Mem0深度解析
摘要:Mem0是一种创新的AI记忆架构,解决了大语言模型在长期交互中的信息遗忘问题。它采用增量记忆机制,通过动态提取、整合和检索关键信息,显著提升了对话连贯性。Mem0ᵍ版本还引入图结构存储,增强跨会话关联处理能力。测试数据显示,其准确率比OpenAI方案高26%,延迟降低91%,节省90%令牌消耗。系统支持多级记忆管理,结合向量和图数据库实现高效检索,同时保障数据隐私。尽管存在自托管复杂等局限,
如今的人工智能系统在长时间交互过程中会遗忘关键信息,导致上下文断裂,进而损害用户信任。单纯扩大大语言模型的上下文窗口只能暂缓这一问题 —— 模型的运行速度会变慢、成本会增加,而且仍会忽略关键细节。
Mem0 采用可扩展的增量记忆架构直面这一难题,该架构能够从对话中动态提取、整合并检索重要信息。其增强版本 Mem0ᵍ 还额外搭载了基于图结构的存储模块,可捕捉更丰富的跨会话关联信息。
在 LOCOMO 基准测试中,Mem0 持续优于六种主流记忆方案,具体表现如下:
- 相较于 OpenAI 的记忆方案,响应准确率提升 26%
- 相较于全上下文处理方法,延迟降低 91%
- 节省 90% 的令牌消耗,让规模化记忆应用兼具实用性与经济性
通过实现高效易用的规模化持久化结构化记忆功能,Mem0 为人工智能智能体的发展铺平了道路,这类智能体不再局限于被动响应,而是能够随着时间推移,真正做到记忆信息、适应变化并协同工作。
核心概念
Mem0 的核心理念体现在以下几个方面:
- 记忆处理:利用大语言模型(LLM)自动从对话中提取关键信息,并将其结构化存储,确保上下文的完整性和可追溯性。
- 记忆管理:系统能够持续更新和维护存储的记忆内容,自动检测并解决信息冲突,保证记忆的准确性和一致性。
- 双重存储架构:创新性地结合了向量数据库(用于高效语义检索)和图数据库(用于实体关系追踪),实现了记忆的多维度管理。
