如何教会模型正确检索——DataFlow AgenticRAG Pipeline 教程
AgenticRAG pipeline是一套自动化数据合成系统,旨在解决RAG系统中模型无法稳定使用检索结果的问题。该系统通过原子问答生成模块自动构建多维QA数据,再经问答质量评估模块进行多指标评分,最终产出结构化、可验证的强化学习数据集。该流水线支持从原始文档生成多样化问答对,并通过F1评分和一致性检查确保数据质量,使模型能真正掌握基于证据的回答能力。使用方法包括环境配置、知识库设置和流水线运行
每个做过 RAG 系统的人,都经历过类似的时刻:
明明检索已经优化到极致,但模型的回答依旧“不稳”。
模型有时候能给出漂亮的回答,有时候却莫名其妙地产生幻觉;
面对多段信息,它偶尔能串出推理链,偶尔又像从未见过上下文。

这时问题往往不是检索本身,而是——模型根本没有学过“如何正确使用检索”。
它不知道什么叫“基于证据的回答”,不知道如何判断事实,不知道什么是好答案、什么是坏答案。所以再好的向量库也无法让它稳定发挥。
这就是为什么强化学习开始被引入 RAG:希望模型通过奖惩真正掌握“检索→理解→回答”这一整套能力。
但真正的挑战随之出现:我们没有足够高质量、可验证、结构化的训练数据供模型学习。人工构造不现实;自动生成不可靠;没有评分、没有对照答案,更无法支撑奖励模型。
于是,整个训练流程被卡在了第一步:如何构建一个可靠的“强化学习数据集”?
为此,DataFlow 团队一直在探索研究,设计了一条全自动、可验证、可评估的数据生成流水线,这就是 AgenticRAG pipeline。我们希望让模型从真实文档中自动学到:
“什么是有证据的好答案?”
“什么是不可靠的坏答案?”
“如何合理地使用检索解决问题?”
让模型不再仅仅是“会回答问题”,而是真正掌握基于证据的回答能力。
AgenticRAG 如何工作
AgenticRAG Pipeline 是一套自动化、模块化的数据合成系统,帮助用户从原始文本输出高质量、可验证的问答数据,直接服务于基于强化学习的 Agentic RAG 模型训练。它将数据生成与质量评估统一在同一条流水线上,确保输出的数据既多样又可靠,并可作为后续奖励模型或策略训练的输入。
