【推荐系统】基于Generator-Evaluator架构的重排模型概述
1、Generator-Evaluator重排模型在淘宝流式场景的实践【2023】
Generator-Evaluator重排模型在淘宝流式场景的实践【2023】
GE架构介绍
GE架构由generator+evaluator两部分组成,在强化学习中generator也可以称为actor(agent),evaluator也可以称为simulator。在我们的实现中,generator是基于pointer network的seq2seq生成式模型,它负责基于一个输入序,端到端地输出一个新的重排序。
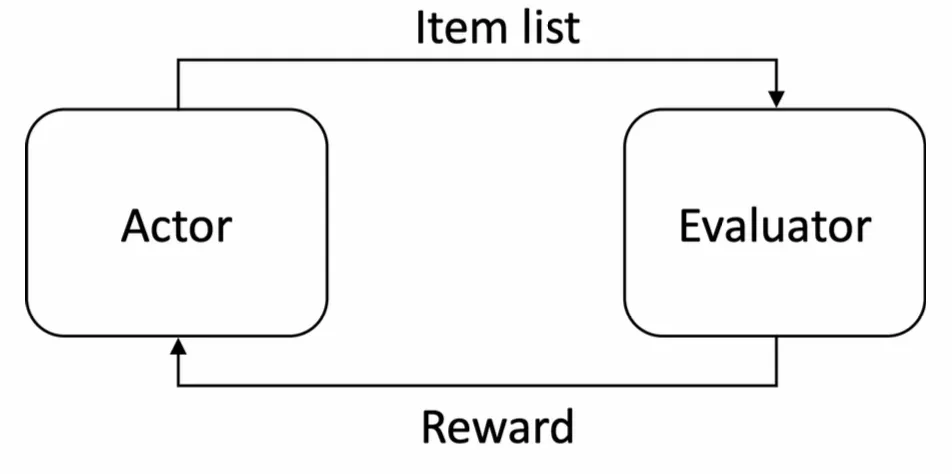
EG架构的重排模型相比于监督学习的重排模型的一个优势是,generator不需要使用监督学习的方式训练,人为指定一个“最优序”作为label供模型学习,generator不需要学习生成我们人为给定的排序结果,因为人为给定的结果肯定是次优的。如果有一个evaluator模型能够近乎模拟线上用户的真实反馈,那么generator通过强化学习的方式,对着这个evaluator模型给出的反馈去训练是更合理的,不断尝试最大化获得的reward。如果数据中有一些非贪心排序范式的排序结果能够获得更好的线上指标,generator也会趋向生成这种模式的排序结果,从而突破贪心排序的范式,生成一些创造性的排序。
EG架构的重排模型,还有一个优势是能够方便地实现店铺打散、曝光宽度、曝光占比控制等业务目标,因为常用的贪心排序范式的模型,模型在打分的过程是不知道最终曝光的序列是怎样的,因此没办法端到端控制商家连续重复、某些类型曝光占比不足等问题,只能在按照模型分排序后做后处理。而EG架构这种生成式重排,generator模型在打分的过程中是直接生成最终排序的,因此在生成的过程中能够感知到生成的序列中商家是否重复、某些类型的曝光占比是否不足等问题。
Generator
Generator是一个encoder-decoder结构的模型,它的主要作用是从M个候选item中生成出长度为N的序列,其框架图如下所示。encoder负责对输入序进行编码,得到每个商品编码后的embedding,以及输入序整体的embedding,decoder会将输入序整体的embedding作为初始state,使用RNN一步一步地生成出最终的排序结果。
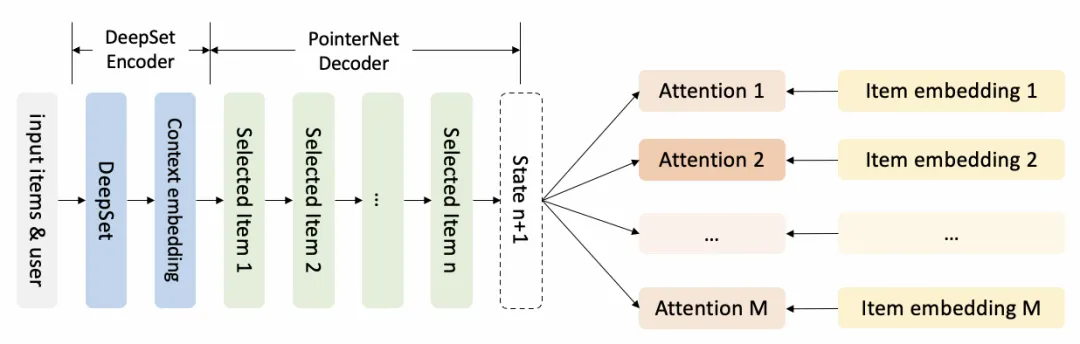
Encoder
在把候选商品集合输入给encoder之前,首先需要进行特征增强和embedding lookup的操作。一个商品的增强特征来源于候选集合,比如商品的历史点击率在整个候选集合中的排名。这是一个非常有效且简单的方式,告诉模型每个商品与它所在的候选集合之间的关系。然后ID特征会被转成实值embedding以方便数值计算。
Encoder是DeepSet的结构,因为它对输入商品的顺序不敏感,其结构图如下所示。DeepSet对于复杂的应用场景可能是更合适的encoder结构,因为要想找到一个好的混合了文本、图片、视频的初始输入序列是不容易的,差的初始输入序可能会伤害重排模型的效果。
