发明 AI 智能体长期记忆:从「金鱼记忆」到「时序推理」—— AI智能体记忆的结构化进化
标题:从「金鱼记忆」到「时序推理」——AI智能体记忆的结构化进化核心问题:全文上下文检索导致信息淹没、时序混乱、延迟高核心解法:三层时序知识图谱(Episode→Semantic→Community)+ 双时序边失效机制技术支撑:BGE-m3嵌入、Neo4j图数据库、Cross-encoder重排、标签传播社区检测最终成果:准确率 +18.5%,延迟 -90%,Token -98.6%本质升华:将
发明 AI 智能体长期记忆:从「金鱼记忆」到「时序推理」—— AI智能体记忆的结构化进化
代码:https://github.com/getzep/graphiti
起点:原始尝试
如果把用户的对话记录塞进大模型的上下文窗口,让它「记住」之前说过的话——
模型确实能回答「上周我跟你说了什么」这类问题
效果虽有,问题却很大:上下文窗口塞满11.5万token后,模型答题准确率仅 55.4%,响应延迟高达 31秒
更糟的是,对话一长,关键信息淹没在海量文本中;信息一更新,旧事实和新事实混为一谈
迭代优化过程
问题一:信息检索不精准
可问题又来了 —— 传统RAG只能做静态文档检索,语义相似≠逻辑相关
于是,你引入 三层知识图谱结构:
• Episode子图:存储原始对话消息,保留完整上下文
• Semantic Entity子图:从对话中抽取实体和关系(如「张三」-「就职于」-「公司A」)
• Community子图:用标签传播算法聚类相关实体,生成高层摘要
这样,检索时不再是「大海捞针」,而是沿着知识图谱的边精准定位
问题二:信息会过时
可问题又来了——用户说「我换工作了」,旧的就职信息怎么处理?
于是,你引入 双时序模型(Bi-temporal Model):
• T时间线:记录事实在现实中的有效期(valid_at 到 invalid_at)
• T’时间线:记录数据何时入库、何时失效
新边入库时,系统自动对比语义相关的旧边,发现矛盾就将旧边标记为「失效」,同时保留历史记录
用户问「我 现在 在哪工作」和「我 去年 在哪工作」,系统能给出不同答案
问题三:检索结果太多、太杂
可问题又来了——三种搜索方法(余弦相似度、BM25全文检索、广度优先图遍历)各有所长,结果如何整合?
于是,你引入 多级重排机制:
• RRF融合排序:综合多路召回结果
• MMR去重:最大边际相关性,去掉冗余结果
• 提及频率排序:对话中高频出现的实体优先返回
• Cross-encoder精排:用模型对候选结果精细打分
最终,上下文从11.5万token压缩到 1600 token,信息密度提升70倍
系统化完善
实体抽取与消歧
消息入库时,系统先做命名实体识别,再用反思技术(Reflexion)减少幻觉;对抽取出的实体,通过embedding相似度+全文检索找到候选重复项,让LLM判断是否合并,避免「张三」和「老张」变成两个节点
时间表达式解析
「下周四」「两周前」这类相对时间,系统根据消息发送时间戳自动转换为绝对时间,确保时序推理准确
社区动态更新
新实体入库时,用标签传播的单步逻辑快速分配社区,延迟完整社区刷新,兼顾实时性和一致性
成就总结
恭喜你,发明了 Zep——基于时序知识图谱的智能体记忆层