AgenticRAG pipeline 主要由两个核心模块构成:
-
原子问答生成模块
-
问答质量评估模块
这两个模块在流水线上串行运行,从原始文本出发,最终产出一份结构化、可评分、适用于强化学习的数据集。
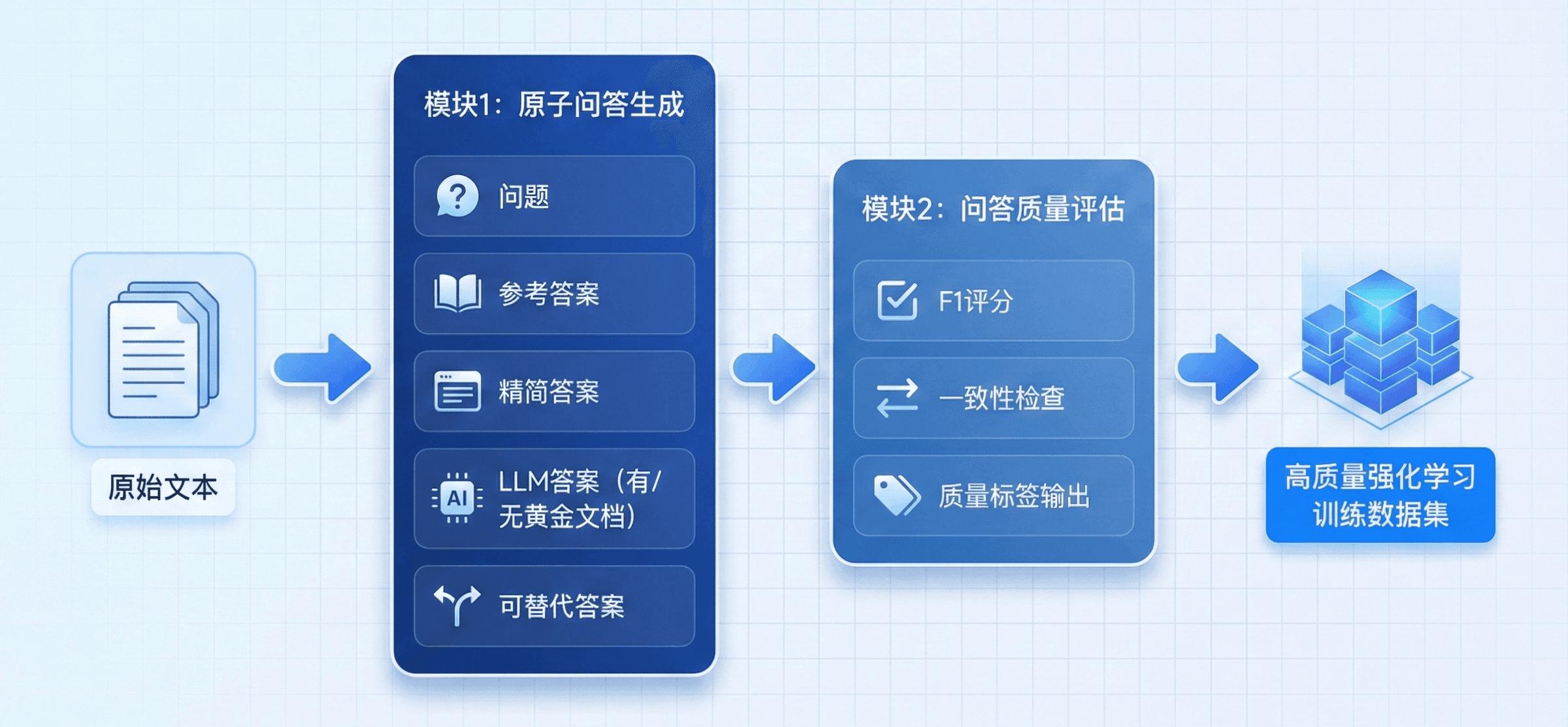
1. 原子问答生成模块
该模块负责从输入文档中自动构造完整的问答结构。每个文本片段将产出一组多维度的 QA 数据,包括:
-
问题:模型基于文本理解主动生成的问题
-
参考答案:与问题语义对应的标准答案
-
精简参考答案:去除冗余后的更精确版本,用于严谨的质量评价
-
有黄金文档时的 LLM 答案:基于原始文档抽取/生成的黄金标准答案
-
无黄金文档时的 LLM 答案:LLM在没有上下文时生成的答案,用于检测模型依赖检索的能力
-
可替代参考答案:语义一致但表述不同的答案,用于强化学习的对比训练
这一阶段的目标是生成尽可能全面、多样、可对照的 QA 数据,让后续的评分、过滤与 RL 奖励更加有效。
2. 问答质量评估模块
生成后的 QA 数据会进入自动评估阶段,通过多指标对答案质量进行评分。主要指标包括:
-
F1 打分器:对精炼答案与黄金文档答案之间重叠程度进行 F1 评估,输出 F1 分数
-
文本一致性检查:评估回答在语义与逻辑上是否忠实于原文
这些评分将作为合成 QA 数据质量、合理性的指标,保障在正确检索下模型能做出有效回答。
如何使用 AgenticRAG Pipeline
在理解了 AgenticRAG Pipeline 的核心理念之后,我们在真实任务中来运行这条流水线。
Step 1:配置环境依赖,下载模型权重
conda create -n dataflow python=3.10
conda activate dataflow
git clone https://github.com/OpenDCAI/DataFlow.git
cd DataFlow
pip install -e .
