FMA-Net++: Motion- and Exposure-Aware Real-World Joint Video Super-Resolution and Deblurring
本文介绍了一种新型视频修复方法FMA-Net++,由KAIST和Chung-Ang University团队提出。该方法创新性地将动态曝光因素纳入视频修复过程,解决了传统方法假设固定曝光导致的修复质量不稳定问题。FMA-Net++采用解耦设计,包含退化学习网络(Netᴰ)和恢复网络(Netᴿ),通过分层细化双向传播块(HRBP)实现并行长程时间建模,并结合曝光感知模块(ETM)动态调整修复策略。实
发表日期: 2025年12月
作者: Geunhyuk Youk, Jihyong Oh, Munchurl Kim
发表单位: KAIST, Chung-Ang University
原文链接: https://arxiv.org/pdf/2512.04390
项目链接: https://kaist-viclab.github.io/fmanetpp site/
这背后其实是一个被很多AI视频修复工具忽略的“魔鬼细节”——动态曝光。我们手机相机的“自动曝光”功能,会根据环境光线实时调整每帧画面的曝光时间。光线暗的时候,曝光时间变长,更容易拍出模糊;光线亮的时候,曝光时间变短,模糊会减轻。这种曝光时间随帧变化的特性,与物体本身的运动耦合在一起,产生了极其复杂、每帧都不同的退化效果。
最近,来自KAIST和Chung-Ang University的研究团队,就在CVPR 2024上发表了论文《FMA-Net++: Motion- and Exposure-Aware Real-World Joint Video Super-Resolution and Deblurring》,直击这个痛点。他们提出的FMA-Net++,号称能同时搞定视频超分辨率(让画面更清晰)和去模糊,并且显式地建模动态曝光的影响。效果有多猛?先看一张对比图感受一下

图5:FMA-Net++在REDS4-ME-5:5和GoPro数据集上的定性对比。每个场景都包含严重的运动模糊。
视频修复新突破:FMA-Net++如何同时搞定超分与去模糊?
首先,我们得搞清楚它要解决的核心任务:联合视频超分辨率与去模糊,英文是Joint Video Super-Resolution and Deblurring,论文里简称为VSRDB。这个任务的目标是,输入一段模糊的、低分辨率的视频,输出一段清晰的、高分辨率的视频。
为什么要把这两件事放一起做?因为现实中它们本来就是纠缠在一起的。想象一下,你手抖拍糊了一段视频,这个“糊”本身就是运动轨迹在时间上的积分。如果先做超分,相当于把模糊的图案放大,模糊本身并没有被消除;如果先做去模糊,虽然可能去掉一些模糊,但丢失的高频细节(比如清晰的边缘、纹理)却无法通过简单的放大找回来。所以,分开处理往往事倍功半,甚至引入新的伪影。
FMA-Net++的厉害之处在于,它不仅仅做了“联合”,更是把退化过程(视频是怎么变模糊、变模糊的)和恢复过程(怎么把它变清晰)给解耦了。用一个不太严谨的比喻:传统的端到端模型像一个黑盒子,吃进模糊视频,直接吐出清晰视频,它可能学了个大概,但说不清道不明。而FMA-Net++则像一位侦探,先分析案发现场(估计每帧的曝光时间、物体的运动轨迹,从而推断出“模糊核”),然后再根据这些线索去还原真相(重建清晰画面)。
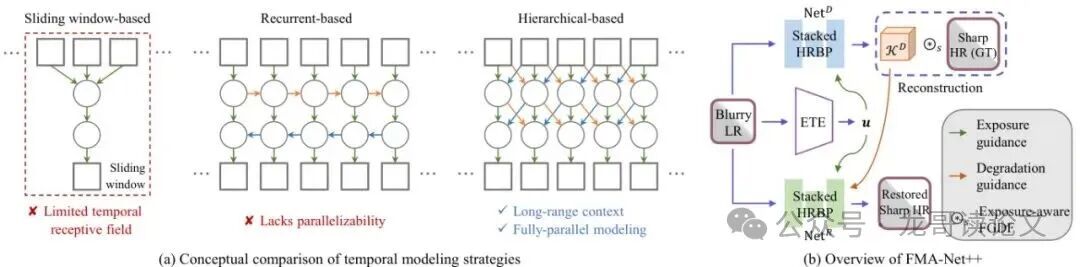
图2:FMA-Net++框架的概念性图示和概述。