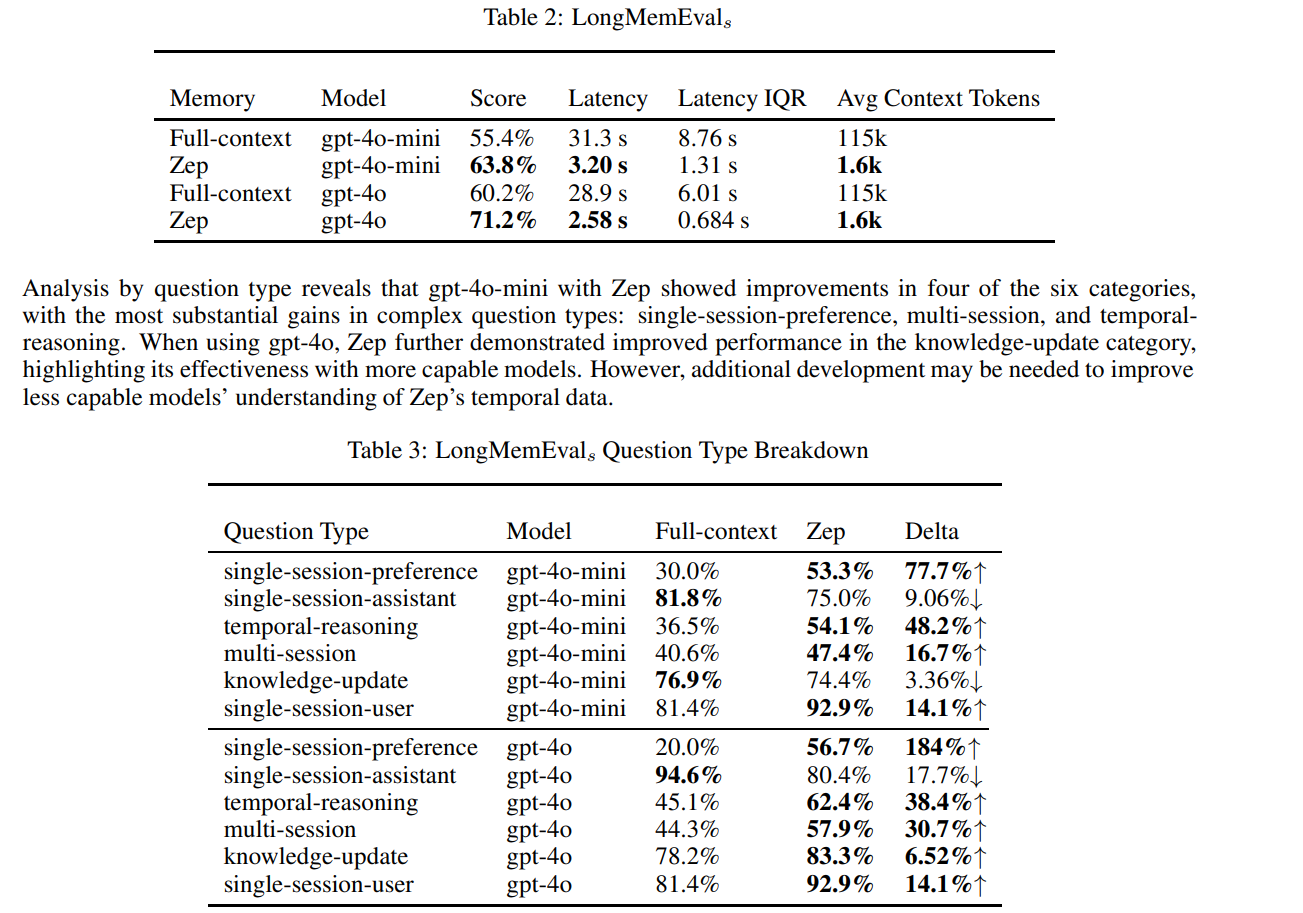
在时序推理任务上提升 38.4%,跨会话任务提升 30.7%——这不仅是检索系统的升级,更是赋予AI智能体真正的「长期记忆」能力
核心演化路径总结
标题:从「金鱼记忆」到「时序推理」——AI智能体记忆的结构化进化
- 核心问题:全文上下文检索导致信息淹没、时序混乱、延迟高
- 核心解法:三层时序知识图谱(Episode→Semantic→Community)+ 双时序边失效机制
- 技术支撑:BGE-m3嵌入、Neo4j图数据库、Cross-encoder重排、标签传播社区检测
- 最终成果:准确率 +18.5%,延迟 -90%,Token -98.6%
- 本质升华:将RAG从「静态文档仓库」变成「动态演化的世界模型」,模拟人类情景记忆与语义记忆的双系统
1. 解法技术拆解
1.1 核心问题
现有RAG(检索增强生成)框架仅能处理静态文档检索,无法满足企业级AI Agent需求:
- 无法动态整合持续演化的对话数据
- 无法融合非结构化对话与结构化业务数据
- 无法追踪知识的时间演变
- 上下文窗口限制导致长期记忆丢失
1.2 整体解法形式
Zep = 时序知识图谱构建(Graphiti) + 混合检索系统 + 分层记忆架构
1.3 与同类算法(MemGPT)的主要区别
| 维度 | MemGPT | Zep |
|---|---|---|
| 记忆表示 | 操作系统式内存管理 | 时序知识图谱 |
| 时间建模 | 无显式时态 | 双时态模型(事件时间+事务时间) |
| 关系建模 | 平面化存储 | 三层分层图结构 |
| 检索方式 | 单一检索 | 混合检索(语义+全文+图遍历) |
| 数据融合 | 仅对话 | 对话+结构化业务数据 |
解法的递归拆解(拆解到不可再分)
整体分解
解法 = 子解法A(图构建) + 子解法B(记忆检索) + 子解法C(上下文生成)
子解法A:时序知识图谱构建
子解法A = A1(分层图架构) + A2(双时态建模) + A3(动态更新机制)
子解法A1:分层图架构(三层子图)
特征原因:对话记忆既有原子性的事件片段,也有抽象的语义关系,需要分层表示
A1 = A1.1(情景子图) + A1.2(语义实体子图) + A1.3(社区子图)
子解法A1.1:情景子图(Episode Subgraph)
为什么需要?
- 原始对话包含细粒度语境信息(谁说的、何时说的、具体措辞)
- 防止信息损失,作为"记忆源头"可追溯
- 支持引用原文(citation)和精确引述(quotation)
具体怎么做?
输入:消息(Message)= {文本内容, 发言者, 参考时间戳tref}
处理:
1. 创建情景节点 ni ∈ Ne,存储原始消息
2. 创建情景边 ei ∈ Ee,连接情景到其引用的语义实体
3. 维护双向索引:情景→语义边、语义边→源情景
输出:非损失的原始数据存储层
预期效果:
- 100%保留原始信息
- 支持正向提取(情景→实体)和反向追溯(实体→来源)
可能风险:
- 存储开销大(每条消息都存全文)
- 冗余信息多
之所以用情景子图,是因为"对话记忆的原子性"特征
子解法A1.2:语义实体子图(Semantic Entity Subgraph)
为什么需要?
