Transformer的工作原理
Transformer是一种基于注意力机制的深度学习模型架构,由Google在2017年提出。它抛弃传统RNN/CNN结构,采用自注意力和前馈网络,实现高度并行化和全局依赖建模。核心组件包括输入表示、多头自注意力机制和位置编码。Encoder-Decoder结构支持多种任务,其中Decoder使用掩码防止信息泄露。Transformer的优势在于并行化处理、长程依赖建模和强大的可扩展性,成为GPT
Transformer的工作原理
Transformer 是一种“完全基于注意力机制(Attention Mechanism)”的深度学习模型架构,由 Google 在 2017 年的论文 《Attention Is All You Need》 中首次提出。它彻底改变了自然语言处理(NLP)领域,并成为大语言模型(如 GPT、BERT、LLaMA 等)的基础。
一、核心思想:用“注意力”替代“循环/卷积”
在 Transformer 之前,主流序列模型(如 RNN、LSTM)依赖顺序处理,难以并行化,训练慢;而 CNN 虽可并行,但对长距离依赖建模能力弱。
Transformer 的突破:
抛弃 RNN/CNN,仅用“自注意力(Self-Attention)+ 前馈网络”构建模型,实现:
- 高度并行化(训练快)
- 全局依赖建模(任意两个词可直接交互)
二、整体架构:Encoder-Decoder 结构
Transformer 由两部分组成:
[Input] → [Encoder Stack] → [Decoder Stack] → [Output]
- Encoder:将输入序列(如句子)编码为富含语义的向量表示;
- Decoder:根据 Encoder 输出和已生成的部分输出,逐步预测下一个词(用于翻译、生成等任务)。
注:像 BERT 只用 Encoder,GPT 只用 Decoder。
三、核心组件详解
1. 输入表示(Input Embedding + Positional Encoding)
- Token Embedding:每个词映射为固定维度向量(如 512 维)。
- Positional Encoding(位置编码):
因为 Transformer 没有顺序信息,需显式加入位置信息。
使用正弦/余弦函数生成不同频率的位置向量,与词向量相加:
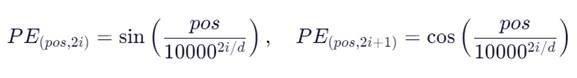
- 其中 pos 是位置,i 是维度索引,d 是向量维度。
2. 多头自注意力机制(Multi-Head Self-Attention)
这是 Transformer 的核心创新。
步骤:
- 对每个输入向量,线性变换出三个向量:
- Query (Q):当前词的“查询”向量
- Key (K):其他词的“键”向量
- Value (V):其他词的“值”向量
- 计算注意力权重:
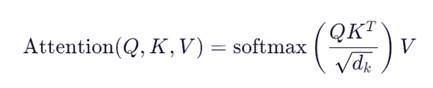


四、Decoder 的特殊设计:Masked Self-Attention
Decoder 在训练时需防止“偷看未来词”,因此:
- Masked Multi-Head Attention:
在计算注意力时,将未来位置的权重设为 -inf(经 softmax 后为 0),确保第 t 步只能看到 1 到 t 的词。 - Encoder-Decoder Attention:
Decoder 还会 attend 到 Encoder 的输出(K, V 来自 Encoder,Q 来自 Decoder),实现跨序列对齐(如翻译中“apple”对应“苹果”)。
五、训练与推理
- 训练:给定目标序列(如翻译结果),用 Teacher Forcing 方式并行计算所有位置损失;
- 推理:自回归生成,逐个 token 预测(因不能提前知道未来词)。
六、为什么 Transformer 如此成功?
|
优势 |
说明 |
|
✅ 并行化 |
无 RNN 依赖,GPU 利用率高 |
|
✅ 长程依赖 |
任意两词可直接交互(RNN 需 O(n) 步) |
|
✅ 可扩展性强 |
易堆叠层数、扩大参数(支撑大模型) |
|
✅ 通用架构 |
不仅用于 NLP,还用于 CV(ViT)、语音、蛋白质结构预测等 |
七、图解简化流程(以 Encoder 为例)
Input Words → [Embedding + Pos Enc]
↓
[Multi-Head Self-Attention] → Add & Norm
↓
[Feed-Forward Network] → Add & Norm
↓
(Repeat N times, e.g., 6)
↓
Context-Aware Representations
总结
Transformer 的本质:
通过 自注意力机制 动态计算每个词在上下文中的重要性权重,从而构建全局语义表示,无需递归、无需卷积,实现高效、强大的序列建模。
如今,几乎所有主流 AI 大模型(包括你正在使用的这个语言模型)都建立在 Transformer 架构之上。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)