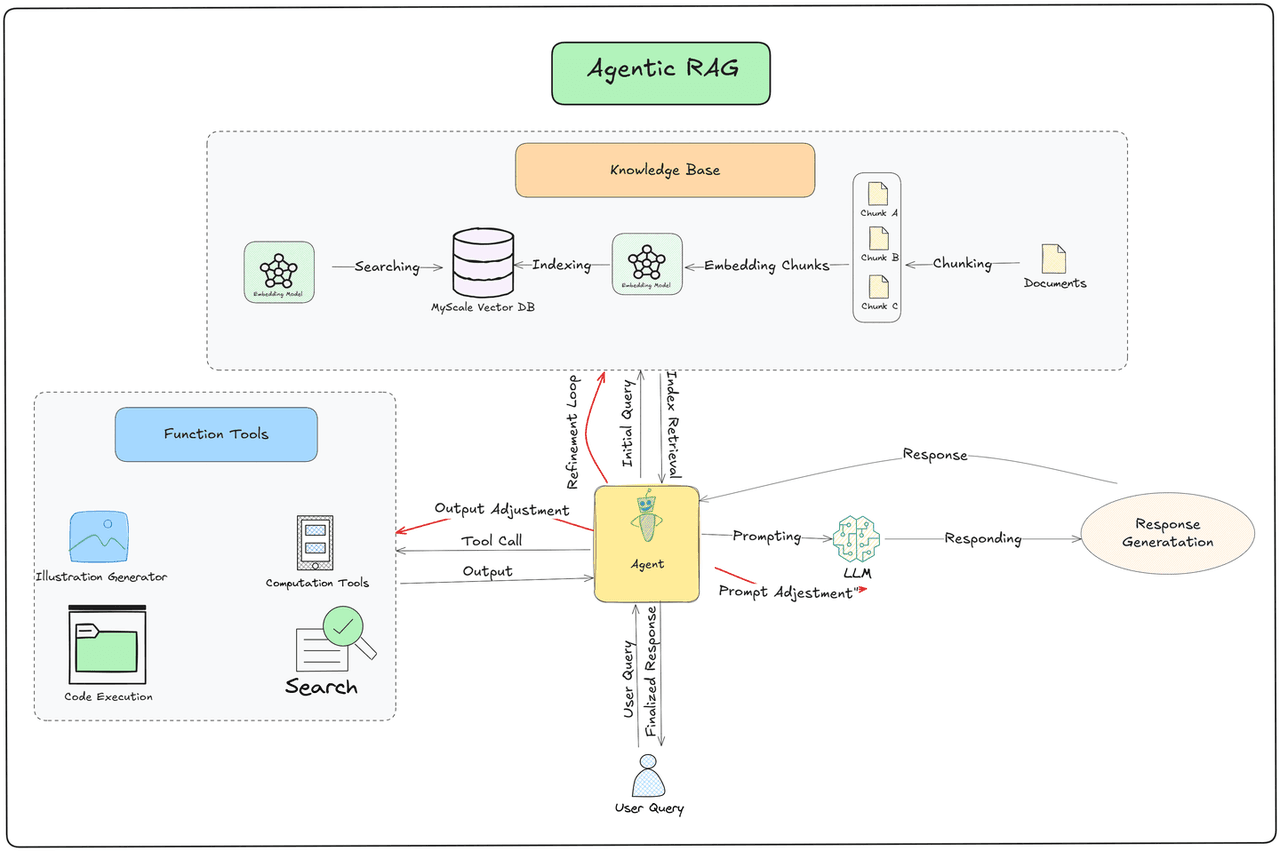
Agentic RAG 的关键创新在于其能够自主使用工具、做出决策并规划下一步。其工作流包括以下核心阶段:
-
处理用户查询
- 用户向系统提交的查询,如文本、语音等,会先进行处理,转化格式,待作后续步骤使用。
-
从向量数据库中检索数据:
-
文档以嵌入的形式存储在向量数据库中,检索器基于向量索引或关键词搜索,从多源文档库中检索相关内容。
-
如果检索到的数据不足,Agent 会细化查询并进行其它的检索尝试,以提取更好的结果。
-
-
使用 Function Tools 进行外部数据获取:
- 如果向量数据库缺乏必要的信息,Agent 使用 Function Tools 从外部来源(如 API、网络搜索引擎或专有数据流)收集实时数据,确保系统提供最新和上下文相关的信息。
-
LLM 生成响应:
- 检索到的数据及工具调用的结果传递给 LLM 后,它综合这些数据生成针对查询的详细、自然流畅、准确的回答。
-
Agent 驱动的改进:
- 在 LLM 生成回答后,Agent 检查结果的逻辑一致性或事实准确性,触发二次检索或修正。最终,在达到预设精度或轮次后输出最终答案给用户。
比较:Agentic RAG 与 RAG
| 特征 | 传统 RAG | Agentic RAG |
|---|---|---|
| 任务处理 | 在生成响应之前从外部来源(例如数据库、文档)检索相关信息,是静态流程。 | 通过添加推理和行动能力扩展 RAG,使其能够主动与环境互动并进行反馈学习,是动态流程。 |
| 环境互动 | 仅从外部知识库检索数据,属于被动互动。 | 具有自主性,主动与外部环境(API、数据源)互动,并根据反馈进行调整 |
| 推理 | 没有明确的推理;依赖检索提供上下文。 | 明确的推理轨迹指导决策和任务完成。 |
| 反馈循环 | 不包含学习的反馈循环。 | 包含来自环境的反馈,以细化推理和行动。 |
| 用例 | 适合需要上下文检索的任务(例如,简单问答)。 | 适合需要推理和与外部系统互动的任务(例如,决策、规划)。 |
结论
Agentic RAG 代表了人工智能领域的重大进步。通过将 LLM 的能力与自主推理和信息检索的能力相结合,Agentic RAG 提供了新的智能和适应性水平。随着 AI 的不断发展,Agentic RAG 将在各个行业中发挥越来越重要的作用,改变我们与技术的工作和互动方式。
要充分实现 Agentic AI 的潜力,满足大规模 AI 应用的苛刻需求,强大而高效的 AI 数据库至关重要。OriginHub MyScale AI 数据库凭借其先进的索引技术和优化的查询处理能力,能够高效赋能 Agentic RAG 系统快速检索相关信息并生成高质量的响应,释放 Agentic AI 的全部潜力并推动创新。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)