- 情景数据是碎片化的,需要抽取跨对话的稳定实体和关系
- 实体可能在多次对话中被提及,需要去重和融合
- 关系表达了知识的结构化形式
具体怎么做?
A1.2 = A1.2.1(实体提取与解析) + A1.2.2(事实提取与去重) + A1.2.3(时态提取与边失效)
子解法A1.2.1:实体提取与解析
特征原因:"实体多次出现需要统一身份"特征
为什么需要?
- 同一实体可能有不同称呼(如"张三"、“小张”、“张工”)
- 需要将碎片化提及聚合为统一实体表示
具体怎么做?
步骤1:实体提取
输入:当前消息 + 前n条消息(n=4,提供2轮对话上下文)
LLM提取:{实体名称, 实体摘要}
特殊规则:发言者自动作为实体提取
步骤2:反思优化(Reflexion技术)
LLM自我检查:是否有遗漏实体?是否有幻觉实体?
迭代优化提取结果
步骤3:实体解析(Entity Resolution)
嵌入:将实体名称→1024维向量
混合检索:
- 余弦相似度搜索(找语义相似实体)
- 全文搜索(找名称/摘要匹配实体)
LLM判断:候选实体 + 对话上下文 → 是否重复?
如果重复:合并实体,生成更完整的名称和摘要
步骤4:写入图谱
使用预定义Cypher查询(非LLM生成)
原因:确保schema一致性,减少幻觉
预期效果:
- 同一实体的多次提及被正确聚合
- 实体摘要随新信息不断丰富
可能风险:
- 实体边界模糊(如"苹果公司"vs"苹果手机")
- 同名异义实体误合并
之所以用混合检索+LLM判断,是因为"实体指称多样性"特征
子解法A1.2.2:事实提取与去重
特征原因:"关系可能重复表述"特征
为什么需要?
- 同一事实可能在多次对话中重复提及
- 需要识别等价事实,避免冗余存储
- 同一事实可能涉及多个实体(超边hyperedge)
具体怎么做?
步骤1:事实提取
输入:消息上下文 + 已提取实体列表
LLM提取:{源实体, 目标实体, 关系类型, 详细事实描述}
约束:仅提取已知实体间的关系
步骤2:事实嵌入
将事实描述→向量表示
步骤3:事实去重
检索范围:仅限于同一实体对之间的边(大幅降低搜索空间)
混合检索:语义相似 + 全文匹配
LLM判断:新事实是否与已有事实等价?
如果重复:不创建新边
步骤4:多实体事实建模(超边)
同一事实可在不同实体对间重复提取
示例:"Alice、Bob、Carol三人开会" →
Alice-Bob有边、Bob-Carol有边、Alice-Carol有边
预期效果:
- 避免重复事实堆积
- 支持复杂多方关系建模
可能风险:
- 语义相近但不同的事实被误判为重复
- 超边实现复杂度高
之所以用"限定实体对"的检索策略,是因为"事实局部性"特征
子解法A1.2.3:时态提取与边失效(Edge Invalidation)
特征原因:"事实会随时间变化"特征
为什么需要?
- 真实世界的关系会演化(如"张三在A公司工作" → “张三在B公司工作”)
- 需要追踪事实的有效期
- 新信息可能使旧信息失效
具体怎么做?
步骤1:时态提取
输入:消息 + 参考时间戳tref + 事实描述
LLM提取:
- 绝对时间("1912年6月23日")→ 直接转换
- 相对时间("两周前")→ 基于tref计算绝对时间
- 时间范围:[tvalid, tinvalid] ∈ T(事件时间线)
步骤2:边失效检测
对每个新边:
检索:与其语义相关的已有边
LLM判断:是否存在矛盾?
示例:新边"张三在B公司" vs 旧边"张三在A公司"
步骤3:失效处理
如果时间重叠且矛盾:
设置旧边的tinvalid = 新边的tvalid
保留历史记录(不删除,只标记失效)
步骤4:双时态追踪
T(事件时间):事实何时为真
T'(事务时间):何时被系统记录
每个边存储4个时间戳:
- tvalid, tinvalid ∈ T
- t'created, t'expired ∈ T'
预期效果:
- 支持"时间旅行"查询(某个时间点的知识状态)
- 保留知识演化历史
- 自动识别并解决知识冲突
可能风险:
- 时间抽取不准确(特别是模糊时间表达)
- 失效判断可能误判(非矛盾的变化被当成矛盾)
之所以用双时态模型,是因为"需要区分事实真实性时间与记录时间"的特征
子解法A1.3:社区子图(Community Subgraph)
特征原因:"局部密集连接的实体形成主题集群"特征
为什么需要?
- 单个实体信息碎片化,难以形成全局理解
- 强连接的实体群组代表某个话题/领域
- 需要高层次摘要支持全局问答
具体怎么做?
步骤1:社区检测
算法:标签传播(Label Propagation)
为什么不用Leiden?→ 标签传播支持动态扩展
步骤2:动态社区扩展(创新点)
当新实体ni加入图:
检查邻居节点所属社区
分配ni到邻居占多数的社区
更新社区摘要(LLM重新总结)
优点:避免每次重新运行全局聚类
代价:社区会逐渐偏离最优,需定期刷新
步骤3:社区摘要生成
方法:Map-Reduce式迭代摘要(借鉴GraphRAG)
输入:社区内所有实体和边
输出:{社区名称(关键词集合), 高层次摘要}
步骤4:社区嵌入
将社区名称→向量
支持基于社区的语义检索
预期效果:
- 支持"全局理解"类问题(如"主要讨论了哪些话题?")
