【强化学习】第五章:无模型评估:蒙特卡洛学习、时序差分学习、TD(λ)
【强化学习】第五章:无模型评估:蒙特卡洛学习、时序差分学习、TD(λ)
从本篇章开始,我们开启无模型(Model-free)的强化学习方法。
一、梳理本章在强化学习中的位置
1、有模型强化学习->无模型强化学习
在强化学习中我们经常听到有模型、无模型这对儿概念。
有模型是指可以将现实问题抽象成一个完备的MDP。完备的MDP就是我们是知道环境中的状态集合,以及每个状态下的动作集合,而且知道状态之间的转移概率,并且知道系统的即时奖励。此时我们用贝尔曼期望方程+动态规划就可以解决,一般称为DP算法,具体实现过程可以参考第三、第四篇章。
无模型(Model-free)是指现实问题是一个非完备的MDP,我们不知道系统背后的状态集合和动作集合,更不知道状态转移矩阵,我们只能实实在在的去打几步或者打完整个游戏,然后得到一些s,a,r序列,然后通过这些序列去计算状态价值。此时游戏中的状态价值的计算就得用无模型强化学习方法,比如蒙特卡洛学习(MC)、时序差分学习(TD)、TD(λ)。这三个算法也是本篇讲解的重点内容。
2、DP、MC、TD、TD(λ)的应用场合
也是有模型算法和无模型算法之间的联系与区别:
(1)DP只能用于完备的MDP,而且DP可以直接计算出最优策略。
(2)无模型算法通常是用于解决非完备MDP问题的,当然它们也可以用来解决完备的MDP问题,只是完备的MDP问题用DP解决效果要比无模型算法的效果好很多!因为DP解出来的是精确解,而且还可以算出最优策略,其他算法都是对DP的近似,所以其他算法都是估计解,自然比不了DP的效果了。所以很多时候选择算法时,一定一定要和你的实际问题匹配。问题和算法不匹配,得到的效果肯定不好。
(3)为什么说强化学习的其他算法(当然也包括本章的无模型算法)都是对DP的近似?因为其他算法都是在DP的基础上,要么是减弱了对环境模型完备性的假设,要么就是降低了计算复杂度。
(4)DP这么好,还要其他算法干嘛?DP虽好也有其缺点,比如非完备的MDP问题,DP是无法求解的。而且DP的计算复杂度也是非常高的。此时你就必须得用无模型算法。一句话,实际要和算法匹配!
3、无模型强化学习过程:无模型预测->无模型控制
(1)通过前面章节的学习,我们知道有模型强化学习DP的学习过程是分2步:第1步评估和优化价值函数,第2步贪婪化迭代局部最优策略。如此循环这两步直到策略收敛到最优策略,done!
(2)同理,无模型强化学习也是要分两步:
第1步:就是用本章将要讲解的MC、TD、TD(λ)三个算法来无模型预测,或者说估计一个未知MDP的价值函数。在无模型强化学习中,这种计算价值的算法叫评估。所以本章的算法都只是用来计算状态价值的。
第2步:无模型控制,也就是优化一个未知MDP的价值函数 由于有些非完备MDP问题,比如投资、机器人行走等一些场景,虽然也可以看作是一个马尔可夫过程,但这个过程太复杂,我们可能根本连状态-行动-奖励的序列都无法描述出来,此时就需要无模型控制来解决这类问题。所以下一个篇章我们讲无模型控制。
4、你必备的基础
上面总结的一些结论,如果你看不明白,说明你还没有强化学习的基础,那本章你理解起来也会非常抽象和难懂,这也是为什么我们一开始就要花大量篇幅去讲DP的原因。你必须要彻底弄懂,第二章的增量式均值计算、指数移动平均,第三章的贝尔曼期望方程,第四章动态规划中的迭代策略评估,这些内容务弄透了,本章的一些关键细节你就轻松拿下了。
二、蒙特卡洛学习(Monte-Carlo Learning)
1、MC的基本描述和基本思想
蒙特卡洛学习,简称MC,是一个典型的无模型算法,主要用于计算非完备MDP中的状态价值。
(1)MC方法是需要agent和环境进行交互的,因为有交互才可以获得交互数据,然后从交互数据中计算状态价值。
(2)MC方法要求agent得从头打到游戏结束。所以MC只能用于有分幕的情况,就是要有游戏结束的情况。为什么要达到游戏结束呢?因为MC计算状态价值是通过一条条幕计算均值的,而计算过程是从终止状态一步步回溯计算的,游戏不打完就没法算啊!