上图清晰地展示了这个“先分析,后恢复”的思想。这种解耦设计带来了两个巨大好处:准确性更高(因为恢复过程有了明确的物理线索指导),效率也更高(复杂的退化估计只做一次,简单的恢复可以快速进行)。
现实世界视频修复的痛点:动态曝光与运动模糊的耦合
要理解FMA-Net++的创新,我们必须先明白现实世界视频退化的“元凶”是什么。论文里反复强调一个词:Motion- and Exposure-Aware,即运动与曝光感知。这可不是随便加的两个定语,而是问题的核心。运动模糊是怎么产生的?简单说,相机在曝光时间内,物体或相机本身发生了移动,传感器记录下的就是这段时间内所有位置的“叠加平均”。
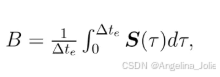
上面这个公式是经典的模糊形成模型。其中,B是模糊帧,Δt_e就是曝光时间,S(τ)是时刻τ的清晰场景信号。看明白了吗?模糊的严重程度直接由曝光时间Δt_e和运动速度共同决定。
在现实拍摄中,尤其是手机摄影,Δt_e不是固定的!相机的自动曝光(Auto-Exposure)功能会不断调整它。走进阴影里,曝光时间自动变长;走到阳光下,曝光时间自动变短。这就导致了一段视频里,不同帧的模糊程度可能天差地别。

图7:REDS-ME数据集中五个曝光等级(5:1到5:5)的示例帧。曝光时间越长,运动模糊越严重。
上图是论文构建的新基准数据集REDS-ME的示例。从左到右,曝光时间依次变长(5:1最短,5:5最长),可以明显看到模糊越来越严重。如果一个修复模型还天真地假设所有帧的曝光时间都一样,那它在处理这种动态变化的视频时,肯定会“精神分裂”,修复效果时好时坏,甚至产生严重的时序不一致。
所以,动态曝光是现实世界VSRDB任务中一个不可忽略的关键变量。FMA-Net++正是抓住了这一点,将其作为核心建模对象。
现有方法的局限:固定曝光假设与有限的时间建模
在FMA-Net++出现之前,主流方法主要有两大类局限。
局限一:死板的“固定曝光”假设
绝大多数视频超分(VSR)和视频去模糊方法,都默认或隐含地假设拍摄时的曝光时间是固定不变的。比如著名的BasicVSR++、RVRT等。这个假设在合成数据集上可能还行,但一到真实世界,面对自动曝光拍出的视频,立刻就露馅了。它们无法适应帧与帧之间模糊强度的剧烈变化,导致修复质量不稳定。
也有一些方法试图引入额外信息,比如事件相机(Event Camera)的数据来辅助(如Ev-DeblurVSR)。事件相机是一种新型传感器,能异步记录像素的亮度变化,理论上对运动非常敏感。但是!99%的普通视频根本没有事件数据,这类方法实用性大打折扣。而且,它们往往还是假设曝光时间已知或固定。
局限二:捉襟见肘的“时间建模”能力
视频修复离不开利用时间上下文信息,即用前后帧的信息来帮助修复当前帧。主流的时间建模策略也有自己的“先天不足”:
滑动窗口(Sliding-Window):比如FMA-Net(FMA-Net++的前作)就采用这种方式。它每次只处理一个固定长度(比如3帧或5帧)的短片段。优点是简单、可以并行计算。但缺点非常明显:时间感受野有限,看不到更远帧的信息,对于长程的依赖或者缓慢的运动就无能为力了。
循环递归(Recurrent):比如BasicVSR++。它像RNN一样,一帧一帧地处理,把前面帧的信息传递下去。这样可以积累很长的历史信息。但致命缺点是无法并行计算,处理长视频慢,而且存在梯度消失/爆炸的风险,训练不稳定。
图2(a):不同时间建模策略的概念性对比。
上图左边就形象地对比了这两种策略的缺点:滑动窗口视野窄,循环递归是串行的。那么,有没有一种方法能既看得远,又能并行跑呢?
