【Python学习打卡-Day21】超越SHAP:模型解释性的“事前”智慧与“事后”洞察
各位伙伴们,大家好!在 Day 20,我们用 SHAP 这把“瑞士军刀”成功地打开了机器学习的“黑箱”,看到了每个特征是如何影响模型决策的。然而,SHAP 只是庞大的可解释性人工智能 (XAI)世界中的一员。今天,Day 21,我们将站得更高,看得更远,系统地梳理模型解释性的不同流派。是不是所有模型都需要“事后”才能解释?有没有天生就是“白箱”的模型?模型告诉我们“A和B相关”,我们能说“A导致B
📋 前言
各位伙伴们,大家好!在 Day 20,我们用 SHAP 这把“瑞士军刀”成功地打开了机器学习的“黑箱”,看到了每个特征是如何影响模型决策的。然而,SHAP 只是庞大的可解释性人工智能 (XAI) 世界中的一员。
今天,Day 21,我们将站得更高,看得更远,系统地梳理模型解释性的不同流派。我们将回答几个关键问题:
- 是不是所有模型都需要“事后”才能解释?
- 有没有天生就是“白箱”的模型?
- 模型告诉我们“A和B相关”,我们能说“A导致B”吗?
让我们一起探索模型解释性的“事前”智慧、“事后”洞察,并初探“因果分析”这片更深的蓝海。
一、模型解释性的两大流派:事前 vs 事后
根据解释性介入模型构建的时机,我们可以将方法分为两大类:事前解释 (Ante-hoc) 和 事后解释 (Post-hoc)。
1.1 事前解释 (Ante-hoc): “白箱”模型的内在智慧
定义:事前解释指的是使用那些本身结构就足够简单、透明,以至于它们自己就能作为解释的模型。我们不需要额外的工具去分析它,模型本身就是“可读”的。
典型代表:
- 线性回归/逻辑回归:我们可以直接查看每个特征的系数(
coef_),直观地了解该特征对结果是正向还是负向影响。 - 决策树:整个模型就是一套
if-then-else规则集,可以完整地被可视化和理解。
比喻:它们就像一个透明的玻璃盒子。你不仅能看到最终输出,还能清晰地看到里面每一个齿轮是如何转动、如何相互作用的。
- 优点:解释是全局的、精确的、可信的。因为解释就是模型本身。
- 缺点:为了追求可解释性,模型结构通常比较简单,可能在复杂的非线性问题上表现不如“黑箱”模型。
1.2 事后解释 (Post-hoc): “黑箱”模型的外部探针
定义:事后解释指的是当模型已经训练完成后(通常是一个复杂的“黑箱”模型,如随机森林、梯度提升树、神经网络),我们使用外部的、独立于模型的工具来分析和解释它的行为。
典型代表:
- SHAP (我们已学):通过计算每个特征的边际贡献来解释预测。
- LIME (Local Interpretable Model-agnostic Explanations):通过在单个样本周围生成一个简单的、局部的、可解释的模型(如线性回归)来“模拟”黑箱模型在该点的行为。
比喻:它们就像给一个密封的、不透明的黑盒子接上各种传感器和探针。我们通过观察探针的读数来推测盒子内部的运作原理,但永远无法100%确定内部的真实情况。
- 优点:模型无关性,可以应用于任何模型,让我们放心地使用性能最强的复杂模型。
