SmolVLA论文代码精读:比主流VLA小10倍,性能却达SOTA!
摘要 本文介绍了视觉-语言-动作(VLA)模型SmolVLA的创新设计。该模型采用轻量级双模块架构:视觉语言模型(VLM)负责多模态感知,动作专家模块基于Flow Matching技术生成控制指令。关键创新包括:1)异步推理机制,通过动作队列缓存实现高效执行;2)交替使用交叉/自注意力提升动作稳定性;3)仅需3万条社区数据训练,显著降低资源需求。实验表明,SmolVLA在消费级硬件上即可运行,为具
0. 简介
近年来,AI领域逐渐转向基础模型的发展,即能够完成多种任务的通用模型。大语言模型(LLMs)作为代表,已在自然语言理解、复杂推理和知识表达等方面表现出接近人类的能力。这类模型的成功推动了多模态基础模型的发展,尤其是在视觉-语言模型(VLMs)和音频-语言模型(ALMs)领域取得了显著进展。这些成果的背后,一方面依赖于Transformer等可扩展架构的使用,另一方面则得益于大规模互联网数据的训练支撑。
尽管基础模型在数字世界中取得了巨大成功,但它们在真实世界中的应用仍面临挑战,尤其是在机器人领域。目前的机器人控制策略在面对不同物体、位置、环境与任务时,仍难以具备足够的泛化能力。要实现机器人对新环境和新物体的适应能力,关键在于让其具备稳健的技能和基本的常识理解。而数据的稀缺与质量不一,成为这一目标实现的主要障碍。
为了解决这些问题,研究者开始探索"视觉-语言-动作"(VLA)模型这一新方向。VLA模型在预训练语言和视觉-语言模型的基础上,进一步融合推理能力、世界知识和决策能力,使得机器人能够根据图像和自然语言指令进行感知与动作预测。
SmolVLA的核心创新在于重新定义了VLA模型的设计哲学——从追求"更大更强"转向追求"更小更实用"。它证明了在合理的架构设计和训练策略下,小模型同样可以达到大模型的性能水平。
1. 论文核心贡献
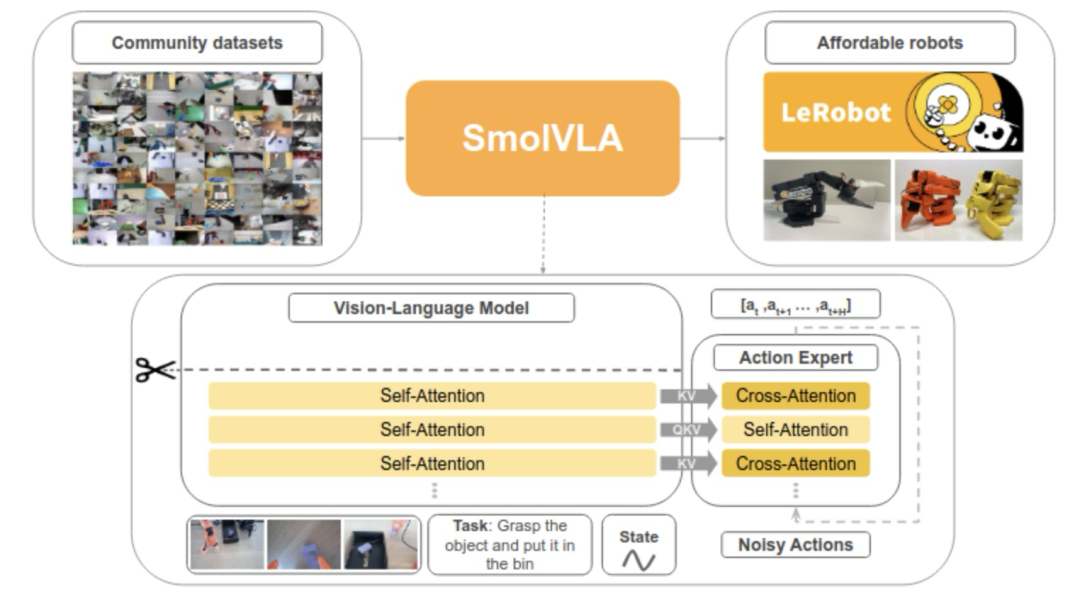
- 轻量架构设计:SmolVLA可以在消费级GPU甚至CPU上运行,训练和推理成本极低。设计上采用了跳过VLM部分层数、减少视觉tokens数量、使用小型预训练模型,并在注意力机制中交替使用自注意力与交叉注意力。
- 社区数据训练:该模型仅使用约3万条社区贡献的数据进行预训练,数据量相比同类方法少一个数量级,仍取得了出色效果。
- 异步推理机制:引入异步推理策略,将感知、预测与执行解耦,提高了推理响应速度,并适应低资源平台上的部署需求。
这种设计理念的转变,不仅解决了传统VLA模型的部署难题,更为具身智能的普及化发展铺平了道路。
2. SmolVLA整体架构解析
2.1 核心设计思想
SmolVLA的核心创新在于将传统的端到端VLA模型拆分为两个协同工作的组件:
- 视觉语言模型(VLM):负责感知理解,处理图像、语言指令和机器人状态
- 动作专家(Action Expert):专门负责动作生成,使用Flow Matching技术预测动作序列
这种解耦设计不仅降低了模型复杂度,还实现了异步推理,大幅提升了机器人响应速度。
2.2 双模块协同架构
SmolVLA 的核心结构可拆解为两部分:
2.2.1 视觉-语言模型(VLM)
VLM 是整个系统的感知主干,负责处理机器人当前的感知状态信息,包括:
- 多路 RGB 相机采集的图像:支持多视角输入,每个相机提供不同角度的环境信息
- 来自机器人本体的传感器状态:包括关节角度、末端执行器位置、夹爪状态等
- 自然语言描述的任务指令:用户以自然语言形式描述的任务目标
该部分使用了名为 SmolVLM-2 的紧凑型多模态模型作为骨干网络,具备处理多张图像与视频输入的能力。视觉部分采用了 SigLIP 编码器,语言部分则使用 SmolLM2 解码器。三种输入分别被编码为视觉 token、语言 token 与状态 token,随后在统一的 token 空间中拼接后,输入到语言解码器中,生成用于动作模块的语义特征。
关键技术特点:
- 像素打乱优化:视觉输入采用了"像素打乱"(pixel shuffle)操作,将每帧图像的 token 数限制在 64 个以内,大幅降低计算复杂度