- 降低检索复杂度(先定位社区,再深入细节)
可能风险:
- 动态更新导致社区划分次优
- 社区摘要可能丢失细节
之所以用标签传播而非Leiden,是因为"需要增量更新"特征
子解法A2:双时态建模(Bi-temporal Model)
为什么需要?
- 事实的"真实发生时间"与"被记录时间"不同
- 需要支持数据库审计(T’)和时序推理(T)
具体怎么做?
- T时间线:事件的真实时间顺序
- T’时间线:数据摄入的事务顺序
- 冲突解决:总是信任T’更新的信息
预期效果:
- 可以查询"某个时间点用户认为的真相"
- 支持知识回滚和版本管理
可能风险:
- 存储开销翻倍
- 查询逻辑复杂化
之所以用双时态,是因为"会话记忆的追溯性和演化性"特征
子解法A3:动态更新机制
为什么需要?
- 对话是流式的,知识图谱需要实时更新
- 静态构建无法应对新信息
具体怎么做?
- 增量式实体解析(每条消息触发)
- 增量式社区扩展(避免全局重算)
- 边失效机制(自动处理知识冲突)
预期效果:
- 毫秒级延迟的图谱更新
- 图谱始终反映最新状态
可能风险:
- 频繁更新可能导致数据不一致
- 并发写入冲突
之所以用增量更新,是因为"对话的实时性"特征
子解法B:混合记忆检索
子解法B = B1(多模检索) + B2(重排序) + B3(上下文构造)
子解法B1:多模检索(三种搜索函数)
特征原因:"单一检索无法覆盖所有相似性维度"特征
B1 = B1.1(语义搜索) + B1.2(全文搜索) + B1.3(图遍历搜索)
子解法B1.1:余弦语义相似度搜索(φcos)
为什么需要?
- 用户问题可能用不同措辞表达相同语义
- 需要捕获语义层面的相关性
具体怎么做?
输入:查询字符串α
步骤1:嵌入查询 → 向量vα
步骤2:计算余弦相似度
对所有边ei:cos_sim(vα, v_edge)
对所有实体ni:cos_sim(vα, v_entity_name)
对所有社区ci:cos_sim(vα, v_community_name)
步骤3:返回Top-K结果
预期效果:
- 找到语义相关但字面不匹配的内容
可能风险:
- 嵌入模型偏差导致误匹配
之所以用语义搜索,是因为"语义相似性"特征
子解法B1.2:全文搜索(φbm25)
为什么需要?
- 某些查询需要精确关键词匹配(如专有名词)
- BM25擅长词频统计
具体怎么做?
使用Neo4j的Lucene实现
对字段:
- 边的fact字段
- 实体的name字段
- 社区的name字段
返回:BM25分数排序的结果
预期效果:
- 精确匹配关键词
- 补充语义搜索的盲区
可能风险:
- 无法理解同义词
之所以用BM25,是因为"词汇重叠相似性"特征
子解法B1.3:广度优先图遍历(φbfs)
为什么需要?
- 相关信息可能在图中距离近但语义/词汇相似度低
- 需要利用图的拓扑结构
具体怎么做?
输入:种子节点(可以是最近的情景或初步检索结果)
步骤1:从种子节点开始BFS
步骤2:扩展n跳邻居
步骤3:返回遍历到的节点和边
预期效果:
- 发现上下文相关但表面不相关的信息
- 支持"最近提及的实体"扩展
可能风险:
- 可能引入无关信息
- 遍历范围难以控制
之所以用图遍历,是因为"上下文局部性"特征
子解法B2:重排序(Reranker)
特征原因:"初步检索召回率高但精度低"特征
为什么需要?
- 三种检索返回大量候选,需要精选
- 需要综合多个检索结果
具体怎么做?
B2 = B2.1(RRF融合) + B2.2(MMR去重) + B2.3(图特征排序) + B2.4(交叉编码器)
子解法B2.1:倒数排名融合(RRF)
为什么需要?
- 融合多个检索结果列表
具体怎么做?
对每个结果r:
score(r) = Σ 1/(k + rank_i(r))
其中rank_i(r)是r在第i个检索列表中的排名
之所以用RRF,是因为"多检索源需要融合"特征
子解法B2.2:最大边际相关性(MMR)
为什么需要?
- 去除冗余结果,增加多样性
具体怎么做?
迭代选择:
选择与查询相关但与已选结果差异大的结果
之所以用MMR,是因为"结果冗余性"特征
子解法B2.3:基于图的情景提及排序
为什么需要?
- 频繁提及的实体/事实更重要
具体怎么做?
统计:实体/边在对话中的提及次数
排序:提及次数多的优先
之所以用提及频率,是因为"重要性与频率正相关"特征
子解法B2.4:交叉编码器(Cross-Encoder)
为什么需要?
- 最精确但最慢的排序方法
具体怎么做?
LLM评分:对每个(查询, 候选)对生成相关性分数
使用:仅在高精度场景使用(成本高)
之所以用交叉编码器,是因为"需要深度语义理解"特征
子解法B3:上下文构造(Constructor χ)
为什么需要?
