大模型面试必备01——GPT参数计算、BPE分词算法
所有参数=$$词向量维度 × (词表大小 + 窗口长度) +(4D^2 + 8D^2 + 5D)*注意力层数 $$,D为词向量维度代码计算看7、代码计算。(计算复杂度和宽度是平方关系,和层数是线性关系)
一、GPT3参数计算
参考:
-
https://zhuanlan.zhihu.com/p/612389702
-
https://zhuanlan.zhihu.com/p/638679519
-
https://www.lesswrong.com/posts/6Fpvch8RR29qLEWNH/the-gpt-3-architecture-on-a-napkin
论文地址:Language Models are Few-Shot Learners
参考视频:LLM Parameter Counting(15分钟快速掌握)
图解计算GPT的参数量:
主要分成四个部分,分别计算每个部分的参数量
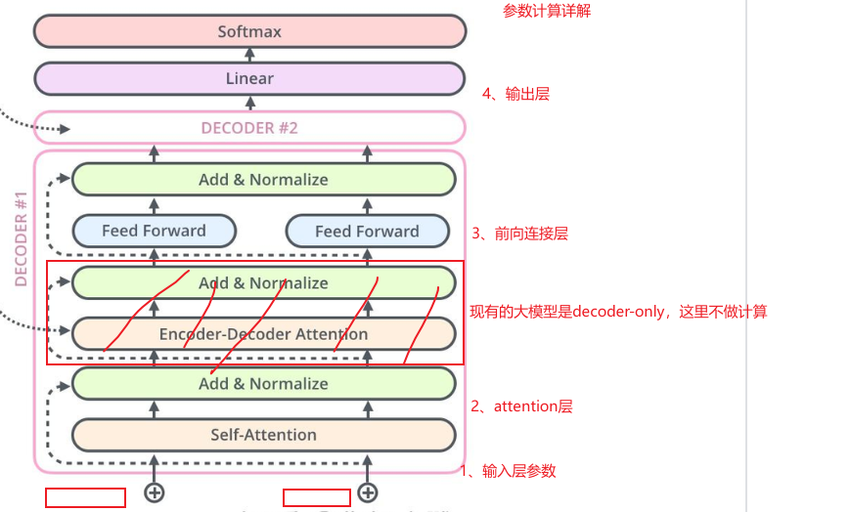
1、输入层参数
输入层参数包括两部分:embedding编码层参数+位置编码层参数
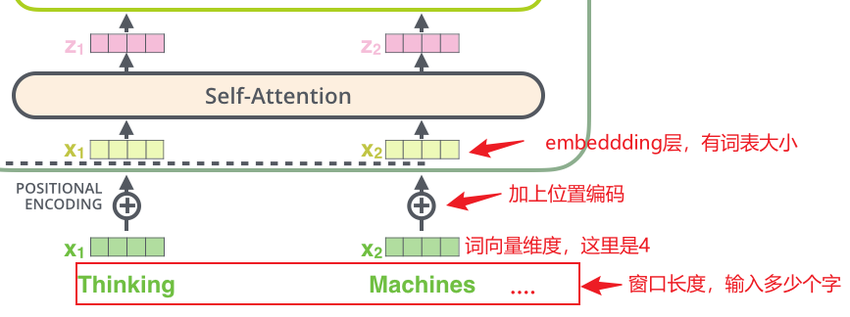
-
输入层的组成
在Transformer架构(如GPT-3)中,输入层的目的是将离散的文本(token序列)转换为连续的向量表示,通常包含以下两部分:
-
Embedding编码层:将每个token映射为词向量。
-
位置编码层:为每个位置添加独立的位置信息。
-
Embedding编码层的参数量
-
公式:
词向量维度 × 词表大小 -
原因:
-
词表大小(V)是模型中不同token的数量(例如英文的3万词)。注:这里是把所有的单词或其分解的子词全部算到这个词表中,这里相当于把整个特征空间全部算进去了。
