【视频异常检测】Knowledge-Guided Textual Reasoning for Explainable Video Anomaly Detection via LLMs
本文提出了一种基于文本的可解释视频异常检测框架TbVAD,通过完全在文本域内完成异常检测与解释。该框架利用视觉-语言模型生成细粒度视频描述,构建包含动作、物体、上下文和环境四个维度的结构化知识,并通过槽位级重要性分析实现可解释推理。实验表明,在UCF-Crime和XD-Violence数据集上,TbVAD不仅提高了检测准确性,还能生成易于理解的异常解释。该方法突破了传统视觉特征的限制,为低分辨率监

原文链接:https://arxiv.org/abs/2511.07429
abstract
摘要翻译
我们提出了基于文本的可解释视频异常检测(TbVAD)——一种面向弱监督视频异常检测(WSVAD)的语言驱动框架,其异常检测与解释过程完全在文本域内完成。与依赖显式视觉特征的传统WSVAD模型不同,TbVAD通过语言表征视频语义,实现了可解释且基于知识的推理。该框架的运行分为三个阶段:(1)利用视觉-语言模型(VLM)将视频内容转换为细粒度描述文本;(2)通过将描述文本组织到动作、物体、上下文和环境四个语义槽中,构建结构化知识;(3)生成基于槽位的解释,揭示哪些语义因素对异常判定的贡献最大。我们在UCF-Crime和XD-Violence两个公开基准数据集上对TbVAD进行了评估,结果表明,文本知识推理能够为现实世界的监控场景提供可解释且可靠的异常检测。
1. .Introduction
视频异常检测(VAD)是计算机视觉领域的一项关键任务,尤其在监控和公共安全应用中具有重要意义[1, 21]。尽管近年来深度学习方法取得了显著进展,但大多数现有方法仍严重依赖从原始帧或预训练网络中提取的视觉特征。然而,在实际监控场景中,闭路电视(CCTV) footage 往往分辨率较低,视觉输入通常难以捕捉到细微却有意义的线索,例如物体的微小移动、异常互动或环境的细微变化。
除原始视觉信号外,语言为视觉场景提供了一种极具价值但尚未被充分探索的表征形式[6, 9, 31, 35]。语言描述能够提供简洁、可解释且具有泛化性的语义信息,与人类的推理方式更为契合。我们认为,当与结构化推理相结合时,文本表征不仅可以作为异常检测的替代模态,还能成为可解释性推理的基础,阐明某一事件被判定为异常的原因。