(3)MC就是用样本均值估计总体均值的方法,就是用样本均值逼近总体均值,或者说就是用频率逼近概率的思路。在完备的MDP中我们是有状态转移矩阵的,所以可以用概率算出状态价值的期望,但是无模型是不知道系统状态是如何转移的,所以只能通过实实在在走出的一条条幕,通过这些幕中的状态实际回报的均值来估计状态价值。
2、MC具体是如何计算状态价值的?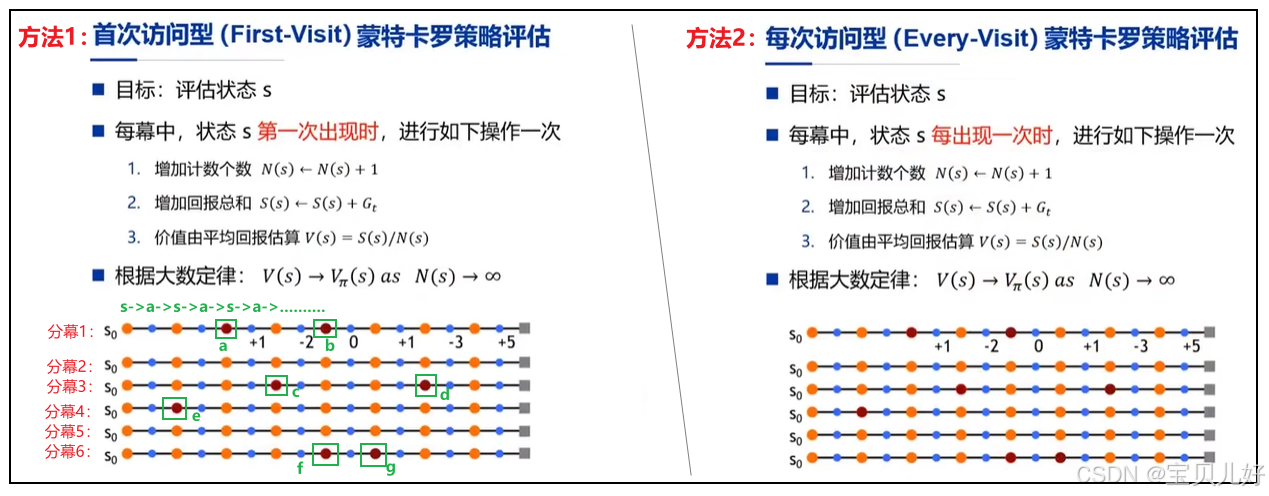
(1)MC可以通过上面两种方法来计算状态价值:first-visit或者every-visit。
(2)上图是agent实实在在的打了6轮游戏,产生了6条分幕,我们现在是要通过这6条分幕来计算状态价值的。
注意:这6条分幕必须是同一个策略下的游戏序列!不能是不同策略下的序列!因为不同策略对应着不同的价值函数。现在我们只是计算价值函数,不是提升策略,提升策略下一个章节讲。
(3)上左图是利用这6条分幕来计算状态s0的价值值的示例。具体做法是:
首先在每条分幕中找到状态s0第一次出现的地方。比如分幕1中,s0第一出现在a处,虽然b处也出现了s0,但是不用管b处,我们只计算a处s0的价值,这也是为什么叫first-visit的原因。那a处s0的价值=其后所有状态的系统奖励和。这是为什么MC必须要求agent从头打完一整局游戏,必须有终止状态,否则没法算啊。如此便算出了第一个s0的价值值。
同理,观察分幕2中s0出现的位置,发现分幕2中压根就没出现状态s0,那就弃用这条分幕!
