什么是InfiniBand(IB)网络
InfiniBand(IB)是一种高性能网络通信标准,采用RDMA技术,具有高吞吐量、低延迟和高可靠性,广泛应用于数据中心、HPC和AI领域。其发展始于2000年,由IBTA联盟推动,以色列公司Mellanox成为技术领导者(2019年被英伟达收购)。IB协议采用分层架构(物理层至传输层),支持无损传输和动态流控技术。带宽从SDR演进至XDR(800G),光模块也同步升级至800G。主要产品包括交
转自微信号:Ai long cloud
一、什么是InfiniBand网络
InfiniBand:即“无限带宽”技术,缩写为IB,是一种网络通信标准,是RDMA技术的一种协议,它采用高速差分信号技术和多通道并行传输机制,主要目标是提供高性能、低延迟和高可靠性。
InfiniBand:是致力于服务器端的高性能计算的互联技术,具有极高的吞吐量和极低的时延,用于计算机与计算机之间的数据互连(如复制,分布式工作等),InfniBand也用作服务器与存储系统之间的直接或交换互连(如SAN和直接存储附件),以及存储系统之间的互连,服务器和网络之间(比如LAN,WANs和the Interet)的通信。广泛用于数据中心、HPC高性能存储等领域。后面随着人工智能的兴起,它被用作为GPU服务器互联的首选网络互连技术。
二、InfiniBand发展历程
