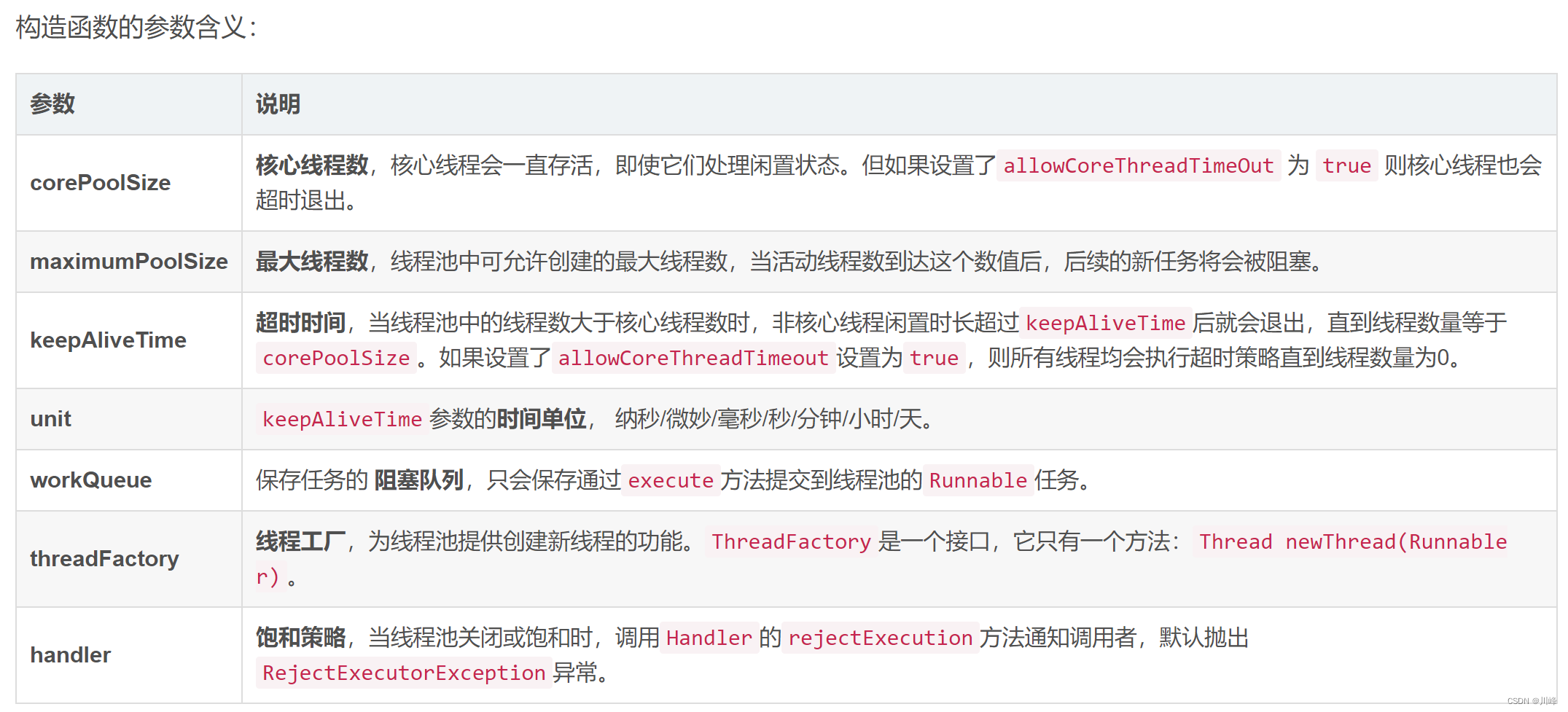
【面试】Java 线程安全&线程池
CPU 密集型任务线程数:建议CPU数 + 1IO 密集型任务线程数:建议CPU数 x 2实现线程池中任务按优先级执行:实现 Runnable, Comparable 接口,在 compareTo 中比较任务优先级进行排序实现线程池的暂停/恢复:利用 ReentrantLock.newCondition() 通过 Condition 的 await()/signal() 实现。
synchronized 同步锁
- 加在普通方法上的
synchronized关键字使用的同步锁的是当前对象,等价于synchronized(this){} - 只有访问同一个对象的同步方法才会同步竞争,访问不同对象的同步方法不会产生竞争,能同时访问执行
- 访问同一个对象的不同的普通同步方法,也会产生竞争,因为它们是使用同一个
this对象,竞争同一个锁 - 加在静态方法上面的
synchronized关键字使用的锁是当前的类对象作为同步锁,等价于synchronized(Foo.class){} - 多个线程同时调用静态同步方法时就会导致竞争
- 2个线程分别调用一个静态同步方法和一个普通同步方法不会竞争,因为它们所使用的加锁对象不同,一个是类的实例对象,一个是
Class类的对象 - 同步代码块必须使用同一个锁对象才有意义,
synchronized (lock)lock 是公用唯一的,不能局部变量,否则每调用一次就会生成一个新的锁对象,达不到锁的目的,锁对象不能为空 - 竞争同步锁失败的线程进入的是该同步锁的就绪(Ready)队列,而不是等待队列,就绪队列时刻准备运行,等待队列只能由他人唤醒
synchronized声明不会被继承,如果一个用synchronized修饰的方法被子类覆盖,那么子类中这个方法不再保持同步,除非用synchronized修饰。
wait()/notify():
wait()释放当前线程的同步锁,使当前线程进入等待状态,直到有其他线程调用notify()或notifyAll()唤醒notify()通知唤醒等待该对象的线程,使该线程从等待状态进入可运行状态,当前线程继续执行,被唤醒的线程不一定立马运行,这取决于当前调用notify的线程是否执行完了synchronized代码块释放了同步锁。如果有多个线程在等待该对象,那么由操作系统指定该执行哪一个。notifyAll()唤醒所有等待该对象的线程,哪一个线程先执行取决于系统实现wait和sleep的区别:wait和notify只能在synchronized代码块中调用,否则会抛异常,sleep可以在任何地方调用。wait进入等待的线程必须由notify来唤醒,而sleep等待的线程到指定时间会自动唤醒执行。wait和sleep都能被中断,响应中断异常。\
synchronized 原理:
- 进入锁释放锁是基于
monitor对象来实现同步的, monitor对象主要有两个指令monitorenter(插入到同步代码开始位置)、monitorexit(插入到同步代码结束的时候),- JVM会保证每个
monitorenter后有monitorexit与之对应,但是可能会有多个monitorexit和同一个monitorenter对应,因为退出的时机不仅仅是方法退出也可能是方法抛出异常。 - 每个对象都有一个
monitor与之关联,一旦持有之后,就会处于锁定状态,当线程执行到monitorenter这个指令时,就会尝试获取该对象monitor所有权 - 监视器锁的原理是通过计数器来实现,通过