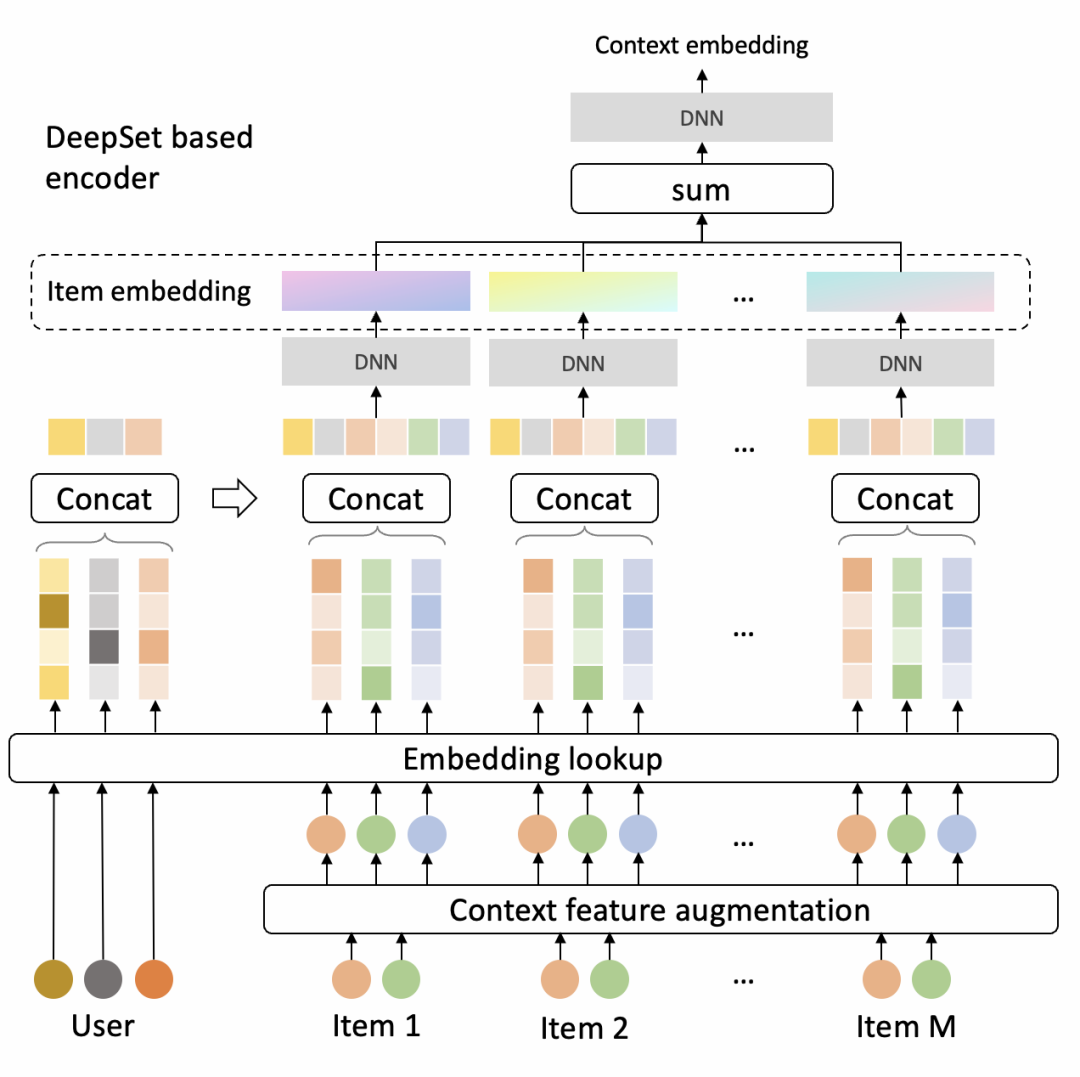
Encoder的输入的User和候选商品集合,输出是一个中间状态的Context embedding。
Decoder
Decoder是基于Pointer Network的结构,其结构图如下所示。它每次会从候选集合中选择一个商品,然后立即更新上下文信息,然后选择下一个商品。
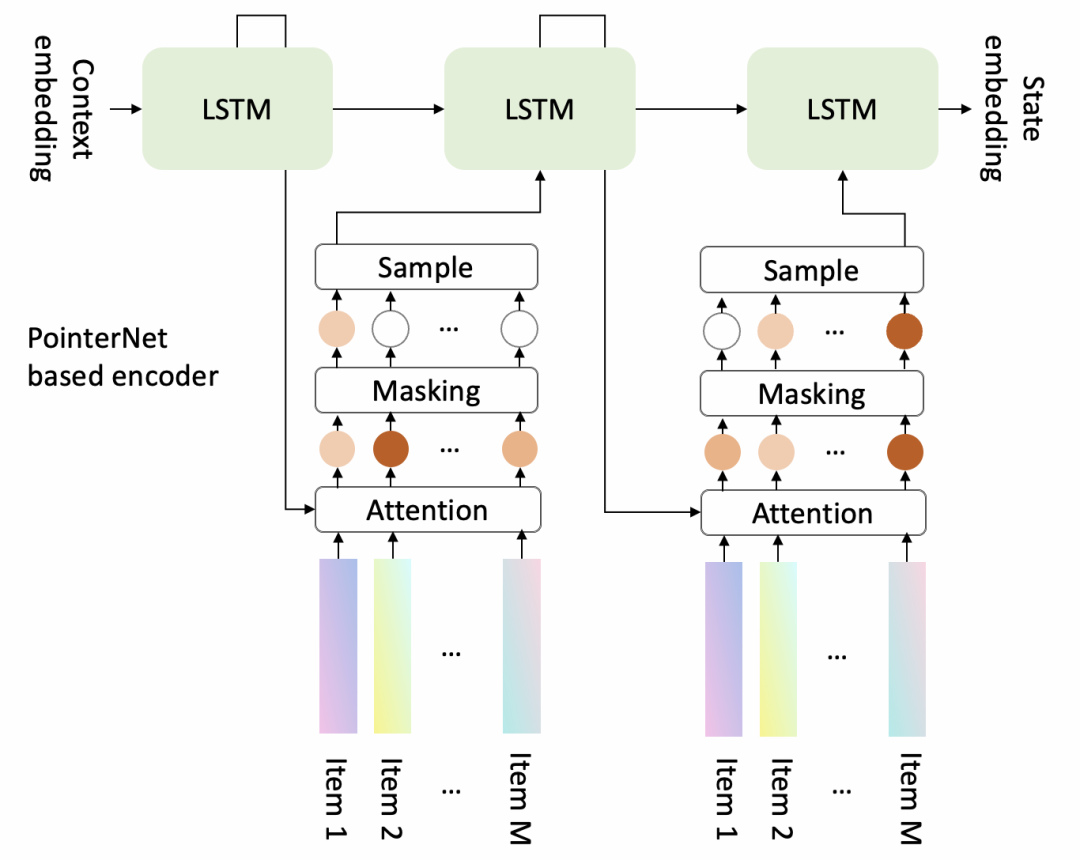
Trick:对计算出的attention概率分布会采用Masking机制,主要有两点原因。首先,一个在前序步骤中已经被选出的商品不应该再被选择了,所以已被选出的商品的attention值需要被mask成0。其次,业务规则可能会要求模型在结果列表中的一些特定位置放一些特定的商品。因为一个顾客可能是通过点击一个trigger商品来到当前推荐场景的,所以需要把trigger商品强制放在推荐列表的最前面,以便提供更多关于trigger商品的信息给用户。在这种情况下,除了trigger的所有商品的attention值应该被mask成0。
同时,generator使用一个采样机制选择商品是至关重要的,因为这会让generator在相似的state尝试不同的action,最终能够帮助generator找到更优的序列生成策略。最简单的选择是Thompson Sampling,会依据每个商品mask后的attention值成比例地选择商品。一个更好的选择可能是Random Network Distillation,倾向于选择一个在之前相似的state下很少被选择的商品。
Evaluator
Evaluator包含了一系列的效用函数,一个效用函数U是从一个商品序列到一个实数的映射,表示在某种视角下这个序列的质量分数,在相关工作中这通常被描述为一个任务。
一些效用函数通常来自于业务规则以及好的排序结果应该满足的先验知识,比如商品多样性,这些效用函数有解析公式,能够被直接计算出来。其他的一些效用函数,比如用户对序列的交互概率,则不得不需要使用模型预测,模型会通过离线数据训练出来。模型一旦训练好后,会被用作为预先定义好的效用函数。
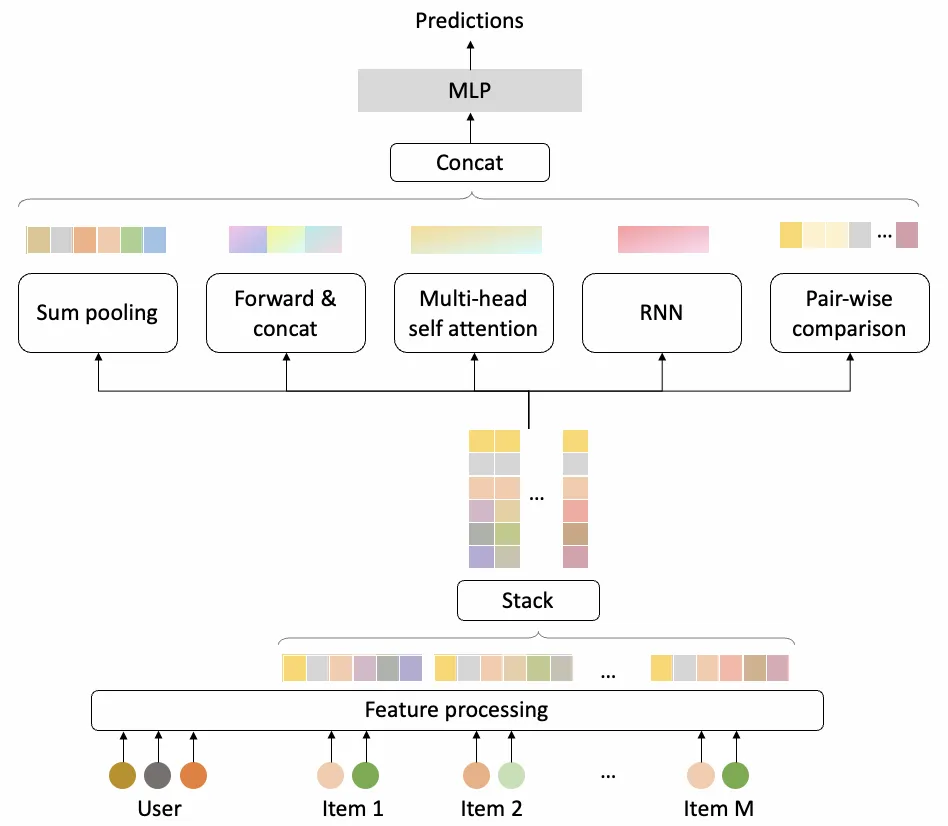
Evaluator的模型结构如上图所示。在经过与generator一样的特征处理后,会被5个聚焦于商品序列不同方面的模型channel处理,5个channel的输出结果会被concat起来,然后通过一个MLP转变成最终的预测分。
模型训练方法
在generator训练之前,会首先使用纯正的监督学习方式充分训练evaluator。目前对于evaluator,我们使用经典的交叉熵损失函数训练得到一个分类模型:
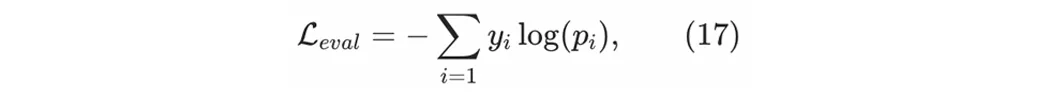
其中是一个类别的one-hot label,
是对应类别的模型预测值。evaluator可能会预测生成的推荐结果列表是否会引导到某种特定的用户交互行为,比如点击以及各种交互的兴趣强度。
