AI导读AI论文: Towards a Unified View of Parameter-Efficient Transfer Learning
该论文发表于ICLR 2022,针对传统全参数微调在大规模预训练语言模型(PLMs)中存在的参数冗余、部署成本高等问题,提出了参数高效迁移学习的统一框架,将Adapter、Prefix Tuning、LoRA等主流方法重构为对PLMs隐藏状态的修改,并定义了功能形式、插入形式等核心设计维度;通过跨方法迁移设计元素,提出了MAM Adapter等新变体,在文本摘要(XSum)、机器翻译(WMT201

1. 一段话总结
该论文发表于ICLR 2022,针对传统全参数微调在大规模预训练语言模型(PLMs)中存在的参数冗余、部署成本高等问题,提出了参数高效迁移学习的统一框架,将Adapter、Prefix Tuning、LoRA等主流方法重构为对PLMs隐藏状态的修改,并定义了功能形式、插入形式等核心设计维度;通过跨方法迁移设计元素,提出了MAM Adapter等新变体,在文本摘要(XSum)、机器翻译(WMT2016 en-ro)、自然语言推理(MNLI)和情感分类(SST2)四大任务中,仅微调6.7%(生成任务)或0.5%(分类任务) 的参数,就实现了与全参数微调(100%参数)相当的性能(如XSum的ROUGE-2达21.90,接近全微调的21.94)。
2. 思维导图
## 研究背景与问题
- 核心痛点:全参数微调参数冗余、部署成本高
- 现有方法:Adapter、Prefix Tuning、LoRA等
- 研究缺口:方法间关联不明、关键设计要素未明确
## 统一框架
- 核心思路:重构为PLMs隐藏状态修改
- 设计维度
- 功能形式:Δh的计算方式
- 插入形式:并行/顺序
- 修改表示:注意力层/FFN层
- 组合函数:简单加法/门控加法/缩放加法
## 实验设计
- 数据集:XSum、WMT2016 en-ro、MNLI、SST2
- 基础模型:BART LARGE、mBART LARGE、ROBERTa BASE
- 评价指标:ROUGE、BLEU、准确率
## 关键发现
- 插入形式:并行优于顺序
- 修改表示:FFN层比注意力层更高效(大参数预算)
- 组合函数:缩放加法优于简单加法
## 新变体与性能
- 代表变体:MAM Adapter、并行Adapter、缩放并行Adapter
- 核心优势:少参数+高性能(6.7%参数≈全微调)
## 结论
- 统一框架揭示方法关联
- 新变体实现参数高效与性能平衡
3. 详细总结
一、研究背景与核心问题
- 行业现状:预训练语言模型(PLMs)迁移学习已成为NLP主流范式,但传统全参数微调存在两大问题:
- 参数冗余:模型规模达数百亿/万亿参数(如Brown et al., 2020的千亿参数模型),多任务场景下需存储多个模型副本,部署成本极高;
- 泛化局限:现有参数高效方法(Adapter、Prefix Tuning等)虽仅微调<1%参数,但性能在高资源/复杂任务(如文本摘要、机器翻译)中仍落后于全微调。
- 核心问题:
- 现有参数高效方法的关联的是什么?
- 其成功的关键设计要素有哪些?
- 能否跨方法迁移设计要素,提出更优变体?