monitor-enter让锁计数加1,monitor-exit指令会让锁计数减1
synchronized 缺陷:
- 不够灵活,不能手动释放锁,一旦加锁成功就必须一直等待同步代码块全部执行完毕,或者抛出异常。
- 不能中断正在加锁的线程, 相比于Lock
- 不能获取申请锁的结果是否成功,相比于Lock
- 不能做到读写锁分离
ReentrantLock 重入锁
- 是
Lock接口的实现类,与synchronized一样是可重入锁,只不过比synchronized控制更灵活 - 可以手动调用
lock() / unlock()方法进行加锁和释放锁 - 支持获取锁超时等待
- 可以获取申请锁的结果,成功还是失败
- 可响应中断
- 支持条件锁,通过
Condition#await()或Condition#signal()来等待或唤醒线程,实现更精细的控制 - 支持公平锁(排队)非公平锁(不排队)
ReentrantLock 和 synchronized 区别:
- ReentrantLock和synchronized都是可重入锁
- ReentrantLock是JDK实现的自旋锁封装类,synchronized是JVM实现的,JVM无法感知ReentrantLock
- ReentrantLock支持中断以及超时,synchronized不支持
- ReentrantLock可以手动释放,synchronized只能自动释放
- ReentrantLock支持条件
- ReentrantLock是面向高端客户
volatile 线程可见
- volatile关键字修饰的成员变量可以保证在不同线程之间的可见性,即一个线程修改了某个变量的值,新的值对其他线程来说是立即可见的。
- volatile关键字就是Java用来解决缓存一致性问题的方案(缓存一致性问题有两种解决方案:一种是加同步锁, 另一种是通过缓存一致性协议(MESI))
- 可见性:保证在不同线程间可见,当变量在每次被线程访问时,都强迫从共享内存重新读取该成员的值,当成员变量值每次发生变化时,又强迫将其变化的值重新写入共享内存。
- 有序性:禁止指令重排序。
- volatile不能保证原子性,即不能保证非原子操作的线程安全,只适用于标志位赋值和判断
Atomic 原子类家族,如 AtomicInteger、AtomicBoolean 等
- 原子类内部包装了 CAS 操作,通过CAS来保证同步,无需加锁(号称无锁),提高了性能。
- CAS概念:CAS(Compare-and-swap)是自旋锁,简单来说,就是指在set之前先比较该值有没有变化,只有在没变的情况下才对其赋值,如果有变化就一直while循环。
- CAS是不停的把当前内存的值和寄存器中的值做比较。自旋的设计能够有效避免线程因阻塞-唤醒带来的系统资源开销。
- 在java中,主要是 Unsafe 类
ThreadLocal 本地副本
- ThreadLocal本质上是一种数据隔离,不同线程的使用的是独立的变量副本
- 每一个Thread的内部都持有一个
ThreadLocalMap对象,不共享,而ThreadLocalMap是以ThreadLocal对象为key的Map结构。这些ThreadLocalMap对象的Key可以是同一个ThreadLocal对象。 ThreadLocalMap中以key-value的形式存储Entry键值对,ThreadLocalMap中的Entry类是继承弱引用类持有key的弱引用。


Semaphore 信号量
- Semaphore 是一个计数信号量, 可以用来控制同时访问特定资源的线程数量,适用于那些资源有明确访问数量限制的场景,常用于限流器的实现 。