- 状态向量压缩:任务状态向量通过线性投影压缩成单个 token,以与语言模型输入结构对齐
- 多模态融合:在统一的token空间中处理不同模态的信息,实现有效的特征融合
2.2.2 动作专家(Action Expert)
动作专家是负责生成具体控制指令的模块,结构上为一个条件化 Transformer。其输入是来自 VLM 的语义特征,输出是未来一段时间的动作序列(chunk),形式上是若干个连续时间步的低层控制指令。
创新的注意力机制设计:
不同于以往使用单一注意力机制的方案,SmolVLA 的动作专家在层间交替使用交叉注意力(cross-attention)与自注意力(self-attention),以更充分地利用视觉-语言信息与动作之间的依赖关系:
- 交叉注意力层:负责让当前动作 token 与 VLM 特征进行交互,确保动作生成充分考虑感知信息
- 自注意力层:使不同时间步的动作 token 能够相互关联,并通过因果遮罩(causal mask)确保动作序列中仅能访问过去的动作状态,从而保证执行顺序的合理性
这种交替设计在实验中表现出更强的鲁棒性,尤其在真实机器人控制中生成的动作序列更加平滑稳定。
3. 核心代码解析深入
3.1 SmolVLAPolicy主类结构详解
让我们从主要的策略类开始深入分析SmolVLA的实现细节:
class SmolVLAPolicy(PreTrainedPolicy):
"""Wrapper class around VLAFlowMatching model to train and run inference within LeRobot."""
config_class = SmolVLAConfig
name = "smolvla"
def __init__(self, config: SmolVLAConfig, dataset_stats: dict[str, dict[str, Tensor]] | None = None):
super().__init__(config)
config.validate_features()
self.config = config
# 初始化归一化模块
self.normalize_inputs = Normalize(config.input_features, config.normalization_mapping, dataset_stats)
self.normalize_targets = Normalize(config.output_features, config.normalization_mapping, dataset_stats)
self.unnormalize_outputs = Unnormalize(config.output_features, config.normalization_mapping, dataset_stats)
# 初始化语言处理器和核心模型
self.language_tokenizer = AutoProcessor.from_pretrained(self.config.vlm_model_name).tokenizer
self.model = VLAFlowMatching(config)
self.reset()
3.2 动作队列管理机制深度解析
SmolVLA的一个重要创新是动作队列管理机制,这是实现异步推理的关键:
def reset(self):
"""This should be called whenever the environment is reset."""
self._queues = {
ACTION: deque(maxlen=self.config.n_action_steps),
}
@torch.no_grad
def select_action(self, batch: dict[str, Tensor], noise: Tensor | None = None) -> Tensor:
"""Select a single action given environment observations."""
