运行MambaIRv2: Attentive State Space Restoration代码时遇到的问题
说No such file or directory: '/data2/guohang/dataset/ARTSR/Set5/LR_bicubic/X2'我一看后面的地是测试数据集的地址,前面的地址不知道啥。我打开了这个配置文件,并把它里面的地址改成了我电脑上数据集相应的地址。模型的当前结构与预训练权重文件中的结构不匹配,导致无法正确加载权重。中,可能指定了一个错误的或不可访问的数据集路径。找到对
测试过程:
Traceback (most recent call last):
File "./basicsr/test.py", line 48, in <module>
test_pipeline(root_path)
File "./basicsr/test.py", line 31, in test_pipeline
test_set = build_dataset(dataset_opt)
File "/data/run01/sczc338/MambaIR/basicsr/data/__init__.py", line 34, in build_dataset
dataset = DATASET_REGISTRY.get(dataset_opt['type'])(dataset_opt)
File "/data/run01/sczc338/MambaIR/basicsr/data/paired_image_dataset.py", line 67, in __init__
self.paths = paired_paths_from_folder([self.lq_folder, self.gt_folder], ['lq', 'gt'], self.filename_tmpl, self.task)
File "/data/run01/sczc338/MambaIR/basicsr/data/data_util.py", line 234, in paired_paths_from_folder
input_paths = list(scandir(input_folder))
File "/data/run01/sczc338/MambaIR/basicsr/utils/misc.py", line 74, in _scandir
for entry in os.scandir(dir_path):
FileNotFoundError: [Errno 2] No such file or directory: '/data2/guohang/dataset/ARTSR/Set5/LR_bicubic/X2'
说No such file or directory: '/data2/guohang/dataset/ARTSR/Set5/LR_bicubic/X2' 我一看后面的地是测试数据集的地址,前面的地址不知道啥。
所以我觉得配置文件options/test/mambairv2/test_MambaIRv2_SR_x2.yml中,可能指定了一个错误的或不可访问的数据集路径。
我打开了这个配置文件,并把它里面的地址改成了我电脑上数据集相应的地址
再次运行
Traceback (most recent call last):
File "basicsr/test.py", line 48, in <module>
test_pipeline(root_path)
File "basicsr/test.py", line 38, in test_pipeline
model = build_model(opt)
File "/data/run01/sczc338/MambaIR/basicsr/models/__init__.py", line 27, in build_model
model = MODEL_REGISTRY.get(opt['model_type'])(opt)
File "/data/run01/sczc338/MambaIR/basicsr/models/sr_model.py", line 30, in __init__
self.load_network(self.net_g, load_path, self.opt['path'].get('strict_load_g', True), param_key)
File "/data/run01/sczc338/MambaIR/basicsr/models/base_model.py", line 304, in load_network
net.load_state_dict(load_net, strict=strict)
File "/data/home/sczc338/.conda/envs/mambair/lib/python3.8/site-packages/torch/nn/modules/module.py", line 2041, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for MambaIRv2:
终于解决掉一个问题了,现在变成了RuntimeError
这个错误表明 PyTorch 在加载模型权重 (state_dict) 时遇到了问题。具体来说,MambaIRv2 模型的当前结构与预训练权重文件中的结构不匹配,导致无法正确加载权重。
那我应该是下载错预训练权重了,改一下
可以看到test_MambaIRv2_SR_x2.yml配置文件中有预训练模型的名称
pretrain_network_g: ./experiments/pretrained_models/mambairv2_classicSR_Base_x2.pth找到对应的预训练模型,下载好后,再次运行
2025-04-23 20:13:01,351 INFO: Loading MambaIRv2 model from ./experiments/pretrained_models/mambairv2_classicSR_Base_x2.pth, with param key: [params].
2025-04-23 20:13:01,546 INFO: Model [MambaIRv2Model] is created.
2025-04-23 20:13:01,547 INFO: Testing Set5...
2025-04-23 20:13:18,982 INFO: Validation Set5
# psnr: 38.6497 Best: 38.6497 @ test_MambaIRv2_SRBase_x2 iter
# ssim: 0.9631 Best: 0.9631 @ test_MambaIRv2_SRBase_x2 iter
2025-04-23 20:13:18,983 INFO: Testing Set14...
2025-04-23 20:13:37,524 INFO: Validation Set14
# psnr: 34.8765 Best: 34.8765 @ test_MambaIRv2_SRBase_x2 iter
# ssim: 0.9275 Best: 0.9275 @ test_MambaIRv2_SRBase_x2 iter
2025-04-23 20:13:37,524 INFO: Testing B100...