acquire()获取一个令牌,令牌 - 1,在获取到令牌、或者被其他线程调用中断之前线程一直处于阻塞状态。release()释放一个令牌,令牌 + 1,唤醒一个获取令牌不成功的阻塞线程。- 支持超时等待
- 支持获取申请锁的结果,成功还是失败
CountDownLatch 计数器
- CountDownLatch是一个减计数器,可以控制多个线程的并发执行。
await():调用该方法的线程会被阻塞,直到构造方法传入的N减到0的时候,才能继续往下执行;countDown():使计数值减1;如果计数到达0,则释放所有等待的线程countDown()的调用放在finally可以保证一定被调用,防止某些情况下判断条件不执行- 场景:让多个线程一起同时开始执行
- 场景:单个线程等待多个线程执行完毕,进行汇总合并,如详情页面我们可能会请求多个接口,最终合并到一起进行处理展示
CountDownLatch的缺陷:
- CountDownLatch是一次性的,计算器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当CountDownLatch使用完毕后,它不能再次被使用。
CountDownLatch 和 Semaphore区别:
CountDownLatch的值大于0,调用await()会阻塞,等于0才能继续,countDown()使计数值 减1Semaphore可用令牌数大于0才可继续执行,小于0会阻塞,acquire()使令牌数减1,release()使令牌数加1
Concurrent 线程安全的集合类,如ConcurrentHashMap等
- 与 HashTable 相比,HashTable 也是线程安全的集合类,但是 HashTable 是对整个对象加锁,HashTable源码当中的几乎每个操作方法像 get()、put()、size() 等都加了 synchronized 关键字,也就是对几乎每个操作方法都加了锁,很显然,虽然简单粗暴的保证了线程安全,但效率低下。
HashTable的问题:
- 大锁:对整个对象加锁
- 长锁:直接对整个方法加锁
- 读写锁共用:只有一把锁,从头锁到尾
ConcurrentHashMap的做法:
- 小锁:分段锁(JDK7),桶点锁(JDK8)
- 短锁:先尝试获取,失败再加锁
- 读写锁分离:读失败再加锁,volatile 读 CAS 写
ConcurrentHashMap 将HashMap数据结构使用分段锁的思想进行细分化。
- JDK1.7之前,若干长度数组作为一个 segment段,每个段进行加锁,其中segment 继承了 ReentrantLock 重入锁。
- JDK1.8 之后,ConcurrentHashMap 抛弃了大的分段锁,将锁的粒度更加细分化,直接以每个数组索引为锁来进行实现。比如HashMap数组中长度有128,那么就会存在128个锁将每个索引锁住。这样相比于JDK1.7之前在效率上有了很大的改进。
- 源码中大量使用了 volatile 变量和 CAS 操作来保证安全
CopyOnWriteArrayList
- 只有写操作加锁,读不会加锁,因为读是直接定位 volatile 的数组对象中获取
- 内存占用高:如果 CopyOnWriteArrayList 要频繁修改数据,每次执行 add()、set()、remove() 等方法时,内部都会 copy 一份数组,内存占用率很高。
- 数据一致性风险:CopyOnWrite 容器只能保证数据的最终一致性,不能保证数据的实时一致性。
Collections.synchronizedxxx方法