FMA-Net++核心架构:解耦退化学习与恢复
现在,让我们掀开FMA-Net++的神秘面纱。它的整体架构如下图所示,清晰地分为两大网络:退化学习网络(Netᴰ)和恢复网络(Netᴿ)。
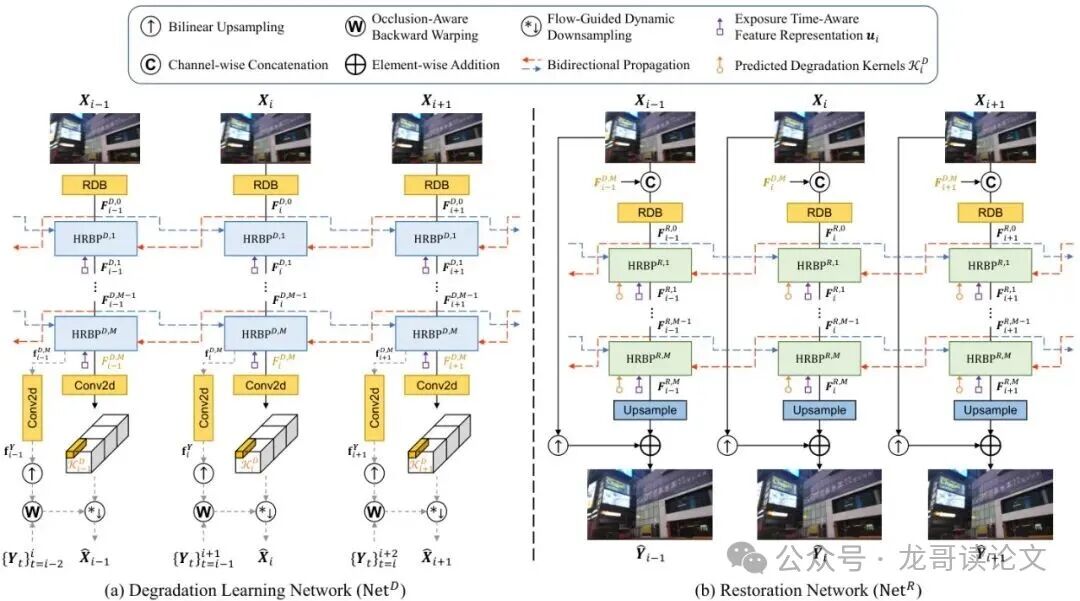
图3:用于联合视频超分辨率与去模糊(VSRDB)的FMA-Net++架构。
Netᴰ(侦探)的任务是:分析输入的模糊低清视频,估计出每帧的退化先验。具体包括: 1. 运动先验:清晰帧之间的光流和遮挡掩码。 2. 退化核先验:一个融合了运动和曝光信息的、空间位置相关的滤波核,记作𝒦ᵢᴰ。这个核就代表了“这一帧的这个像素,是如何由附近几帧清晰高清像素模糊并下采样得到的”。
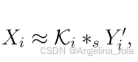
Netᴿ(修复师)的任务是:拿着Netᴰ分析出来的线索(运动先验、退化核先验),结合原始模糊输入,最终恢复出清晰的高清帧。
分层细化双向传播块:实现并行长程时间建模
解决了“做什么”(解耦设计)和“为什么做”(建模动态曝光)的问题后,接下来就是“怎么做”的核心了。FMA-Net++的骨架是一个名为分层细化双向传播块的单元,简称HRBP。无论是侦探(Netᴰ)还是修复师(Netᴿ),它们的核心都是由多层HRBP块堆叠而成。
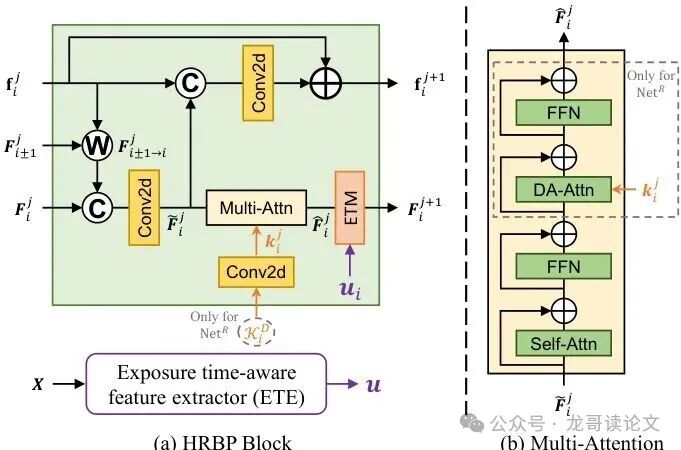
图4:HRBP块的细节。(a) 第(j+1)个细化步骤中,第i帧的HRBP块结构。(b) 多头注意力模块的结构。FFN指Transformer的前馈网络。
HRBP的设计哲学非常巧妙,它要同时解决上一节提到的两个核心局限:有限的感受野和无法并行。它的运作方式像一个信息接力赛:
第一层(j=1):每个HRBP块处理当前帧的特征,并与其直接相邻的前后帧(i-1, i+1)交换信息(通过光流引导的扭曲和融合)。此时,每帧只能“看到”邻居。
第二层(j=2):由于第一层已经融合了邻居信息,那么在第一层输出的特征里,其实已经包含了邻居的“影子”。当第二层HRBP块再处理时,它通过自己的邻居,就能间接“看到”更远的帧(i-2, i+2)。