2025-04-23 20:15:04,985 INFO: Validation B100
# psnr: 32.6213 Best: 32.6213 @ test_MambaIRv2_SRBase_x2 iter
# ssim: 0.9052 Best: 0.9052 @ test_MambaIRv2_SRBase_x2 iter
2025-04-23 20:15:04,986 INFO: Testing Urban100...
2025-04-23 20:21:26,074 INFO: Validation Urban100
# psnr: 34.4844 Best: 34.4844 @ test_MambaIRv2_SRBase_x2 iter
# ssim: 0.9468 Best: 0.9468 @ test_MambaIRv2_SRBase_x2 iter
2025-04-23 20:21:26,078 INFO: Testing Manga109...
2025-04-23 20:30:25,927 INFO: Validation Manga109
# psnr: 40.4212 Best: 40.4212 @ test_MambaIRv2_SRBase_x2 iter
# ssim: 0.9810 Best: 0.9810 @ test_MambaIRv2_SRBase_x2 iter
测试成功了!
sczc338@g0030:~/run/MambaIR$ python basicsr/test.py -opt options/test/mambairv2/test_MambaIRv2_SR_x2.yml
Disable distributed.
Path already exists. Rename it to /data/run01/sczc338/MambaIR/results/test_MambaIRv2_SRBase_x2_archived_20250423_201247
2025-04-23 20:12:47,313 INFO:
name: test_MambaIRv2_SRBase_x2
model_type: MambaIRv2Model
scale: 2
num_gpu: 8
manual_seed: 10
datasets:[
test_1:[
name: Set5
type: PairedImageDataset
dataroot_gt: ./datasets/SR/Set5/HR
dataroot_lq: ./datasets/SR/Set5/LR_bicubic/X2
filename_tmpl: {}x2
io_backend:[
type: disk
]
phase: test
scale: 2
]
test_2:[
name: Set14
type: PairedImageDataset
dataroot_gt: ./datasets/SR/Set14/HR
dataroot_lq: ./datasets/SR/Set14/LR_bicubic/X2
filename_tmpl: {}x2
io_backend:[
type: disk
]
phase: test
scale: 2
]
test_3:[
name: B100
type: PairedImageDataset
dataroot_gt: ./datasets/SR/B100/HR
dataroot_lq: ./datasets/SR/B100/LR_bicubic/X2
filename_tmpl: {}x2
io_backend:[
type: disk
]
phase: test
scale: 2
]
test_4:[
name: Urban100
type: PairedImageDataset
dataroot_gt: ./datasets/SR/Urban100/HR
dataroot_lq: ./datasets/SR/Urban100/LR_bicubic/X2
filename_tmpl: {}x2
io_backend:[
type: disk
]
phase: test
scale: 2
]
test_5:[
name: Manga109
type: PairedImageDataset
dataroot_gt: ./datasets/SR/Manga109/HR
dataroot_lq: ./datasets/SR/Manga109/LR_bicubic/X2
filename_tmpl: {}_LRBI_x2
io_backend:[
type: disk
]
phase: test
scale: 2
]
]
network_g:[
type: MambaIRv2
upscale: 2
in_chans: 3
img_size: 64
img_range: 1.0
embed_dim: 174
d_state: 16
depths: [6, 6, 6, 6, 6, 6]
num_heads: [6, 6, 6, 6, 6, 6]
window_size: 16
inner_rank: 64
num_tokens: 128
convffn_kernel_size: 5
mlp_ratio: 2.0
upsampler: pixelshuffle
resi_connection: 1conv
]
path:[
pretrain_network_g: ./experiments/pretrained_models/mambairv2_classicSR_Base_x2.pth
strict_load_g: True
results_root: /data/run01/sczc338/MambaIR/results/test_MambaIRv2_SRBase_x2
log: /data/run01/sczc338/MambaIR/results/test_MambaIRv2_SRBase_x2
visualization: /data/run01/sczc338/MambaIR/results/test_MambaIRv2_SRBase_x2/visualization
]
val:[
save_img: False
suffix: None
metrics:[
psnr:[
type: calculate_psnr
crop_border: 2
test_y_channel: True
]
ssim:[
type: calculate_ssim
crop_border: 2
test_y_channel: True
]
]
]
dist: False
rank: 0
world_size: 1
auto_resume: False
is_train: False
2025-04-23 20:12:47,320 INFO: Dataset [PairedImageDataset] - Set5 is built.
2025-04-23 20:12:47,321 INFO: Number of test images in Set5: 5
2025-04-23 20:12:47,328 INFO: Dataset [PairedImageDataset] - Set14 is built.