- Collections 类提供了一些以 synchronized 开头的方法,可以方便的将普通的非线程安全集合转化为线程安全的集合对象,如 Collections.synchronizedMap、Collections.synchronizedList 等等。
- 内部实现是每个方法都加了 synchronized 同步关键字,效率低下
ReadLock/WriteLock 读写锁
ReentrantReadWriteLock内部维护了两个锁:
- 读操作锁,称为共享锁(所有线程均可同时获得,并发量高,比如在线文档查看)
- 写操作锁,称为排他锁(同一时刻只有一个线程有权修改资源,比如在线文档编辑)
特性:
- 公平选择性:支持公平锁和非公平锁(默认)的获取锁的方式;
- 可重入性:读写锁都支持线程重入
- 锁降级:写锁能够降级成为读锁。
- 可中断:读锁和写锁都支持锁获取期间的中断;
- Condition支持:写入锁提供了一个 Conditon 实现;读取锁不支持 Conditon。
锁的优化
- 长锁不如短锁,尽可能只锁必要部分,不要对线程安全类的所有方法都进行同步,只对那些会改变共享资源方法的进行同步。
- 如果可变类有两种运行环境,单线程环境和多线程环境,则应该为该可变类提供两种版本:线程安全版本和线程不安全版本(没有同步方法和同步块)。在单线程中环境中,使用线程不安全版本以保证性能,在多线程中使用线程安全的版本。
- 只有共享资源的读写访问才需要同步。如果不是共享资源,那么就根本没有同步的必要。(如ThreadLocal)
- 避免共享变量,或共享不可变的资源。只有“变量”才需要同步访问。如果共享的资源是固定不变的,那么就相当于“常量”,线程同时读取常量也不需要同步。如使用 final 实现不可变量,无需 volatile 就能保证线程可见性。
- 减小锁的颗粒度,同步的代码段范围越小越好,可将同步方法改成同步代码块,以便更加精细的控制锁的范围。
- 减少加锁的次数,合并访问相同共享资源的锁,将访问相同的资源的的多次加锁进行合并成只加一次锁,或者将访问相同资源的不同锁对象合并成一个锁对象。
- 读写锁分离,只要有写锁进入才需要做同步处理,但是对于大多数应用来说,读的场景要远远大于写的场景,因此一旦使用读写锁,在读多写少的场景中,就可以很好的提高系统的性能。
- 减少持锁时间, 尽管锁在同一时间只能允许一个线程持有,其它想要占用锁的线程都得在临界区外等待锁的释放,这个等待的时间我们希望尽可能的短。
- 锁粗化 ,尽可能的合并处理频繁过短的锁
- 尽量避免嵌套锁,使用扁平锁替代,避免死锁
- 消除无用锁,能不加锁尽量不加,或使用 volatile 代替。

线程死锁
- 发生死锁的根本原因是:在申请锁时发生了交叉闭环申请。即线程在获得了锁A并且没有释放的情况下去申请锁B,这时,另一个线程已经获得了锁B,在释放锁B之前又要先获得锁A,因此闭环发生,陷入死锁循环。
死锁必要条件:
- 互斥
- 请求和保持(占有且等待)
- 不可剥夺
- 循环等待
如何避免死锁
- 调整申请锁的顺序:当几个线程都要访问共享资源A、B、C 时,保证每个线程都按照相同的顺序申请锁和释放锁。
- 调整申请锁的范围:尝试减小锁的申请范围,避免锁的申请发生闭环。
- 避免一个线程同时获取多个锁。避免在一个资源内占用多个 资源,尽量保证每个锁只占用一个资源。
- 尝试使用超时锁,使用
tryLock(timeout)来代替使用内部锁机制,在一定时间内无法获取锁就退出或抛异常。 - 避免同步嵌套的发生,尽量避免在一个对象的同步块内调用另一个对象的同步方法。
死锁的简单例子:
如何实现线程安全?

