DataFlow 安装部署最佳实践
DataFlow 是一款开源模型数据准备框架,专为大模型自动化、体系化输出高质量数据。本文旨在提供安装部署 DataFlow 的最佳实践。
DataFlow 是一款开源数据准备框架,支持可视化 Pipeline 构建与算子扩展。本文旨在提供一份安装部署的最佳实践指南,帮助开发者快速、稳定地完成环境部署与运行验证。
环境准备
-
系统要求
-
操作系统:Linux / macOS / Windows(推荐 Linux)
-
Python:3.10 及以上版本
-
Conda:用于环境隔离与依赖管理
-
IDE:VSCode 或 PyCharm
-
-
推荐目录结构
workspace/
├── dataflow_env/
├── pipelines/
├── data/
├── cache_local/
└── logs/
(注:只需准备一个空文件夹例如'workspace'即可,目录下的内容pipelines等可通过后续命令自动生成)
安装与环境配置
- 创建 Conda 环境
conda create -n dataflow python=3.10 -y
conda activate dataflow
Tips:
-y参数表示“yes”,即自动确认安装。如果不加也没有影响,在终端运行准备完之后,会提示“是否确定要安装”,此时输入 y 即可。
代码说明:
-
conda create -n dataflow python=3.10:创建名字叫做 dataflow 的环境,指定 python 版本等于 3.10。 -
conda activate dataflow:创建了环境之后使用 conda 激活虚拟环境。
- 安装 DataFlow
pip install open-dataflow
# 或可选
pip install "open-dataflow[vllm]"
这里推荐使用第一条pip install open-dataflow ,即使用 pip 来安装运行dataflow 所需的所有仓库。如有 GPU,可后续再安装带有 vllm 的版本。
- 验证安装
dataflow -v
出现如下提示信息,即表示安装成功:
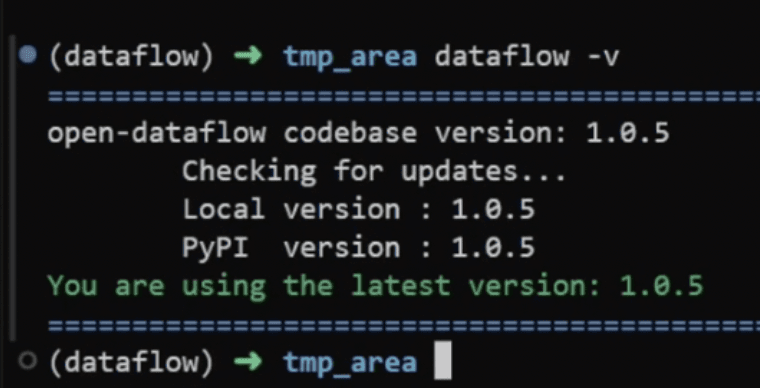
You are using the latest version: x.x.x
注意:不同时期的版本可能不一样,但安装成功的提示信息相同。
项目初始化与运行验证
- 初始化项目目录
dataflow init
执行后将在当前目录生成默认的 Pipeline 示例与配置文件(如下图所示)。
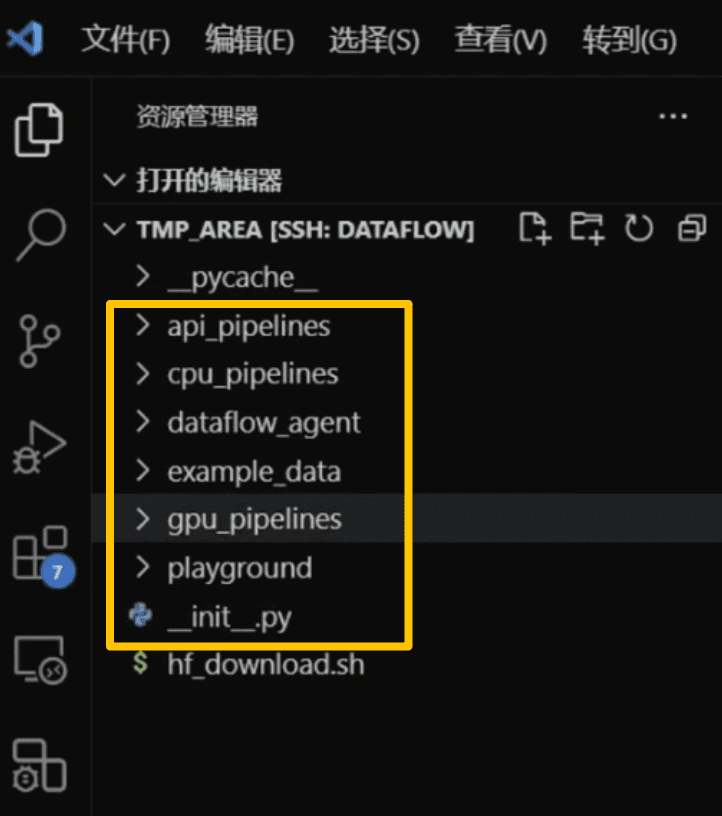
-
运行示例 Pipeline
a. 在工作目录下找到目标 pipeline 文件
b. 配置数据源,数据文件可从 example data 下的对应目录获取
c. 输入命令:python+目标 pipeline 文件路径
python example_data/example_pipeline.py
d. 结果文件将输出到 cache_local/ 目录中。
初次运行时,会有一个 example data 可以给大家直观体验运行的结果。
进阶部署实践
1. 从源码构建
适用于需要修改底层逻辑或调试 DataFlow 框架的开发者。
git clone https://github.com/OpenDCAI/DataFlow.git
conda create -n dataflow_diy python=3.10
conda activate dataflow_diy
cd DataFlow
pip install -e .