2025-04-23 20:12:47,328 INFO: Number of test images in Set14: 14
2025-04-23 20:12:47,340 INFO: Dataset [PairedImageDataset] - B100 is built.
2025-04-23 20:12:47,341 INFO: Number of test images in B100: 100
2025-04-23 20:12:47,354 INFO: Dataset [PairedImageDataset] - Urban100 is built.
2025-04-23 20:12:47,354 INFO: Number of test images in Urban100: 100
2025-04-23 20:12:47,367 INFO: Dataset [PairedImageDataset] - Manga109 is built.
2025-04-23 20:12:47,367 INFO: Number of test images in Manga109: 109
/data/home/sczc338/.conda/envs/mambair/lib/python3.8/site-packages/torch/functional.py:504: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at /opt/conda/conda-bld/pytorch_1682343962757/work/aten/src/ATen/native/TensorShape.cpp:3483.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
2025-04-23 20:12:49,887 INFO: Network [MambaIRv2] is created.
2025-04-23 20:12:59,946 INFO: Network: DataParallel - MambaIRv2, with parameters: 22,903,001
2025-04-23 20:12:59,946 INFO: MambaIRv2(
(conv_first): Conv2d(3, 174, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(patch_embed): PatchEmbed(
(norm): LayerNorm((174,), eps=1e-05, elementwise_affine=True)
)
(patch_unembed): PatchUnEmbed()
(layers): ModuleList(
(0-5): 6 x ASSB(
(patch_embed): PatchEmbed()
(patch_unembed): PatchUnEmbed()
(residual_group): BasicBlock(
dim=174, input_resolution=(64, 64), depth=6
(layers): ModuleList(
(0-5): 6 x AttentiveLayer(
(softmax): Softmax(dim=-1)
(lrelu): LeakyReLU(negative_slope=0.01)
(sigmoid): Sigmoid()
(norm1): LayerNorm((174,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((174,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((174,), eps=1e-05, elementwise_affine=True)
(norm4): LayerNorm((174,), eps=1e-05, elementwise_affine=True)
(wqkv): Linear(in_features=174, out_features=522, bias=True)
(win_mhsa): WindowAttention(
dim=174, window_size=(16, 16), num_heads=6, qkv_bias=True
(proj): Linear(in_features=174, out_features=174, bias=True)
(softmax): Softmax(dim=-1)
)
(assm): ASSM(
(selectiveScan): Selective_Scan()
(out_norm): LayerNorm((348,), eps=1e-05, elementwise_affine=True)
(act): SiLU()
(out_proj): Linear(in_features=348, out_features=174, bias=True)
(in_proj): Sequential(
(0): Conv2d(174, 348, kernel_size=(1, 1), stride=(1, 1))
)
(CPE): Sequential(
(0): Conv2d(348, 348, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=348)
)
(embeddingB): Embedding(128, 64)
(route): Sequential(
(0): Linear(in_features=174, out_features=58, bias=True)
(1): GELU(approximate='none')
(2): Linear(in_features=58, out_features=128, bias=True)
(3): LogSoftmax(dim=-1)
)
)
(convffn1): ConvFFN(
(fc1): Linear(in_features=174, out_features=348, bias=True)
(act): GELU(approximate='none')
(dwconv): dwconv(
(depthwise_conv): Sequential(
(0): Conv2d(348, 348, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=348)
(1): GELU(approximate='none')
)
)
(fc2): Linear(in_features=348, out_features=174, bias=True)
)
(convffn2): ConvFFN(
(fc1): Linear(in_features=174, out_features=348, bias=True)
(act): GELU(approximate='none')
(dwconv): dwconv(
(depthwise_conv): Sequential(
(0): Conv2d(348, 348, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), groups=348)
(1): GELU(approximate='none')
)
)
(fc2): Linear(in_features=348, out_features=174, bias=True)
)
(embeddingA): Embedding(64, 16)
)
)
)
(conv): Conv2d(174, 174, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(norm): LayerNorm((174,), eps=1e-05, elementwise_affine=True)
(conv_after_body): Conv2d(174, 174, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(conv_before_upsample): Sequential(
(0): Conv2d(174, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.01, inplace=True)
)
(upsample): Upsample(
(0): Conv2d(64, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): PixelShuffle(upscale_factor=2)
)
(conv_last): Conv2d(64, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
2025-04-23 20:13:01,351 INFO: Loading MambaIRv2 model from ./experiments/pretrained_models/mambairv2_classicSR_Base_x2.pth, with param key: [params].
