[NAACL 2018]Explainable Prediction of Medical Codes from Clinical Text
计算机-人工智能-卷积注意力交叉熵ICD多标签分类

论文网址:[1802.05695] Explainable Prediction of Medical Codes from Clinical Text
论文代码:GitHub - jamesmullenbach/caml-mimic: multilabel classification of EHR notes
目录
2.3.1. Convolutional architecture
2.3.5. Embedding label descriptions
2.4. Evaluation of code prediction
2.5. Evaluation of Interpretability
2.5.1. Extracting informative text snippets
2.7. Conclusions and Future Work
1. 心得
(1)是数据划分得很好吗?
2. 论文逐段精读
2.1. Abstract
①文本和标签之间没有直接的对间联系,使得分类很难很杂乱
2.2. Introduction
①ICD分类难点:标签空间大、写作风格不统一
②作者提出Convolutional Attention for Multi-Label classification (CAML)
taxonomy n.分类法;分类学;分类系统
2.3. Method
①ICD编码设为
②对每个标签需要去分类这个样本
,其中
2.3.1. Convolutional architecture
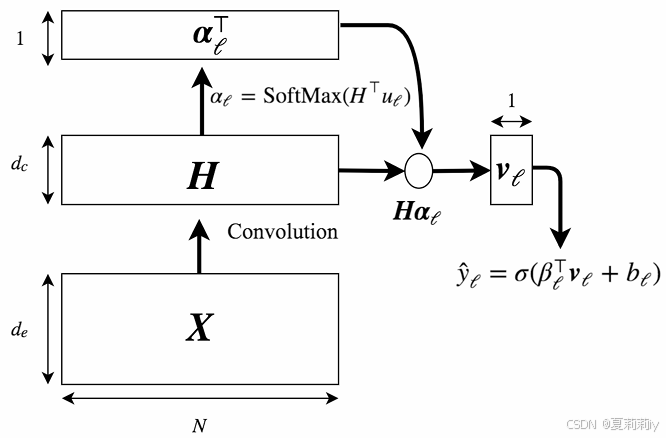
①临床文本嵌入:,其中
是文本长度
②对每个单词嵌入使用卷积:
其中是选择卷积的token/words数,
是输入的文本嵌入隐藏层维度,
是输出的文本嵌入隐藏层维度,*是卷积操作,
逐元素非线性变换,
是偏置。作者padding了一下所以输出是
2.3.2. Attention
①实际上是一个
-gram的文本特征
②计算文本特征和标签特征的矩阵乘积:
其中是标签
的特征
③归一化:
④每个标签的表示:
⑤文档级特征嵌入:
2.3.3. Classification
①对于文档级特征嵌入使用线性层分类:
其中是权重向量,
是偏置标量
②模型设计:
2.3.4. Training
①交叉熵损失:
对权重使用L2正则以及使用Adam优化器
2.3.5. Embedding label descriptions