同理,计算分幕3、分幕4、分幕6中的s0价值值。这样就又得到3个s0的价值值。
最后,求这4个s0价值值的均值,就得到状态s0的价值值。
如此方法计算其他状态的价值。
(4)上右图:方法2示例的也是如何计算状态s0的价值值。但是every-visit采用的是,只要幕中出现状态s0,就统统计算其价值值,然后求平均,平均值就是s0的价值值。简单粗暴。
(5)我们一般多数用的是every-visit方式。anyway,不管是first-visit还是every-visit,很多时候都是可以收敛的,所以这两种方法差别不大,你随便选一种即可,不必纠结。
3、增量式MC、指数移动平均MC
MC的原理非常非常简单,但是工程实现上还有两个技巧:
(1)对于稳态环境问题,工程上一般是用增量来计算价值均值的,也就是我们常说的增量式MC。
为什么会有增量式MC?
首先,比如上面first-visit和every-visit求s0的示例中,是智能体一次性打完6轮游戏,拿到6条分幕的数据,然后才开始计算s0。那在工程实现上,是不是得保留6条分幕的所有数据后,才能计算状态价值。如果一个游戏要玩数十万轮数百万轮计算结果才可靠,那不就得要保存数十万条数百万条分幕!其实没必要,我们的目的只是计算均值而已,所以我们可以在agent打完第1条分幕后,就计算一次s0,agent继续打完第2条分幕后,再计算(更新)一次s0,如此不断更新即可。这样之前打的分幕就没必要保存了,这样就更节省内存和算力了。所以,现实中我们不是坐等agent打完数十万数百万轮游戏后再计算,一般都是打完一局游戏就计算一次。
其次,增量式MC的计算结果和总体求平均的结果是一样的,而且各项的权重是一样的。
(2)对于非稳态环境问题,一般是用指数移动平均来计算价值均值的,也就是我们常说的指数移动平均MC。
为什么会有指数移动平均MC?
稳态环境就是比如agent打游戏,每次打到状态s1,并且agent做了a1动作后,系统转移到其他状态的概率是稳定的。这种情况我们一般称为稳态。非稳态就是agent打到状态s1并且做了a1动作后,系统迁移到其他状态是飘忽不定的,就是没有一个固定概率的转移集合。这种情况就是非稳态情况。此时如果agent再按照之前打游戏的经验来打本轮游戏,岂不是会吃亏,因为之前的经验不可靠了,所以此时就得用指数移动平均来计算价值,就是在计算时,给最近轮次的经验更高的权重,越往前的经验给更小的权重。
(3)增量式MC和指数移动平均MC的迭代过程的数学表示:
(4)下面我再用一个小例子对比一下增量式MC、指数移动平均MC之间的各项权重的差异,因为不管是这里的非稳态MC还是后面要讲的时序差分,都有α这个超参数,而且α对算法的收敛性的影响还很大,所以这里我们再直观的看看超参α在计算中的作用:
从这个例子中我们可以清晰看到增量式MC和普通的求均值效果是一模一样的。但是指数移动平均MC的权重是一个指数递减的过程,例子中α=1/5,每次权重按照上次的20%速率进行递减,所以越往后权重越小。
其实不管是增量式计算状态价值还是指数移动平均计算状态,我在第二章都已经用实际例子和具体代码给大家展示过了:https://blog.csdn.net/friday1203/article/details/155787017?spm=1001.2014.3001.5501 还是不理解的同学可以回看我这篇博文中的例子。
至此,我们使用蒙特卡洛方法就计算出了策略Π下的系统状态价值。现在回看这部分的原理是不是特别特别简单和通俗!而且这个思想其实我在第三章讲状态收益(return)的时候就已经提到了。
三、时序差分学习(Temporal-Difference Learning)
1、时序差分是用来解决什么问题的?