上世纪90年代早期,为了支持越来越多的外部设备,英特尔公司率先在标准PC架构中引入PCI总线设计。但是随着CPU、内存、硬盘等部件都在快速升级,PCI总线因升级速度缓慢成为整个系统的瓶颈。为了解决这个问题,IT界巨头:康柏,戴尔(Dell),惠普(HP),IBM,Intel,微软和Sun等180多家公司共同发起成立IBTA(InfiniBand Trade Association,即InfiniBand行业协会)。

IBTA成立目的,就是研究新的替代技术来取代PCl,解决PCI总线传输瓶颈的问题。于是在2000年,InfiniBand架构规范的1.0版本正式发布,它引入了RDMA协议,具有更低的延迟,更大的带宽,更高的可靠性,可以实现更强大的I/O性能,成为系统互连的新技术标准。
提到InfiniBand,就不得不提到一家以色列公司--Mellanox(中文名为:迈络思,可简单记住“卖螺丝”)。1999年5月,几名从英特尔和伽利略技术公司离职的员工在以色列创立了Mellanox。Mellanox公司成立后,随之加入了InfiniBand行业阵营,2001年他们推出了自己的首款InfiniBand产品。

2002年,InfiniBand阵营突遭巨变。这一年,英特尔公司“临阵脱逃”,决定转向开发PCI Express(也就是PCIe,2004年推出)。而另一家巨头微软,也退出了InfiniBand的开发。尽管SUN和日立等公司仍选择坚持,但InfiniBand的发展已然蒙上了阴影。
2003年开始,InfiniBand转向了一个新的应用领域,那就是计算机集群互联。2005年,InfiniBand又找到了一个新场景:存储设备连接。2012年之后,随着高性能计算(HPC)需求的不断增长,InfiniBand技术继续高歌猛进,市场份额不断提升。