- 智能检索系统:通过语义搜索与图查询相结合,能够基于记忆的重要性、时效性等多维度条件,精准检索出最相关的历史信息。
- 模型上下文协议(MCP):提供标准化的协议接口,支持不同 AI 应用间的记忆共享与互通,打破信息孤岛。
- 本地化处理:所有数据处理与存储均可在本地完成,极大保障了用户隐私和数据安全,用户对数据拥有完全控制权.
Mem0 支持多级记忆架构,包括:
- 用户级记忆:跨会话持久化保存用户偏好和历史行为
- 会话级记忆:记录当前交互的上下文信息
- 智能体级记忆:存储 AI 系统自身的知识和学习成果
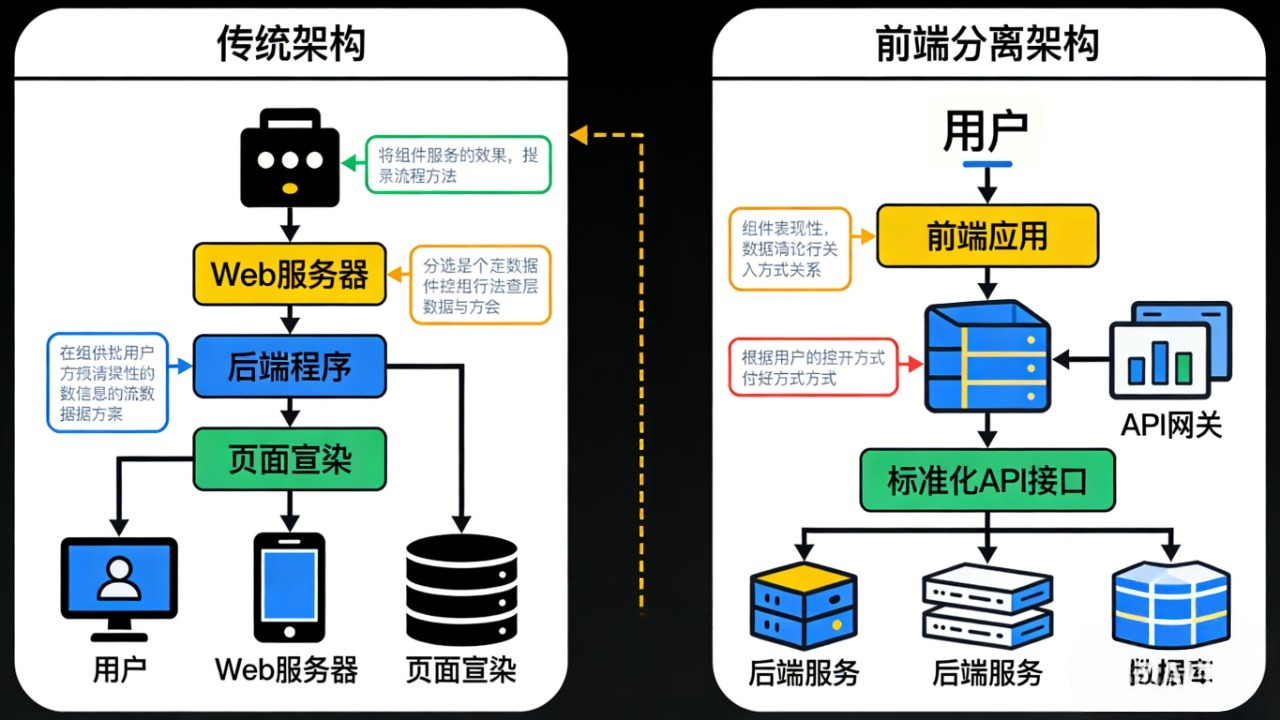
基础架构
Mem0 的记忆层架构巧妙结合了大语言模型(LLM)与向量存储技术。LLM 负责从用户与智能体的对话中自动提取关键信息,而向量存储则将这些信息转化为高维向量,实现高效的语义检索。通过这种架构,AI 智能体能够将历史交互与当前上下文有机结合,生成更加相关和个性化的响应。
记忆层的核心工作流程包括:
- 信息提取:LLM 对对话内容进行深度分析,自动识别并提取出具有长期价值的关键信息点。
- 向量化:将提取出的信息通过嵌入模型转化为向量表示,便于后续的高效检索。
- 存储:将向量化后的记忆单元存储到向量数据库中,支持大规模、低延迟的语义检索。
- 检索:根据当前用户查询,系统在向量空间中检索出最相关的历史记忆。
- 整合:将检索到的记忆与当前对话上下文进行整合,辅助智能体生成更具针对性和连贯性的响应。
这种架构设计,使 Mem0 能够在保证高效率的同时,提供精准且可扩展的记忆检索服务。
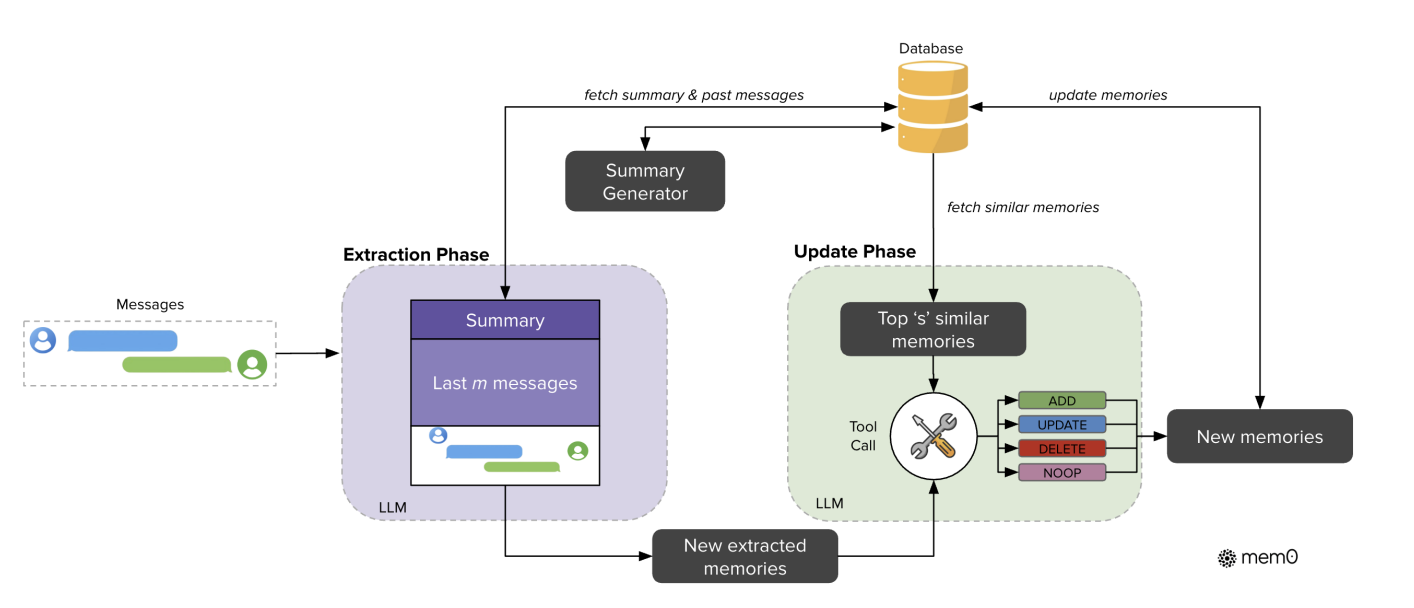
核心流程
架构包含两个阶段:提取阶段与更新阶段
更新记忆流程
更新记忆的操作流程如下图所示:
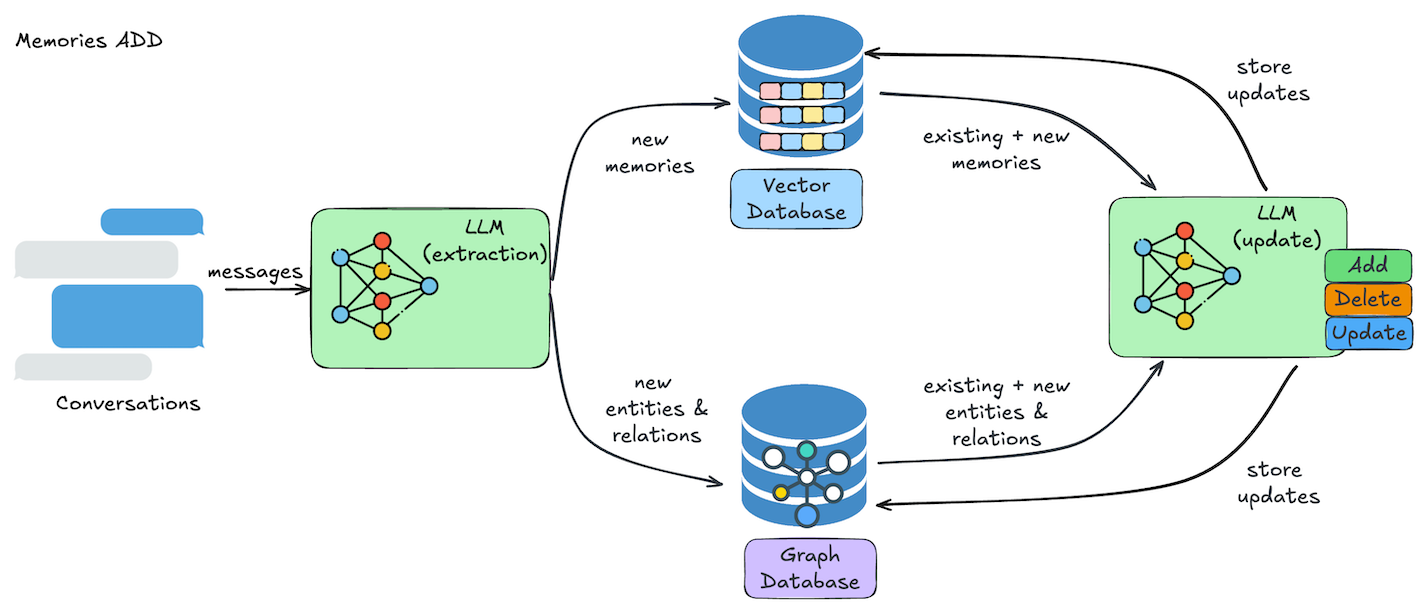