这里有两个点要注意:1. 可变, 2. 共享,如果资源既不可变,或不共享,那其实不会存在线程安全问题。
- 从不可变角考虑度就是尽量确保资源不可变,如使用
final关键字 - 从不共享角度考虑就是尽量确保资源不同享,如使用
ThreadLocal,还有使用静态方法它访问的资源是不共享的
final 的作用:1. 保证资源不可变 2. 禁止重排序
同样,使用 volatile 关键字,也可以保证禁止重排序,如果你不加这个,像下面的单例模式,可能导致构造方法的执行顺序不一定在前面,其他线程可能得到一个未初始化完毕的对象。


也就是说,final static 和 volatile static 这两种方式都能保证禁止重排序




线程中断
void interrupt():向线程发送中断请求,线程的中断状态将会被设置为true,如果当前线程被一个sleep调用阻塞,那么将会抛出interrupedException异常。boolean isInterrupted():判断线程是否被中断,这个方法的调用不会产生副作用即不改变线程的当前中断状态。
线程优先级
- Java的线程的优先级具有继承性,在某线程中创建的线程会继承此线程的优先级。那么我们在UI线程中创建了线程,则线程优先级是和UI线程优先级一样,平等的和UI线程抢占CPU时间片资源。
- JDK Api 通过
getPriority()和setPriority()获取和设置优线程的先级,取值范围为[1~10], 优先级越高,获取CPU时间片的概率越高。UI线程优先级为5。 - Android Api 通过
Process.getThreadPriority()和Process.setThreadPriority()可以为线程设置更加精细的优先级(-20~19),优先级priority的值越低,获取CPU时间片的概率越高。UI线程优先级为-10。
线程池