-
每个token对应一个词向量,向量的每个维度都是一个可学习的参数。
-
权重矩阵形状为
[V, D](D是词向量维度),参数量为V×D。
-
-
示例: 若词表大小为50,000,词向量维度为512,则参数量为
50,000 × 512 = 25,600,000。
-
-
位置编码层的参数量
-
公式:
词向量维度 × 窗口长度 -
原因:
-
窗口长度(N)是输入序列的长度(例如单次输入的文本长度)。
-
每个位置需要一个独立的位置编码向量,与词向量维度一致。
-
权重矩阵形状为
[N, D],参数量为N×D。
-
-
示例: 若窗口长度为64,词向量维度为512,则参数量为
64 × 512 = 32,768。
-
-
输入层总参数量
输入层总参数量=embedding编码层参数+位置编码层参数
= 词向量维度 × 词表大小 +词向量维度 × 窗口长度
= 词向量维度 × (词表大小 + 窗口长度)
2、attention层参数
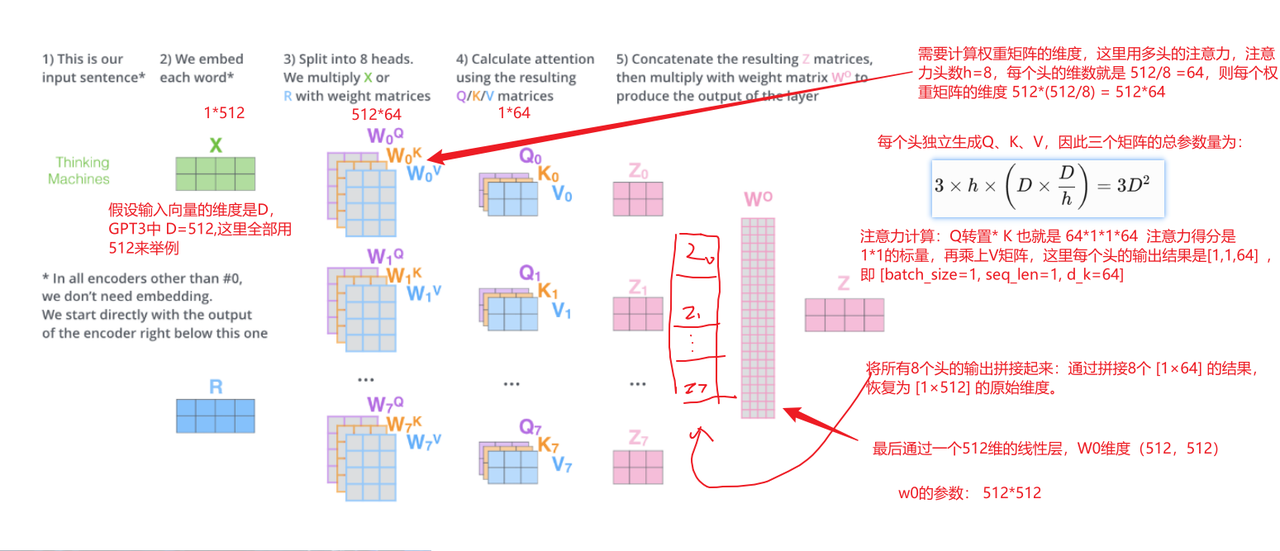
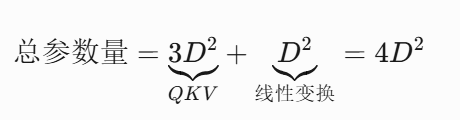
Attention层总参数量:假设省略偏置项,D=词向量维度
3、前向连接层



4、输出层
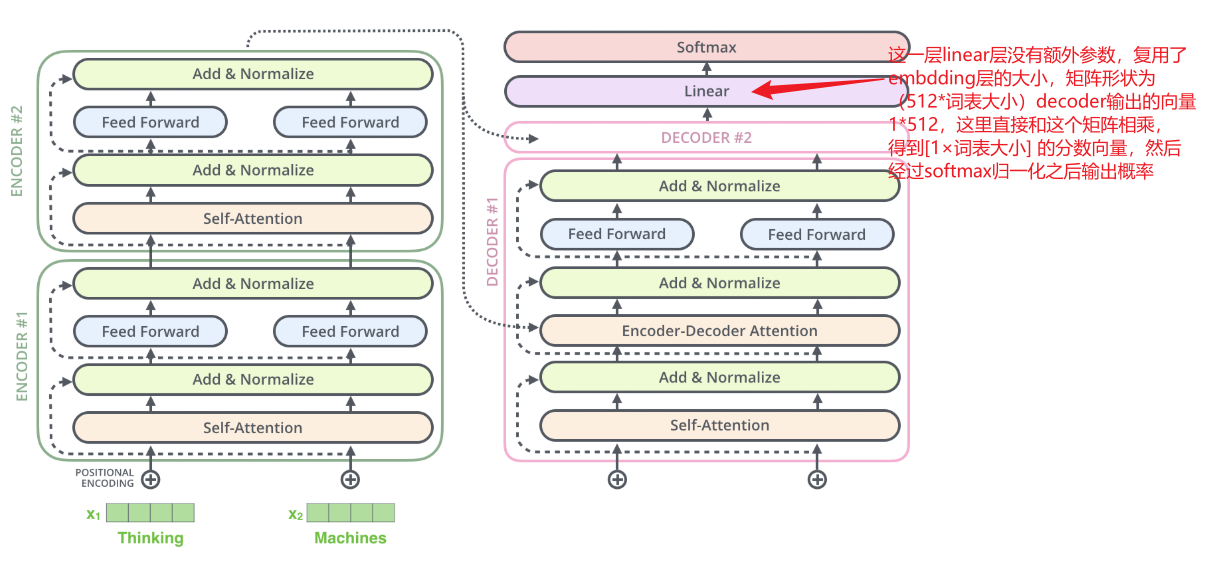
补充softmax过程:

5、参数总结:
所有参数=$$词向量维度 × (词表大小 + 窗口长度) +(4D^2 + 8D^2 + 5D)*注意力层数 $$,D为词向量维度
代码计算看7、代码计算。(计算复杂度和宽度是平方关系,和层数是线性关系)