- 信息提取:LLM 从对话中自动提取出相关记忆,识别重要实体及其关系。
- 冲突解决:系统会将新提取的信息与现有记忆进行比对,自动识别并解决潜在的矛盾或重复内容,确保记忆的准确性。
- 记忆存储:最终的记忆内容会被存储到向量数据库中,同时相关的实体关系会同步到图数据库中。每次用户与智能体的互动,都会不断丰富和完善记忆库。
大语言模型会根据候选事实与已有记忆的语义关联,自主判定执行以下四种操作之一:
- 新增(ADD):当不存在语义等价的记忆时,创建新的记忆条目;
- 更新(UPDATE):利用候选事实中的补充信息,完善已有记忆;
- 删除(DELETE):当新信息与已有记忆存在冲突时,移除矛盾的记忆;
- 无操作(NOOP):当候选事实无需对知识库进行任何修改时,执行空操作。
提取记忆流程
记忆提取的操作流程如下图所示:
系统采用两个互补的信息来源:
- 从数据库调取的对话摘要 S,该摘要涵盖了整个对话历史的语义内容;
- 来自对话历史的近期消息序列 {mt−m,mt−m+1,...,mt−2},其中 m 是控制近期窗口大小的超参数。
异步摘要生成模块,用于定期更新对话摘要。该模块独立于主处理流水线运行,确保记忆提取过程始终能利用最新的上下文信息,且不会产生处理延迟
这两类上下文信息与新消息对相结合,构成提取函数 ϕ 的完整提示词 P=(S,{mt−m,...,mt−2},mt−1,mt),该提取函数由大语言模型(LLM)实现。随后,函数 ϕ(P) 从这段新的对话交互中提取出一组关键记忆 Ω={ω1,ω2,...,ωn},同时兼顾对话的整体上下文。
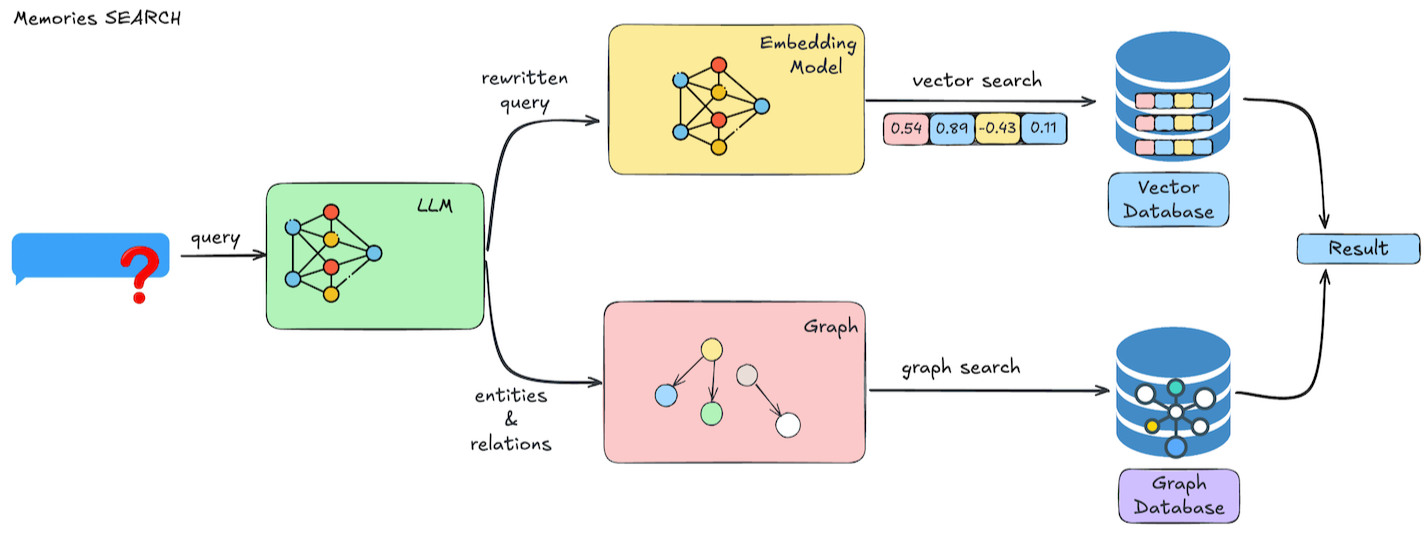
- 查询处理:LLM 首先对用户的查询进行理解和优化,系统自动生成针对性的检索过滤条件。
- 向量搜索:系统在向量数据库中执行高效的语义搜索,根据与查询的相关性对结果进行排序,并可按用户、代理、元数据等多维度进行过滤。