execute 和 submit 的区别:
- submit 既能提交 Runnable 也能提交 Callable 类型的任务,返回一个 Future 对象,以便将来通过 Future.get() 方法获取返回值。
- execute 只能提交 Runnable 类型的任务,是 void 方法,没有返回值
- execute 方法提交的任务异常是直接抛出的,而 submit 方法是是捕获了异常的,当调用 Future.get() 方法时,才会抛出异常。
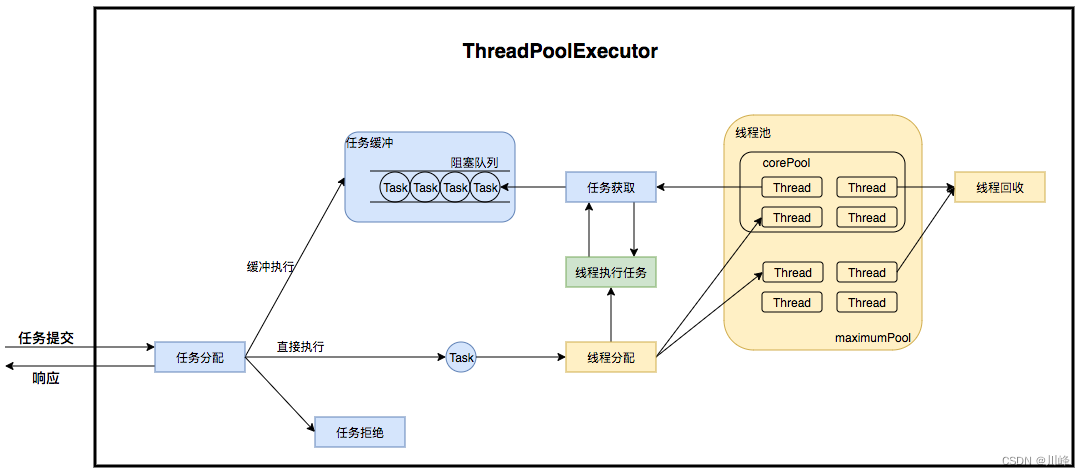
线程池执行任务过程:
- 当线程数小于核心线程数时,创建线程。
- 当线程数大于等于核心线程数,且任务队列未满时,将任务放入任务队列。
- 当线程数大于等于核心线程数,且任务队列已满
a). 若线程数小于最大线程数,创建线程
b). 若线程数等于最大线程数,抛出异常,拒绝任务
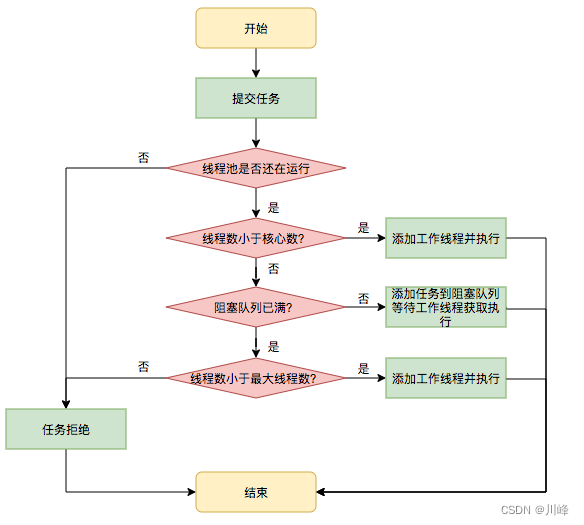
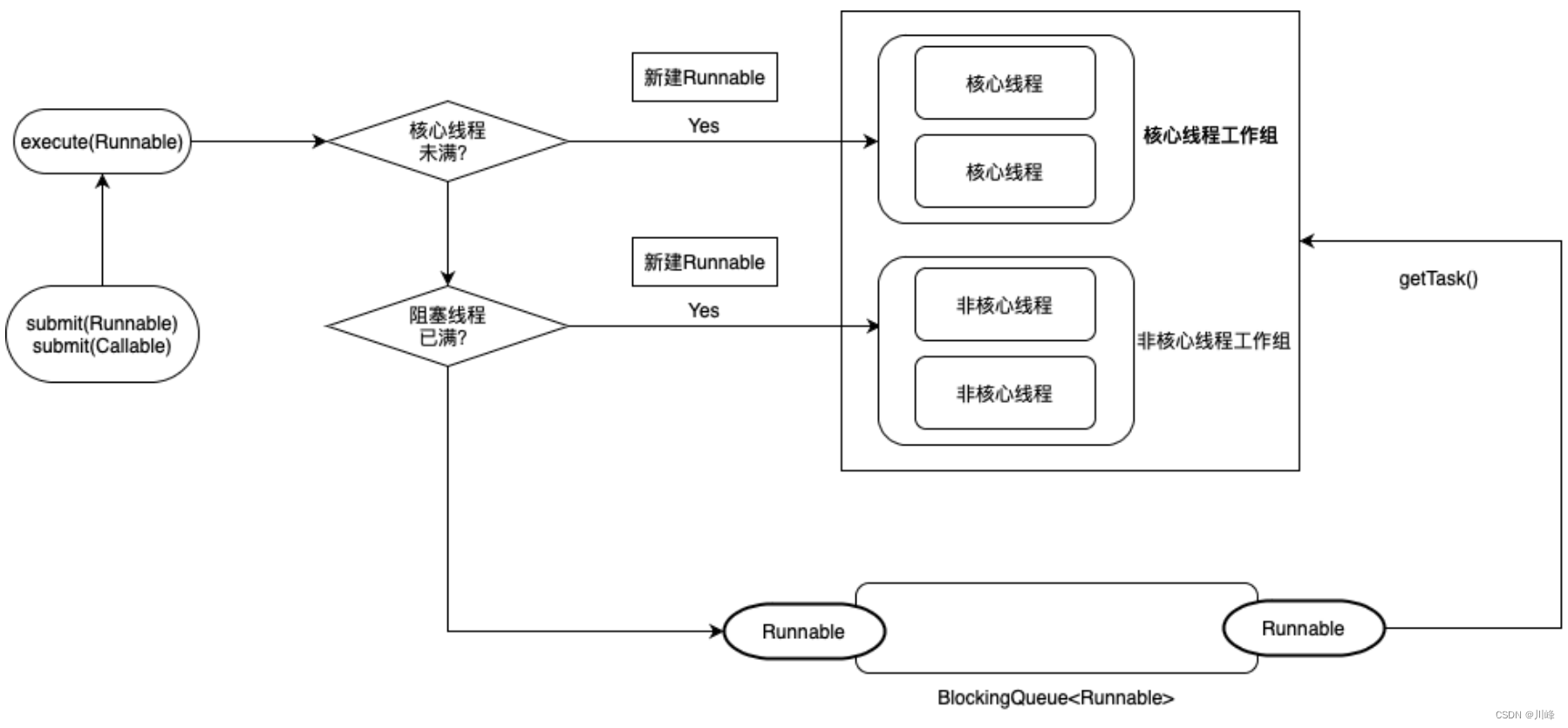
简单来说就是优先核心线程,其次等待队列,最后非核心线程。
JDK自带的几种线程池:
Executors.newFixedThreadPool(); // 固定线程数的线程池
Executors.newSingleThreadExecutor(); // 线程数为1的线程池
Executors.newCachedThreadPool(); // 可复用线程池
Executors.newScheduledThreadPool(); // 可执行定时任务的线程池
Executors.newSingleThreadScheduledExecutor(); // 单线程执行定时任务的线程池
Executors.newWorkStealingPool(); // 抢占式操作的线程池