- LLM需要格式化的文本输入
具体怎么做?
输入:检索到的边、实体、社区节点
格式化:
<FACTS>
事实1 (有效期: tvalid - tinvalid)
...
</FACTS>
<ENTITIES>
实体名: 摘要
...
</ENTITIES>
<COMMUNITIES>
社区摘要
...
</COMMUNITIES>
输出:格式化字符串β
预期效果:
- 提供时间信息(支持时序推理)
- 结构化呈现(便于LLM理解)
可能风险:
- Token开销大
之所以包含时间戳,是因为"时序推理需求"特征
完整解法的形式化表达
Zep(query α) = χ(ρ(ϕ(α)))
其中:
ϕ(α) = {φcos(α), φbm25(α), φbfs(α)} → 候选集合
ρ = RRF ∘ MMR ∘ 图排序 ∘ 交叉编码器 → 重排序
χ = 格式化(事实+时间, 实体+摘要, 社区摘要) → 上下文字符串β
完整例子:多轮对话构建与检索
场景设定
输入对话:
[2024-01-01 10:00] Alice: 我在Google工作
[2024-01-15 14:00] Alice: 我上周离职了
[2024-01-20 09:00] Alice: 现在在Meta工作
[2024-02-01 16:00] Bob: Alice现在在哪工作?
图构建过程
1. 第一条消息处理(2024-01-01):
- 情景节点:存储原始消息
- 实体提取:Alice, Google
- 事实提取:Alice WORKS_AT Google
- 时态:tvalid = 2024-01-01, tinvalid = null
- 边创建:[Alice] --WORKS_AT–> [Google]
2. 第二条消息处理(2024-01-15):
- 实体:Alice(解析为已有实体)
- 事实:Alice LEFT_JOB(隐含)
- 时态计算:“上周” + tref(2024-01-15) = 约2024-01-08
- 边失效触发:
- 检测到与"Alice WORKS_AT Google"矛盾
- 设置旧边:tinvalid = 2024-01-08
3. 第三条消息处理(2024-01-20):
- 实体:Alice(已有), Meta(新)
- 事实:Alice WORKS_AT Meta
- 时态:tvalid = 2024-01-20
- 新边创建:[Alice] --WORKS_AT–> [Meta]
最终图状态
[Alice] --WORKS_AT(2024-01-01 ~ 2024-01-08)--> [Google] (已失效)
[Alice] --WORKS_AT(2024-01-20 ~ ∞)--> [Meta] (有效)
检索过程(查询:“Alice现在在哪工作?”)
1. 多模检索:
- 语义搜索:找到与"工作"相关的边
- 全文搜索:匹配"Alice"、"工作"关键词
- 图遍历:从最近情景出发,找到Alice的邻边
2. 重排序:
- RRF融合三个检索结果
- 时间过滤:仅保留tinvalid=null或tinvalid>now的边
- 提及排序:Alice最近被提及,权重高
3. 上下文构造:
<FACTS>
Alice WORKS_AT Meta (2024-01-20 ~ present)
</FACTS>
<ENTITIES>
Alice: 实体,在对话中提及的员工
Meta: 公司
</ENTITIES>
4. LLM生成答案:
“Alice现在在Meta工作(自2024年1月20日起)”
2. 子解法的逻辑链
决策树形式
用户查询
│
├─【判断1:是否需要记忆检索?】
│ ├─ 否 → 直接LLM回答
│ └─ 是 ↓
│
├─【阶段1:图构建(离线/实时)】
│ │
│ ├─ 步骤1.1:情景摄入
│ │ ├─ 消息类型?
│ │ │ ├─ Message → 提取发言者+内容+时间
│ │ │ ├─ Text → 仅内容+时间
│ │ │ └─ JSON → 结构化解析
│ │ └─ 创建情景节点 → 存入Ge
│ │
│ ├─ 步骤1.2:实体抽取
│ │ ├─ LLM提取实体(n=4上下文)
│ │ ├─ 反思优化(减少幻觉)
│ │ ├─ 实体解析
│ │ │ ├─ 混合检索候选实体
│ │ │ ├─ LLM判断是否重复
│ │ │ ├─ 是 → 合并实体
│ │ │ └─ 否 → 创建新实体
│ │ └─ 写入Gs(实体节点)
│ │
│ ├─ 步骤1.3:事实抽取
│ │ ├─ LLM提取关系(仅限已知实体间)
│ │ ├─ 事实去重
│ │ │ ├─ 限定同实体对检索
│ │ │ ├─ LLM判断是否等价
│ │ │ ├─ 是 → 跳过
│ │ │ └─ 否 → 继续
│ │ ├─ 时态提取
│ │ │ ├─ 绝对时间 → 直接解析
│ │ │ └─ 相对时间 → tref计算
│ │ ├─ 边失效检测
│ │ │ ├─ 检索相关边
│ │ │ ├─ LLM判断矛盾
│ │ │ ├─ 有矛盾 → 设置tinvalid
│ │ │ └─ 无矛盾 → 共存
│ │ └─ 写入Es(语义边)
│ │
│ └─ 步骤1.4:社区检测
│ ├─ 新实体加入
│ │ ├─ 调查邻居社区
│ │ ├─ 分配到多数社区
│ │ └─ 更新社区摘要