如此层层堆叠,信息就像涟漪一样,从每帧向时间轴两端扩散。堆叠4个HRBP块,理论上就能建立起覆盖前后多帧的长程时间感受野,完美解决了滑动窗口视野窄的问题。
更妙的是,这个过程完全并行!因为每一层内部,所有帧的处理是独立的,不依赖于前一帧的计算结果(不像RNN那样有序列依赖)。所以,FMA-Net++可以一次性处理整段视频序列,在训练和推理时都极大地提升了效率。这又解决了循环递归方法速度慢的痛点。
此外,HRBP块还集成了一个多头注意力模块(图4b),它包含两种注意力:自注意力用于捕捉空间依赖,而在恢复网络Netᴿ中,还会使用退化感知注意力。这个机制让Netᴿ能够“有针对性”地关注那些被严重退化的区域,相当于修复师拿到了侦探标注的“重点勘查区域”地图。
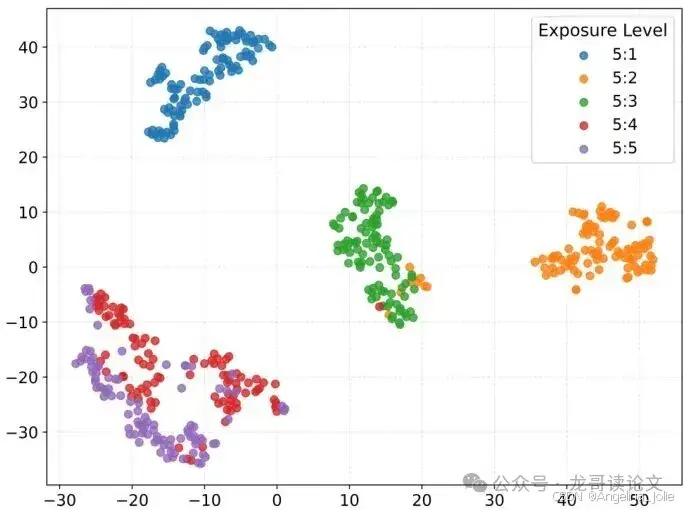
图8:曝光时间感知特征提取器提取的特征的t-SNE可视化,显示了它们在不同曝光等级间的可区分性。
然后,这个“曝光代码”会被送到每一个HRBP块中。在每个块处理完注意力特征后,ETM层会基于这个代码,生成一组简单的缩放和平移参数,去调制(微调)当前的特征图。
![]()
你可以把它想象成给模型戴上了一副“智能眼镜”,这副眼镜能根据每帧的曝光情况,自动调整模型的“视觉敏感度”。对于曝光长、模糊严重的帧,模型的特征表达会更侧重于如何从一团糊中提取结构;对于曝光短、相对清晰的帧,则更侧重于增强细节和分辨率。

图9:ETE引导对Netᴰ预测的曝光感知退化核的影响。对于一个来自REDS4-ME-5:5的严重模糊帧,在正确的曝光引导(5:5)下,核变得空间扩散;而在错误的引导(5:1)下则高度集中,证明了其对曝光的依赖性。
图9的实验直观展示了ETM的作用。当用正确曝光(5:5)的信息去引导Netᴰ时,它预测出的退化核是扩散的,符合严重模糊的特性;而如果用短曝光(5:1)的信息错误引导,预测出的核就变得非常集中,相当于误以为模糊很轻微。这证明了ETM成功地将曝光信息注入到了退化建模的核心过程中。
曝光感知光流引导动态滤波:预测物理可解释的退化核
现在,侦探Netᴰ拥有了强大的时空分析能力(HRBP)和感知曝光变化的“眼镜”(ETM)。它要用这些能力来完成最关键的任务:预测那个融合了运动和曝光信息的、物理可解释的退化核𝒦ᵢᴰ。