FixedThreadPool
- 最大特点是
corePoolSize = maximumPoolSize,即核心线程数和最大线程数相等。 - 如果当前运行线程数少
corePoolSize,则创建一个新的线程来执行任务。 - 当前线程数量达到
corePoolSize后,新的任务将加入LinkedBlockingQueue队列中等待。 - 线程池中线程任务执行完毕后,会循环中反复从
LinkedBlockingQueue获取任务来执行 - 由于使用无界队列,运行中的
FixedThreadPool不会拒绝任务,所以不会去调用RejectExecutionHandler的rejectExecution方法抛出异常。 FixedThreadPool使用的LinkedBlockingQueue的默认大小是Integer.MAX_VALUE,因此是无界队列,这也会导致一个缺点就是运行时可能造成大量任务的堆积。
SingleThreadExecutor
- 核心线程数和最大线程数都是1。
- 使用无界队列,它的缺陷也和FixedThreadPool相同
- 如果当前线程池中线程正在执行任务,新添加的任务同样会被加入到无界队列中等待执行
- 任务按顺序执行,同一时刻保证只有一个任务会被执行
CachedThreadPool
- 适合处理大量任务周期比较短的异步任务场景,它的最大特点是核心线程数为 0,最大线程数无限制 Integer.MAX_VALUE
- 闲置超时时间是
60s - 缺陷:如果主线程提交任务的速度高于线程池中线程处理任务的速度时,CachedThreadPool将会不断的创建新的线程,在极端情况下,可能会因为创建过多线程而耗尽CPU和内存资源。
ScheduledThreadPool
- 是使用的单独的一个类,适用于延时或周期性定时的执行后台任务