这一步骤在我们之前的文章中有更详细的演示,在此不过多赘述。配置环境的同时,可以在 DataFlow 的同级目录下先建立一个名为“showcase”的文件夹,用于统一存放所有需要的相关示例。
Step 2:配置知识库来源
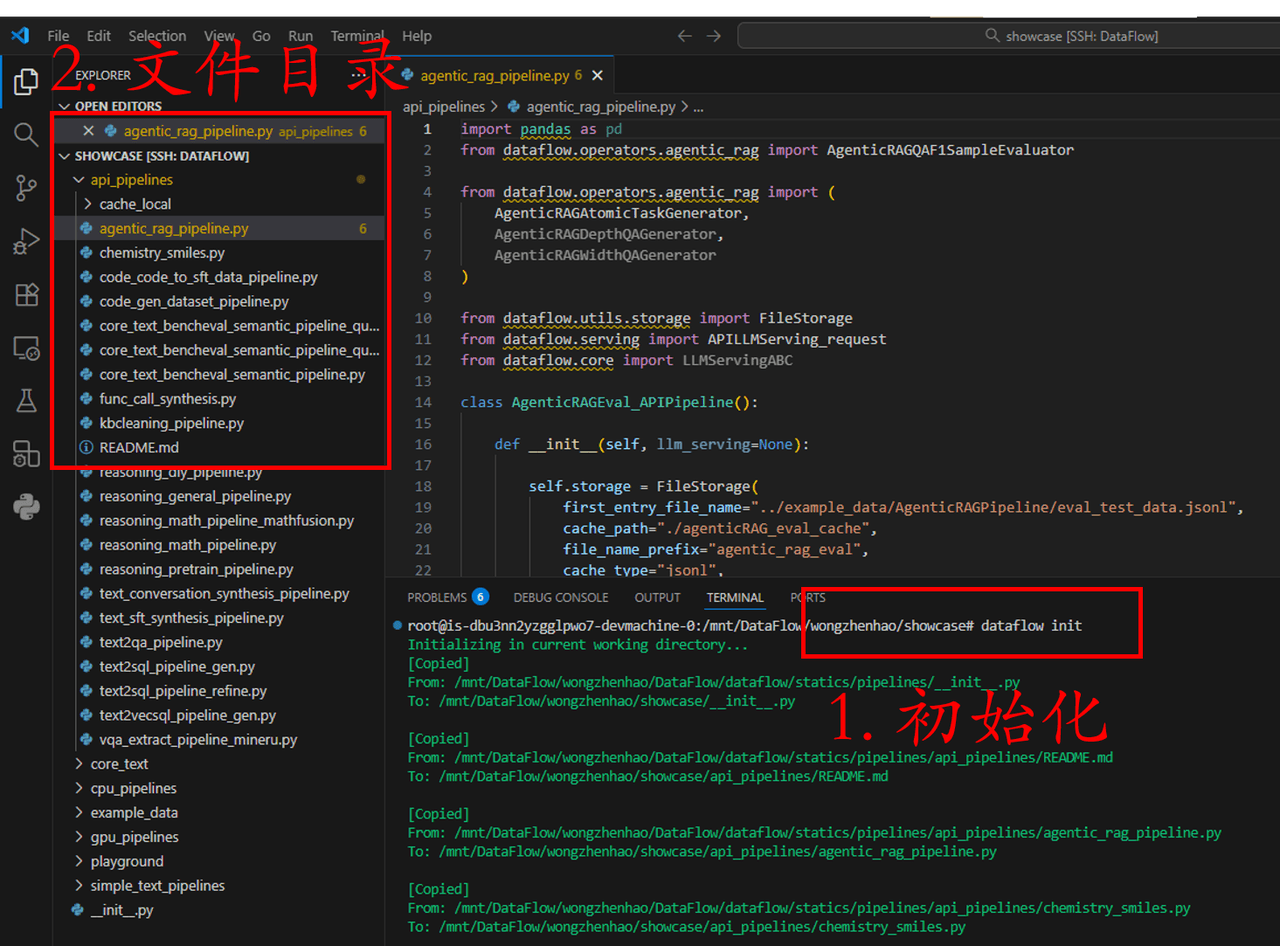
首先初始化工作空间,这是我们在运行所有 DataFlow 相关 pipeline 之前都必须要执行的一步。
mkdir showcase
cd showcase
dataflow init
通过 dataflow int,需要的示例输入和示例程序就会加载到我们刚刚创建的 showcase 目录下。
Step 3:配置 API
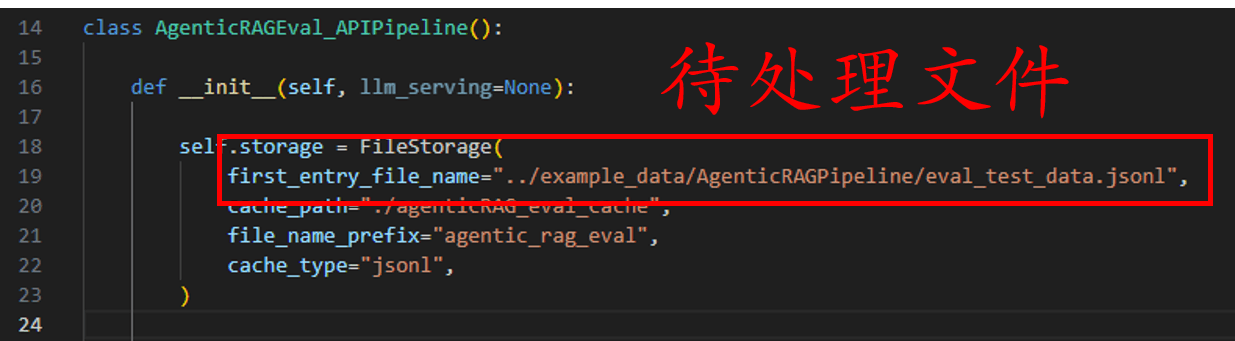
当你已经准备好输入数据时,就需要替换输入数据路径,或可使用提供的示例数据。
随后,我们需要配置API url 和API key。
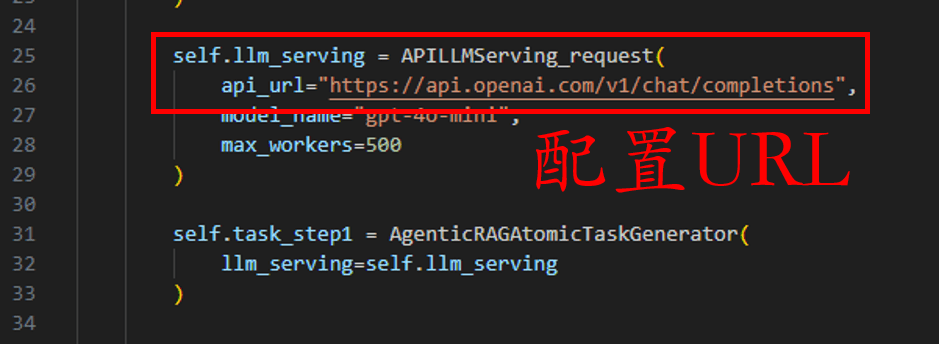
API key需要用户在命令行中填写,如图所示的部分决定了需要将API key写入哪个key,如果没有造成冲突或无额外的需求,则无需修改这个key name,如下所示将自己的API key写入命令行即可:
export DF_API_KEY="YOUR PERSONAL API KEY"
注意:不要忘记在终端中将 API key 设置到环境变量中。
Step 4:运行 AgenticRAG pipeline
设置好后,切换到 API pipeline 文件夹,然后开始运行 AgenticRAG pipeline。
cd api_pipelines
python agentic_rag_pipeline.py
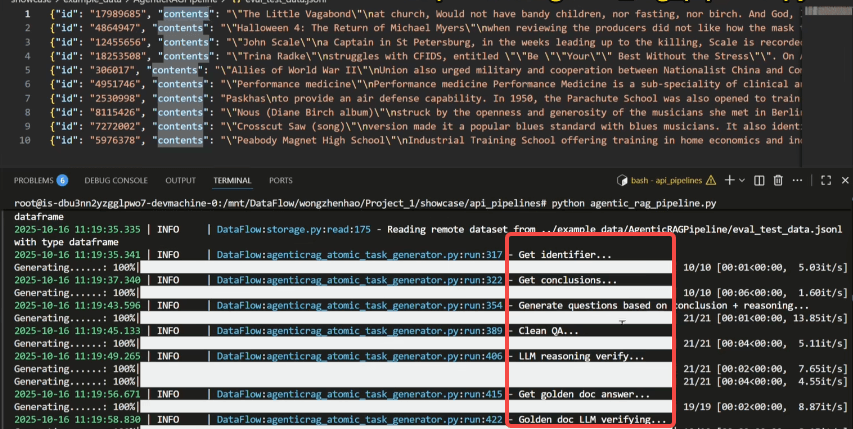
在运行的过程中,可以看到,问答生成算子对每一个输入的内容进行识别提取,输出假设的结论。接下来将这两者结合起来进一步生成问题和相关的答案对,之后进行数据清洗。除此之外,该算子中还提供了大模型分别在有黄金文档和无黄金文档的情况下的推理答案。
为了更好地验证和训练 RL 模型,还会生成更多可选择及可验证的答案,这有助于在 AgenticRAG RL 训练中给出更精确的 reward。
在原子问答任务生成后,接下来就是对 QA 对进行 F1 score 评分。
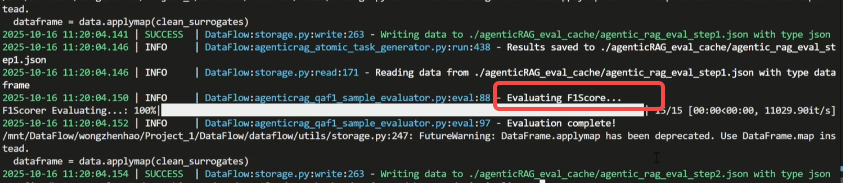
Step 5:查看执行结果
最后我们一起来看下完整的输出。运行结果会保存在运行目录下的 agenticRAG_eval_cache 文件夹中