在InfiniBand技术逐渐崛起的过程中,Mellanox也在不断壮大,逐渐成为了InfiniBand市场的领导者。2010年,Mellanox和Voltaire公司合并,InfiniBand主要供应商只剩下了Mellanox(2019年被英伟达收购)和QLogic(2012年被Intel收购)。
2013年,Mellanox相继收购了硅光子技术公司Kotura和并行光互连芯片厂商IPtronics,进一步完善了自身产业布局。
2015年,InfiniBand技术在TOP500榜单中的占比首次超过了50%。这标志着InfiniBand技术首次实现了对以太网技术的逆袭,成为超级计算机最首选的集群互联技术。
2015年,Mellanox在全球InfiniBand市场上的占有率达到80%。他们的业务范围,已经从芯片逐步延伸到网卡、交换机/网关、远程通信系统和线缆及模块全领域,成为世界级网络提供商。
2019年,英伟达豪掷69亿美元收购了Mellanox,老黄的说法是:这是两家全球领先高性能计算公司的结合,NVIDIA专注于加速计算,而Mellanox专注于互联和存储。现在看来,英伟达是非常有远见的:大模型训练高度依赖高性能计算集群,而InfiniBand网络则是高性能计算集群的最佳搭档。
三、InfiniBand工作原理
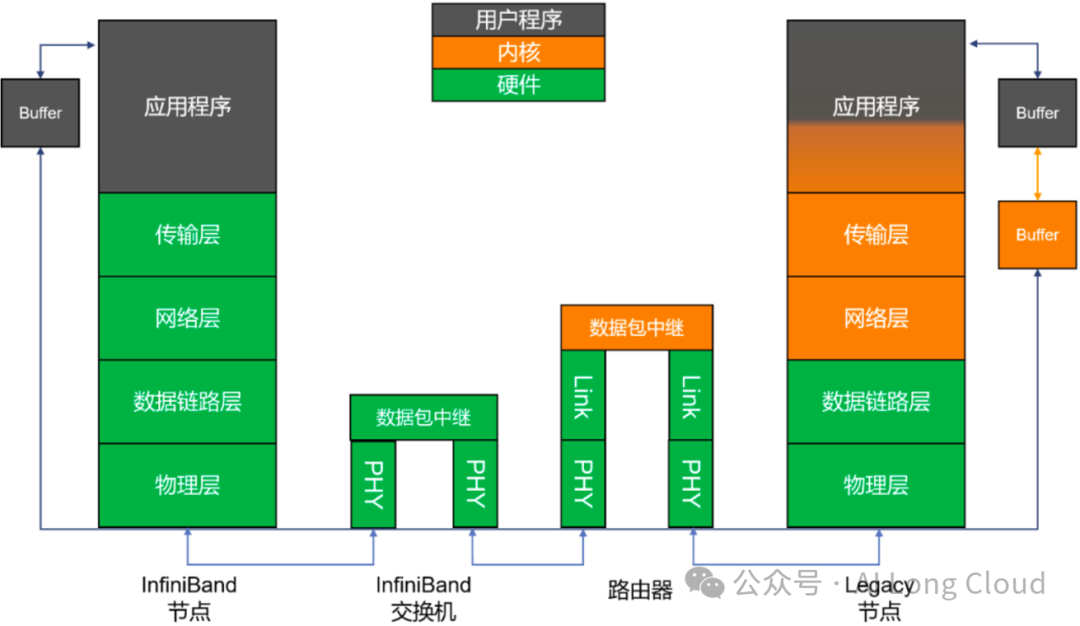
InfiniBand工作原理非网络专业的看起来比较深奥,初学者可以简单了解一下或直接跳过。InfiniBand 协议同样采用了分层结构,各层相互独立,下层为上层提供服务,其工作原理如下图所示:
-
物理层:定义了在线路上如何将比特信号组成符号,然后再组成帧、数据符号以及包之间的数据填充等,详细说明了构建有效包的信令协议等。
-
链路层:定义了数据包的格式以及数据包操作的协议,如:流控、 路由选择、编码、解码等。
-
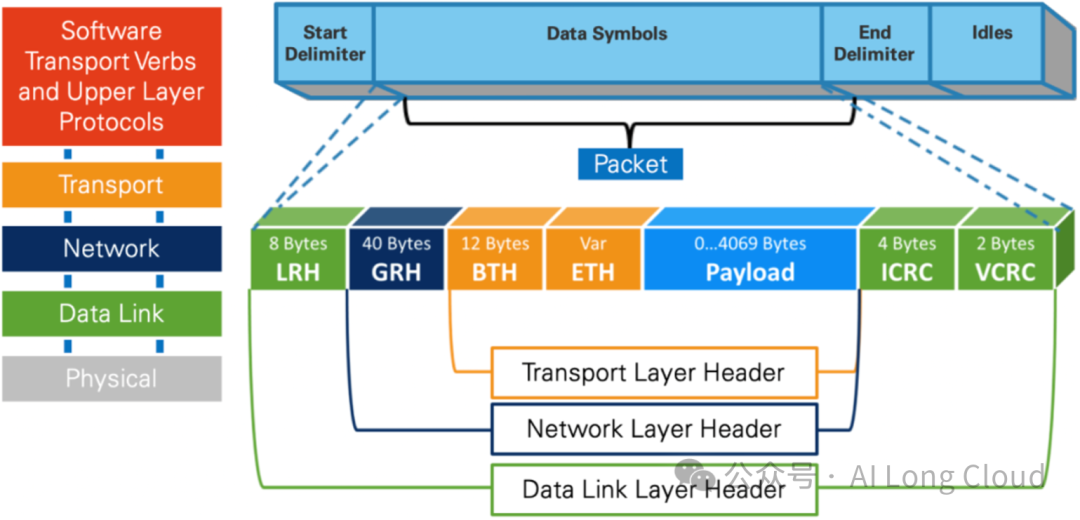
网络层:通过在数据包上添加一个40字节的全局的路由报头(Global Route Header, GRH)来进行路由的选择,对数据进行转发。在转发的过程中,路由器仅仅进行可变的CRC校验,这样就保证了端到端的数据传输的完整性。
Infiniband报文封装架构如下图所示:
-
传输层:将数据包传送到某个指定的队列偶(Queue Pair, QP)中,并指示QP如何去处理该数据包。InfiniBand网络的传输采用了基于信用的流控(Credit-Based Flow Control, CBFC)技术来确保数据传输的可靠性和效率。这种机制通过管理发送方和接收方之间的信用额度(即接收方能够接收的数据量)来避免数据包的丢失和拥塞。如下图所示:
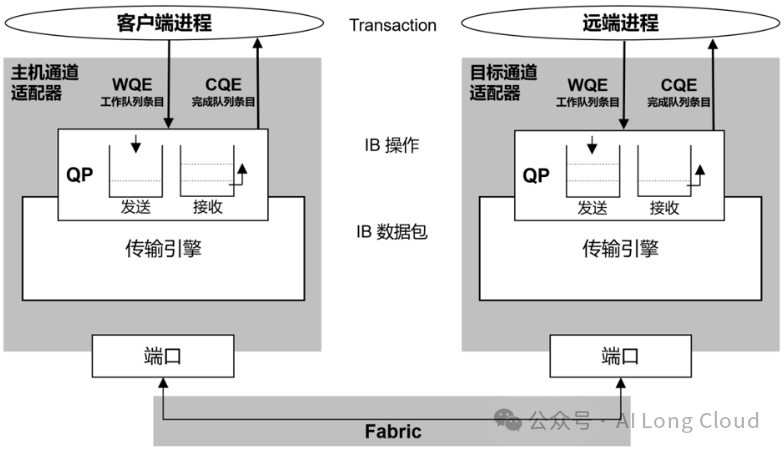
QP是RDMA技术中通信的基本单元。队列偶就是一对队列,SQ(Send Queue,发送工作队列)和 RQ(Receive Queue,接收工作队列)。用户调用API发送接收数据的时候,实际上是将数据放入QP当中,然后以轮询的方式,将QP中的请求一条条的处理。
CBFC技术的优势可以主要概括为三点:
-
避免拥塞:通过动态调整信用额度、无损传输,CBFC技术能够有效地避免网络拥塞和数据包丢失;