-e参数表示以可编辑模式安装,修改源码后无需重新安装即可生效。
代码说明
conda create -n dataflow_diy python=3.10:以可编辑的方式通过源码安装一个新的 dataflow 环境。
2. 验证安装(如上文)
dataflow -v
3. 从 Hugging Face 下载数据集
安装 Hugging Face 包
pip install huggingface_hub
创建脚本 hf_download.sh:
export HF_ENDPOINT=https://hf-mirror.com # 可选镜像
rep="<huggingface 数据集名称>"
local_dir="./data"
huggingface-cli download $rep \
--repo-type dataset \
--local-dir $local_dir \
--force
运行脚本,下载的数据集样式如下图所示:
bash hf_download.sh
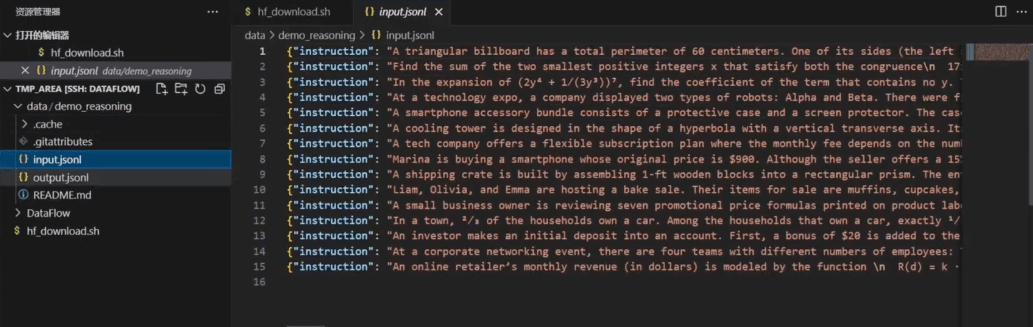
4. 使用下载的数据运行自定义 Pipeline
此处详细步骤与上文相同,不再赘述。
python pipelines/custom_pipeline.py --config config/custom.json
通过参数文件可灵活控制输入源、算子顺序与输出路径。
部署优化与推荐实践
| 场景 | 推荐实践 |
|---|---|
| 环境隔离 | 使用 Conda + requirements.txt 保证依赖一致性 |
| 版本锁定 | 使用 pip freeze > requirements.txt 固定依赖版本 |
| 日志与缓存管理 | 定期清理 cache_local/,使用 logs/ 记录运行状态 |
| 算子扩展 | 在 custom_operators/ 目录中新增模块并注册 |
| 性能优化 | 优先使用多线程算子或分布式 Pipeline,减少单节点 I/O |
| 数据路径管理 | 使用相对路径和 .env 文件存储路径配置,增强可移植性 |
常见问题与排查
| 问题 | 原因 | 解决方案 |
|---|---|---|
| dataflow: command not found | 未激活虚拟环境 | 运行 conda activate dataflow |
| ModuleNotFoundError | 安装路径不一致 | 检查是否使用 -e . 安装 |
| Permission denied | 权限不足 | 在管理员权限或 sudo 下执行 |
| Pipeline 无输出 | 路径或数据源错误 | 检查 example_data/ 目录及 pipeline 配置文件 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 9
9 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)