GE架构中的generator不会按照监督学习的方式,最大化某一个人为指定的输出序列的联合概率,而是像强化学习一样,generator通过一些带有随机性的探索机制,尝试让自己的生成结果能够最大化获得的reward。
这个reward,既包含evaluator对生成序列点击率的模型预估分,又包含一些规则性的判断生成序列是否满足各项业务规则的评分,然后将这些分数通过加权求和的方式,融合到一个最终整体的reward上,这个reward是一个序列整体的reward,然后generator的训练目标就是不断最大化这个reward,手段是根据reward正负和大小调节生成具体序列的概率。(E的训练目标是最大化整体的reward)
对于generator的训练,我们使用一个基于REINFORCE的方法。REINFORCE是一个经典的policy gradient算法。在强化学习中,policy是一个state到所有可能action的概率分布的一个映射,期望能够最大化total reward。简单来说,policy告诉我们在给定state下应该采取哪个action。

基于RL训练G的好处
强化学习训练方式的两个好处:
1、不需要显式地指定label,在重排场景下,就是不需要显式地指定模型应该输出怎样的重排序。因为我们根本不知道最优的重排序是什么,或者是有可能存在较多种优秀的重排序,没法知道哪个更好。这种情况下,我们就不需要去让模型模仿监督信号,而是要直接面向reward也就是最终效果进行优化,只要是能够获得更高reward的行为,就是更好的行为,有可能找到比贪心排序更好的组合更优的排序结果。
2、由于这个reward R是环境给予的反馈,在实践中就是evaluator给予的反馈,它跟generator的模型参数是没关系的,因此我们调整generator的模型参数,去最大化这个最终获得的总reward R,是不需要对reward R算gradient的。也就意味着,如果假设reward是一个函数产生的,就算产生reward的这个函数是不可导的也没关系,因为我们不需要对产生reward的这个函数进行求导,就算它是一个黑盒,我们不知道它的计算式子也没关系,只要我们拿到它最终的值就可以了。因此这个reward函数可以任意复杂,既可以是模型预估分,也可以是根据业务规则计算出来的分数,方便融入各种业务要求,因此非常适用于我们这个业务规则约束较多的场景。
实践应用
G模型的输入是混排后分数最高的20个候选item,这20个item中会包含不同类型的供给,它们会作为一个集合送进G模型(也就是actor)打分,然后G生成一个长度为10的重排后的序列。 训练结束后,我们只将训练好的序列生成器G上线,E不上线。
E是判别式模型,给每个序列打一个分,希望用户反馈更多的序列的evaluator分数比用户反馈更少的序列的evaluator分数要高,因此E离线评估看的是auc指标。在淘宝实验中,E的auc大概为0.75左右。