MC方法最大的缺点就是需要agent打完每一轮游戏,才能从一条条游戏序列中计算出状态价值。这样是非常低效的,比如有的复杂游戏需要打非常非常多轮,有的状态才出现一次,而且一轮游戏需要很长时间,那不是要采样到天荒地老了吗?而且有的游戏压根就没有结束状态,那MC就没法用了。时序差分学习就在这个场景下诞生了。
所以时序差分学习是用来计算无法进行分幕的、非完备的MDP中的状态价值的。也所以时序差分学习也是一个无模型强化学习方法。
2、时序差分的基本描述和基本思想
(1)上图左边是时序差分的基本描述。中间是非稳态的every-visit蒙特卡洛学习。右边是最简单的时序差分学习。将TD和MC放一起因为TD是对MC的改进算法,方便对二者进行对比。
(2)A处:前面讲动态规划时的迭代策略评估中,当时就说那个迭代过程叫自举 bootstrapping,就是从一组非收敛的状态价值迭代到一组收敛的状态价值!或者说就是,通过一组预测值来预测另外一组预测值,就这样不断地预测,最后还能预测正确值!其实这也是强化学习最大的缺点,也是导致强化学习的收敛性一直都是一个行业问题。所以在很多复杂情况下,强化学习的收敛性一直是无法证明的。
(3)C处:A处说TD是通过不断地自举迭代来计算收敛的状态价值的。那TD具体如何自举迭代的呢?就是上图C处的式子,这个式子就是TD自举的过程。
- 我们先看C处灰框中的红色字体部分:
它不就是前面第三章中的贝尔曼期望方程的形式之一嘛!可见,又是把无限计算变成有限局部关系的戏码!
MC计算收敛的状态价值时,是得agent实实在在地打了很多步游戏,游戏中的每个状态都需要出现很多次,才能逼近真实的期望Gt。所以MC算法是用实际回报来更新迭代状态价值,直到逼近到真正的状态价值(也就是收敛的状态价值)。但是很多时候,尤其是有些复杂游戏,状态个数非常多的游戏,MC就没法算了,因为可能有些状态MC都打了1万轮了也没碰到过,所以此时就得用TD了。
TD就非常高明了,我想它一定是借鉴了贝尔曼期望方程的思路:TD由于没有像MC那样打了很多幕的游戏,有很多信息,TD可能只打了几步游戏,所以对于TD来说,既然整体无法求解,那我就观察局部,我找出局部之间的关系,让一个无限的东西变成了一个递推式,就让无限变成了有限。就是TD玩的游戏的步数是无限的,但是TD可能就只玩了几步,那想从无限的游戏中算出Gt,就只能列出游戏中有限状态之间的Gt的关系!所以TD用的是估计回报来更新迭代状态价值的。这里你可以类比动态规划中的迭代策略评估,通过预测值来预测另外一组预测值,一轮轮预测,最后也能收敛到真正的状态价值。
也所以,这里的γ是回报的折扣因子。和我们计算第三章中计算状态回报公式中的γ含义一样!!