-
提高效率:发送方可以在不等待确认的情况下连续发送数据,直到信用额度耗尽,从而提高了数据传输的效率。
-
自动配置:Infiniband设备在物理安装完成后,流控机制即自动工作,无需用户手动配置。
可以看出,InfiniBand 拥有自己定义的 1-4 层(物理层、链路层、网络层、传输层)格式,是一个完整的网络协议。端到端流量控制,是 InfiniBand 网络数据包发送和接收的基础,可以很好的实现无损网络。
当然InfiniBand高速无损网络还有:类似Socket Direct、自适应路由(Adaptive routing)、Subnet Manager子网管理、网络分区、SHARP引擎网络优化等技术和功能,共同组合来实现其高性能、低延迟和易扩展的特性。这里就不展开了。
四、InfiniBand网卡端口、光模块演进
InfiniBand的网络带宽通过技术发展和迭代,从早期的SDR、DDR、QDR、FDR、EDR、HDR,一路升级到NDR、XDR、GDR。其速度是基于 4x 链路速度。如下图所示,该路线图详细阐述了1x、2x、4x和12x端口宽度的发展方向。
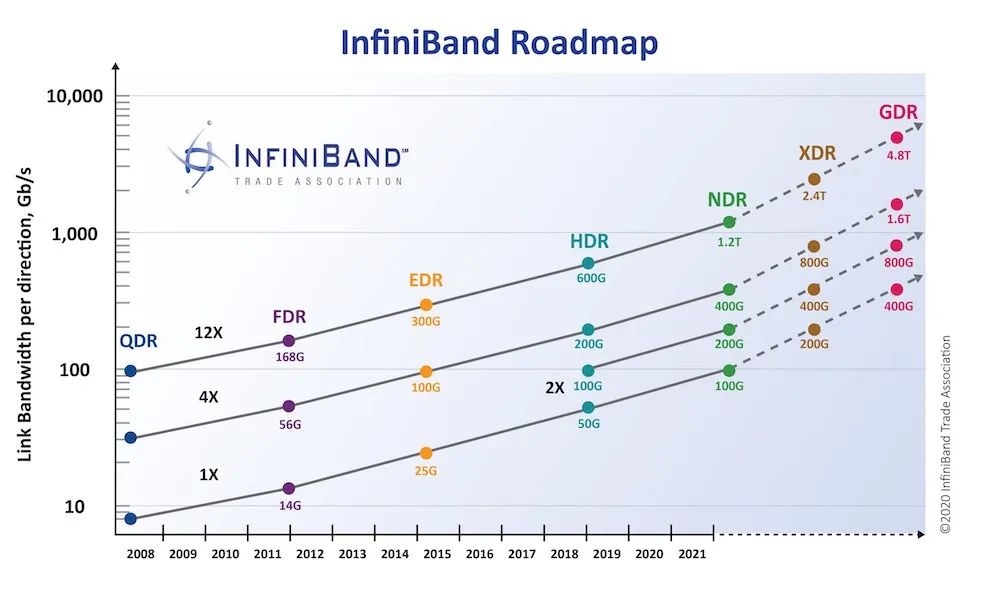
1、InfiniBand网卡端口带宽演进
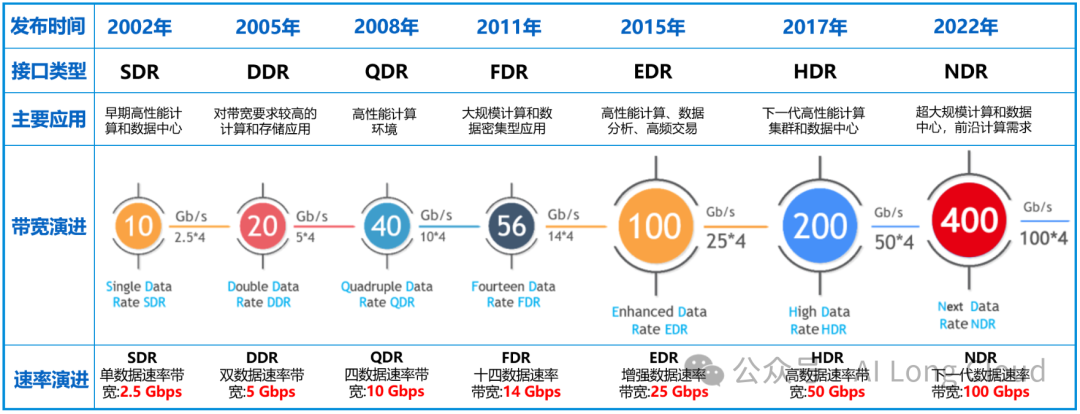
InfiniBand接口速率对比
最新的平台Quantum-X800 更是达到了InfiniBand 800G XDR。但是因XDR和GDR目前还在处于实验阶段,并未推出并投入实际应用,可能还需等等。