- 结果处理:系统将检索到的结果进行合并和排序,最终返回带有相关性分数、元数据和时间戳的记忆内容,供智能体进一步使用。
Mem0g图记忆
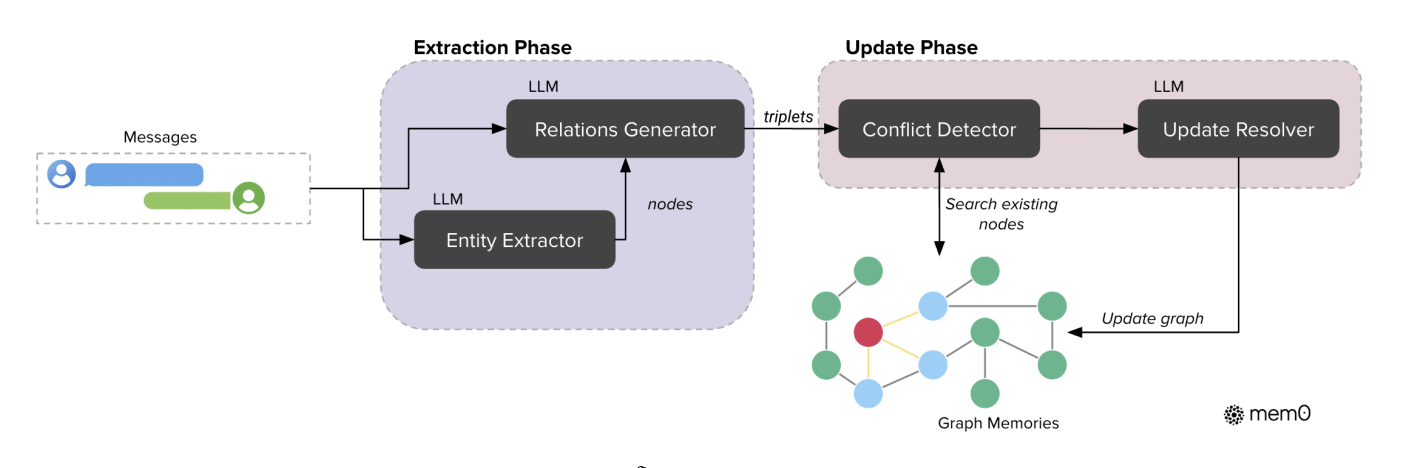
Mem0g 处理流程采用一种基于图谱的记忆方法,能够高效地从自然语言交互中捕捉、存储并检索上下文信息(Zhang 等人,2022)。在该框架中,记忆被表示为一个有向标记图 \(G=(V,E,L)\),其中:
- 节点 V 代表实体(例如:爱丽丝、旧金山)
- 边 E 代表实体间的关系(例如:居住于)
- 标记 L 用于为节点赋予语义类型(例如:爱丽丝 - 人物、旧金山 - 城市)
第一阶段,实体提取模块对输入文本进行处理,识别出一组实体及其对应的类型。
第二阶段,关系生成组件挖掘这些实体之间的有效关联,构建一组关系三元组,以此呈现信息的语义结构。
Mem0g 的记忆检索功能采用双策略模式,以实现最优的信息访问效率。
第一种是实体中心检索法:系统首先识别查询语句中的核心实体,再通过语义相似度匹配,在知识图谱中定位对应的节点;随后系统性地遍历这些锚点节点的入边与出边,构建一个涵盖相关上下文信息的完整子图。
第二种是语义三元组检索法,作为前一种方法的补充,该方法从更全局的视角出发,将整个查询语句编码为一个稠密嵌入向量;再将该查询向量与知识图谱中所有关系三元组的文本编码进行匹配,计算查询与每个三元组之间的细粒度相似度得分;最终仅返回相似度超过可配置阈值的结果,并按相似度从高到低排序。这种双检索机制使 Mem0g 能够同等高效地处理两类查询需求:一类是针对特定实体的精准问题,另一类是范围更广的概念性问题。
| 对比维度 | Mem0g 流程图核心特征 | 待对比架构(如 Mem0)流程图核心特征 | 差异本质 |
|---|---|---|---|