- 下面我们再看C处整个式子:
C处整个式子表示的是TD是如何迭代到收敛的状态价值的过程。TD还是不同于动态规划中的迭代策略评估的,第三章讲同步DP和异步DP时,都是一次迭代,就更新了全部的状态价值,就是从v0->v1->v2-v3->...一直收敛的v。但是TD的迭代方式式不同于DP。TD是迭代一次,迭代的是差异:v0 --> v1' =v0+α(v1-v0) --> v2'=v1'+α(v2-v1') --> v3'=v2'+α(v3-v2') -->.....直到得到收敛的一组状态价值,停止迭代。
所以TD叫时序差分学习!因为它迭代的是状态序列之间的价值差值。
说明:这里的α是迭代状态价值时,经验的折扣因子!意思就是在迭代计算状态价值,α参数是给当前经验和过去经验的权重参数。在非稳态环境中,过去的经验可能参考性要小很多,因为几个动作下来,已经时过境迁了,环境已经发生了很大的变化,所以当前经验比过去经验要更可信,所以参数α是调整当前经验和过去经验的参数。一定要和γ区别开。二者含义天差地别的。
(4)B处:B处是MC的迭代过程,在讲MC时已经讲过它的原理了。这里想说的是,TD算法(C处)是MC算法(B处)的改进算法,改的仅仅是Gt的计算方式。MC计算Gt是通过一条条实际打出来的幕中回溯计算而得的实际回报,而TD则是利用贝尔曼期望方程估计的回报。也所以MC和TD的本质差异是:
MC没有利用马尔可夫性,所以MC通常在非马尔可夫环境中更有效。
TD利用了马尔可夫性,所以TD通常在马尔可夫环境中效率更高。
为什么会有这样的差异呢?MC有实实在在的游戏回合数据啊,而TD没有!TD对应的是无终止状态的游戏,而且很可能只有打了几步游戏的有限数据啊。
3、MC和TD的使用场景对比
时序差分是现在很多强化学习方法的依据,也就是说,现在很多强化学习方法是依据时序差分来做的。因为TD只要采集当下动作的系统奖励和下一个状态的以前的价值值即可,TD就可以迭代一组新的系统状态价值了。而MC的计算不仅需要当下动作的系统奖励,还要当下状态以后的所有状态的系统奖励。当我们无法采集到很多后续状态的系统奖励时,MC算法就无能为力了,此时TD算法就可堪大任。
此外:
(1)在训练过程中,TD一般会比MC收敛的快一些。
(2)α大小的设置也是影响模型收敛的重要因素。有时α设置得不合适,模型可能都无法收敛。
四、强化学习中的几个重要概念和常识
1、真实值和估计值的表示
在强化学习领域,人们习惯用符号v或V来表示状态价值(v是value的首字母)。但是一般用小v表示"系统中的所有状态的真实价值",而大V表示"系统中的所有状态的估计价值"。我们一般是不知道一个系统中的所有状态的真实价值的,因此需要“估计”这个值。
2、方差和偏差
偏差和方差是机器学习中的一对儿重要概念,指的是模型在训练集和测试集上的表现。我们知道训练集都是一些已经切切实实发生了的样本数据,而测试集被看作是从总体中新抽样的数据。一个模型如果在训练集上表现很好,测试集上表现很糟,我们就说这个模型偏差小但方差大,过拟合了。如果一个模型在训练集上表现比较好,测试集上表现也可以,那我们就说这个模型拟合得比较好。在机器学习中,很多时候我们会故意牺牲一点训练集上的效果,来提升测试集的效果,也就是牺牲一点模型偏差来提升模型方差。
强化学习中也存在方差与偏差,比如MC和TD就是一个方差与偏差的问题:
这里的对系统状态价值的评估问题也是一个偏差与方差的平衡艺术。由于MC是从大量的实际数据中算出的状态价值,所以我们说MC算法是零偏差的,但是对于新数据,MC算法可能就不行了,因为它没见过新数据,所以对新数据预测就不准,所以MC是高方差的。但是对于TD算法,由于TD只有少量的实际样本,所以它计算出来的状态价值就会偏差大,但是它的结果更加具有泛化性,所以TD是低方差的。当然如果TD的样本量实在太太少时,那肯定是偏差大、方差也大,因为数据太少肯定是欠拟合的,全部都是瞎猜的,自然是高偏差高方差了。
3、小批量:Batch MC\TD
在深度学习中,梯度下降优化算法就常用小批量(batch)样本来迭代损失函数,其好处和优点这里我就不展开说,感兴趣可以查看我之前的深度学习文章。
在强化学习中同样也有batch这个概念的,但强化学习中的batch操作稍微复杂一点:
注意:上面的K条分幕必须是同一个策略下的游戏序列!