G的离线评估指标是better percentage,含义是所有请求的样本中,generator生成的重排序获得的evaluator score,比线上真实曝光序的evaluator score更高的比例。在实践中,generator的better percentage通常能达到70%+左右,也就是说如果E的评判打分是靠谱的,那么大概有70%的请求,G能够生成出比之前的线上曝光序更好的序列。
2、重排序在快手短视频推荐系统中的演进【2022】
快手短视频推荐
快手推荐系统包括了传统的召回、粗排、精排、LTR多目标排序、多目标预估等技术环节。而在这些模块之后的技术环节为重排序,主要包括手机端和服务端两部分。服务端通过传统服务器部署重排服务,包括序列重排、多源内容混排、多样性模块。端上部分包括端上重排模型和端上重排策略两部分。
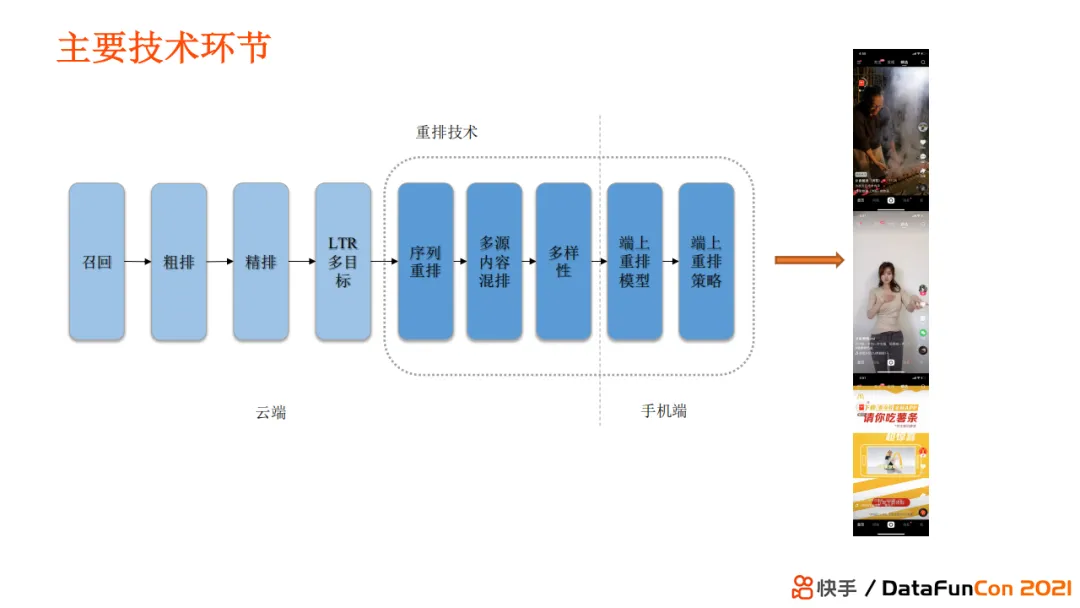
重排阶段处理的问题包括:
-
整个序列的价值并非单 item 效果的累计,如何使得序列价值最大化;
-
沉浸式场景中,什么是好的多样性体验,业务意志如何体现;
-
同一个场景下越来越多的业务参与其中,如何恰当地分配流量和注意力,达成业务目标和整体最优;
-
如何更加及时、更加细微地感知用户状态,及时调整我们的推荐策略和内容。
序列重排
序列重排基于两个认知。
首先,上下文对当前 item 造成了重要影响,即视频的交互或者表现指标的好坏不仅仅由 item 自身决定,还由上文内容决定。比如当前推荐视频是有关英语学习的,但如果前一个视频是一个小姐姐跳舞的视频,那么看完上文视频再去看学英语的视频可能性较小。但如果上一条视频是一首很燃的英语歌曲,那很可能用户会因为听不懂歌曲内容,更愿意观看下一条有关学习英语的视频。
其次,相同的内容不同的序的表现也是天差地别的。比如第一条视频是将军对于台海危机的言论,但如果下一条视频推荐了小姐姐视频那就相当不合时宜,因为这两个视频没有连贯性,推荐效果较差。那如果下一个推荐视频是比较燃的音乐,再在后面推荐小姐姐跳舞的视频,那么这时候内容的连贯性就较好,用户不会觉得突兀。
我们希望得到一个好的推荐序列使得序列价值最大,那么就会涉及到好的序列如何去定义的问题。我们认为好的序列完成度很高,整个序列的正向交互程度很高,用户具有高粘性,有看完视频后下刷的意愿,且序列在内容上具有序贯属性。
传统方案具有以下缺陷:
-
精排单点打分缺少当前 item 其他内容的信息,单点的预估存在不准确的问题;
-
贪心的打散方案只能解决内容散度的问题,缺少局部最优到整体最优路径;
-
MMR,DPP等是在优化目标上加入散度项,并非是序列表现最佳。
所以重新定义序列重排的目标(序列发现和序列评价范畴):
-
第一,需要有 transformer 或者 LSTM 把上游内容信息融入当前内容信息中;
-
第二,优化目标是序列的整体表现情况,而不是单item的表现;
-
第三,需要重排模型有持续发现好的排列模式的能力。
序列重排架构
快手短视频序列重排整体结构采用了GE范式,G从top50中生成模式丰富的序列类型,E评价召回的序列的整体价值。
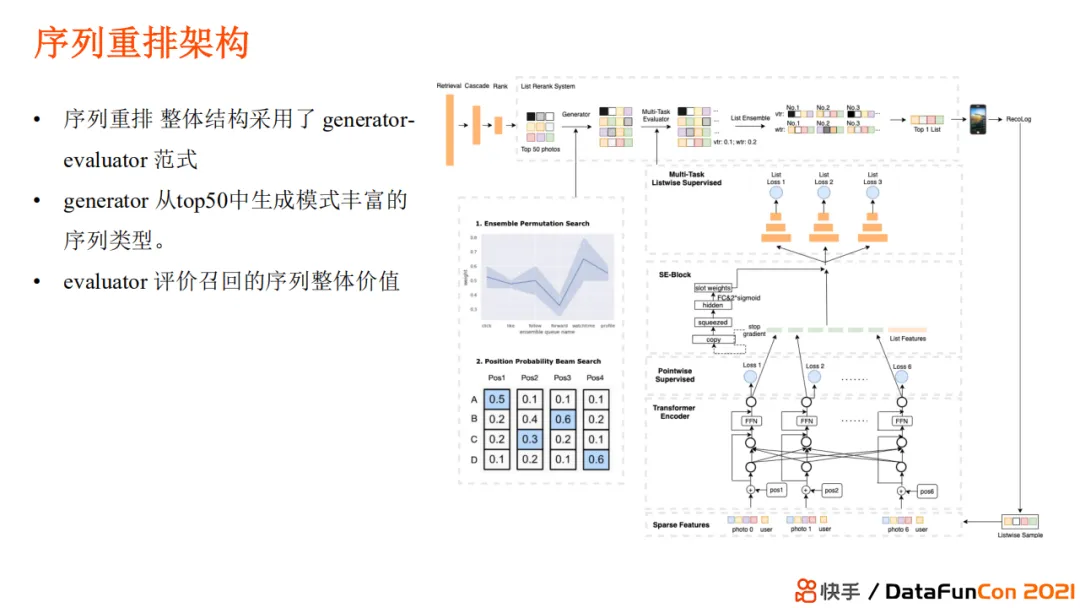