| 核心流程框架 | 分为 提取→存储更新→双策略检索 三阶段,全程围绕知识图谱(实体 - 关系三元组) 展开 | 分为 提取→更新(ADD/UPDATE/DELETE/NOOP)→记忆调用 三阶段,围绕扁平记忆集合 展开 | 数据组织形式差异:图谱结构化 vs 记忆条目扁平化 |
| 关键模块设计 | 提取层拆分为 实体提取 + 关系生成 双模块;更新层含 冲突检测 + 标记失效 子流程;检索层并行 实体中心 + 语义三元组 双路径 | 提取层是 单模块 LLM 提取关键记忆;更新层依赖 相似记忆检索 + LLM 工具调用 决策;检索层未单独拆分子流程 | 模块复杂度差异:Mem0g 模块更细分,依赖图谱操作;对比架构更简洁,依赖 LLM 推理 |
| 技术特性可视化 | 流程图中会体现 Neo4j 图数据库 标识、实体嵌入向量计算 节点、时序标记(无效关系) 符号 | 流程图中会体现 向量数据库 标识、对话摘要 + 近期消息 双上下文输入、4 类更新操作 分支 | 技术依赖差异:图谱存储 vs 向量存储;时序标记 vs 直接增删 |
| 流程闭环逻辑 | 新增信息→实体关系提取→图谱更新(不删旧数据)→双路径检索→结果融合,闭环围绕图谱的完整性和时序性 | 新消息对→关键记忆提取→与旧记忆比对→更新记忆集合→检索记忆,闭环围绕记忆的一致性和无冗余 | 闭环目标差异:图谱扩展 vs 记忆提纯 |
Mem0优缺点
优点
- 记忆管理智能高效
- 动态优化记忆内容:能从对话中提取关键事实并精炼归纳,还可通过冲突检测机制处理新旧信息,比如自动判断是否新增、更新或删除记忆,避免冗余和矛盾内容,相比传统 RAG 方案减少了噪声干扰。且 Mem0 支持向量存储与图存储组合架构,搭配多级记忆体系,既能通过向量库做语义检索,又能靠图数据库处理实体关系,还能区分用户、会话、代理级记忆,适配不同记忆需求。