4、在线学习(Online Learning)和离线学习(Offline Learning)
在线学习和离线学习是强化学习中的两种范式,描述的是数据的来源方式:你的算法在训练过程中是否能持续与环境交互,实时收集新数据?
(1)离线学习:表示游戏的轮次(可以是一个episode,也可以是多个episode)已经全部打完,然后再计算状态价值。比如MC就必须要至少打完一局游戏,才能开始计算状态价值,所以MC是离线学习。
(2)在线学习:表示边打游戏边计算状态价值,或者说,甚至可以打一步游戏就评估一次状态价值。比如TD就是在线进学习。
5、无模型强化学习的任务
无模型强化学习的任务分预测任务和控制任务。
强化学习的最终目的是寻找最优策略的,就是如何让一个agent从小白逐渐成为高手的。这个目的一般由预测任务+控制任务来达到。
比如,在DP中我们是通过两步来寻找最优策略的,第一步是求收敛的价值函数,第二步贪婪化的更新策略,直到得到最优策略。那第一步就是预测任务,也叫评估和优化价值函数。第二步就是控制任务,控制任务也就是策略提升任务。
本章的MC\TD\TD(λ)都是无模型学习,也叫无模型评估,都是用于计算策略Π下的系统状态价值的,也就是解决预测任务的,后面紧接着就需要进行无模型控制。但是对于非完备的MDP问题,我们是不知道各个状态下的动作集合的,也不知道状态转移矩阵,所以就无法用像DP中的贪婪化方式寻找最优策略。所以无模型的控制任务要复杂很多,下一个篇章我们专门展开这个话题。
