为什么你写的Python爬虫脚本老是掉链子?
现在大型网站的反爬策略越来越高明了,不仅是对IP访问频率、User-Agent请求头进行异常识别,还会分析IP地址、浏览器指纹、JS动态加载、API逆向、行为模式等方式各种设卡,动不动跳出五花八门的验证码,非常难搞。怎么应对反爬是个系统性问题,需要采取多种策略,而且涉及到法律法规,得遵守网站的robot协议,做一些自动化检测、采集少量公开数据没啥问题,对网站造成干扰的事情可不能干。我觉得使用Pyt
现在大型网站的反爬策略越来越高明了,不仅是对IP访问频率、User-Agent请求头进行异常识别,还会分析IP地址、浏览器指纹、JS动态加载、API逆向、行为模式等方式各种设卡,动不动跳出五花八门的验证码,非常难搞。
怎么应对反爬是个系统性问题,需要采取多种策略,而且涉及到法律法规,得遵守网站的robot协议,做一些自动化检测、采集少量公开数据没啥问题,对网站造成干扰的事情可不能干。
我觉得使用Python爬虫有6个技巧比较重要,可以更稳定的采集数据。
1、尽量不要使用无头浏览器
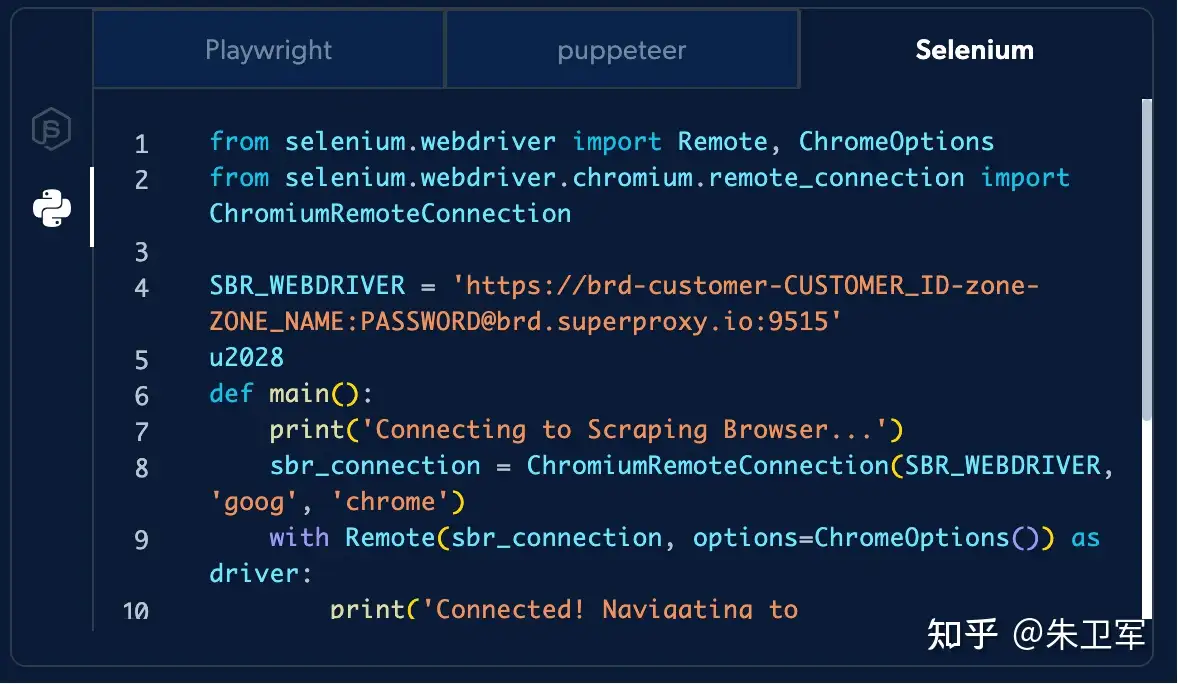
因为很多网站会直接识别headless模式,也就是无头模式,只有selenium、playwright这样的自动化工具才会这么干,真人只会在浏览器界面访问,所以用selenium、playwright时要打开真实浏览器界面,这样不容易被检测。
2、要模仿真人使用浏览器的行为
在playwright点击、翻页、下载等动作之间设置不定时的延迟,比如1~5秒的随机延迟,这样是为了模仿真人行为的不规律性。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# 启动浏览器,设置更真实的视图窗口
browser = p.chromium.launch(headless=True)
context = browser.new_context(viewport={'width': 1920, 'height': 1080})
page = context.new_page()
# 导航到页面
page.goto("https://example.com")
# 模拟随机鼠标移动(可选,根据需要)
# page.mouse.move(random.randint(0, 1920), random.randint(0, 1080))
3、调整浏览器指纹
浏览器指纹包括像User-Agent、屏幕分辨率等,可以使用多个真实的User-Agent随机轮换访问,设置浏览器界面为常见分辨率等。
import requests
import random