为此,我们提出了基于文本的可解释视频异常检测(TbVAD)——一种完全在文本域内完成异常检测与解释的框架。TbVAD 整合了三个互补组件:(1)由视觉-语言模型(VLM)生成的细粒度描述文本,用于刻画局部视觉事件;(2)通过基于大型语言模型(LLM)的多维度总结构建的结构化知识,涵盖动作、物体、上下文和环境四个语义槽,捕捉正常与异常行为模式;(3)基于槽位的解释生成模块,根据影响最大的语义因素解读异常判定结果。这些组件共同构成了一个全面的推理流程,其中领域级先验知识与实例特定描述共同助力可解释性决策的实现。
在推理阶段,TbVAD 计算槽位级重要性分数,以确定哪些语义维度对异常预测的影响最为显著。每个描述文本都会与对应的结构化知识进行对齐,并据此检索最相关的文本证据。通过将这些证据与细粒度描述文本相结合,TbVAD 利用轻量级语言模型为检测到的异常生成简洁、易于人类理解的解释。这种一体化设计弥合了定量检测与定性解读之间的鸿沟,实现了具有可解释性且基于知识的视频异常检测。
最后,在 UCF-Crime 和 XD-Violence 数据集上进行的大量实验表明,将结构化文本知识与细粒度描述相结合,显著提升了检测的准确性和可解释性,验证了 TbVAD 基于文本推理方法的有效性。
3. 方法
本文提出的框架包含三个核心组件:(1)用于构建多维度文本先验知识的结构化知识分支;(2)用于编码细粒度描述文本的文本理解分支;(3)用于异常检测中基于知识的可解释性推理分支。
3.1 结构化知识分支
3.1.1 概述与动机
为利用文本语义进行异常检测,该框架通过将视觉输入转换为丰富的基于语言的表征来构建结构化知识。这一过程始于从采样帧中提取细粒度描述文本,随后通过大型语言模型(LLM)[18]进行多视角总结。
3.1.2 描述文本生成的视觉-语言模型基准测试
考虑到监控视频分辨率低、场景杂乱的特点,选择高效的视觉-语言模型(VLM)生成描述文本至关重要。我们在多种闭路电视(CCTV)样本上对五种代表性VLM(BLIP2[12]、GIT[24]、LLaVA[15]、MiniGPT4[39]和Molmo[8])进行了实证评估。如图1所示,Molmo持续生成了最详尽且贴合上下文的描述文本,其性能优于其他常生成简短或通用表述(如“商店内出现一名穿连帽衫的男子”)的模型。
