【AI课程领学】课时3:深度学习 —— 从感知机到现代神经网络(含 Python 代码)
【AI课程领学】课时3:深度学习 —— 从感知机到现代神经网络(含 Python 代码)
·
【AI课程领学】课时3:深度学习 —— 从感知机到现代神经网络(含 Python 代码)
【AI课程领学】课时3:深度学习 —— 从感知机到现代神经网络(含 Python 代码)
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文。详细信息可扫描博文下方二维码 “
学术会议小灵通”或参考学术信息专栏:https://ais.cn/u/mmmiUz
详细免费的AI课程可在这里获取→www.lab4ai.cn
3.1 什么是神经网络?
- 最简单的神经网络 = 线性变换 + 非线性激活:
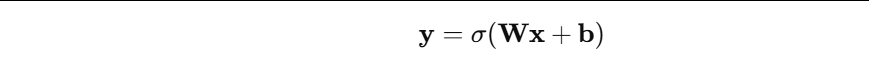
其中: - x x x:输入向量(例如一个像元的多波段值、一个像素的 RGB)
- W W W:权重矩阵(模型参数)
- b b b:偏置
- σ σ σ:激活函数(如 ReLU、Sigmoid)
当你把很多这样的层堆叠起来: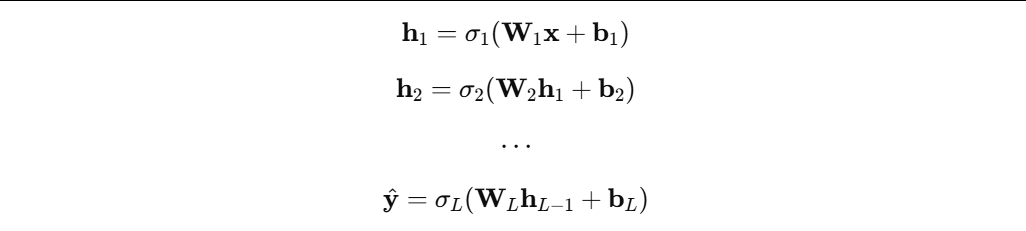
你就得到一个深层网络(Deep Network)。
- 深度学习:用多层神经网络从数据中学习复杂函数。
3.2 一个最小的“手写”神经网络(用 NumPy)
- 先不用任何深度学习框架,完全用 NumPy 手写一个 2 层网络,感受前向传播和反向传播。
3.2.1 网络结构
- 输入维度:2
- 隐层:3 个神经元,ReLU 激活
- 输出:1 维,Sigmoid 激活(用于二分类)
import numpy as np
np.random.seed(42)
# 1. 生成模拟数据:一个简单的二分类问题
num_samples = 200
X = np.random.randn(num_samples, 2)
y = (X[:, 0] * X[:, 1] > 0).astype(np.float32).reshape(-1, 1) # 简单逻辑
# 2. 初始化参数
hidden_dim = 3
input_dim = 2
output_dim = 1
lr = 0.1 # 学习率
W1 = 0.01 * np.random.randn(input_dim, hidden_dim)
b1 = np.zeros((1, hidden_dim))
W2 = 0.01 * np.random.randn(hidden_dim, output_dim)
b2 = np.zeros((1, output_dim))
def relu(z):
return np.maximum(0, z)
def relu_grad(z):
return (z > 0).astype(np.float32)
def sigmoid(z):
return 1.0 / (1.0 + np.exp(-z))
# 3. 训练循环(极简版)
for epoch in range(2000):
# ---- 前向传播 ----
z1 = X @ W1 + b1 # (N, hidden_dim)
a1 = relu(z1) # (N, hidden_dim)
z2 = a1 @ W2 + b2 # (N, 1)
y_hat = sigmoid(z2) # (N, 1)
# 二分类的交叉熵损失
eps = 1e-8
loss = -np.mean(y * np.log(y_hat + eps) + (1 - y) * np.log(1 - y_hat + eps))
# ---- 反向传播 ----
# dL/dz2
dz2 = (y_hat - y) / num_samples # (N, 1)
dW2 = a1.T @ dz2 # (hidden_dim, 1)
db2 = np.sum(dz2, axis=0, keepdims=True)
# dL/da1
da1 = dz2 @ W2.T # (N, hidden_dim)
dz1 = da1 * relu_grad(z1) # (N, hidden_dim)
dW1 = X.T @ dz1 # (2, hidden_dim)
db1 = np.sum(dz1, axis=0, keepdims=True)
# ---- 参数更新 ----
W1 -= lr * dW1
b1 -= lr * db1
W2 -= lr * dW2
b2 -= lr * db2
if (epoch + 1) % 200 == 0:
preds = (y_hat > 0.5).astype(np.float32)
acc = np.mean(preds == y)
print(f"Epoch {epoch+1}, loss={loss:.4f}, acc={acc:.4f}")
这里你可以清晰地看到:
- 前向:矩阵乘 + 激活
- 后向:利用链式法则一步步把梯度“传回去”
- 更新:参数朝着负梯度方向走,这就是最简单的梯度下降
这就是深度学习训练过程的“微缩版”。
3.3 用 PyTorch 写一个真正可用的深度学习模型
- 现在我们用 PyTorch 重写一个类似的网络,但这次让框架帮你处理反向传播和优化。
3.3.1 PyTorch 二分类示例
import torch
import torch.nn as nn
import torch.optim as optim