- 推理表现出色:在 LOCOMO 长记忆测试集中,其处理单跳和多跳问题时的 J 值(质量评分)显著优于多数同类方案,准确率比 OpenAI Memory 高 26%;升级后的 Mem0g 在时序推理任务中 J 值达 58.13%,处理时间、人物等复杂关系类问题时表现突出。
- 大幅降低使用成本:通过智能过滤数据,仅向大模型传输关键信息,据称可减少高达 80% 的大模型成本,且平均每对话仅需 7k Token,远低于同类的 Zep 的 600k Token;同时总延迟中位数仅 1.44 秒,较全上下文方案延迟降低 91%,兼顾低成本与低延迟。
- 集成与使用门槛低:提供简洁的核心接口,仅需几行代码就能集成到现有 LLM 应用,还兼容 LangGraph 等主流智能体框架。其跨平台特性可保障不同设备上的使用一致性,同时支持多模态记忆,能从图像与文本中提取关键信息,适配发票解析、截图信息提取等多样场景。
- 部署方式灵活:既提供省心的托管服务,包含自动更新和专属支持,无需用户投入大量维护精力;也支持开源版本的自托管,满足企业对数据私有化的需求,适配不同规模的部署场景。
缺点
- 自托管部署难度大:虽然托管服务便捷,但开源版本的自托管需要大量部署和维护工作。若要搭配本地部署的大模型使用,还可能出现兼容性问题,部分用户反馈切换到自定义部署的大模型时,需修改框架源码才能正常运行。
- 性能存在不稳定场景:在处理矛盾信息更新时表现波动较大,比如向系统输入与既有记忆冲突的内容时,有时会出现同时保留两个矛盾结果的情况。且开启记忆图谱功能后,处理简单对话也可能需要近 10 秒,延迟明显增加,难以适配实时聊天这类对响应速度要求高的场景。
- 外部依赖与存储支持受限:Mem0 运行依赖多个外部库,这会给部分开发者的集成工作增加复杂度。同时目前仅支持 Neo4j 作为图存储提供商,选择范围窄,对习惯使用其他图数据库的用户来说,灵活性不足。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)