为量化这一观察结果,表1报告了各模型的平均描述文本长度和TF-IDF分数。Molmo生成的描述文本最长且语义最丰富,能有效捕捉物体细节、场景上下文和动作线索——这些都是异常推理的关键特征。
| 模型 | 可训练参数数量 | 平均长度 | 词频-逆文档频率(TF-IDF) |
|---|---|---|---|
| GIT | 10亿 | 9.73 | 1.9621 |
| BLIP2 | 27亿 | 10.52 | 1.9829 |
| MiniGPT-4 | 130亿 | 49.09 | 3.2602 |
| LLaVA | 70亿 | 91.28 | 1.9526 |
| Molmo | 70亿 | 2602.86 | 4.2929 |
表1. 不同模型在UCF数据集上的平均描述文本长度和信息含量(TF-IDF)对比。所有描述文本均基于同一视频集生成,以确保公平比较。
尽管Molmo展现出卓越的描述文本生成能力,但由于UCF-Crime数据集采用逐帧评估协议,需要为每帧生成描述文本,大规模推理的计算成本极高,因此我们未将其应用于该数据集。相反,我们利用Molmo构建推理阶段所需的结构化知识表征,确保其语义理解能力仍能为整个框架提供支持。对于在未剪辑片段上采用视频级标签的XD-Violence数据集,Molmo被选为生成细粒度文本描述的主要描述文本生成器。
3.1.3 基于大型语言模型的多维度总结
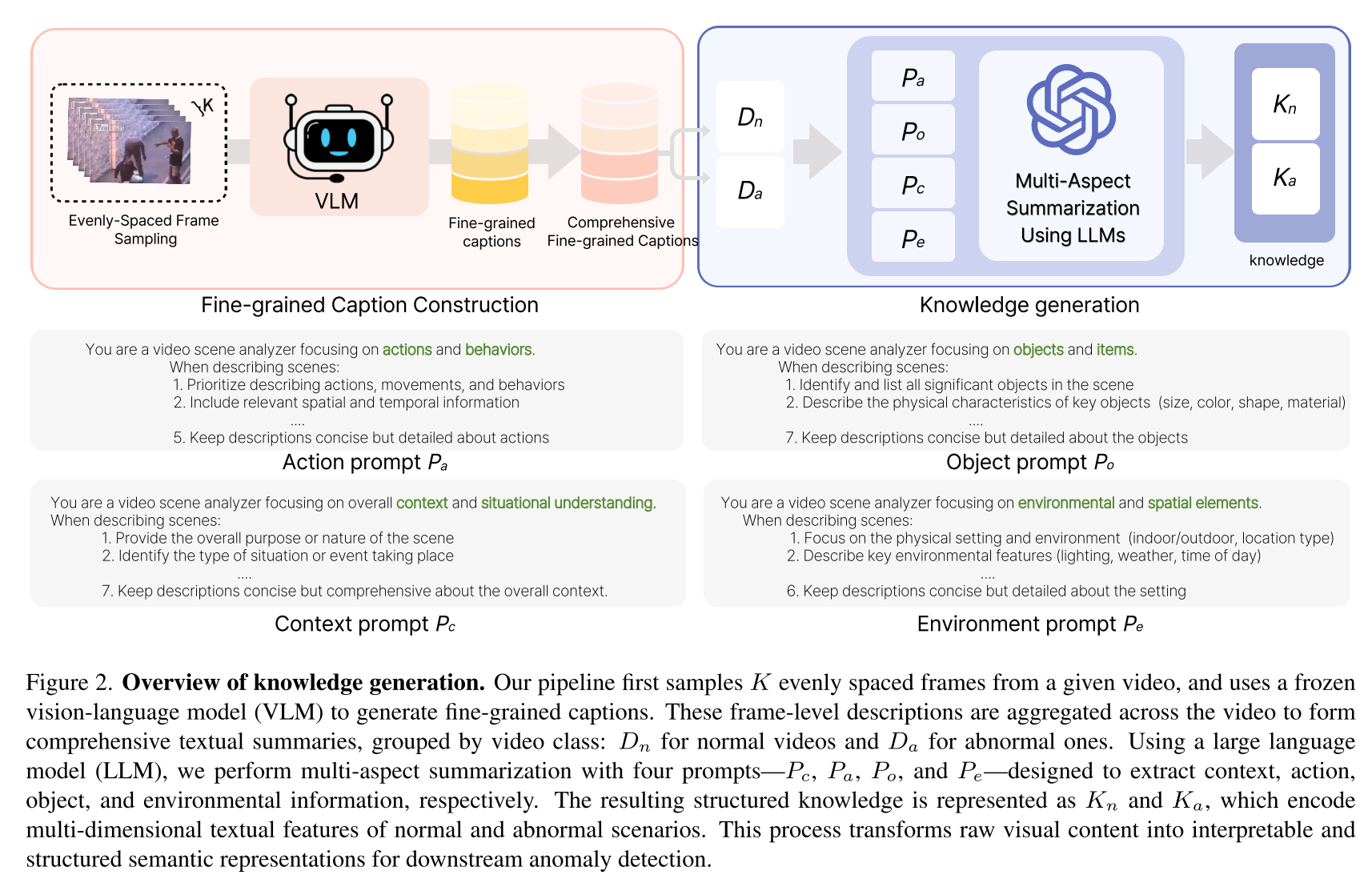
如图2所示,我们通过大型语言模型(LLM)[19]的多维度总结,从细粒度描述文本(即跨多帧聚合形成的综合描述)中构建结构化知识。对于每个输入视频,我们采样K帧等间隔帧,并使用冻结的视觉-语言模型(VLM)[8]生成细粒度描述文本。生成的描述文本按视频标签分组,正常样本组记为 D n D_{n} Dn,异常样本组记为 D a D_{a} Da。