五、TD(λ)
1、TD(λ)是用来解决什么问题的?
TD(λ)方法可以看作是蒙特卡洛方法和时序差分方法的混合。因为TD(0)最大的缺点是偏差大,MC最大的缺点是方差大,所以TD(λ)融合了二者,既继承了MC的偏差小优点,又继承了TD的方差小优点。
2、TD(0):n步TD
前面我们学的TD,其实应该写成TD(0),因为它计算状态价值时,用的序列样本都是比如走1步的序列片段,或者都是走2步的序列片段,或者都是走3步的序列片段,或者...,所以叫TD(0)。上左图中的"1步TD"、"2步TD"、"n步TD"都叫TD(0)。
3、TD(0)->TD(λ)
但是,在实际中,我们不是非得只采样1步的样本片段、或者只采样2步的样本片段,我们是可以采样随意步数的序列片段的,当然最大步数就是MC的步数:直到游戏结束。
当TD算法在计算状态价值时,用的样本是随意步数的序列片段、并且这些不同步长片段之间的权重按(1-λ)乘以λ的n-1次方(λ在0-1之间)来分配的权重的,用此时计算出来的Gt,来更新迭代状态价值时,我们叫TD(λ),如下面右图所示: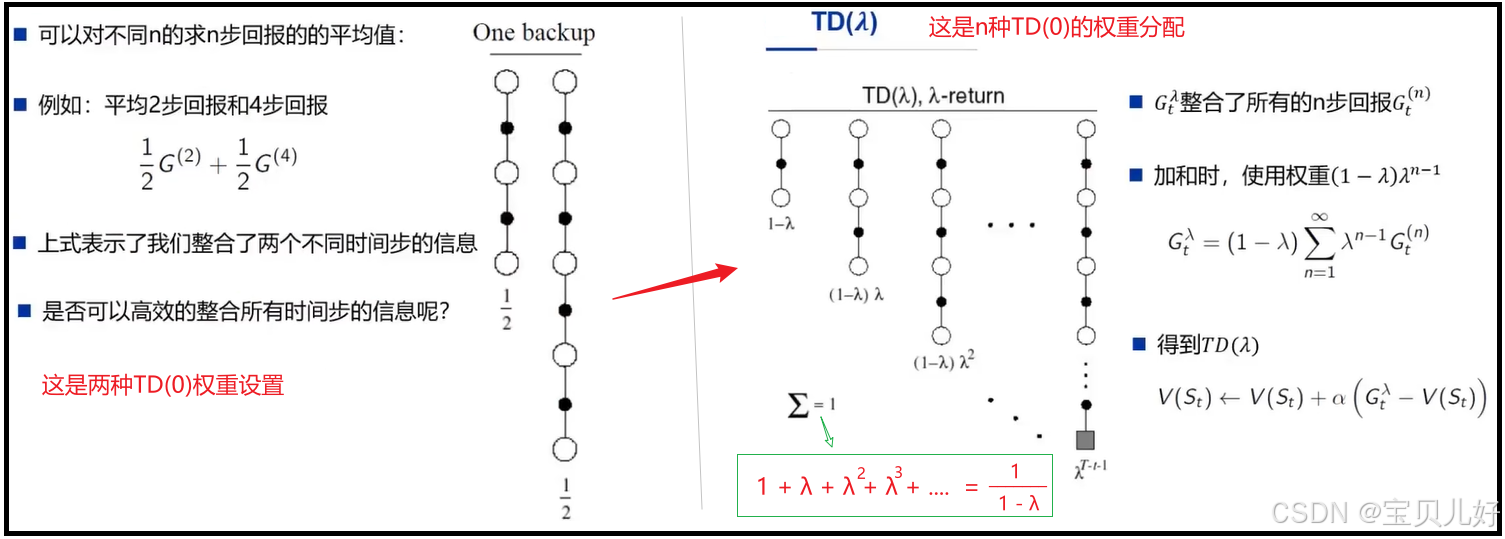