│ └─ 定期全局刷新(标签传播)
│
├─【阶段2:记忆检索(在线)】
│ │
│ ├─ 步骤2.1:多模检索
│ │ ├─ φcos(语义搜索)
│ │ │ ├─ 嵌入查询
│ │ │ ├─ 搜索边/实体/社区
│ │ │ └─ 返回Top-K1
│ │ ├─ φbm25(全文搜索)
│ │ │ ├─ BM25匹配
│ │ │ └─ 返回Top-K2
│ │ └─ φbfs(图遍历)
│ │ ├─ 确定种子(最近情景/初检结果)
│ │ ├─ n跳扩展
│ │ └─ 返回邻居集
│ │
│ ├─ 步骤2.2:重排序
│ │ ├─ RRF融合
│ │ ├─ MMR去重
│ │ ├─ 图特征排序
│ │ │ ├─ 提及频率
│ │ │ └─ 节点距离
│ │ └─ (可选)交叉编码器
│ │
│ └─ 步骤2.3:上下文构造
│ ├─ 提取Top-N边/实体/社区
│ ├─ 格式化为文本
│ │ ├─ 事实+时间戳
│ │ ├─ 实体+摘要
│ │ └─ 社区摘要
│ └─ 返回上下文字符串β
│
└─【阶段3:LLM生成】
├─ 拼接:系统提示 + 上下文β + 用户查询α
└─ 生成最终答案
逻辑链类型
混合型(链条+网络)
- 图构建阶段:链条式(顺序流程)
- 检索阶段:网络式(三路并行检索后融合)
3. 隐性方法分析
隐性方法1:限定实体对的事实去重
课本方法:全局检索相似边
隐性创新:仅搜索同一实体对之间的边
为什么隐性?
- 论文仅一句带过:“This constraint not only prevents erroneous combinations…”
- 未形成独立命名的技术
关键步骤:
传统方法:检索空间 = 全部边(O(E)复杂度)
隐性方法:检索空间 = 同实体对的边(O(1)均摊复杂度)
价值:
- 将复杂度从O(E)降低到O(k),k<<E
- 避免跨实体的错误合并
隐性方法2:动态社区扩展(单步标签传播)
课本方法:Leiden/Louvain全局聚类
隐性创新:单次递归标签传播步骤
为什么隐性?
- 论文描述为"dynamic extension logic"
- 非标准算法,是对标签传播的增量化改造
关键步骤:
标准标签传播:迭代至收敛(O(V²))
隐性方法:仅执行一次邻居投票(O(d),d为度数)
代价明确指出:
- “communities gradually diverge from optimal”
- 需要定期刷新
隐性方法3:双向索引的情景-语义连接
课本方法:单向引用(语义→源)
隐性创新:双向可追溯索引
为什么隐性?
- 论文轻描淡写:“bidirectional indices”
- 未展开实现细节
关键步骤:
正向:情景 → 它生成的实体/边
反向:实体/边 → 它来源的情景
价值:
- 支持引用溯源(cite原文)
- 支持快速获取实体的上下文
隐性方法4:反思式实体提取(Reflexion技术)
课本方法:一次性LLM提取
隐性创新:LLM自我检查并迭代
关键步骤:
第一轮:LLM提取初步实体
第二轮:LLM审查"是否有遗漏?是否有幻觉?"
第三轮:根据反馈调整
为什么隐性?
- 引用了Reflexion论文,但未详述具体prompt
隐性方法5:Cypher预定义查询(拒绝LLM生成SQL)
课本方法:LLM生成数据库查询(如Text2SQL)
隐性创新:硬编码Cypher模板
关键步骤:
拒绝:LLM生成Cypher → 易幻觉,schema不一致
采用:预定义模板 + 参数填充
为什么隐性?
- 论文仅一句:“We chose this approach over LLM-generated queries”
- 未展示具体模板
4. 隐性特征分析
隐性特征1:实体对局部性
显性特征:实体需要去重
隐性特征:相似事实几乎总是发生在同一实体对之间
在哪发现?
- 事实去重步骤:“constrained to edges existing between the same entity pairs”
- 这是经验性的数据分布特征,非问题定义中给出
如何利用?
- 限定检索范围,降低复杂度
隐性特征2:社区的动态稳定性
显性特征:图会动态增长
隐性特征:社区结构短期内相对稳定
在哪发现?
- "延迟完全刷新的需求"暗示了这一假设
- 如果社区极不稳定,增量更新将完全失效
如何利用?
- 用单步传播近似,延迟全局重算
隐性特征3:时间局部性(Recent Bias)
显性特征:对话有时序
隐性特征:用户查询更关注最近信息
在哪发现?
- BFS种子选择:“recent episodes as seeds”
- 提及频率排序(最近提及权重高)
如何利用?
- 从最近情景开始遍历
- 时间衰减加权
隐性特征4:矛盾的时间排他性
显性特征:事实可能矛盾
隐性特征:矛盾的事实通常时间上互斥
在哪发现?
- 边失效逻辑:“temporally overlapping contradictions”
- 如果时间不重叠,即使矛盾也可共存(如工作经历)
如何利用?
- 仅在时间重叠时触发失效
5. 方法的潜在局限性
5.1 可扩展性局限
问题1:社区检测的扩展性
- 瓶颈:图达到百万节点后,标签传播也会变慢
- 论文承认:“periodic community refreshes remain necessary”
- 未解决:何时刷新?刷新成本如何控制?