为提取结构化语义,我们设计了四个针对场景不同维度的定制化提示词:上下文 ( P c (P_{c} (Pc)、动作( P a P_{a} Pa)、物体( P o P_{o} Po)和环境( P e P_{e} Pe),如图2所示。每个提示词均应用于正常和异常描述文本组。设 V = { n , a } V=\{n,a\} V={n,a}代表正常和异常标签集合,对于每个维度 K ∈ { C , A , O , E } K \in \{C,A,O,E\} K∈{C,A,O,E},可得到总结结果 K v K_{v} Kv(其中 v ∈ V v \in V v∈V)。这些元素构成了每个类别的结构化知识: K v = { C v , A v , O v , E v } K_{v}=\{C_{v},A_{v},O_{v},E_{v}\} Kv={Cv,Av,Ov,Ev} ( v ∈ V (v \in V (v∈V)。完整的表征定义为 K = { K n , K a } K=\{K_{n},K_{a}\} K={Kn,Ka}。这种结构化表征捕捉了正常和异常事件的丰富语义先验知识,使模型即使在视觉信号模糊或嘈杂的情况下,也能基于文本识别异常。
3.1.4 知识编码
该过程接收由视频的四个文本组件构成的结构化表征 K = { C , A , O , E } K=\{C,A,O,E\} K={C,A,O,E}。这些组件被拼接后,通过冻结的语言模型编码为单个序列,生成令牌嵌入 S V ′ = { s 1 , s 2 , . . . , s L } S_{V}'=\{s_{1},s_{2},...,s_{L}\} SV′={s1,s2,...,sL}。最终的知识表征通过将这些嵌入的均值投影到共享潜在空间获得: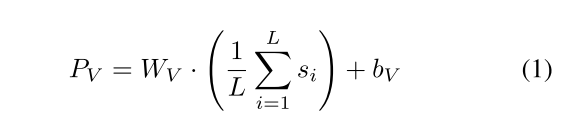
3.2 文本理解分支
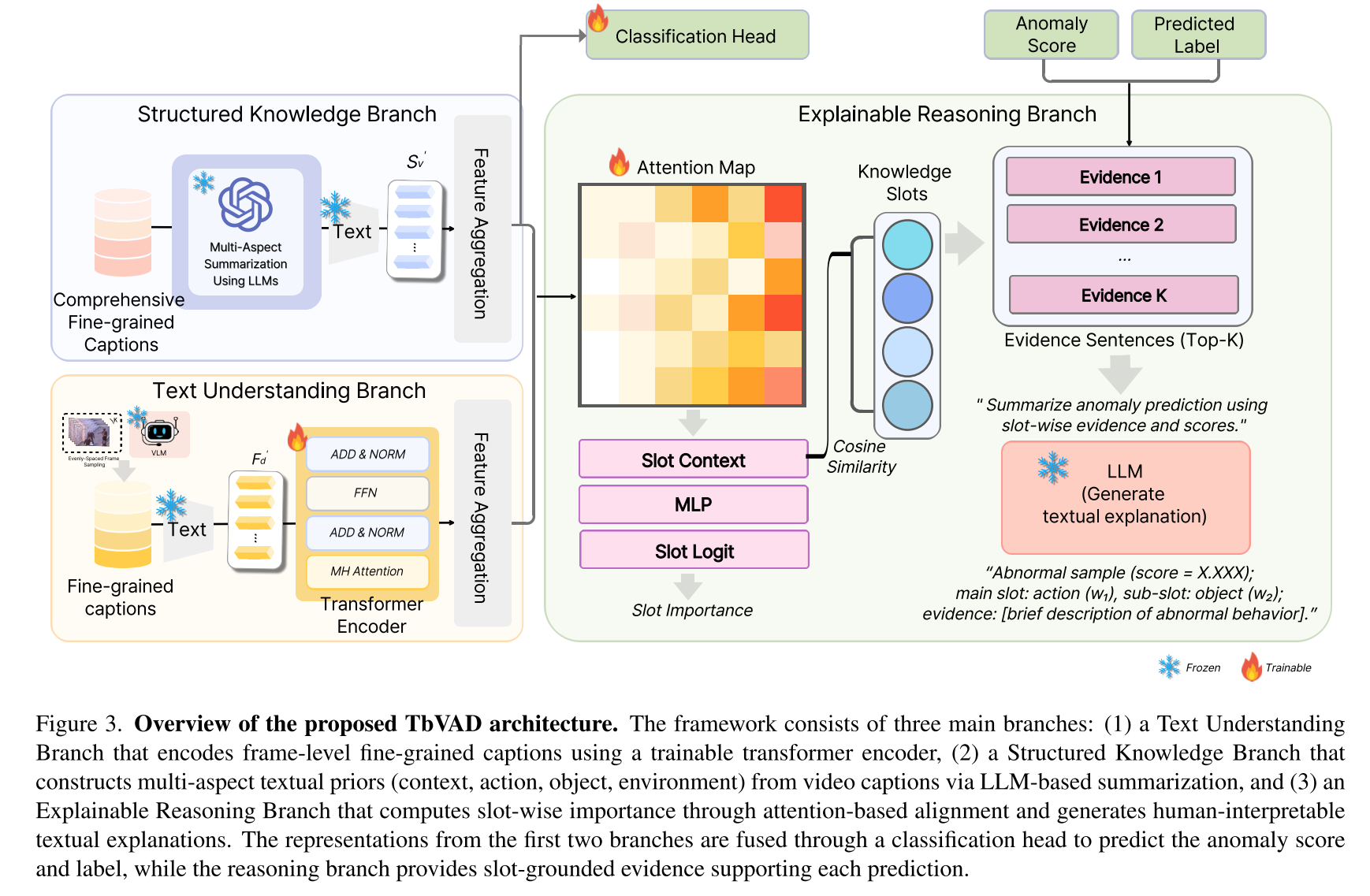
3.2.1 细粒度描述文本编码
对于给定视频,我们采样K帧等间隔帧,并使用冻结的视觉-语言模型生成对应的描述文本 F d ′ = { c 1 , c 2 , . . . , c K } F_{d}'=\{c_{1},c_{2},...,c_{K}\} Fd′={c1,c2,...,cK}。这些描述文本经过令牌化处理后嵌入为向量 X d = { x 1 , x 2 , . . . , x K } X_{d}=\{x_{1},x_{2},...,x_{K}\} Xd={x1,x2,...,xK},作为Transformer编码器的初始输入,即 Z ( 0 ) = X d Z^{(0)}=X_{d} Z(0)=Xd。