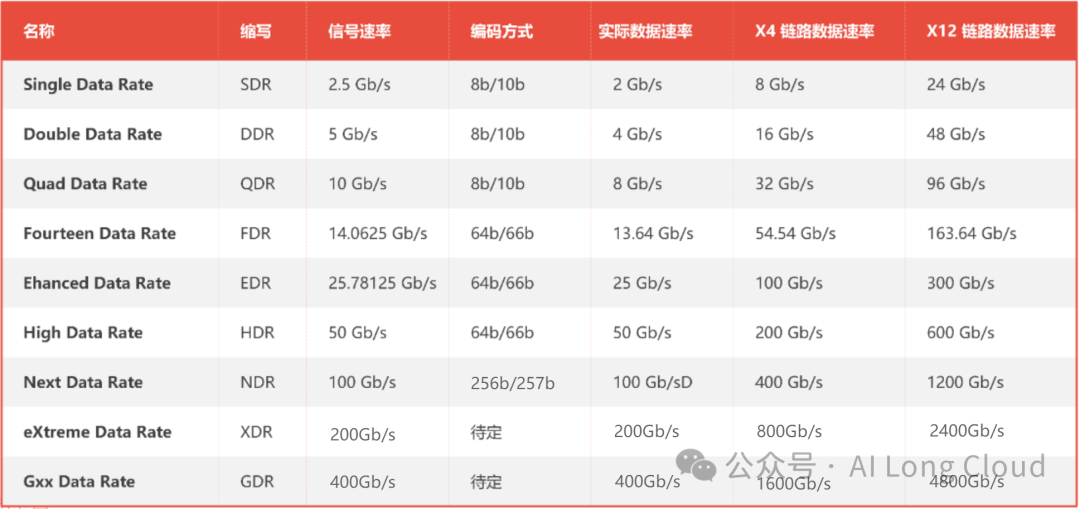
2、光模块及其带宽的演进
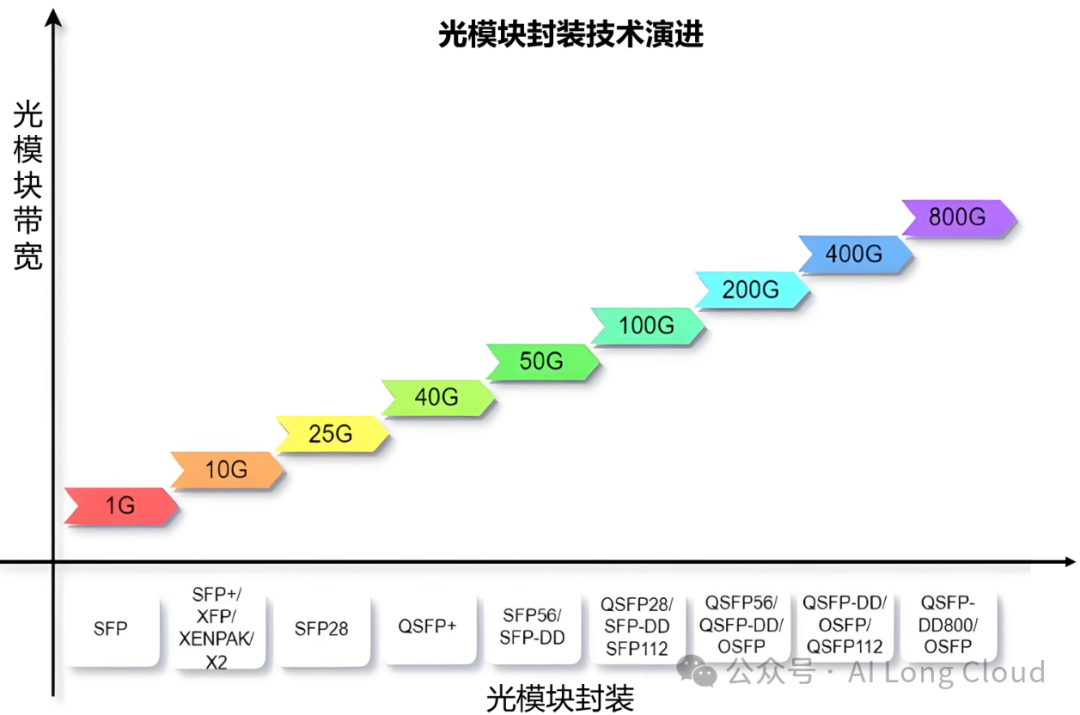
光模块的带宽是跟随光模块的封装技术演进而不断变大的,目前QSFP-DD封装技术,可以到达800G。
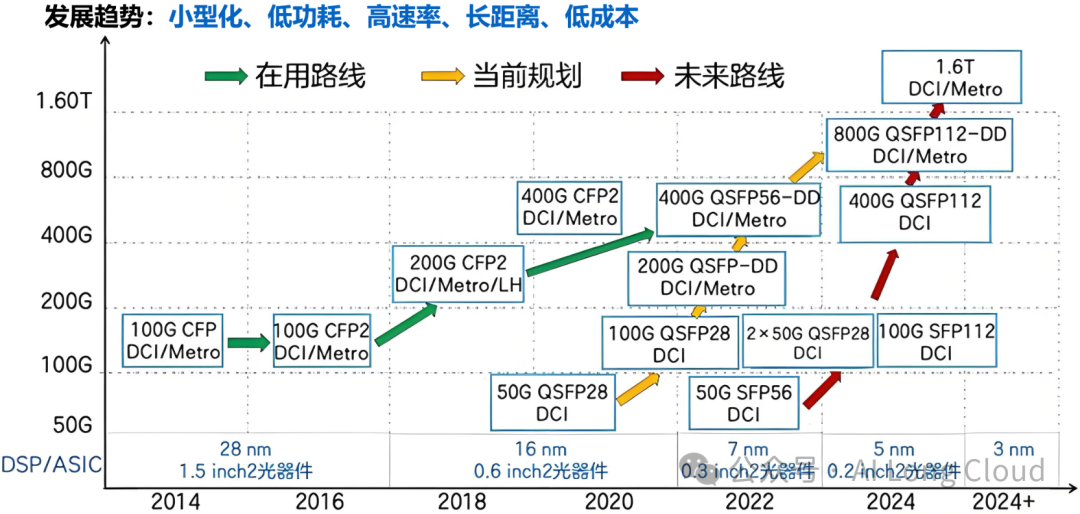
光模块及带宽发展趋势:
五、常见的InfiniBand网络产品
1、InfiniBand交换机
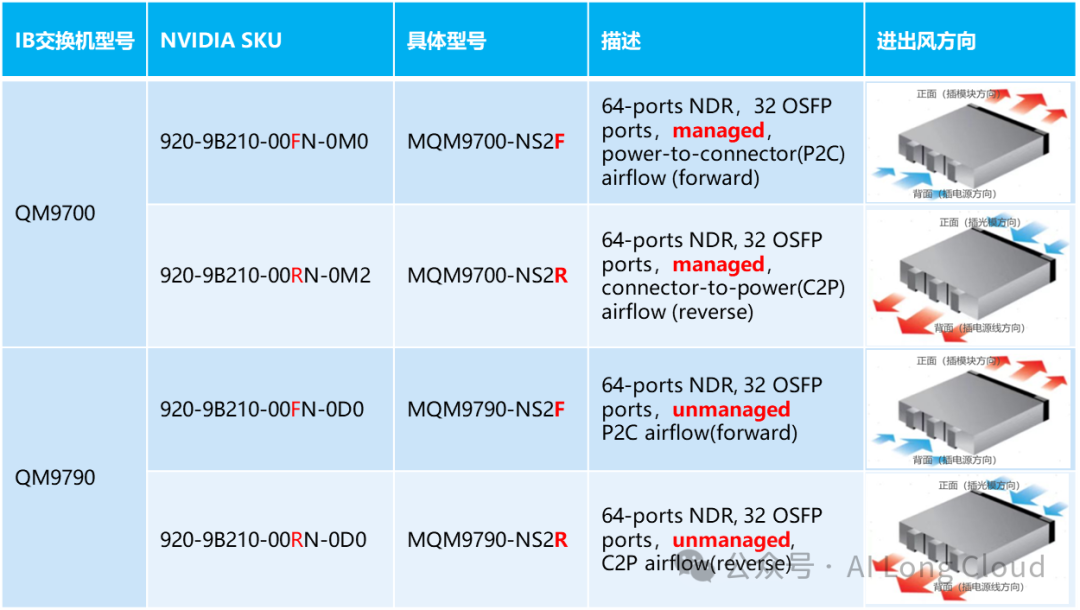
现今,在千卡集群搭建过程中,如果部署IB网络,一般都会要求到400G及其以上的网络,因此NVIDIA Quantum-2 的 QM9700 和 QM9790两款交换机,通常作为IB网络的首选。
QM9700 正面图和背面图,带管理功能


标准机架式64口带管理模块NDR IB交换机,单台可提供64个NDR 400Gb/s IB端口,冗余风扇模块,1+1冗余电源。具体参数可上英伟达的官网查看。
QM9790正面图,不带管理功能

标准机架式64口NDR IB交换机,单台可提供64个NDR 400Gb/s IB端口,冗余风扇模块,1+1冗余电源。但是QM9700是不带管理功能的。具体参数可上英伟达的官网查看。
另外还有个特别需求关注的,就是选择交换机的时候,要选择好具体的型号,需要根据机房及机柜部署方式,选择不一样的交换机的进出风方向,如果选择不对,可能会对综合布线会带来非常大麻烦!