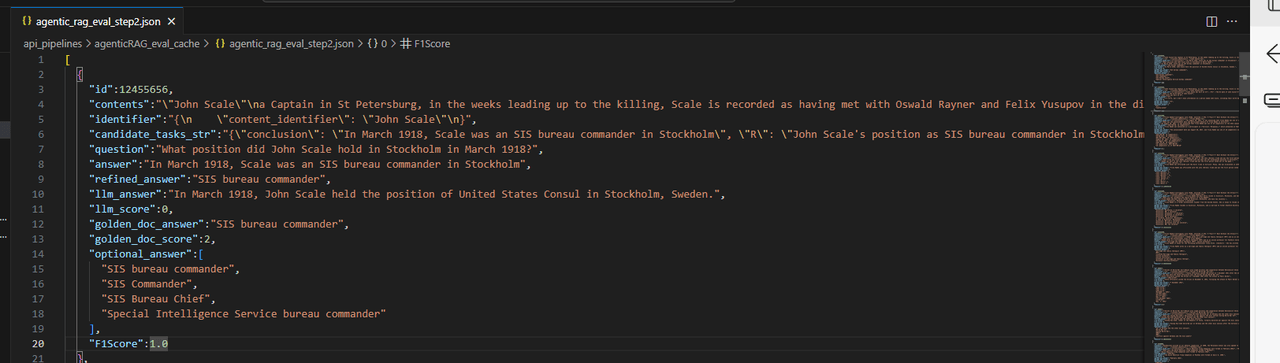
对于输入数据,AgenticRAG pipeline 首先进行了识别提取,结论假设和关联性评估。然后根据这些内容构造了 QA 对和更精炼的大模型生成答案。除此之外,输出中还包括上文提到的黄金文档,以及大模型在有无黄金文档下的问答。
值得注意的是,这里也提供了可选择的可验证性答案,以便在模型训练中更好地给出 reward。
结语
通过 AgenticRAG 数据合成流水线,我们为 RAG 系统提供了一种从底层重塑能力的方式:让模型不仅能学会检索,更能系统性地理解、判断、组织与验证信息。自动化问答生成与质量评估的结合,使我们终于能够大规模构建可用于强化学习的高质量数据集,让 Agentic RAG 模型在真实任务中具备稳定、可控、基于证据的推理能力。
更重要的是,这套流水线并不局限于某一种场景,它天然具备通用性与可扩展性。无论是构建企业内部知识库的问答数据、为奖励模型生成监督信号,还是为生产级 Agentic RAG 打造更可靠的行为策略,这条流水线都能成为核心基础设施。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 25
25 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)