从“看到”到“说到”:视觉注意力驱动的图像描述生成
本文解读了经典论文《Show, Attend and Tell》,介绍了视觉注意力机制如何使AI实现"看图说话"。传统方法通过全局特征生成描述存在信息丢失问题,而该论文创新性地提出软/硬两种注意力机制:软注意力通过加权混合关注区域,硬注意力则随机聚焦特定区域。模型架构包含编码器、注意力模块和解码器三部分,通过可视化展示模型生成词语时关注的图像区域。实验证明该方法在多个数据集上达到最优性能,且具有良
从“看到”到“说到”:视觉注意力驱动的图像描述生成
本文深入解读了2015年那篇经典论文《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》,带大家理解视觉注意力机制如何让AI学会“看图说话”。
引言:让机器学会"看图说话"
想象一下,当你看到一张图片时,你的眼睛不会一次处理所有信息,而是会快速扫描图片中最重要的部分——可能是一个人的脸、一个特别的物体,或者一个有趣的动作。你的大脑会把这些视觉碎片组合起来,然后用语言描述出来。这就是"看图说话"的自然过程。
在计算机视觉领域,让机器学会"看图说话"一直是极具挑战性的任务。这不仅仅要求机器能识别图片中的物体,还要理解它们之间的关系,并用自然的语言表达出来。传统的做法是把整张图片压缩成一个固定长度的向量,然后让语言模型基于这个向量生成描述。但这种方法有个明显的缺点:它丢失了图片的空间信息和局部细节。
核心问题:全局特征 vs 局部注意力
在《Show, Attend and Tell》这篇论文发表之前,大多数图像描述生成模型都采用一个简单的思路:用一个卷积神经网络(比如AlexNet或VGG)提取图片的全局特征,然后把这个特征向量输入到循环神经网络(通常是LSTM)中生成文字描述。
这种方法存在两个主要问题:
-
信息丢失:把整张224×224的图片压缩成4096维的向量,必然会丢失大量细节信息
-
缺乏可解释性:我们不知道模型生成每个词时到底"看"到了图片的哪个部分
这就像让你看完一张图片后立即闭上眼睛,然后凭记忆描述它——你可能会记得主要物体,但会忘记很多细节。
核心创新:引入视觉注意力机制
这篇论文的核心创新点,就是引入了视觉注意力机制。简单来说,就是让模型在生成每个词时,动态地决定应该关注图片的哪个区域。
两种注意力机制
论文提出了两种不同的注意力机制,各有特点:
1. 软注意力(Soft Attention)
软注意力可以理解为"温和的注视"。它不是死死盯着一个点,而是给图片的每个区域分配一个权重,然后把这些区域的视觉特征按照权重混合起来。
举个例子:当模型要生成"狗"这个词时,它会给图片中可能是狗的区域分配较高的权重,给其他区域分配较低的权重,然后把所有这些区域的特征加权平均,得到一个"狗相关的"视觉上下文。
这种方法的优点是可微分,可以直接用反向传播训练,整个过程很平滑。
2. 硬注意力(Hard Attention)
硬注意力则更像"迅速的扫视"。在每个时间步,它随机选择一个图像区域作为关注的焦点,就像人的眼睛快速从一个点跳到另一个点。