二、现有参数高效调优方法
| 方法 | 核心机制 | 调优参数占比(示例) | 关键特点 |
|---|---|---|---|
| Adapter(Houlsby et al., 2019) | 插入瓶颈层(down-proj→非线性→up-proj),顺序插入Transformer层 | 0.5%-7.2% | 单头结构,可插入注意力层/FFN层 |
| Prefix Tuning(Li & Liang, 2021) | 在注意力层键/值前拼接可学习前缀向量 | 0.1%-3.6% | 多头结构,并行插入,依赖门控加法 |
| LoRA(Hu et al., 2021) | 注入低秩矩阵近似权重更新,应用于注意力层查询/值投影 | 0.5%-7.2% | 缩放加法组合,参数利用率高 |
| BitFit(Ben Zaken et al., 2021) | 仅微调预训练模型的偏置向量 | 0.1% | 参数最少,但复杂任务性能较弱 |
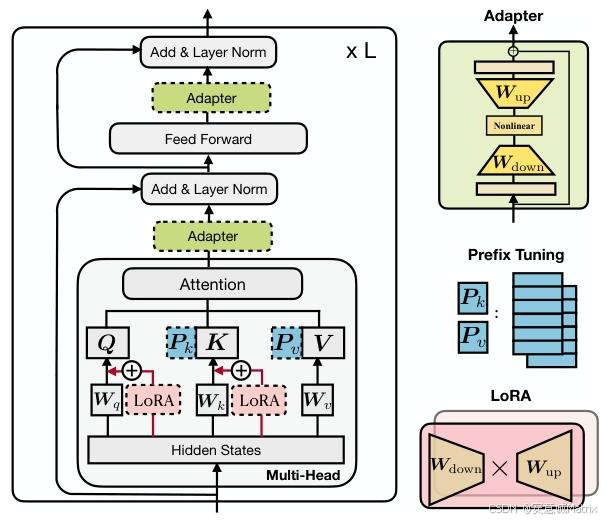
三、统一框架设计
- 核心重构:将所有参数高效方法统一为“学习修改向量Δh,作用于PLMs隐藏状态”的过程。
- 四大设计维度(关键区分标准):
- 功能形式:Δh的计算方式(如Adapter的ReLU非线性、LoRA的线性投影);
- 插入形式:并行(如Prefix Tuning、LoRA,输入为PLM层输入x)/顺序(如传统Adapter,输入为PLM层输出h);
- 修改表示:直接修改的隐藏状态(注意力层输出/FFN层输出);
- 组合函数:Δh与原始h的融合方式(简单加法、门控加法、缩放加法)。
- 跨方法关联:Prefix Tuning的Δh计算可拆解为低秩矩阵操作,与Adapter的瓶颈层机制同源;LoRA的缩放加法可迁移至Adapter,形成“缩放并行Adapter”。
四、实验设计详情
- 数据集与模型:
| 任务类型 | 数据集 | 基础模型 | 训练数据量 | 评价指标 |
|---|---|---|---|---|
| 文本摘要 | XSum | BART LARGE | 204,045条训练数据 | ROUGE-1/2/L |
| 机器翻译 | WMT2016 en-ro | mBART LARGE | 610,320条训练数据 | BLEU |
| 自然语言推理 | MNLI | ROBERTa BASE | 392,702条训练数据 | 准确率 |
| 情感分类 | SST2 | ROBERTa BASE | 67,349条训练数据 | 准确率 |
- 实验设置:
- 瓶颈维度r/l范围:{1, 30, 200, 512, 1024};
- 优化器:Adam,学习率5e-5(生成任务)/1e-4(分类任务);
- 对比基准:全参数微调(100%参数)、现有参数高效方法。
五、关键实验发现
- 现有方法局限性:在高资源任务(如XSum、en-ro翻译)中,即使调优10%+参数,性能仍落后全微调(如XSum的ROUGE-2:Adapter为20.98,全微调为21.94);
- 设计维度有效性:
- 插入形式:并行插入(如并行Adapter)优于顺序插入(传统Adapter),XSum任务ROUGE-2提升1.7个点;
- 修改表示:大参数预算下,FFN层修改比注意力层更高效(LoRA-FFN比LoRA-注意力在XSum的ROUGE-2提升1个点);小参数预算(0.1%)下,多头注意力修改(Prefix Tuning、MH PA)更优;
- 组合函数:缩放加法(LoRA、缩放并行Adapter)优于简单加法,XSum的ROUGE-2提升0.56个点。
六、新变体与性能表现
- 核心变体:MAM Adapter:
- 设计逻辑:注意力层用Prefix Tuning(l=30,0.1%参数)+ FFN层用缩放并行Adapter(r=512,6.6%参数),总调优参数6.7%;
- 性能对比(生成任务):