2025-04-23 20:13:01,546 INFO: Model [MambaIRv2Model] is created.
2025-04-23 20:13:01,547 INFO: Testing Set5...
2025-04-23 20:13:18,982 INFO: Validation Set5
# psnr: 38.6497 Best: 38.6497 @ test_MambaIRv2_SRBase_x2 iter
# ssim: 0.9631 Best: 0.9631 @ test_MambaIRv2_SRBase_x2 iter
2025-04-23 20:13:18,983 INFO: Testing Set14...
2025-04-23 20:13:37,524 INFO: Validation Set14
# psnr: 34.8765 Best: 34.8765 @ test_MambaIRv2_SRBase_x2 iter
# ssim: 0.9275 Best: 0.9275 @ test_MambaIRv2_SRBase_x2 iter
2025-04-23 20:13:37,524 INFO: Testing B100...
2025-04-23 20:15:04,985 INFO: Validation B100
# psnr: 32.6213 Best: 32.6213 @ test_MambaIRv2_SRBase_x2 iter
# ssim: 0.9052 Best: 0.9052 @ test_MambaIRv2_SRBase_x2 iter
2025-04-23 20:15:04,986 INFO: Testing Urban100...
2025-04-23 20:21:26,074 INFO: Validation Urban100
# psnr: 34.4844 Best: 34.4844 @ test_MambaIRv2_SRBase_x2 iter
# ssim: 0.9468 Best: 0.9468 @ test_MambaIRv2_SRBase_x2 iter
2025-04-23 20:21:26,078 INFO: Testing Manga109...
2025-04-23 20:30:25,927 INFO: Validation Manga109
# psnr: 40.4212 Best: 40.4212 @ test_MambaIRv2_SRBase_x2 iter
# ssim: 0.9810 Best: 0.9810 @ test_MambaIRv2_SRBase_x2 iter
训练过程:
输入命令:
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 basicsr/train.py -opt options/train/mambairv2/train_MambaIRv2_SR_x2.yml --launcher pytorch-
-m torch.distributed.launch:调用 PyTorch 的分布式启动模块 -
--nproc_per_node=8:指定当前节点使用 8 个 GPU 进程 -
--master_port=1234:设置主节点的通信端口为 1234(用于多进程通信) -
basicsr/train.py:要运行的主训练脚本(来自 BasicSR 框架) -
-opt options/train/mambairv2/train_MambaIRv2_SR_x2.yml:指定训练配置文件(YAML 格式,包含模型架构、训练参数等) -
--launcher pytorch:明确使用 PyTorch 作为分布式启动器
也是报错啦,先改地址问题
想起来没下载训练数据集呢,先弄它
omg!21G,我觉得可以先不用训了。
数据集的下载:
1,可以先下到本地(zip)再把zip文件上传到超算上,如果在本地解压,上传解压过的文件的话由于文件过大很容易失败。
2,可以直接在超算上下载,不过需要联网,很容易因为网络不稳定而下载失败。
接下来修改train_MambaIRv2_SR_x2.yml配置文件中的地址信息,然后运行以下命令:
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 basicsr/train.py -opt options/train/mambairv2/train_MambaIRv2_SR_x2.yml --launcher pytorch1. python -m torch.distributed.launch
这是 PyTorch 的分布式训练启动器:
-
-m表示运行一个模块 -
torch.distributed.launch是 PyTorch 提供的用于启动分布式训练的脚本
2. --nproc_per_node=8
分布式训练参数:
-
指定每个节点(机器)上使用 8 个 GPU 进程
-
意味着你有一台配备至少 8 个 GPU 的机器
-
训练将在 8 个 GPU 上并行进行
3. --master_port=1234
分布式训练通信参数:
-
设置主节点的端口号为 1234
-
在分布式训练中,各进程需要通过这个端口进行通信
-
如果 1234 被占用,可以改为其他未被使用的端口
4. basicsr/train.py
这是要运行的主训练脚本:
-
basicsr是 BasicSR 框架的代码目录 -
train.py是训练入口脚本
5. -opt options/train/mambairv2/train_MambaIRv2_SR_x2.yml