由于TD算法主要应用于无终止状态的场景中,比如终止状态的游戏,所以步数n是趋向无穷大的,所以上图绿框中的权重分配方式也比较合理。打游戏的步数越长,权重就越低。这是合理的。因为此时TD就坍塌成MC了,就是所有的可能性都坍塌了,所以计算的价值虽然偏差小,但方差大。下图是绿框权重的衰减图: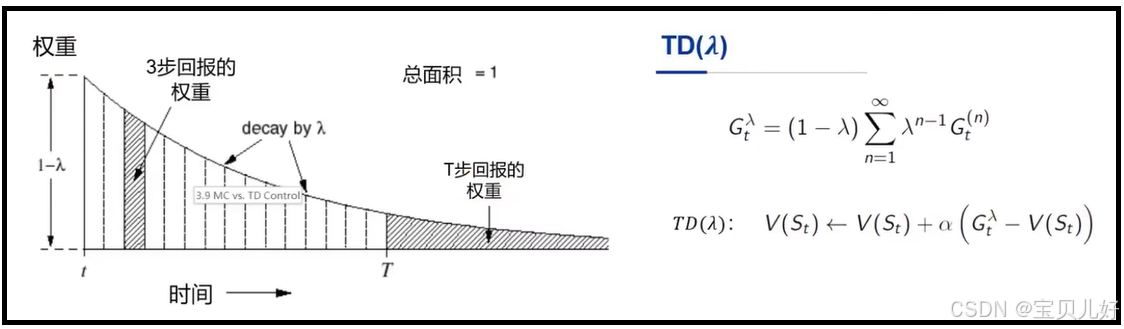
六、DP、MC、TD、TD(λ)对比总结¶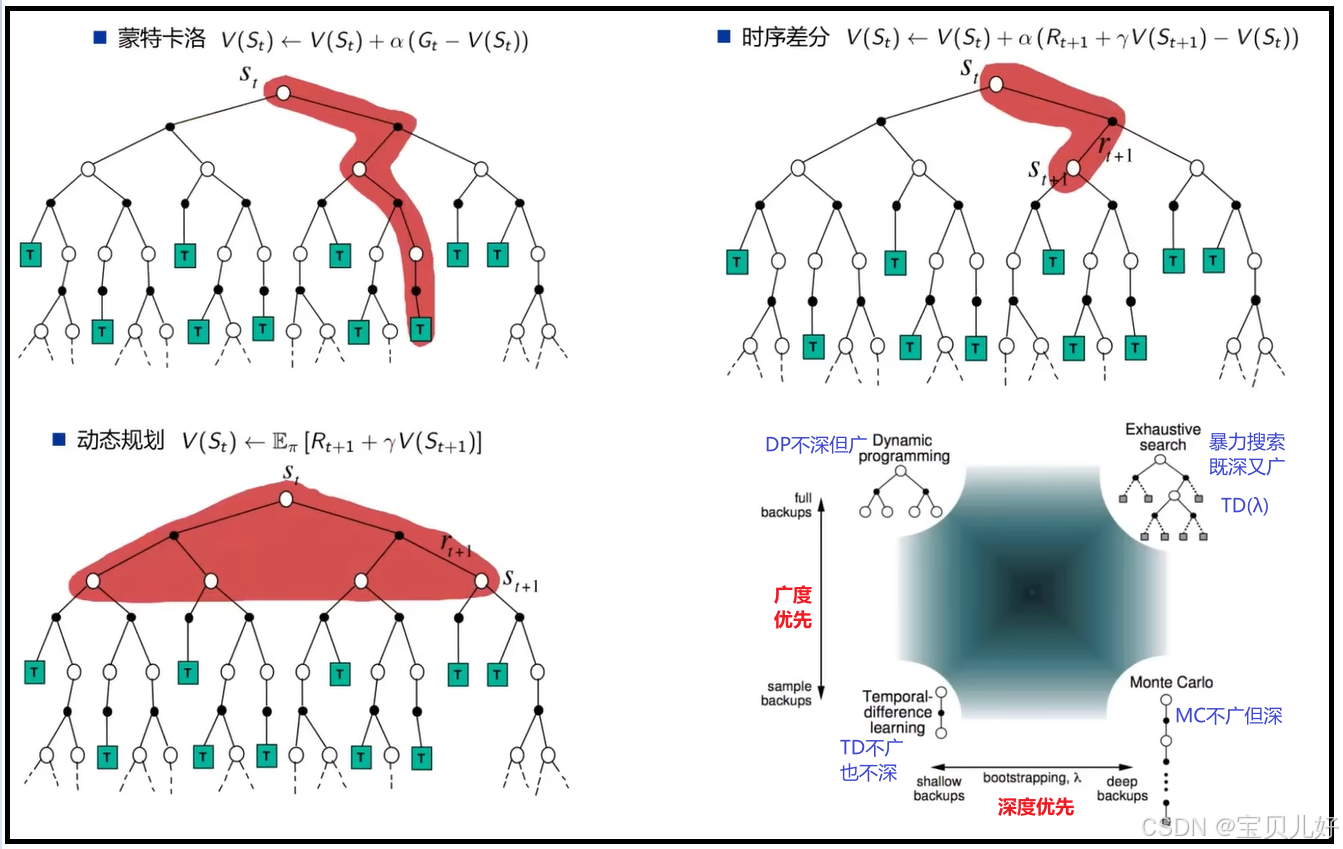
1、MC和TD都需要采样,DP不需要采样。
2、DP不用采样,因为能用DP解决问题,说明这个问题是一个完备的MDP问题,完备的MDP是知道系统的状态转移矩阵、系统奖励、以及每个状态下的动作集合的。所以DP根据概率就能准确求出期望价值,压根不需要采样。
3、MC是要实实在在打出一幕游戏数据,就是需要采样一条完整的序列,然后再计算状态价值。这可以看作是深度优先。
4、TD(0)是不用打完游戏,打完1步也可以算状态价值了。也就是TD(0)只需要采样序列片段就可以计算了。
5、TD(λ)是兼顾了深度的宽度探索,所以也叫暴力搜索、或者叫穷举法。
本篇完。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)