| 方法 | 调优参数占比 | XSum(ROUGE-2) | WMT2016 en-ro(BLEU) |
|---|---|---|---|
| 全参数微调(论文基准) | 100% | 22.27 | 37.7 |
| 全参数微调(本文复现) | 100% | 21.94 | 37.3 |
| MAM Adapter | 6.7% | 21.90 | 37.5 |
| Prefix Tuning(l=200) | 3.6% | 20.46 | 35.6 |
| LoRA(ffn, r=102) | 7.2% | 21.29 | 36.8 |
- 分类任务表现:MAM Adapter仅调优0.5%参数,MNLI准确率达87.4%(全微调87.6%),SST2准确率达94.2%(全微调94.6%)。
七、结论
- 提出的统一框架揭示了现有参数高效方法的内在关联,明确了四大核心设计维度;
- 跨方法迁移设计要素可生成更优变体,MAM Adapter实现“少参数(6.7%/0.5%)+ 高性能(媲美全微调)”;
- 为未来参数高效调优提供指导:根据参数预算选择修改表示(FFN层/注意力层),优先采用并行插入和缩放加法。
4. 关键问题
问题1:论文提出的统一框架包含哪四大核心设计维度?这些维度如何区分不同参数高效调优方法?
答案:四大核心设计维度为功能形式、插入形式、修改表示、组合函数。区分方式如下:①功能形式:Δh的计算逻辑(如Adapter含ReLU非线性,LoRA为线性投影);②插入形式:新增模块的插入方式(并行插入如Prefix Tuning,顺序插入如传统Adapter);③修改表示:直接作用的隐藏状态(注意力层输出或FFN层输出);④组合函数:Δh与原始隐藏状态的融合方式(Adapter的简单加法、Prefix Tuning的门控加法、LoRA的缩放加法)。该维度体系可将Adapter、Prefix Tuning、LoRA等主流方法统一归类,明确其设计差异。
问题2:新提出的MAM Adapter如何融合现有方法的优势?其在核心任务上的性能表现与全参数微调相比如何?
答案:MAM Adapter的融合逻辑的是:①借鉴Prefix Tuning的“多头注意力修改”优势,在注意力层采用小瓶颈维度(l=30)的Prefix Tuning,适配小参数预算场景;②借鉴LoRA的“缩放加法”和Adapter的“FFN层修改”优势,在FFN层采用大瓶颈维度(r=512)的缩放并行Adapter,充分利用大参数预算的有效性。性能表现:仅调优6.7%的参数,在XSum文本摘要任务中ROUGE-2达21.90(全微调为21.94),WMT2016 en-ro翻译任务BLEU达37.5(全微调为37.3);分类任务中仅调优0.5%参数,MNLI准确率87.4%(全微调87.6%),SST2准确率94.2%(全微调94.6%),整体与全参数微调性能持平。
问题3:现有参数高效调优方法的主要局限性是什么?论文通过哪些实验验证了这一局限性,且如何通过统一框架解决?
答案:现有方法的核心局限性是“性能泛化不足”——在高资源、复杂任务(如文本摘要、机器翻译)中,即使调优10%+参数,性能仍落后于全参数微调。实验验证:在XSum任务中,Adapter(7.2%参数)的ROUGE-2为20.89,Prefix Tuning(3.6%参数)为20.46,均低于全微调的21.94;WMT2016 en-ro翻译中,LoRA(7.2%参数)的BLEU为36.8,低于全微调的37.3。解决方式:通过统一框架拆解现有方法的设计要素,跨方法迁移优势模块——如将Prefix Tuning的“并行插入”迁移至Adapter形成“并行Adapter”,将LoRA的“缩放加法”迁移至Adapter形成“缩放并行Adapter”,最终融合为MAM Adapter,在仅调优6.7%参数的情况下弥补了性能差距。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献72条内容
已为社区贡献72条内容

所有评论(0)