训练配置文件:
-
-opt表示指定配置文件选项 -
options/train/mambairv2/train_MambaIRv2_SR_x2.yml是 YAML 格式的配置文件路径 -
这个文件包含了模型架构、训练参数、数据集路径等配置
6. --launcher pytorch
指定启动器类型:
-
明确告诉训练脚本使用 PyTorch 的分布式启动器
-
这与开头的
torch.distributed.launch相对应
即可开始训练过程。
报出以下错误:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 22.00 MiB (GPU 0; 23.64 GiB total capacity; 22.84 GiB already allocated; 9.69 MiB free; 23.09 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
说明GPU显存不足
1,尝试清理缓存,手动释放PyTorch缓存(有时缓存占用过多)
没成功,但我觉得还是可以再试一下的,因为22.00 MiB与22.84 GiB确实只差一点点,差一点就够了。
import torch
torch.cuda.empty_cache()然后检查 GPU 内存情况:
print(torch.cuda.memory_summary())结合训练命令的话,可以这样修改命令,在启动训练前先清理缓存:
python -c "import torch; torch.cuda.empty_cache()" && \
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 basicsr/train.py -opt options/train/mambairv2/train_MambaIRv2_SR_x2.yml --launcher pytorch2,增加卡数,尝试跨节点(跨机器,也就是使用多个机器)提交
This DataLoader will create 256 worker processes in total. Our suggested max number of worker in current system is 64, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary 
Traceback (most recent call last):
File "train.py", line 225, in <module>
train_pipeline(root_path)
File "train.py", line 101, in train_pipeline
opt, args = parse_options(root_path, is_train=True)
File "/data/run01/sczc338/MambaIR/basicsr/utils/options.py", line 107, in parse_options
init_dist(args.launcher)
File "/data/run01/sczc338/MambaIR/basicsr/utils/dist_util.py", line 14, in init_dist
_init_dist_pytorch(backend, **kwargs)
File "/data/run01/sczc338/MambaIR/basicsr/utils/dist_util.py", line 22, in _init_dist_pytorch
rank = int(os.environ['RANK'])
File "/data/home/sczc338/.conda/envs/mambair/lib/python3.8/os.py", line 675, in __getitem__
raise KeyError(key) from None
KeyError: 'RANK'分布式环境变量未设置错误
代码调用了 init_dist(args.launcher),但可能没有通过分布式启动工具(如 torch.distributed.launch 或 torchrun)启动脚本,导致 RANK 环境变量未被设置。
这是因为我在编写run.sh文件时,最后一行是python train.py而不是python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 basicsr/train.py -opt options/train/mambairv2/train_MambaIRv2_SR_x2.yml --launcher pytorch,修改过来之后就没有这个错误了。
但是这个方法仍没有解决显存不够的问题
3, 减少工作线程数
减小配置文件train_MambaIRv2_SR_x2.yml中的num_worker_per_gpu
我是由32减到16了,但仍然报错,原因都没变
4, 减少批次大小
减小配置文件train_MambaIRv2_SR_x2.yml中的batch_size_per_gpu
我是由4减到1了。
我滴老天爷啊终于解决这个问题了,现在在运行中,下个问题见!
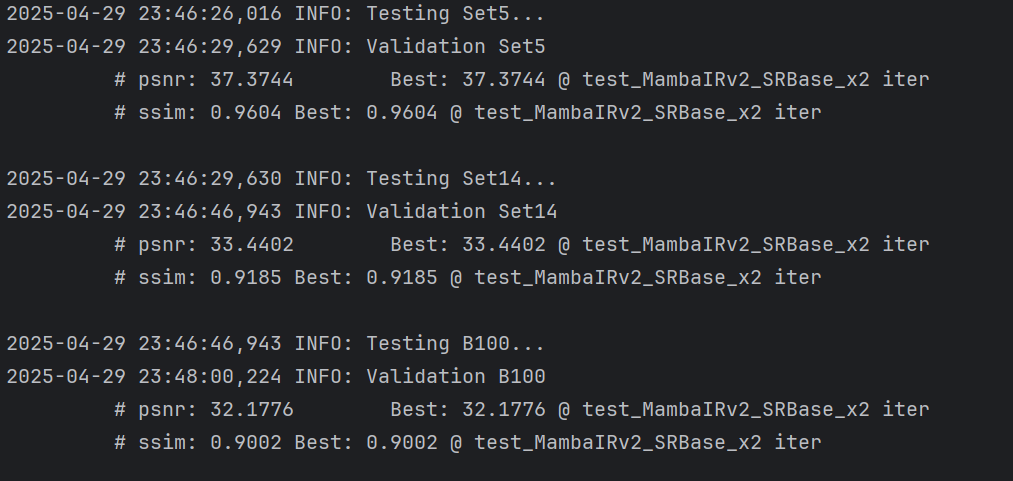
hh!没问题啦!!!!跑出来了!!!!!万岁!!第一次跑通一个项目,我真的要哭了,纪念一下2025/4/29 23:56

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)