- 缺点:解释是近似的,尤其是在局部。有时为了简化,解释可能会忽略掉一些复杂的交互,甚至产生误导。
二、实战演练:“事前解释”的魅力之决策树
让我们亲身体验一下“事前解释”的清晰与直观。我们将使用心脏病数据集,训练一个决策树模型,并将其“翻译”成人类能懂的规则。
【代码实现】
# 【我的代码】
# 本部分代码将演示如何使用决策树进行“事前解释”
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
# --- 1. 数据准备 ---
# 使用之前课程中的心脏病数据集
# 此处假设已有名为 'heart.csv' 的文件
# data = pd.read_csv('heart.csv')
# 假设数据已加载并分为 X 和 y
# 为了演示,我们随机生成一些数据
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=300, n_features=5, n_informative=3, n_redundant=0, random_state=42)
feature_names = [f'feature_{i}' for i in range(X.shape[1])]
X = pd.DataFrame(X, columns=feature_names)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# --- 2. 训练一个“白箱”模型 ---
# 我们限制树的深度,使其更容易被可视化和理解
dt_model = DecisionTreeClassifier(max_depth=3, random_state=42)
dt_model.fit(X_train, y_train)
print(f"决策树模型在测试集上的准确率: {dt_model.score(X_test, y_test):.2f}")
# --- 3. 模型即解释:可视化决策树 ---
plt.figure(figsize=(20, 10))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体,防止乱码
plt.rcParams['axes.unicode_minus'] = False
plot_tree(
dt_model,
feature_names=feature_names,
class_names=['无病', '有病'], # 假设 0 为无病, 1 为有病
filled=True, # 用颜色填充节点
rounded=True, # 使用圆角框
fontsize=10
)
plt.title("决策树可视化:模型即解释", fontsize=20)
plt.show()
【结果解读】
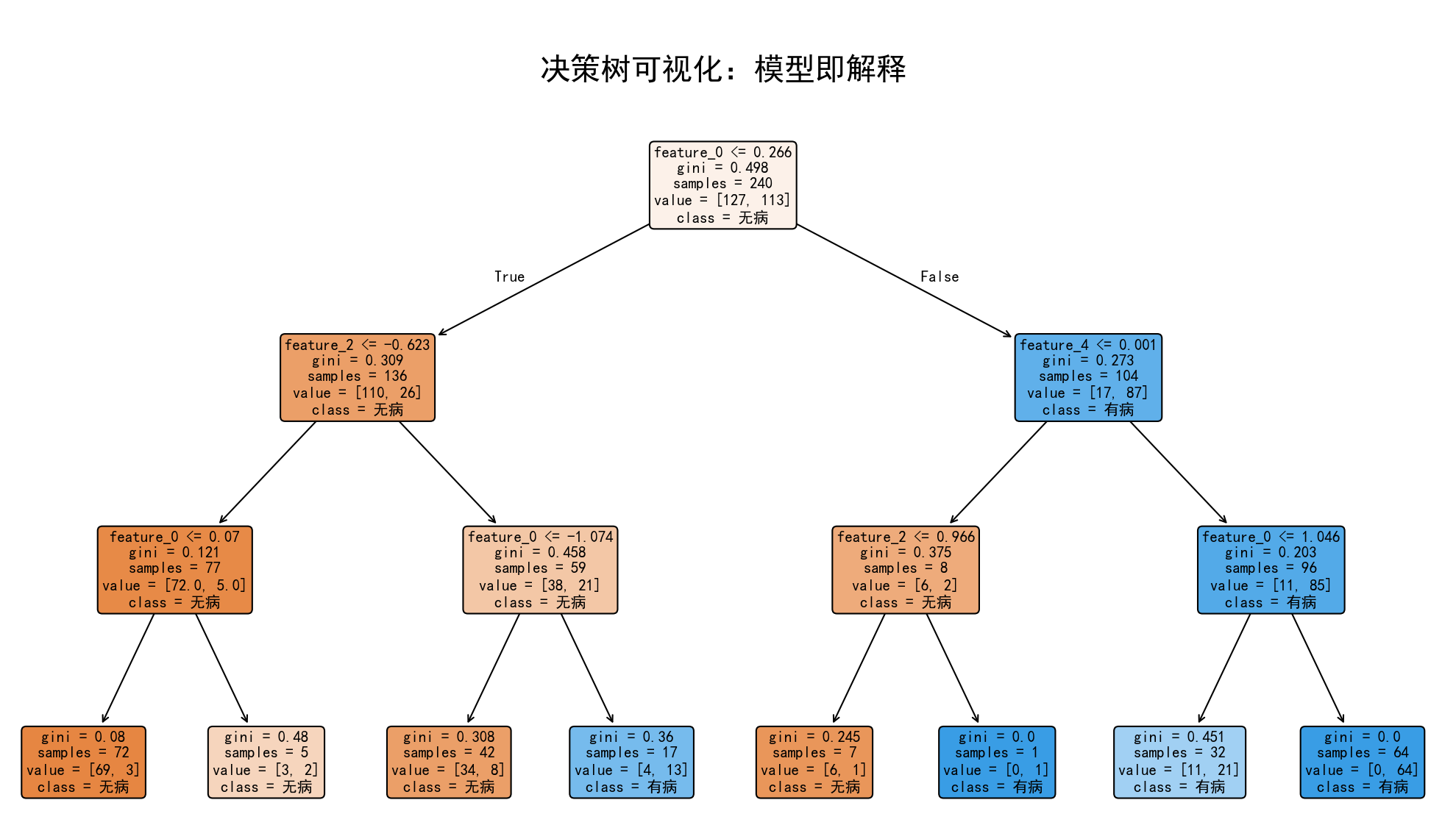
运行代码后,你会得到一张非常直观的决策树图。你可以沿着任意一条从根节点到叶节点的路径,将其翻译成一条清晰的规则。
例如,从根节点向左走的第一条路径可能可以解读为:
如果
feature_2<= -0.735,并且feature_1<= -0.543,那么模型预测该病人“无病”(class=0),这个判断基于 XX 个样本,其中绝大多数是“无病”类别。
这就是“事前解释”的强大之处:决策逻辑一目了然,没有任何黑箱成分。
三、冰山之下:简单的因果分析
模型解释性告诉我们**“什么(What)”——哪个特征重要。但它通常不能告诉我们“为什么(Why)”——改变这个特征是否导致**了结果的改变。
3.1 相关性 ≠ 因果性
这是数据科学中最重要、也最容易被混淆的概念。
经典例子:夏天,冰淇淋的销量和溺水人数都同时上升。
- 相关性分析会告诉你:冰淇淋销量和溺水人数高度正相关。
- 错误的因果推断:禁止卖冰淇淋可以减少溺水。
- 正确的因果分析:存在一个“共同原因”(混杂变量)——“天气炎热”。天热导致人们既想吃冰淇淋,又想去游泳(从而增加了溺水风险)。
机器学习模型非常擅长发现相关性,但如果把这种相关性误当作因果关系来指导决策,后果可能是灾难性的。
3.2 如何进行简单的因果分析?
真正的因果推断是一个复杂的领域,但我们可以了解其基本思想和工具。Python 中有一个强大的库 dowhy 可以帮助我们。
因果推断的四个步骤:
- 建模 (Model):用先验知识画出“因果图”,明确你认为变量之间是如何相互影响的。
- 识别 (Identify):根据因果图,找到一个有效的估计方法来计算我们关心的“因果效应”。
- 估计 (Estimate):使用统计方法(如回归、匹配)来计算出因果效应的大小。
- 反驳 (Refute):进行敏感性分析,检查你的结论是否稳健,排除潜在的偏见。
简单的说,我们不再是直接将 X 和 y 扔进模型,而是先定义一个关于“世界如何运作”的假设(因果图),然后用数据来验证和量化这个假设中的某条路径。
四、总结与心得
Day 21 的学习,让我对模型可解释性的理解从一个“点”(SHAP)扩展到了一个“面”,甚至窥见了冰山下的“体”(因果推断)。
-
没有银弹,只有取舍:在“事前解释”(如决策树)和“事后解释”(如SHAP)之间,存在一个经典的性能 vs. 可解释性的权衡。选择哪种方法,取决于具体的业务场景。在高风险、强监管领域(如金融、医疗),“白箱”模型可能更受青睐;而在效果至上的领域(如广告推荐),我们则可以放心使用“黑箱”+“事后解释”。
-
解释的层次不同:SHAP/LIME 告诉我们模型**“看到了什么关联”,而因果推断试图告诉我们“世界真实的运作方式是怎样的”**。前者是关于模型的,后者是关于现实的。作为数据科学家,必须时刻警惕两者的区别。
-
打开了一扇新的大门:今天的学习让我意识到,XAI 和因果推断是两个充满深度和价值的领域。它将技术与业务、统计与决策紧密地联系在一起,是数据科学家从“建模工程师”走向“领域专家”和“决策顾问”的必经之路。
感谢 @浙大疏锦行 老师的课程设计,它不仅仅是在教我们使用工具,更是在引导我们建立一个完整、深刻的数据科学世界观。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)