这个任务由一个曝光感知的光流引导动态滤波模块来完成。它是前作FMA-Net核心模块的升级版。传统动态滤波是在图像固定的空间邻域内操作,这对于运动模糊是无效的,因为模糊是沿着运动轨迹产生的。因此,FMA-Net引入了光流引导,让滤波的采样点沿着估计的运动路径分布,从而更准确地模拟模糊过程。
FMA-Net++在此基础上,加上了“曝光感知”。还记得HRBP块输出的特征吗?它们已经被ETM层用曝光信息调制过了。曝光感知FGDF模块就利用这些富含曝光上下文的特征,来预测最终的滤波权重。这样一来,预测出的𝒦ᵢᴰ核就同时编码了“物体怎么动”(光流)和“动了多久/多严重”(曝光)这两个关键物理因素。
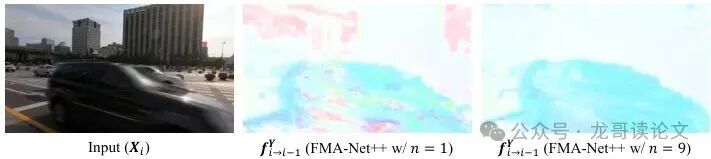
图10:多流-掩码对数量(n)对严重模糊场景下预测光流的影响。
另一个细节是,FMA-Net++采用了多组光流-遮挡掩码对(图10)。在严重模糊下,一个像素可能对应多个可能的清晰位置(一对多匹配)。使用多组假设(论文中n=9)比只用一组光流(n=1)更加鲁棒,能产生更清晰、准确的光流场,为后续的滤波提供更好的运动指导。
至此,Netᴰ侦探成功完成了现场勘查,输出了运动先验和曝光-运动感知退化核这两份关键报告。Netᴿ修复师将根据这些报告,开展高效的复原工作。
两大新基准:REDS-ME与REDS-RE
要公正地评估一个解决动态曝光问题的方法,就需要有相应的“考场”。然而,现有的VSRDB数据集大多假设固定曝光。为此,论文构建了两个新的基准数据集,这是其另一大贡献。
REDS-ME(多曝光):在REDS数据集的基础上,合成了五种不同曝光等级的模糊低清视频,从5:1(曝光最短,模糊最轻)到5:5(曝光最长,模糊最严重)。如图7所示,它系统地模拟了不同曝光时间下的模糊程度,用于训练和评估模型对不同程度静态曝光的处理能力。
REDS-RE(随机曝光):这个数据集更贴近真实世界。它在一段视频内随机混合了五种曝光等级的帧(采用步进式随机游走策略,模拟曝光平滑变化)。如图12所示,它用于评估模型在动态变化曝光下的鲁棒性和时序一致性,是检验“曝光感知”能力的试金石。