①I表示相关,HI表示高相关,CAML总是能抓住比较相关的文本:

②另一个约束项variant Description Regularized CAML(DR-CAML),让可学习向量的特征和描述文本特征(从WHO中得到)相近:
2.4. Evaluation of code prediction
2.4.1. Datasets
①MIMIC III:有8921个标签,其中6918是疾病,2003是操作
②按被试ID划分,同一个被试的多次住院不会被同时分进训练集/验证集/测试集
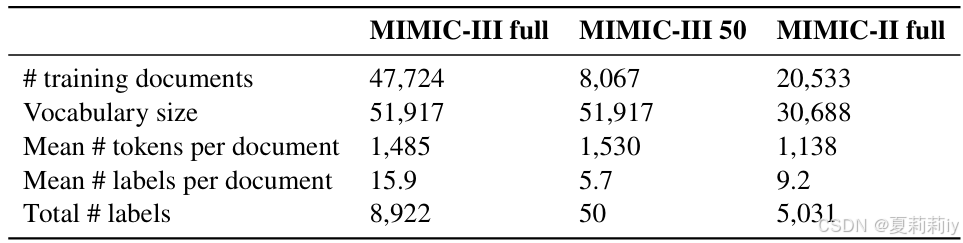
③数据集:MIMIC III full,MIMIC III 50,MIMIC II:
④数据预处理:移除不包含字母的文本(如500被移除但是500mg保留),将所有字母小写,⭐把整个数据集出现小于三个文档的token标记为UNK
⑤预训练文本嵌入模型word2vec CBOW,维度为
⑥所有诊断记录被截断为2500个token
addendum n.补遗;(尤指书籍的)补篇
2.4.2. Systems
①超参数设置:
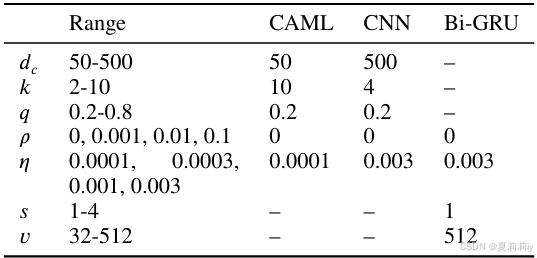
调参是通过Spearmint Bayesian optimization pack age做到的
2.4.3. Evaluation Metrics
①列举一些评估指标
2.4.4. Results
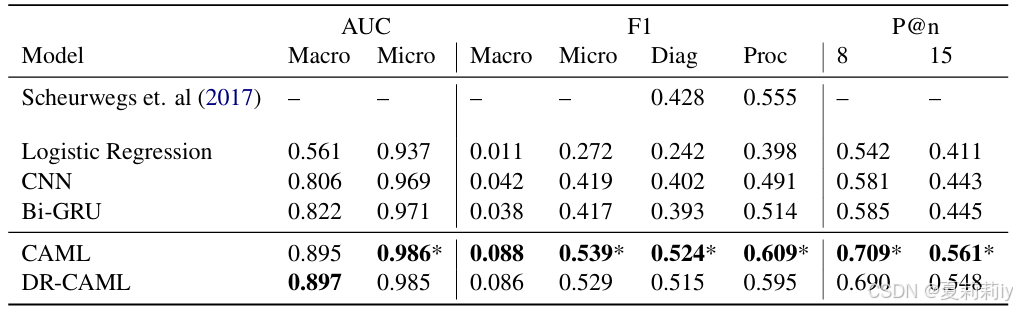
①MIMIC III full上的对比实验:
②MIMIC III 50上的对比实验:
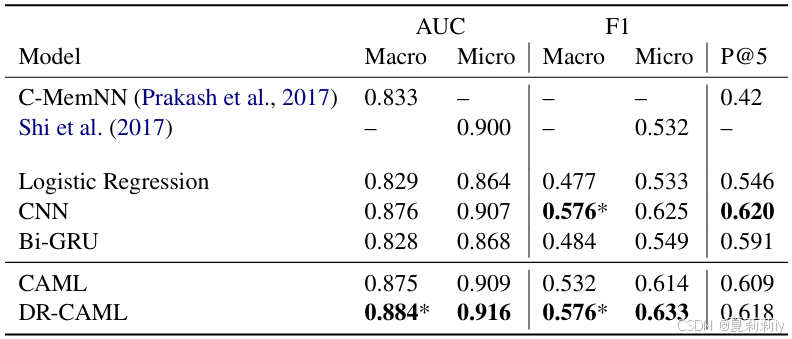
③MIMIC II full上的对比实验:
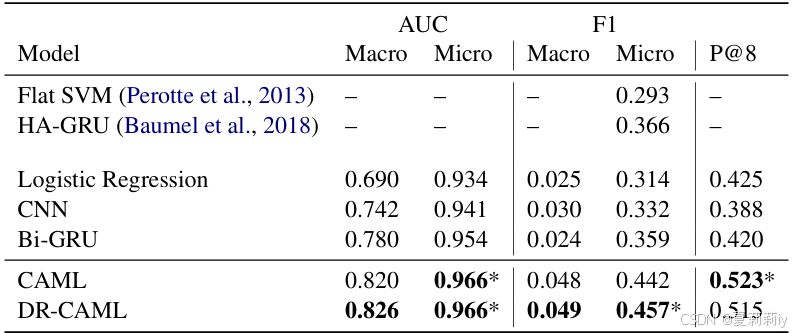
2.5. Evaluation of Interpretability
2.5.1. Extracting informative text snippets
①描述了对于不同模型怎么提取标签对应的n-gram
2.5.2. Results
①请专家评估100次预测中标签和n-gram的对应程度:
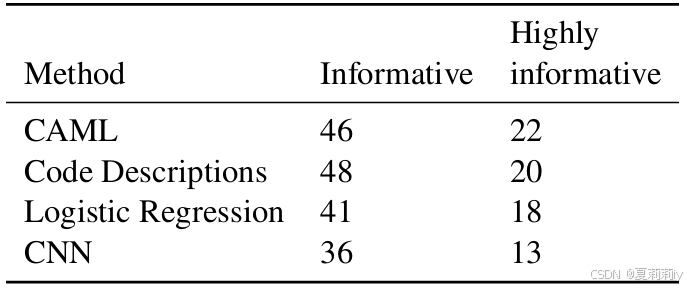
2.6. Related Work
①列举CNN、LSTM、RNN等方法
2.7. Conclusions and Future Work
~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)