序列生成
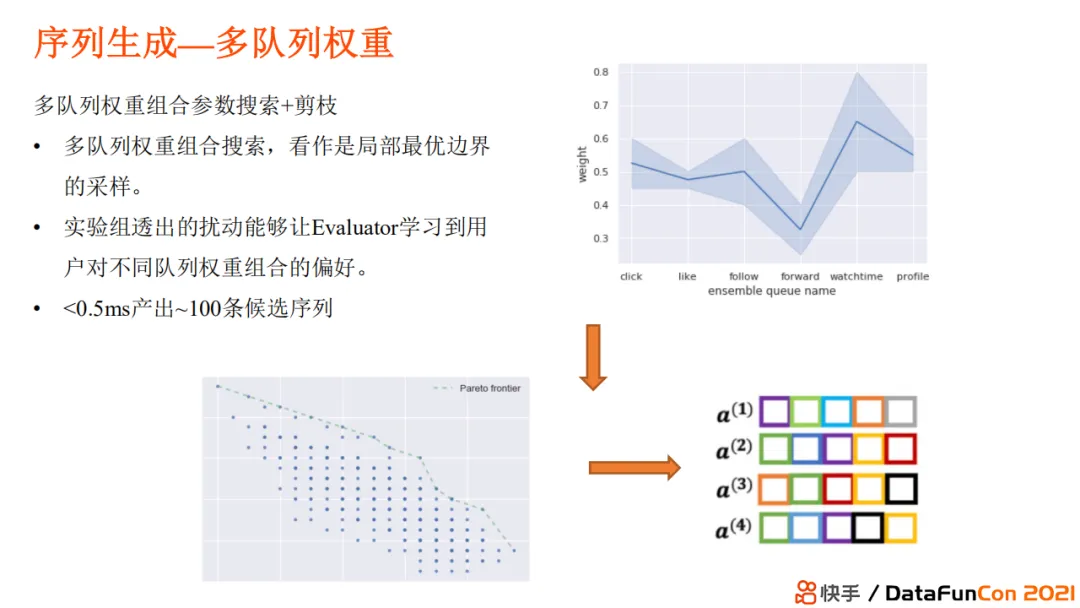
序列生成的方法最容易想到的是将得分高的排在序列头部,得分低的排在序列尾部,即使用贪心的算法生成序列。其中BeamSearch是大家常用的实现方法,它顺序地生成每个位置的视频,选择方式是根据该位置前序的item选择模型或者策略预估最优的topk视频。
第二种序列生成的方案是多队列权重。原先我们在线上的队列是使用手工调参或者使用自动调参工具进行调节。但是线上参数并不是每时每刻都是固定的,需要在不同状态下使用不同的参数,比如某段时间需要推荐沉浸时间较长的视频,而另外一段时间需要低成本高获得感的视频内容,那么前者需要更多关注观看时长的目标,互动可以进行折算;而后者需要互动、点赞率较高。所以我们不能使用固定的参数,而是进行协同采样。采样过程从原理上来讲是不断地逼近Pareto最优曲面,进而得到不同的采样点,形成不同的序列。
其他的一些序列生成方法有MMR多样性召回、Seq2slate召回,还有其他一些规则性的或者启发式的召回策略等。
序列生成算法总结:BeamSearch、多队列权重、规则类(MMR+Seq2slate)等。
Evaluator
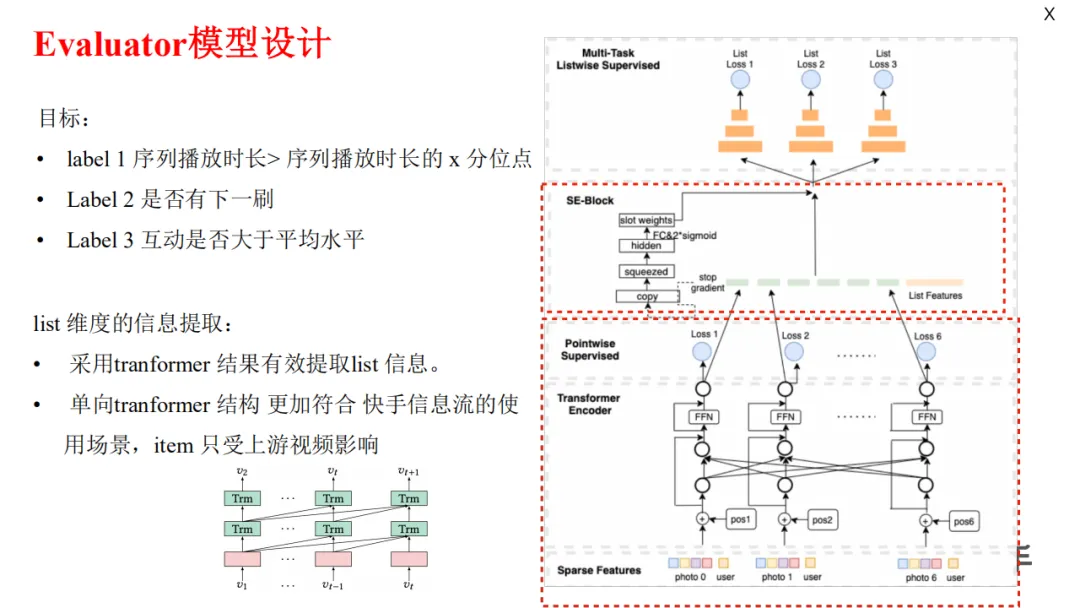
生成不同的序列后就需要对序列进行评价,评价目标有三个:
-
第一,序列播放时长要大于某一个分位点;
-
第二,序列播放完毕后用户要有下刷动作;
-
第三,用户互动率能够大于平均互动水平。
Evaluator使用单向transformer模型,这是因为用户其实是自上而下的刷视频,下游视频信息对上游视频没有增益,只有上游信息会对下游内容有影响。单向transformer模型可以降低计算复杂度,提升模型的稳定性。在单向transformer之后,我们使用一个辅助模型去做embedding表达,最后依次预估整个序列的得分。这一序列重排模型在线上产生了非常多的累积收益。
多元内容混排
在混排之前,业务是通过固定位置的形式来获取流量,平台不会考虑业务价值或者用户需求。这就会带来以下三个问题:
-
用户角度,偏好的业务和非偏好业务等频率出现;
-
业务方角度,流量中既有偏好的用户也有非偏好的用户,降低了业务服务效率;
-
平台角度,资源错配导致了浪费。
那么混排的问题就可以被定义为:将各个业务返回的结果恰当地组合,得到综合价值最大的返回序列。

最简单的办法就是对每个业务结果进行打分并据此进行排序。例如LinkedIn的一篇论文就是使用打分之后排序操作来实现的,他们为这一方法做了很完善的理论分析。将优化目标设定为在用户价值体验大于C的前提下最优化营收价值。如果用户的广告价值大于用户的产品价值的时候,那我们就去投放广告内容;否则我们就去投放产品内容。这一算法实现很简单,即在满足用户体验约束以及两个广告间隔约束下,哪一部分价值高就推送哪一部分内容。