问题2:Neo4j单机限制
- 瓶颈:Neo4j企业版支持分布式,但开源版单机
- 风险:超大规模对话(如客服中心)可能遇到瓶颈
5.2 准确性局限
问题3:实体解析错误累积
- 场景:同名异义(“苹果”=水果/公司)
- 论文未讨论:错误合并后如何修正?
- 风险:错误会传播到所有后续边
问题4:时态提取不准确
- 场景:模糊时间(“前段时间”、“最近”)
- 论文承认:依赖LLM,可能出错
- 实验未测:LongMemEval未单独测试时态推理
问题5:边失效的误判
- 场景:非矛盾的变化被当成矛盾
- 例:“喜欢咖啡” vs “最近爱上了茶” → 可能是偏好扩展,非替换
- 论文未讨论:如何区分"替换"与"补充"?
5.3 成本局限
问题6:LLM调用成本高
统计:每条消息至少7次LLM调用
- 实体提取
- 实体反思
- 实体解析
- 事实提取
- 事实去重判断
- 时态提取
- 边失效判断
论文未披露:实际部署的成本数据
问题7:存储冗余
- 问题:原始情景+实体+边+社区,四层存储
- 论文未讨论:存储成本 vs 性能的权衡
5.4 实验局限
问题8:单一领域测试
- 实验:仅对话场景(DMR、LongMemEval)
- 未测:论文声称支持"structured business data",但实验中未体现
问题9:single-session-assistant性能下降
- 现象:该类问题准确率降低17.7%(gpt-4o)
- 论文承认:“further research and engineering work is needed”
- 未解释:为什么这类问题特别差?
问题10:无对照实验(MemGPT)
- 问题:论文未能在LongMemEval上运行MemGPT
- 理由:“MemGPT does not support direct ingestion”
- 缺陷:无法直接对比SOTA
5.5 设计局限
问题11:超边实现复杂
- 论文提到:“multi-entity facts through hyper-edges”
- 未展开:具体如何实现?性能如何?
问题12:Prompt工程依赖
- 观察:大量复杂prompt(见附录)
- 风险:换模型可能需要重新调优prompt
问题13:无主动记忆管理
- 缺失:论文未讨论如何"遗忘"不重要信息
- 风险:长期运行后图谱膨胀
6. 多题一解的通用解题思路
通用模式1:分层抽象
共用特征:需要处理多粒度信息(细节+摘要)
共用解法:构建层次结构
- 底层:原子数据(情景)
- 中层:结构化知识(实体+边)
- 高层:聚合摘要(社区)
适用场景:
- 文档RAG:段落→句子→关键词
- 知识管理:原文→笔记→思维导图
- 数据库:明细表→汇总表→数据仓库
通用模式2:混合检索
共用特征:单一相似度无法覆盖所有情况
共用解法:多路检索+融合
- 语义(向量)
- 词汇(BM25)
- 结构(图/树遍历)
适用场景:
- 推荐系统:协同过滤+内容过滤+热度
- 搜索引擎:语义+关键词+PageRank
- 问答系统:FAQ匹配+知识图谱+生成
通用模式3:时态建模
共用特征:数据会随时间演化
共用解法:版本化+有效期
- 每条记录带时间戳
- 支持"时间旅行"查询
- 冲突解决策略(覆盖/合并)
适用场景:
- 数据库:慢变维度(SCD Type 2)
- 版本控制:Git的commit历史
- 区块链:不可变账本
通用模式4:增量更新
共用特征:数据流式到达,全量重算成本高
共用解法:局部更新+定期全局校正
- 实时:增量处理
- 离线:批量优化
适用场景:
- 流计算:Flink的状态更新
- 索引维护:搜索引擎的增量索引
- 机器学习:在线学习
通用模式5:实体消歧
共用特征:同一对象多种表述
共用解法:检索+判断+合并
- 混合检索候选
- 语义判断是否等价
- 合并或创建
适用场景:
- 知识图谱:实体对齐
- CRM系统:客户去重
- 引文分析:作者消歧
7. 暴露决策过程
决策1:社区检测算法选择
考虑方案:
方案A:Leiden算法(GraphRAG使用)
- 优点:聚类质量高,有理论保证
- 缺点:不支持增量更新,每次需全局重算
方案B:标签传播(最终选择)
- 优点:支持单步增量扩展
- 缺点:质量逐渐下降,需定期刷新
决策理由:
- 实时性 > 最优性
- 论文明确:“influenced by label propagation’s straightforward dynamic extension”
决策2:数据库查询生成方式
考虑方案:
方案A:LLM生成Cypher(Text2Cypher)
- 优点:灵活,适应复杂查询
- 缺点:易幻觉,schema不一致
方案B:预定义模板(最终选择)
- 优点:可靠,性能稳定
- 缺点:不够灵活
决策理由:
- 论文明确:“to ensure consistent schema formats and reduce the potential for hallucinations”
- 生产系统优先稳定性
决策3:MemGPT的LongMemEval评估
尝试方案:
- 将对话注入MemGPT的archival history
失败原因:
- “unable to achieve successful question responses”
- MemGPT不支持直接摄入已有历史
暗示:
- MemGPT设计用于实时对话,非离线评估
- Zep的离线批量导入是优势
决策4:时态模型的复杂度
考虑方案:
方案A:单时态(仅事件时间)
- 简单,存储省
方案B:双时态(事件+事务时间)(最终选择)
- 支持审计和知识演化追溯
决策理由:
- 企业应用需求:“bi-temporal model… represents a novel advancement”
- 论文强调这是创新点
决策5:嵌入维度选择
论文选择:1024维(BGE-m3)
未讨论的权衡:
- 更高维(如1536维OpenAI):精度可能更高,但成本、存储、检索速度下降
- 更低维(如768维):更快,但精度损失
暗示:选择了中间值平衡性能与成本
8. 隐蔽的知识
8.1 新手注意不到的规律
规律1:事实的时间粒度决定失效策略
新手思维:所有矛盾事实都应该互斥
专家洞察:
- 时间重叠的矛盾→替换(如工作地点)
- 时间不重叠的矛盾→共存(如历史记录)
如何发现?