2、InfiniBand网卡
因为目前的IB网络一般要求400G及其以上,因此我们选择对应的网卡都是400G OSFP,以下是英伟达原厂的ConnectX-7 400G OSFP网卡。

ConnectX-7(400G OSFP)是一个 PCIe Gen5 x16 的矮卡。
NVIDIA®ConnectX®-7 系列远程直接内存访问 (RDMA) 网络适配器支持 InfiniBand 和以太网协议以及高达 400Gb/s 的速度。 支持各种智能、可扩展且功能丰富的网络解决方案,可满足传统企业的需求,直至世界上最苛刻的人工智能、科学计算和超大规模云数据中心工作负载。

3、InfiniBand光模块
400G及以上的IB网络,选择的光模块一般就是:NDR光模块,目前市面分别有400G的和800G的,需要根据机房距离来选择使用多模还是单模的,多模一般只能传输50m以内的距离。
多模光模块——MMA4Z00-NS(50m)
单模光模块——MMS4X00-NS(100m)、MMS4X00-NM(500m)。
如:MMA4Z00-NS 800G模块

MA4Z00-NS InfiniBand NDR OSFP2x400G光模块 850nm 50m
MMA4Z00-NS 是一款InfiniBand和以太网800Gb/s 2x400Gb/s 双端OSFP、2xSR4多模,每通道速率为400Gb/s,使用8 根多模光纤,最大光纤传输距离为50米的光模块。主要用于Quantum-2InfiniBand 到两个400Gb/sConnectX-7 OSFP网卡,如下图所示的连接方式。
Spine-Leaf间布线方式

以上就是IB交换机的Spine与Leaf之间的连接,两端分别需要1个800G模块,中间需要连接2条MPO线缆。
Leaf-GPU服务器间的布线方式
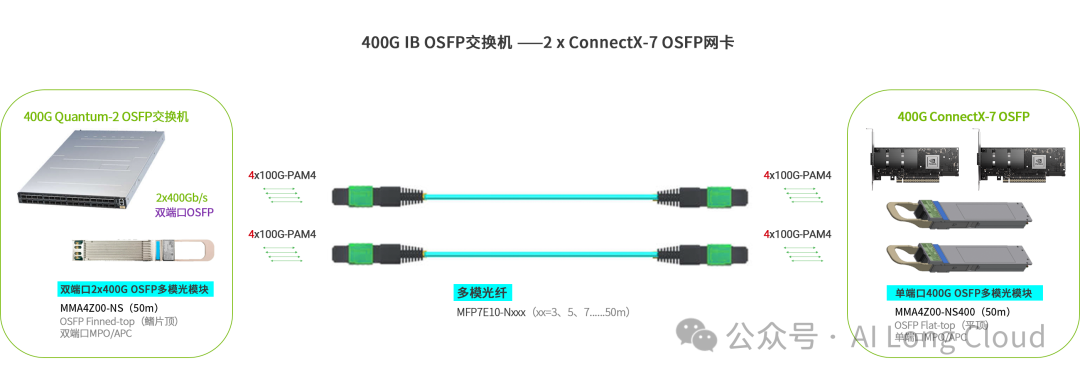
以上就是IB的Leaf交换机与GPU服务器之间的连接,Leaf交换机侧只需要1个800G模块,GPU服务器端可以连接2个400G光卡,中间需要连接2条MPO线缆。
4、InfiniBand线缆
InfiniBand网络中,使用的线缆区别于传统的以太网线缆和光纤线缆。一般需使用专用的InfiniBand线缆。InfiniBand线缆产品包括:DAC高速铜缆、AOC有源线缆。

DAC高速线缆:也叫直连铜缆(Direct Attach Copper cable)。DAC高速线缆的功耗比较低,但传输距离通常低于10米。价格方面相对便宜一些。
AOC有源光缆(Active Optial Cable),功耗相对比较大些,但传输的距离可达到100米,但是价格比较昂贵。
其实随着技术发展,现在的IB网络的线缆不再局限以上2种线缆类型(因为以上的2种线缆确实太贵),现在800G和400G的光模块已经兼容普通的MPO线缆,这里就不展开了,感兴趣的可以私信我,我们共同交流讨论。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)