但上述方案有一个弊病,即它包含了很多强假设。首先,它的目标是最大化营收价值而不是最大化综合价值。第二,这一算法假设单一item的价值在不同位置和不同上下文的情况下保持不变,这和序列化建模的认知不同。第三,它认为广告对用户后续体验及留存等没有影响,但是如果从单一刷次来看放置广告的价值一定比不放广告的价值大,可是它并不是最优解,因为它会对后续的用户体验产生影响。
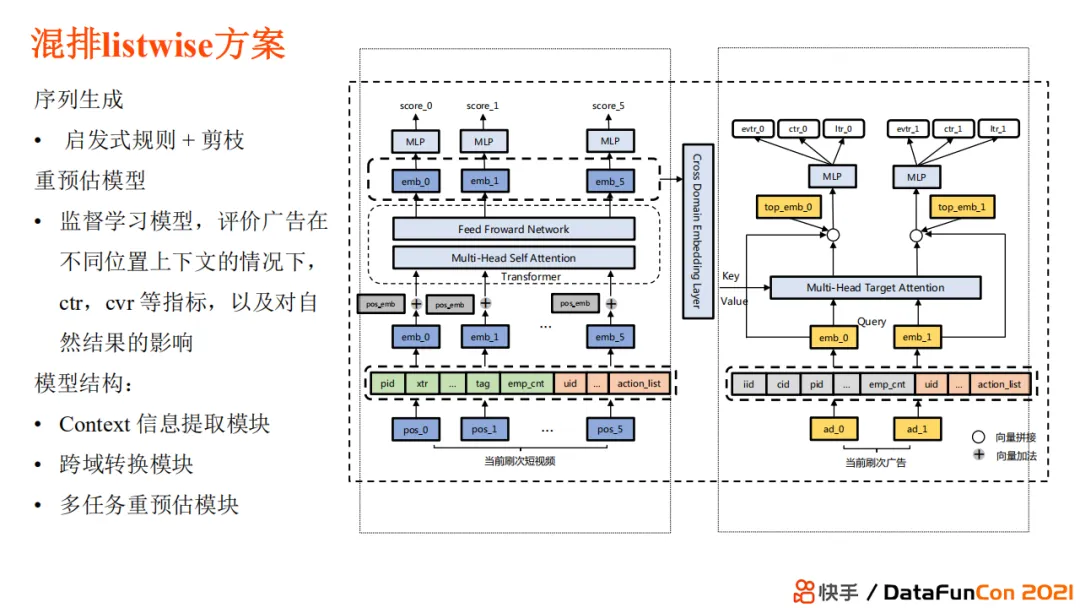
首先介绍一下混排listwise方案。这一方法秉承了序列生成和序列评估的过程,我们对每一种放置方案都会进行预估,衡量其对排序结果的影响,包括广告在不同位置不同上下文的情况下ctr/cvr等指标以及对自然结果的影响。模型的第一个模块是context信息提取模块。这一模块我们重新预估了视频内容的表现情况。第二个模块是跨域转换模块,因为广告和自然内容是跨域的。第三个模块会对广告的内容进行多任务重预估,比如衡量它的曝光率、cvr、ctr 等。有了这些预估指标后,我们就可以得到一个最佳价值序列。

接下来介绍混排RL方案。在不同状态下,RL可以在不同策略中选择一个最佳策略来达到长期体验和近期收入的平衡。原先的模型采用的是固定策略,即在不同状态下的广告放置、广告营收和结果体验的配比都是固定的。但这一做法其实是有问题的。
我们定义状态为用户在一个 session内的下刷深度、曝光内容、广告交互历史、内容交互历史、上下文信息以及本刷的内容。动作空间则包含如第一条、第二条广告放置在哪一位置等。当然动作空间中需要满足业务约束。最终的结果既要考虑营收价值,又要考虑用户体验价值以及长期留存的内容。
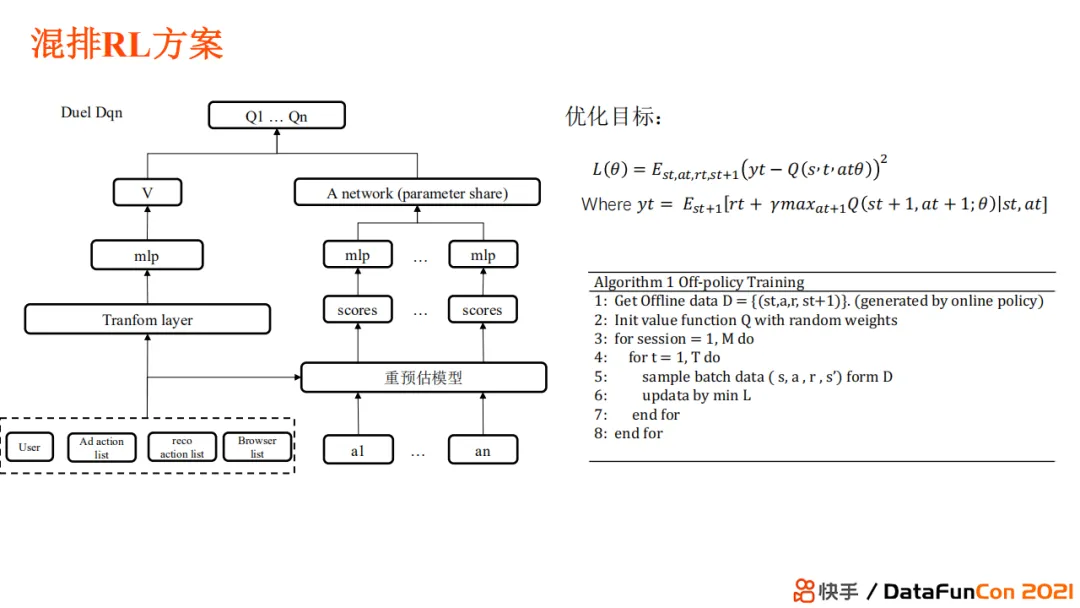
Action空间是一个十分稀疏的空间,我们最终选择了Duel Dqn的方案来实现。首先,V网络评估用户当前的满意程度,这使得模型可以在不同的用户状态下选择不同的放置策略。但由于放置策略十分离散,它的解空间相当大,那么我们需要对离散空间dense化。我们的dense化不是通过模型去做的,而是通过之前使用的重预估监督模型来实现。通过监督模型,我们就可以知道这个action下每个位置放置的内容可以带来多少的用户体验和商业价值。之后,我们可以使用一个神经网络对不同的action进行打分。我们的优化目标是每一步选择能够达到最终的总和价值最大,reward是长期价值和近期价值的组合。
我们采用了两段式训练范式,首先使用online-policy的方式,先将模型部署上线生成online-policy 下的数据,作为off-policy的训练数据放入回放池。之后,我们使用off-policy来训练Dqn模型。经过优化后,在线上模型针对不同的用户状态得到的Value,可以选择使得Q值最大的策略,最终得到线上的预估结果。
3、基于GE架构的重排总结
先概括一下重排模型一个主要作用:相比于前序模型,重排模型的一个显著区别是显示建模item之间的相互影响,称为context information。
GE架构由生成器网络(Generator)和评估器网络(Evaluator)两部分组成。G负责从M个备选item中构建长度为N的序列,E则包含多种评估函数,能够从转化率、多样性、流量分配等多个维度对生成的序列进行综合打分。然后,G会根据E的反馈结果进行强化学习训练,更新网络参数,实现推荐效果的迭代提升。总结就是:
- 生成器Generator:负责“怎么排”,从候选集合中生成完整序列;
- 评估器Evaluator:负责“好不好”,仅对最终序列打分,依据是真实用户行为(CTR/CVR)。
在上述淘宝的应用中,G使用了一个encoder-decoder结构的模型,encoder负责对输入序进行编码,得到每个商品编码后的embedding,以及输入序整体的embedding,decoder会将输入序整体的embedding作为初始state,使用RNN一步一步地生成出最终的排序结果。
个人理解,G不限于使用模型,也可以使用各种规则代替,如MMR截断长度为N的序列等。当然,模型化的G可以解决策略类的G难以维护的烦恼。这样GE框架会输出两种范式:
- 使用真实的曝光样本训练Evaluator,再通过强化学习训练Generator,然后通过BeamSearch等算法生成排序结果。
- 使用真实的曝光样本训练Evaluator,再使用DPP、MMR等作为Generator的生成序列,Evaluator选出打分最好的序列作为结果。
训练流程
模型训练流程主要分为两个阶段:生成器Generator和评估器Evaluator分别训练。
第一阶段,先对评估器模型Evaluator进行独立训练,使其能够准确地对推荐序列进行多维度打分和业务指标评估。
第二阶段,在加载已训练好的评估器参数后,利用评估器的反馈作为强化学习的reward信号,进一步训练生成器模型Generator,优化其序列生成策略,从而提升整体推荐效果。推断时生成器并行生成K个最优序列,评估器对候选序列做整体打分,最后返回得分最高序列。
评估器Evaluator
Evaluator是一个监督学习模型,其目标是通过多任务交叉熵Loss对用户在曝光商品上的多种行为进行联合建模,优化评估器对序列的综合打分能力,从而提升推荐列表的个性化和业务转化效果
Evaluator模型用的是标准 loss。比如想训练这一页推荐结果用户会不会有点击这样一个点击率预估模型,会用一个01的 label,用标准的交叉熵loss去训练 evaluator。充分训练evaluator,然后锁死,再开始训练Generator。
通常,Evaluator是一个离线预训练好的CTR/CVR模型,具体的网络结构灵活设计,如 DeepFM、DIN均可。Evaluator参数冻结,不参与联合训练。
Evaluator的输入来自真实的曝光样本,输出可以是用户特征+商品序列(含位置、品类等上下文信息),Evaluator的输出可以是预估点击率,即 reward。通过使用真实的曝光样本来完成Evaluator的离线训练,评估器的目标是“尽可能准确预测真实反馈”。
生成器Generator
Generator以序列列表整体的reward最大化为目标,利用E的分数作为强化学习reward信号,训练生成器不断优化生成策略,得到最优的重排生成序列。Reward的设计是模型比较关键的部分,可以根据业务需求自行设计。