- 论文仅一句:“temporally overlapping contradictions”
- 需要理解双时态的深层含义
规律2:检索范围与精度的反比关系
新手思维:检索范围越大,召回越全
专家洞察:
- 限定范围(如同实体对)可以提高精度
- 因为减少了噪声干扰
证据:
- 事实去重限定在同实体对
- BFS限定在n跳邻居
规律3:社区的"延迟失效"特性
新手思维:增量更新会立即导致社区错误
专家洞察:
- 社区结构有"惯性",短期内增量更新足够好
- 可以延迟全局刷新以节省成本
如何发现?
- 论文提到"delaying the need for complete community refreshes"
- 这是经验性的工程智慧,非理论
8.2 新手无法觉察的微小区别
区别1:T vs T’ 的微妙差异
新手理解:两个时间戳都是记录时间
专家理解:
- T:事实的客观真实时间(语义时间)
- T’:系统的记录时间(物理时间)
- 关键差异:T可以是过去(“我10年前毕业”),T’总是当前
实际影响:
- 查询"用户当时认为什么"需要T
- 审计"谁何时修改了数据"需要T’
区别2:实体解析 vs 事实去重
新手理解:都是去重,应该用同一套方法
专家理解:
- 实体解析:全局检索(因为"张三"可能在任何对话中)
- 事实去重:局部检索(同一实体对的边)
- 原因:数据分布特性不同
区别3:Reflexion vs 简单重试
新手理解:让LLM再跑一次
专家理解:
- Reflexion:LLM看到自己的第一次输出,进行批判性审查
- 简单重试:重新生成,不看前次结果
价值:
- Reflexion利用了"自我批评"能力
- 成本更低(一次额外调用 vs 多次重试)
8.3 对意外的敏感
意外1:single-session-assistant准确率下降
表面现象:这类问题准确率降低17.7%
深层问题:
- 论文未深入分析原因
- 可能假设:这类问题需要assistant的原话,而Zep的摘要丢失了语气/措辞细节
启示:
- 抽象化(实体/事实)会丢失某些信息
- 需要权衡压缩率与信息保真度
意外2:DMR vs LongMemEval的性能差异
表面现象:
- DMR:Zep仅比full-context好0.4%
- LongMemEval:Zep比full-context好18.5%
深层洞察:
- DMR对话太短(60条消息),full-context已足够
- 真正的挑战:长上下文(115k tokens)
- 启示:基准测试设计很重要,DMR不够challenging
意外3:论文未提的限制
观察:论文大量篇幅讨论图构建,但实验仅用了检索功能
意外发现:
- 双向索引:论文提到但实验未用
- 情景引用:未在评估中体现
- 结构化数据融合:宣称支持但未测试
启示:
- 系统能力 ≠ 实验验证的能力
- 很多功能是为未来准备的
总结:隐蔽知识的共同特点
1. 不在教科书中
- 双时态在会话场景的应用
- 限定检索范围的工程技巧
- 社区的动态稳定性假设
2. 需要实践经验才能发现
- 何时用增量 vs 批量
- 如何平衡准确性与成本
- 哪些抽象会丢失信息
3. 论文刻意淡化或未展开
- 失败的尝试(MemGPT评估)
- 性能下降的原因(single-session-assistant)
- 未验证的功能(情景引用)
附录:关键公式总结
图结构定义
G = (N, E, φ)
其中:
N = Ne ∪ Ns ∪ Nc (情景节点 ∪ 实体节点 ∪ 社区节点)
E = Ee ∪ Es ∪ Ec (情景边 ∪ 语义边 ∪ 社区边)
φ: E → N × N (关联函数)
检索流程
f(α) = χ(ρ(ϕ(α))) → β
ϕ: 查询 → 候选集
ϕ(α) = {φcos(α), φbm25(α), φbfs(α)}
ρ: 候选集 → 排序集
ρ = RRF ∘ MMR ∘ 图排序 ∘ 交叉编码
χ: 排序集 → 上下文字符串
χ(edges, entities, communities) → 格式化文本
双时态模型
每个边存储:
T维度:[tvalid, tinvalid] (事实有效期)
T'维度:[t'created, t'expired] (系统记录时间)
失效条件:
if 新边.tvalid ≤ 旧边.tinvalid AND 内容矛盾:
旧边.tinvalid = 新边.tvalid

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献114条内容
已为社区贡献114条内容

所有评论(0)