工作原理:模型先计算每个区域被选中的概率,然后根据这个概率分布随机采样一个区域。这种选择是"硬"的——要么选中,要么没选中,没有中间状态。
这种方法更接近人类的注意力机制,但因为涉及随机采样,训练时需要用到强化学习技术(特别是REINFORCE算法)。
模型架构:如何实现注意力机制
整个模型可以分为三个主要部分:
1. 编码器:提取视觉特征
首先,我们需要从图片中提取有用的视觉特征。论文使用了预训练的VGG网络,但关键的是,它没有使用最后一个全连接层的输出(这是当时的主流做法),而是使用了卷积层的输出。
为什么要用卷积特征而不是全连接特征呢?因为卷积特征保留了空间信息。一个14×14×512的特征图,可以看作是图片被分成了14×14=196个网格,每个网格都有一个512维的特征向量,对应着图片的一个局部区域。
2. 注意力模块:决定"看哪里"
这是模型的核心创新。在每个时间步t,当LSTM要生成第t个词时,它会:
-
基于当前的隐藏状态
,计算对每个图像区域的"关注程度"
-
根据这些关注程度,构建一个上下文向量
z_t
数学上,这个过程可以表示为:
首先计算每个区域的"能量值":
其中是第i个图像区域的特征向量,
是LSTM上一个时间步的隐藏状态。
然后用softmax函数将这些能量值转换为权重(这些权重加起来等于1):
3. 解码器:生成文字描述
解码器是一个LSTM网络,它的特别之处在于,除了常规的输入(上一个词的词嵌入)外,还在每个时间步接收一个上下文向量,这个向量包含了当前最应该关注的视觉信息。
对于软注意力:
对于硬注意力:
其中s_t是从多项分布中采样得到的位置索引。
LSTM的更新公式如下:
这些公式可能看起来复杂,但核心思想很简单:LSTM有三个"门"(输入门、遗忘门、输出门)来控制信息的流动,而上下文向量作为一种额外的视觉输入,影响了所有这些门的计算。
最后,模型通过一个深度输出层来预测下一个词:
这个公式的意思是说,下一个词的概率分布取决于三个因素:上一个词的嵌入()、当前的隐藏状态(
)和视觉上下文(
)。
注意力可视化:让模型"看得见"
论文最令人印象深刻的部分之一就是注意力可视化。通过将注意力权重上采样回原始图片大小,我们可以看到模型在生成每个词时到底在"看"哪里。
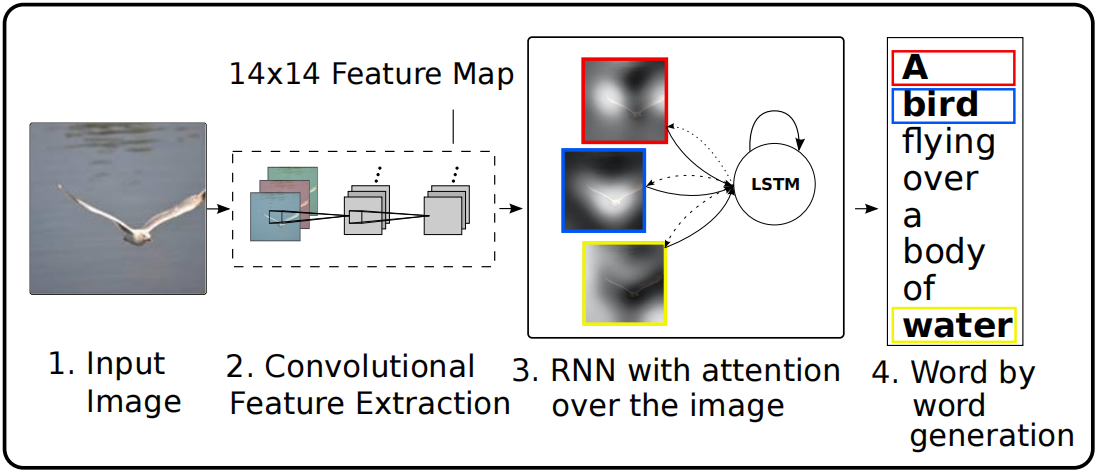
图1展示的是单词与图像的对应关系。图中的热力图显示了模型在生成特定单词时关注的图像区域。例如,当生成"dog"时,模型主要关注图片中狗的部分;当生成"frisbee"时,关注飞盘的部分。这种对齐不是手动设定的,而是模型自己学习到的。

图3更详细地展示了软注意力和硬注意力在生成每个词时的关注模式。可以看到,软注意力(上图)的关注区域比较平滑、分散,而硬注意力(下图)则更加集中、离散。有趣的是,尽管两种注意力的工作方式不同,但在这个例子中生成了完全相同的描述。
软注意力的双重随机正则化
在训练软注意力模型时,论文还引入了一个巧妙的技巧:双重随机正则化。
正常情况下,注意力权重在每个时间步加起来等于1(即),但并没有约束每个位置在所有时间步的总关注度。这意味着模型可能会完全忽略图片的某些区域。
为了解决这个问题,论文添加了一个额外的约束:鼓励每个位置在所有时间步的注意力权重之和接近一个常数τ(实验中设为1):