该序列随后通过L层Transformer编码器堆叠处理:
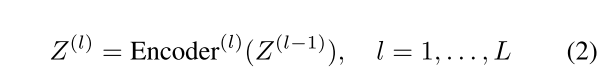
最终输出 H d = Z ( L ) = { h 1 , h 2 , . . . , h K } H_{d}=Z^{(L)}=\{h_{1},h_{2},...,h_{K}\} Hd=Z(L)={h1,h2,...,hK}经平均池化聚合后投影到潜在空间:
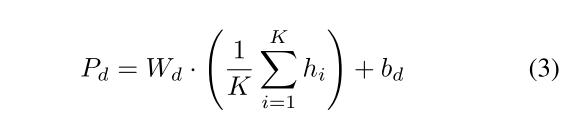
3.2.2 特征聚合与分类
两个投影向量 P d P_{d} Pd和 P V P_{V} PV通过特征融合模块拼接后,输入分类头生成异常概率:
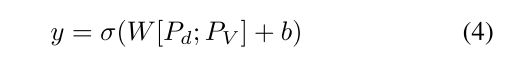
其中,y表示预测的异常概率。该架构有效结合了帧级细粒度语义与高层上下文知识,实现了稳健且可解释的视频异常检测。
3.3 可解释推理分支
3.3.1 槽位级重要性估计
给定描述文本特征矩阵 H d ∈ R T × d H_{d} \in \mathbb{R}^{T \times d} Hd∈RT×d和知识槽位原型 K v ∈ R S × d K_{v} \in \mathbb{R}^{S \times d} Kv∈RS×d ( S = 4 (S=4 (S=4,对应上下文、动作、物体和环境),我们首先计算跨注意力图,将每个槽位与描述文本中最相关的令牌对齐:
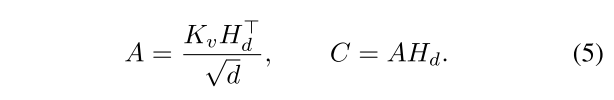
其中, A ∈ R S × T A \in \mathbb{R}^{S \times T} A∈RS×T表示槽位与令牌之间的注意力对齐关系, C ∈ R S × d C \in \mathbb{R}^{S \times d} C∈RS×d表示通过令牌嵌入的加权组合得到的槽位特定上下文向量。
随后,通过轻量级投影网络融合每个槽位的上下文向量和原型嵌入,估计其重要性:
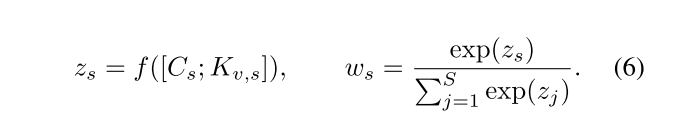
其中, f ( ⋅ ) f(\cdot) f(⋅)表示双层前馈变换, w s w_{s} ws表示槽位s的归一化重要性。 w s w_{s} ws值越高,表明该槽位对异常判定的贡献越大。
3.3.2 基于知识的证据检索
对于每个槽位,通过计算描述文本均值嵌入与槽位特定知识表征之间的余弦相似度,识别语义最匹配的知识句子:
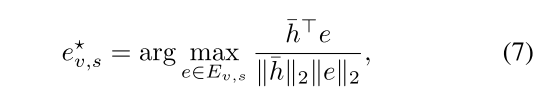
其中, h ˉ \bar{h} hˉ表示均值池化后的描述文本表征, E v , s E_{v,s} Ev,s表示类别v下槽位s的候选知识句子集合。在所有槽位中,保留前k个(通常k=2)作为支持证据,为模型决策提供可解释的文本依据。
3.3.3 文本解释生成
最后,将检索到的证据、槽位重要性分数和预测标签整合为结构化记录R。解释生成模块基于R生成简洁的自然语言解释,总结导致异常判定的主要因素。
生成的解释反映了模型的内部推理过程,将定量预测与可解释的文本证据相结合,提升了检测结果的透明度和可靠性。
4. Experiments
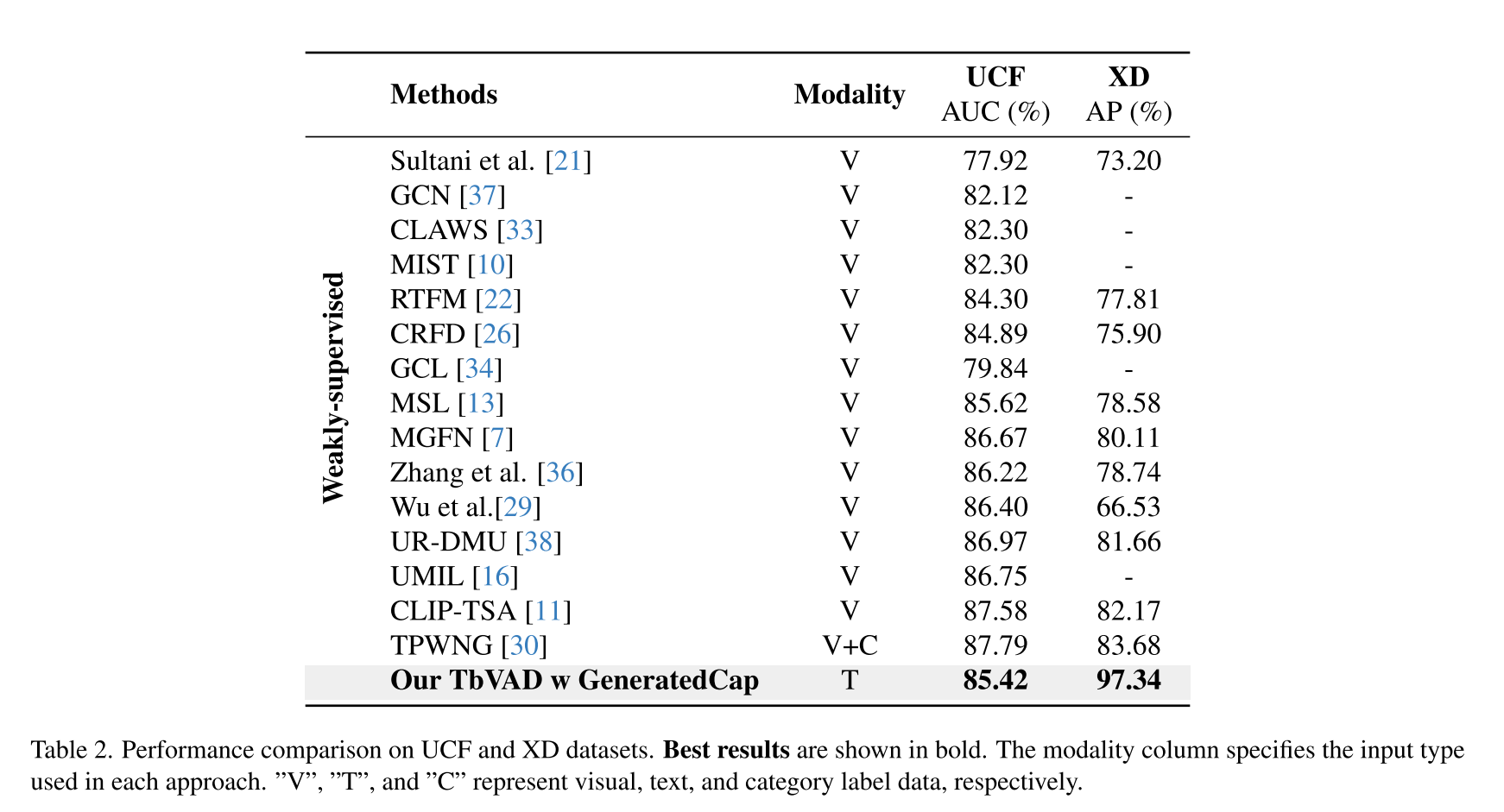
5. Conclusion
我们介绍了TbVAD,这是一个新颖的基于文本的视频异常检测(VAD)框架,通过利用细粒度的字幕和结构化知识,完全在语言领域内运行。通过将监控视频转换为丰富的文本表示,TbVAD能够在弱监督下实现健壮和可解释的异常检测。我们的框架在UCF犯罪和XD暴力上表现出了良好的性能,验证了文本推理在理解真实世界场景中复杂事件方面的有效性。除了检测精度之外,TbVAD在可扩展性和效率方面具有实际优势,消除了对高质量视觉输入的依赖。未来的工作将集中在将TbVAD扩展到实时分析,并增强其跨不同事件类型的解释的通用性。通过识别异常及其语义前兆,TbVAD有望实现主动安全监控和智能监控应用。
总结
怎么评测的感觉没说清楚,看样子像是输出视频级分数。如果是这样的话,咋和之前的工作做对比?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)