Generator的输入可以是精排topM候选商品集合,这里直接使用精排的结果队列截断topM即可,其输出为长度为N的商品序列(M选N)。
训练Generator的loss有两部分内容,一部分是reward相关的,一部分是模型生成这个list的 probability。给定一个user和candidates,generator会生成一个序列,这个序列喂进evaluator或者是reward function,可以拿到一个reward的评估。然后减去baseline也就是减去线上真实曝光的那个list,因为离线训练的数据是通过log获取的,所以知道当时的线上真实曝光序列是什么,这个序列也进入reward function拿到一个reward值,对它们进行一个减的操作,希望生成高于线上或者优于线上序列的结果。
第二部分是乘一个probability项,给定user和candidates,计算generator生成这个序列的 probability 。训练的核心思想就是reward得分高的序列应该有更大的概率被生成。
Reward
GE框架下Reward主要用于驱动模型训练。
Generator负责生成一个序列,Evaluator会对这个序列做出评估,评估结果会作为reward反馈给Generator,这样Generator就会根据reward的大小来调节生成序列的策略。也就是说如果模型看到了一个大reward分的序列,当以后再遇到相似的情况下,模型就会以更大的概率生成当前这个序列。
Reward 有两个非常突出的优势:
- 一是reward无需 label。生成一个序列后,evaluator只要能对当前这个序列做评估就可以了,至于最优序列和其reward是什么无需要知道。
- 二是reward无需可导。在信息检索领域,通常用NDCG来评估推荐的结果,但训练时绝大部分工作不会直接优化NDCG指标,一个重要原因就是NDCG不可导没有办法计算梯度,没法做深度模型训练。但reward不需要可导,从而可以在reward里边非常灵活地加入各种各样的计算。比如店铺打散,结果序列中店铺的个数就是一个很好的reward,虽然它显然不可导。
假设业务场景的输入是一个user、m个candidate item,分别是C1到Cm,一个reward function Rw。Rw是把w当做参数,进行线性求和,求和的项是w乘以utility function U。U 可以是点击、冷启内容的占比等各种各样的业务目标,w是业务目标的融合权重。我们希望output能满足argmax Rw这个条件,给出user以及目前的候选集,在候选集里边的item拼出来的任意序列中,挑选Rw最大的标星序列,记为Lw*。模型的任务就是在这个序列存在的前提下找到 Lw*,如果有多个那么返回任意一个都可以。完成这个任务的最基本的思想就是训练一个Generator,当给定一个item候选集的时候,Generator跑一遍正向运算,然后会给出一个最优序列。充分训练之后,就会认为它生成的这个序列趋近于 Lw*。
参考文档

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)