Knowledge Completes the Vision(AAAI 2026)
本文提出MERGE框架,首个针对新闻图片标题的多模态实体感知检索增强生成方法。该框架包含三个创新组件:1)构建实体中心的多模态知识库(EMKB),整合文本、视觉和结构化知识;2)采用假设性字幕引导的三阶段思维链机制实现细粒度跨模态对齐;3)通过检索驱动的多模态知识整合实现精确视觉-实体匹配。实验表明,MERGE能有效补充缺失细节,提升标题生成质量。该方法通过动态构建知识图谱和分阶段对齐策略,显著改
研究方向:Image Captioning
论文全名:《Knowledge Completes the Vision: A Multimodal Entity-aware Retrieval-Augmented Generation Framework for News Image Captioning》
1. 论文介绍
本文引入了MERGE,首个针对新闻图片标题的多模态实体感知检索增强生成框架。MERGE构建了一个以实体为中心的多模态知识库(EMKB),整合了文本、视觉和结构化知识,实现了丰富的背景检索。它通过多阶段假设-标题策略改善跨模态对齐,并通过图像内容引导的动态检索提升视觉实体匹配效果。

MERGE引入了三个关键创新:
1)信息增强:MERGE构建了一个以实体为中心的多模态知识库,整合了命名实体、图像和结构化背景知识,补充文章中缺失的细节。
2)细粒度跨模态对齐:MERGE引入了假设性字幕引导的多模态对齐,该机制采用了一个三阶段的思维链(CoT)提示机制。这种结构化的推理过程使得视觉线索与文本细节之间能够准确匹配,包括细微差别。
3)精确的视觉-实体对齐:MERGE采用了检索驱动的多模态知识整合,动态检索多模态证据并从多模态知识库构建背景知识图谱,能够在视觉上区分相似的个体并保持精确的实体关联。
2. 方法介绍
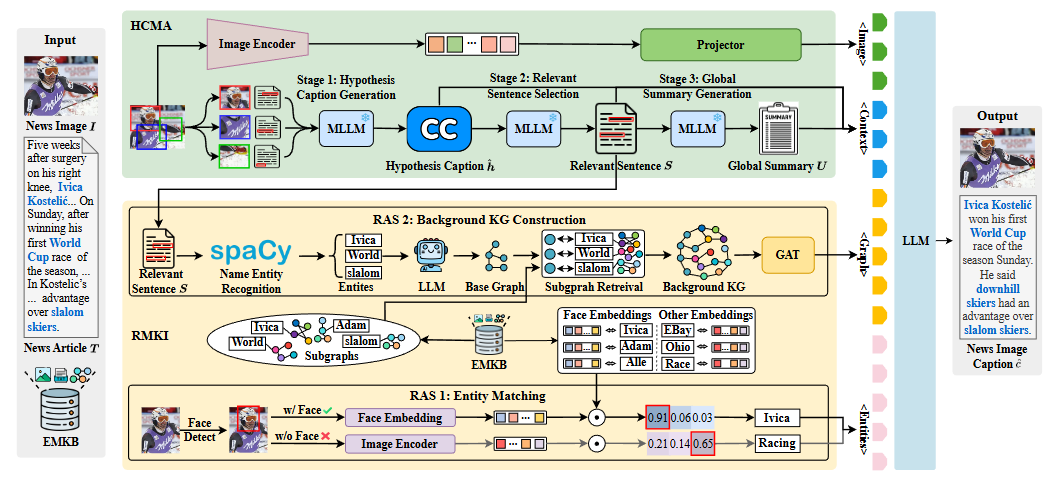
MERGE包含三个核心组件:
1)以实体为中心的多模态知识库(EMKB):整合命名实体、图像和背景知识,以消除信息差距并加强上下文关联。
2)假设字幕引导的多模态对齐(HCMA):通过一个三阶段的思维链(CoT)提示过程,在视觉和文本输入之间实现细粒度的句子级对齐。
3) 检索驱动的多模态知识整合(RMKI):通过匹配视觉线索与实体,并从EMKB动态构建背景知识图谱,提高视觉-实体关联的准确性。
2.1 以实体为中心的多模态知识库构建
![]()
是第
个实体,{
}是其关联的图像,
表示背景知识,
是其结构化知识子图。

1)实体提取和图片收集:实体从数据集中提取,图片为维基百科获取
2)背景知识的获取:从网上获取
3)结构化知识子图构建
2.2 假设性字幕引导的多模态对齐
通过三阶段的CoT提示过程来解决句子级别的跨模态对齐问题:
第一阶段:假设标题生成,该标题包含了输入图像I和文章T的视觉和文本线索。
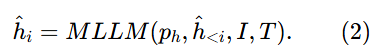
第二阶段:选择相关句子,从T中选择最相关的句子S来精炼上下文。
![]()
第三阶段:全局摘要生成。
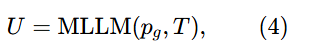
通过整合S的本地语境和U的全局语境,HCMA生成精确且语境丰富的字幕。
2.3 检索驱动的多模态知识整合
1)实体匹配
RMKI通过两个途径将图像I中的视觉线索与EMKB B中存储的实体进行匹配:
面部图像:使用InsightFace将I中检测到的面部编码为特征向量F。RMKI计算每个向量y与EMKB B图像中的面部向量
的余弦相似度:
![]()
从中匹配的实体随后被提取出来形成实体集E。
非人脸图像:对于没有人脸的图像,RMKI利用CLIP的图像编码器生成视觉嵌入。使用余弦相似度来识别最接近的匹配图像,从而得出实体集E。
2)背景知识图谱构建
命名实体识别:使用spaCy在S中识别命名实体
关系抽取:使用带有专门提示的大型语言模型(LLM)来抽取
中实体间的关系R,形成基础关系图
子图检索:对于每个实体,从EMKB B中检索知识子图
并将它们聚合成一个集合Φ。
图集成:将子图Φ集成到e中,去除重叠的节点和边,以生成最终的知识图谱G。

2.4 caption生成
给定一张图片I和一篇新闻报道T,MERGE的步骤如下:首先,HCMA生成一个假设标题 ,选择相关句子S,并创建一个全局摘要U。其次,RMKI将图片I与实体E匹配,并构建一个背景知识图谱G。最后,采用InstructBLIP进行标题生成,并用一个四层图注意力网络来编码图谱G,整合多模态输入:
),以生成最终标题
:
![]()
交叉熵(CE)损失:
![]()

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)