self.eval()
# 适配特定机器人平台(如Aloha)
if self.config.adapt_to_pi_aloha:
batch[OBS_STATE] = self._pi_aloha_decode_state(batch[OBS_STATE])
batch = self.normalize_inputs(batch)
# 动作队列逻辑:只有队列为空时才调用模型预测
if len(self._queues[ACTION]) == 0:
# 准备多模态输入
images, img_masks = self.prepare_images(batch)
state = self.prepare_state(batch)
lang_tokens, lang_masks = self.prepare_language(batch)
# 调用模型预测动作序列
actions = self.model.sample_actions(images, img_masks, lang_tokens, lang_masks, state, noise=noise)
# 处理动作并填充队列
actions = self.unnormalize_outputs({"action": actions})["action"]
if self.config.adapt_to_pi_aloha:
actions = self._pi_aloha_encode_actions(actions)
# 填充队列,实现异步执行
self._queues[ACTION].extend(actions.transpose(0, 1)[:self.config.n_action_steps])
return self._queues[ACTION].popleft()
动作队列缓存策略:一次预测多步动作(action chunk),避免频繁调用模型。这种设计基于一个重要观察:机器人的动作往往具有时序连贯性,短期内的动作序列可以一次性预测。
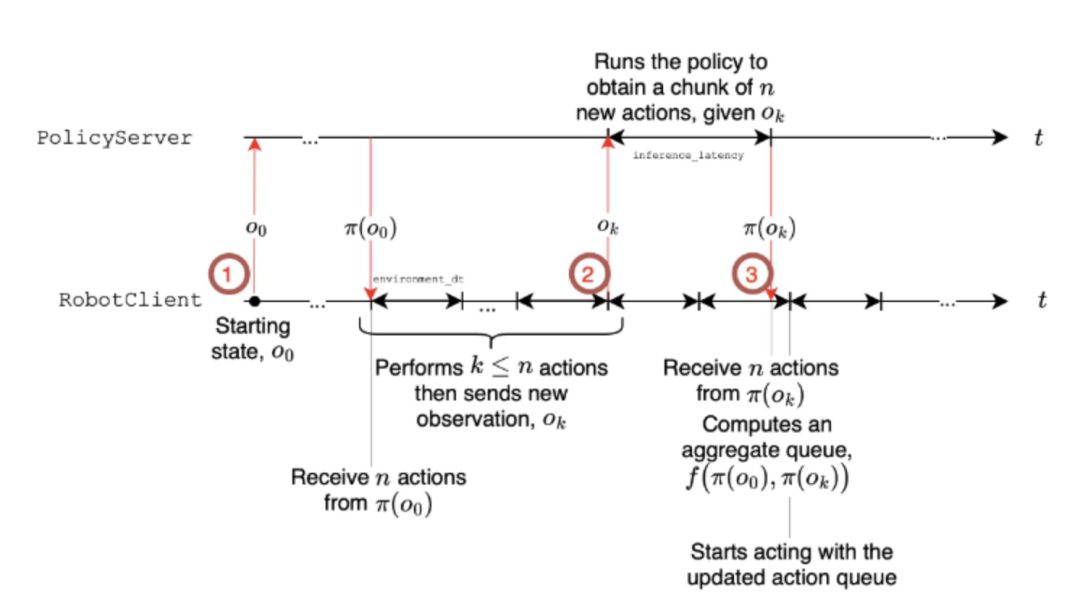

通过维护一个固定大小的动作队列,存储预测的动作序列,当队列中剩余动作数量低于阈值时,触发新的预测。算法中动作执行和预测在不同线程中并行进行,通过流水线处理,隐藏推理延迟。
2.3 VLAFlowMatching核心模型深度解析
这是SmolVLA的核心实现,让我们深入分析其架构设计:
class VLAFlowMatching(nn.Module):
"""
SmolVLA核心模型
架构图:
┌──────────────────────────────┐
│ actions │
│ ▲ │
│ ┌─────────┐ ┌─|────┐ │
│ | │────► │ │ │
│ | │ kv │ │ │
│ | │────► │Action│ │
│ | VLM │cache │Expert│ |
│ │ │────► | │ │
│ │ │ │ │ │
│ └▲──▲───▲─┘ └───▲──┘ |
│ │ | | │ |
│ | | | noise │
│ │ │ state │
│ │ language tokens │
│ image(s) │
└──────────────────────────────┘
"""
def __init__(self, config):
super().__init__()
self.config = config
# 核心组件:VLM + 动作专家
self.vlm_with_expert = SmolVLMWithExpertModel(
model_id=self.config.vlm_model_name,
freeze_vision_encoder=self.config.freeze_vision_encoder,
train_expert_only=self.config.train_expert_only,
load_vlm_weights=self.config.load_vlm_weights,
attention_mode=self.config.attention_mode,
num_expert_layers=self.config.num_expert_layers,
num_vlm_layers=self.config.num_vlm_layers,
self_attn_every_n_layers=self.config.self_attn_every_n_layers,
expert_width_multiplier=self.config.expert_width_multiplier,
)
# 投影层设计
self.state_proj = nn.Linear(self.config.max_state_dim, self.vlm_with_expert.config.text_config.hidden_size)
self.action_in_proj = nn.Linear(self.config.max_action_dim, self.vlm_with_expert.expert_hidden_size)
self.action_out_proj = nn.Linear(self.vlm_with_expert.expert_hidden_size, self.config.max_action_dim)
# Flow Matching的时间嵌入网络
self.action_time_mlp_in = nn.Linear(self.vlm_with_expert.expert_hidden_size * 2, self.vlm_with_expert.expert_hidden_size)
self.action_time_mlp_out = nn.Linear(self.vlm_with_expert.expert_hidden_size, self.vlm_with_expert.expert_hidden_size)
4. Flow Matching算法深度解析
…详情请参照古月居

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 8
8 0
0- 0



 已为社区贡献165条内容
已为社区贡献165条内容

所有评论(0)