对应的惩罚项被加入到损失函数中:
这个技巧有两个好处:
-
提高描述丰富性:强制模型关注图片的不同区域,从而生成更全面的描述
-
防止过拟合:避免模型只关注少数几个"容易"的区域
硬注意力的训练技巧
训练硬注意力模型要复杂一些,因为它涉及随机采样。论文使用了REINFORCE算法,这是强化学习中常用的策略梯度方法。
核心思想是:把选择注意力位置看作一个"动作",把生成描述的对数似然看作"奖励"。通过采样多个注意力轨迹,可以估计出梯度并更新模型参数。
为了降低训练方差,论文还使用了几个技巧:
-
移动平均基线:用之前批次的平均奖励作为基线
-
熵正则化:鼓励探索,防止过早收敛到局部最优
-
部分确定性训练:有一半的概率使用期望值代替采样值
这些技巧使得硬注意力模型能够稳定训练,最终在多个数据集上取得了优异的表现。
实验结果与意义
在Flickr8k、Flickr30k和MS COCO三个基准数据集上,这种基于注意力的模型都取得了当时的最优性能。特别是在MS COCO数据集上,硬注意力模型在BLEU-4指标上达到了25.0,显著超过了之前的方法。

图4进一步展示了模型正确关注到物体的情况。图中白色区域表示模型在生成某个单词时关注的图像区域,下划线标出了对应的单词。我们可以看到,模型在生成"woman"、"red"、"white"、"skateboard"等词时,确实关注到了图片中相应的物体或属性区域。这种精确的对齐证明了注意力机制的有效性。
但更重要的是,这篇论文展示了注意力机制的可解释性优势。通过可视化注意力权重,我们可以理解模型为什么生成了某个描述,甚至能分析它为什么会犯错。

图5展示了一些错误案例及其注意力可视化。通过观察模型在生成错误描述时的关注区域,我们可以直观地理解错误的原因。例如,模型可能因为关注了错误的区域而将"猫"误认为"狗",或者因为忽略了关键细节而描述不完整。
总结与展望
《Show, Attend and Tell》这篇论文的主要贡献可以总结为三点:
-
方法创新:首次将视觉注意力机制系统性地引入图像描述生成任务,提出了软硬两种注意力机制
-
性能提升:在多个基准数据集上取得了当时的最优结果
-
可解释性:通过注意力可视化,让模型的决策过程变得透明可理解
这篇论文的影响远远超出了图像描述生成领域。它启发了后续很多视觉-语言任务的研究,包括视觉问答、图像检索、视觉推理等。注意力机制也成为了深度学习中的标准模块,被广泛应用于各种序列到序列的任务中。
如今,基于Transformer的架构(如ViT、DETR等)进一步发展了注意力机制的思想,但《Show, Attend and Tell》中提出的核心理念——让模型动态地关注输入的不同部分——仍然是现代深度学习架构的基础之一。
对于刚入门的小白来说,理解这篇论文的关键在于把握一个核心思想:好的模型不应该一次处理所有信息,而应该学会在适当的时候关注适当的部分。这个思想不仅在计算机视觉中有用,在自然语言处理、语音识别、甚至强化学习中都有着广泛的应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)