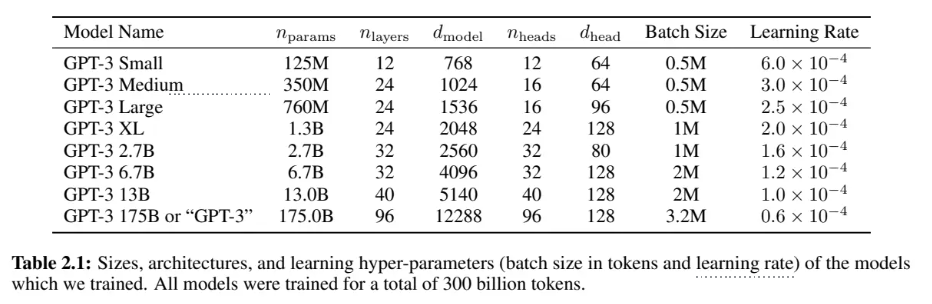
6、GPT3模型参数计算:
论文中的参数表:
7、代码计算
def gpt3_params(d_model, n_layers, vocab_size):
# 单层参数计算
attn_params = 4 * d_model**2 # Q/K/V + 投影矩阵
ffn_params = 8 * d_model**2 + 5 * d_model # FFN扩展维度为4d_model
layer_params = attn_params + ffn_params
# 总参数
total = n_layers * layer_params + vocab_size * (d_model + 1) # 词嵌入,假设窗口为1
return total // 1e9 # 返回十亿单位
# 输出结果差异分析(实际计算约178B,因未计入偏置项等细节)
print(f"Calculated: {gpt3_params(d_model, n_layers, vocab_size)}B vs Official: 175B")
输出结果:
Calculated: 174.0B vs Official: 175B二、BPE分词算法(词表的构造原理)
优质博客解读:https://leimao.github.io/blog/Byte-Pair-Encoding/
论文地址:https://arxiv.org/abs/1508.07909
2.1 原理
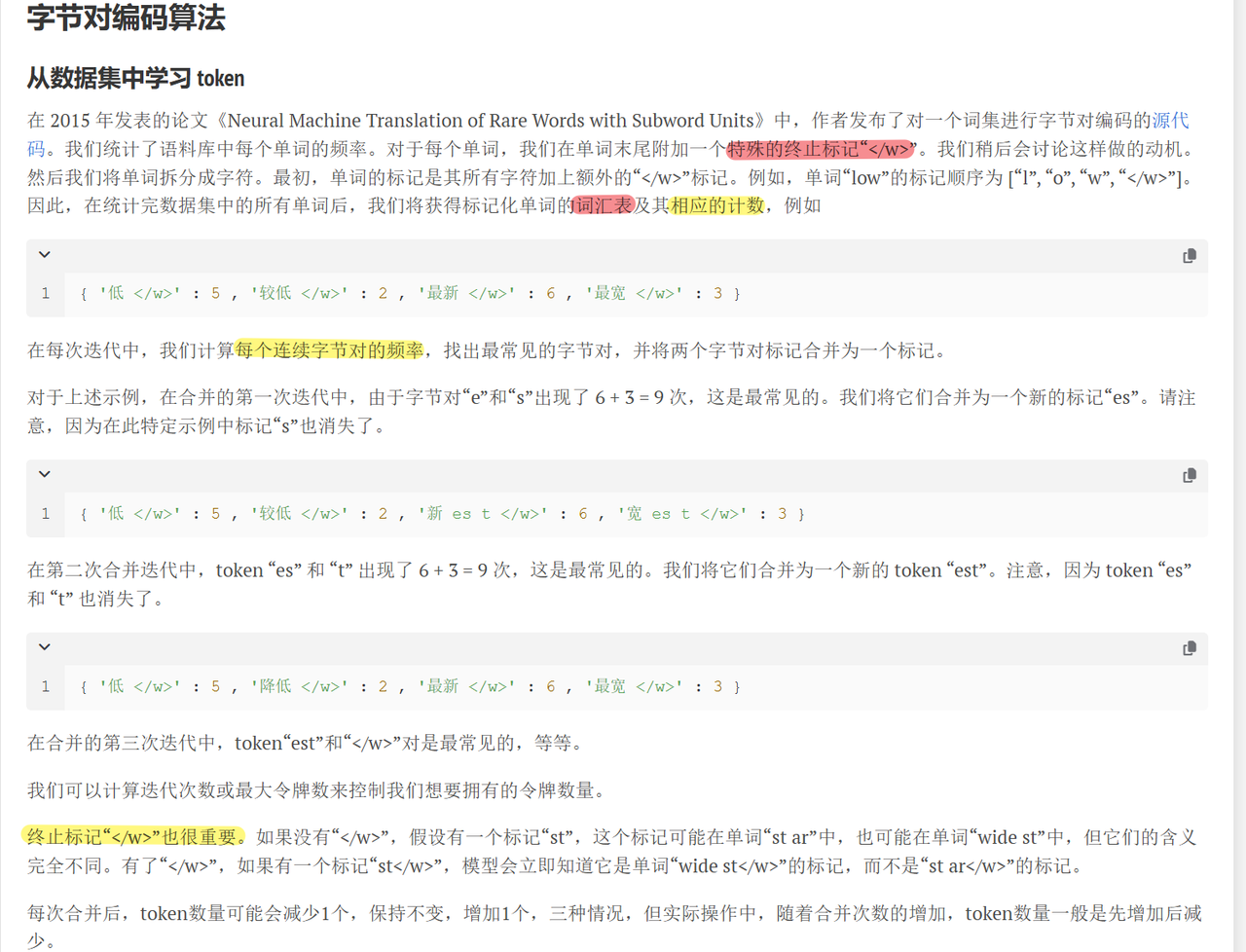


2.2 代码实战
-
使用HuggingFace Tokenizers库训练BPE分词器:
-
from tokenizers import CharBPETokenizer tokenizer = CharBPETokenizer() tokenizer.train(files=["text.txt"], vocab_size=30000, min_frequency=2) tokenizer.save("bpe_model.json")
-
对比WordPiece在BERT中的实现(参考BERT Tokenization Guide)
-
from transformers import BertTokenizer, GPT2Tokenizer # BPE(GPT-2) gpt2_tokenizer = GPT2Tokenizer.from_pretrained("gpt2") print(gpt2_tokenizer.tokenize("unbelievable")) # ['un', 'belie', 'vable'] 🌟 # WordPiece(BERT) bert_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") print(bert_tokenizer.tokenize("unbelievable")) # ['un', '##bel', '##ie', '##va', '##ble'] 🌟如果想进一步代码(深层原理)实现,推荐看【【手写ChatGPT - 1/3】实现BPE Tokenizer】 https://www.bilibili.com/video/BV1SZ42177SH/?share_source=copy_web&vd_source=9fe9e3d550891e4a38f66eead88c8b40

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)