# 1. 准备数据(同样的逻辑)
torch.manual_seed(42)
N = 500
X = torch.randn(N, 2)
y = (X[:, 0] * X[:, 1] > 0).float().unsqueeze(1)
# 2. 定义网络结构
class SimpleNet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, 16),
nn.ReLU(),
nn.Linear(16, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.net(x)
model = SimpleNet()
criterion = nn.BCELoss() # 二分类交叉熵
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 3. 训练
for epoch in range(1000):
y_hat = model(X)
loss = criterion(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 100 == 0:
preds = (y_hat > 0.5).float()
acc = (preds == y).float().mean().item()
print(f"Epoch {epoch+1}, loss={loss.item():.4f}, acc={acc:.4f}")
这里你能感受到框架的好处:
- 不用手写反向传播,
loss.backward()自动算梯度。 optimizer.step()自动更新所有参数。- 你只需关注网络结构和损失函数。
这也是深度学习在工程上被大规模采用的一个关键:开发成本降低,研究者可以专注在模型设计和问题本身。
3.4 一个典型的“从传统 ML 到深度学习”的迁移思路
假设你有一个实际任务,比如:
- 根据多源遥感指标(LST、NDVI、DEM、降水、土壤类型等)估算地表某一变量(SM / AOD / PM2.5)。
传统机器学习可能会做:
- 手工构造特征(归一化、指数、窗口统计等);
- 用 Random Forest / GBDT / SVM 等进行建模;
- 特征重要性解释物理意义。
深度学习可以做:
- 构建一个多层 MLP / CNN,把“特征构造”与“建模”合并;
- 若有图像空间结构,使用 CNN / U-Net;若有时序信息,使用 RNN / Transformer;
- 通过中间层表征(embeddings)理解模型学到的模式。
用 PyTorch 写一个简单 MLP 回归框架非常像上面二分类的例子,只需把最后一层改为线性输出、损失改为 MSE:
import torch
import torch.nn as nn
import torch.optim as optim
# 假设 feature_dim=10, 有 1000 个样本
torch.manual_seed(0)
N, feature_dim = 1000, 10
X = torch.randn(N, feature_dim)
# 构造一个模拟的回归目标:y = w_true^T x + noise
w_true = torch.randn(feature_dim, 1)
y = X @ w_true + 0.1 * torch.randn(N, 1)
class MLPRegressor(nn.Module):
def __init__(self, in_dim, hidden_dim=64):
super().__init__()
self.net = nn.Sequential(
nn.Linear(in_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, 1)
)
def forward(self, x):
return self.net(x)
model = MLPRegressor(feature_dim)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(1000):
y_pred = model(X)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 200 == 0:
print(f"Epoch {epoch+1}, MSE={loss.item():.4f}")
- 这个 MLP 已经可以作为基准深度学习回归模型,在很多表格型数据任务(包括一些遥感地理变量估算)中与 RF/GBDT 做对比。
3.5 深度学习的几个核心概念(为后续课程铺垫)
1)过拟合与正则化
- 模型太复杂、训练集拟合过好、泛化差。
- 常用手段:Dropout、L2 正则、早停等。
2)优化与梯度
- SGD、Momentum、Adam 等。
- 学习率是超参数中的超参数。
3)训练、验证、测试拆分
- 防止“自我感动”的基本原则:不能在同一数据上调参+评估。
4)可复现性
- 固定随机种子、记录版本、保存配置、写清楚数据预处理流程。
这些会在后续更深入的课程中展开。
3.6 小结
这一课,我们:
- 从数学角度解释了神经网络的基本单元;
- 手写了一个 NumPy 版两层网络,理解前向 + 反向;
- 用 PyTorch 写了一个可用的分类 / 回归模型,感受工程实践;
- 为后续的网络结构、调参、迁移学习等埋下几个关键词。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)