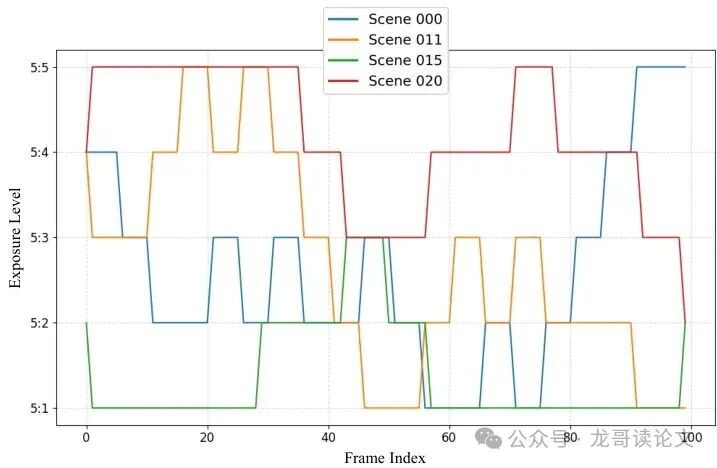
图12:REDS-RE基准中合成的曝光轨迹可视化。每条彩色线代表一个不同测试场景的曝光等级演变。
有了这两个新基准,我们就能科学、全面地评估FMA-Net++及其他方法在动态曝光场景下的真实水平了。
实验结果分析
FMA-Net++的实验设计非常系统和严谨。首先,为了公平比较,论文将多个SOTA的视频超分、去模糊及VSRDB方法在其提出的REDS-ME训练集上进行了重新训练(在结果表中用*标注)。这确保了所有对比方法都在相同的动态曝光数据分布下学习。
评估指标不仅包括衡量像素级精度的PSNR、SSIM,还包含了衡量时间一致性的tOF(时间光流误差),这对于视频修复至关重要。同时,也对比了模型参数量和运行时间,以评估效率。
实验结果全面且令人信服地支持了FMA-Net++的设计。在静态多曝光数据集REDS-ME上,其领先优势已经很明显,这得益于HRBP的长程建模能力和对曝光差异的建模。当测试集切换到动态随机曝光的REDS-RE时,FMA-Net++的优势被进一步放大,这直接证明了其ETM等曝光感知模块的有效性——它确实学会了根据每帧曝光情况自适应调整策略,而非僵化地使用同一套参数。在未参与训练的GoPro数据集上表现优异,则证明了其良好的泛化能力。这种泛化能力源于其建模的物理本质——运动与曝光的耦合是真实世界退化的核心,而非特定数据集的人造特征。
在效率方面,FMA-Net++的表现同样亮眼。得益于其并行化的HRBP架构,它在保持高精度的同时,推理速度远超许多复杂度相近的模型(如RVRT*),实现了超过5倍的加速。这种“又快又好”的特性,为其在手机端、边缘设备等对实时性有要求的场景落地提供了可能。
消融实验进一步夯实了每个设计选择的必要性。例如,移除曝光感知特征提取器(ETE)后,模型在动态曝光数据集REDS-RE上的性能下降最为明显,这直接证明了ETM层是应对曝光变化的关键。而将分层架构替换为滑动窗口或循环版本,性能也会显著下滑,验证了HRBP在长程时间建模和并行效率上的优势。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)