# 准备一个User-Agent列表
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36...",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36...",
# ... 更多User-Agent
]
headers = {"User-Agent": random.choice(USER_AGENTS)}
4、可以设置代理IP池
同一个IP访问频率和时间过长,也会被检测,所以需要找一些质量好点的IP池,可以切换访问。
python selenium可以通过options模块专门设置代理,可以随机切换,设置不定时的延迟,这样就不容易被封掉。
import requests
import random
# 假设的代理IP池
proxies_list = [
{"http": "http://1.2.3.4:8080", "https": "http://1.2.3.4:8080"},
# ... 更多代理
]
proxy = random.choice(proxies_list)
5、修改execute_cdp_cmd文件,隐藏selenium痕迹
selenium会默认在DOM中加入selenium标记脚本,这比较容易被识别出来,可以修改execute_cdp_cmd文件
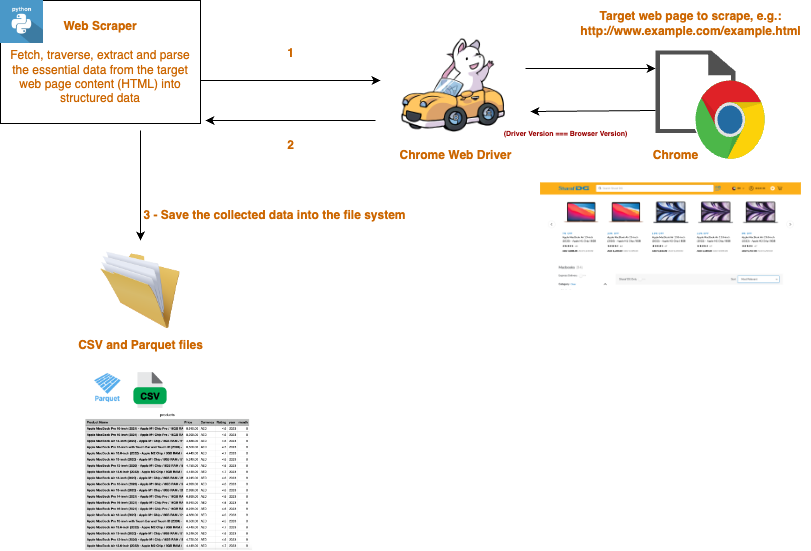
6、可以尝试用亮数据的采集api
如果是技术小白,不会写上面提到的那些规避措施代码,就可以尝试用亮数据的这样的采集api,它把各种规避检测的技术、IP代理池都封装到一个接口里,还提供专门的云上浏览器,用selenium接入,和普通浏览器一样,有头无头都支持,但不需要再写各种反爬措施之类的脚本,比较简单直接。
而且亮数据还提供了专门的数据采集API-Scraper APIs,已经配置好所有爬虫环节,你只需要配置好API接口就能一键采集到各大主流网站的数据。
Scraper APIs是亮数据专门为批量采集数据而开发的接口,支持上百个网站,200多个专门API采集器,例如商品、短视频数据采集器,当然这些数据都是公开可抓取的,不会涉及任何隐私安全问题。
亮数据使用方法:
- 注册账号 → 选择“亮数据浏览器”。
https://get.brightdata.com/webscra - 输入目标网址 → 生成Python代码示例。
- 运行代码 → 自动采集并存储数据。
总的来说,应对反爬有很多措施,核心是模拟真人访问行文,但现在检测技术也越来越先进,魔高一尺道高一丈的博弈。不管怎么样,一定要尊重robots协议,还得控制爬取频率,合法合规最关键。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 4
4 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)