- 最大线程数也没有限制(Integer.MAX_VALUE),使用的阻塞队列为延时优先级队列DelayedWorkQueue(无界队列),DelayedWorkQueue保证添加到队列中的任务,按照任务的延时时间进行排序,延时时间少的任务首先被获取。
SingleThreadScheduledExecutor
- 同ScheduledThreadPool, 只不过是创建一个核心线程数为1的单线程来执行
WorkStealingPool
- 是JDK 1.8新增的线程池,利用的类是 ForkJoinPool, ForkJoinPool 适用于CPU密集型任务,适合进行大量计算,可以拆分成子任务,进行分治递归处理,最后合并处理结果。
自定义线程池
- CPU 密集型任务线程数:建议CPU数 + 1
- IO 密集型任务线程数:建议CPU数 x 2
- 实现线程池中任务按优先级执行:实现 Runnable, Comparable 接口,在 compareTo 中比较任务优先级进行排序
- 实现线程池的暂停/恢复:利用 ReentrantLock.newCondition() 通过 Condition 的 await()/signal() 实现
- 实现异步任务结果主动切换到主线程:任务执行结果发送到主线程的 Handler, mainHandler.post(Runnable)
关闭线程池
- shutdown(): 之前提交的任务会继续执行,但不会接受新的任务。
- shutdownNow(): 尝试停止所有正在执行的任务,不再处理还在池队列中等待的任务,并返回等待执行的任务列表
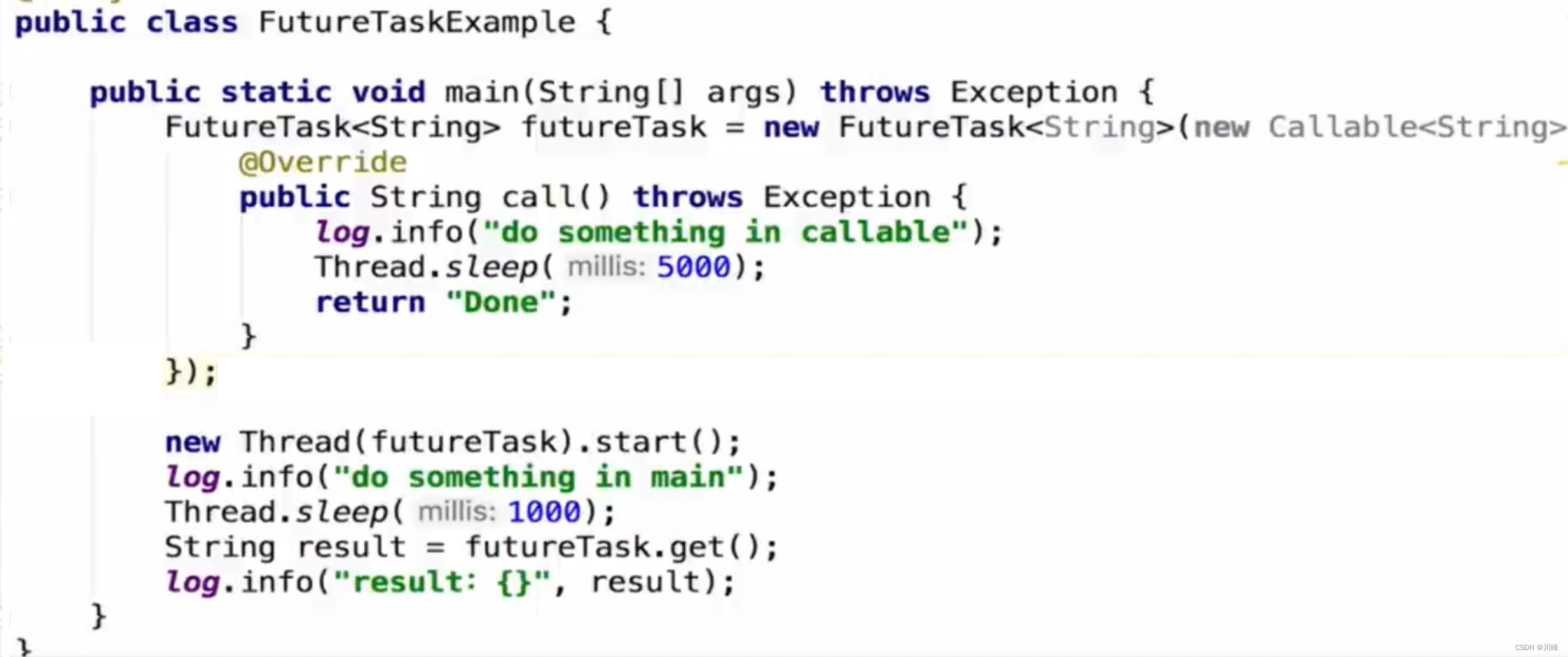
FutureTask


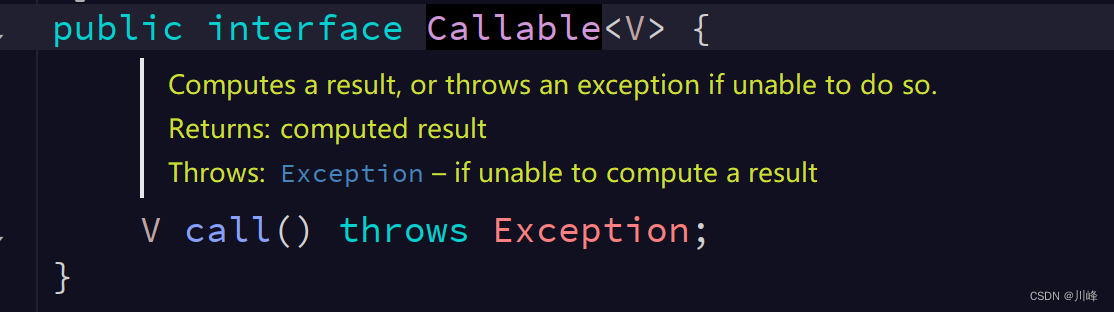
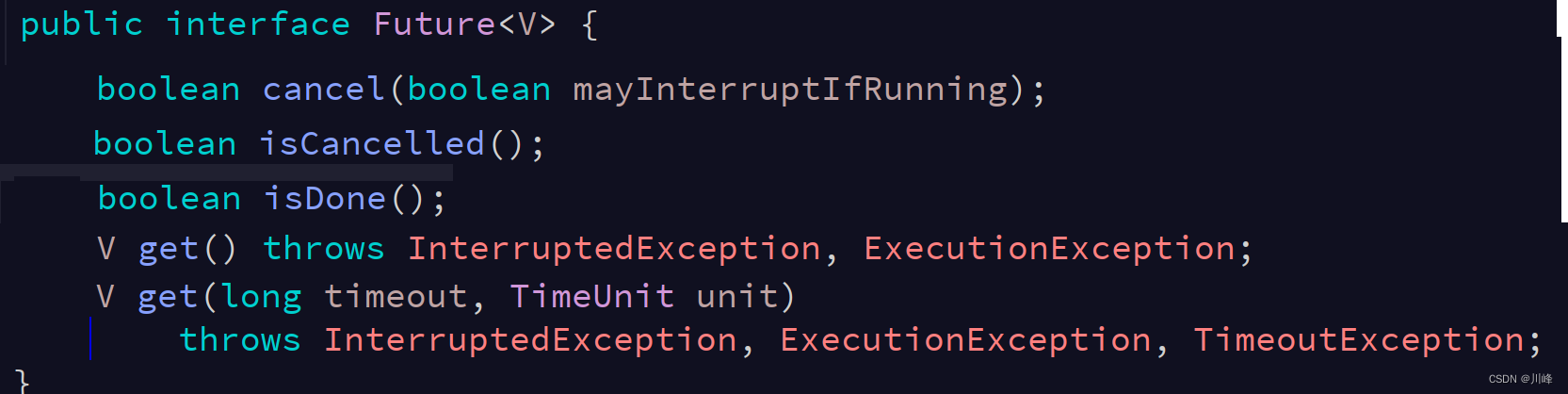


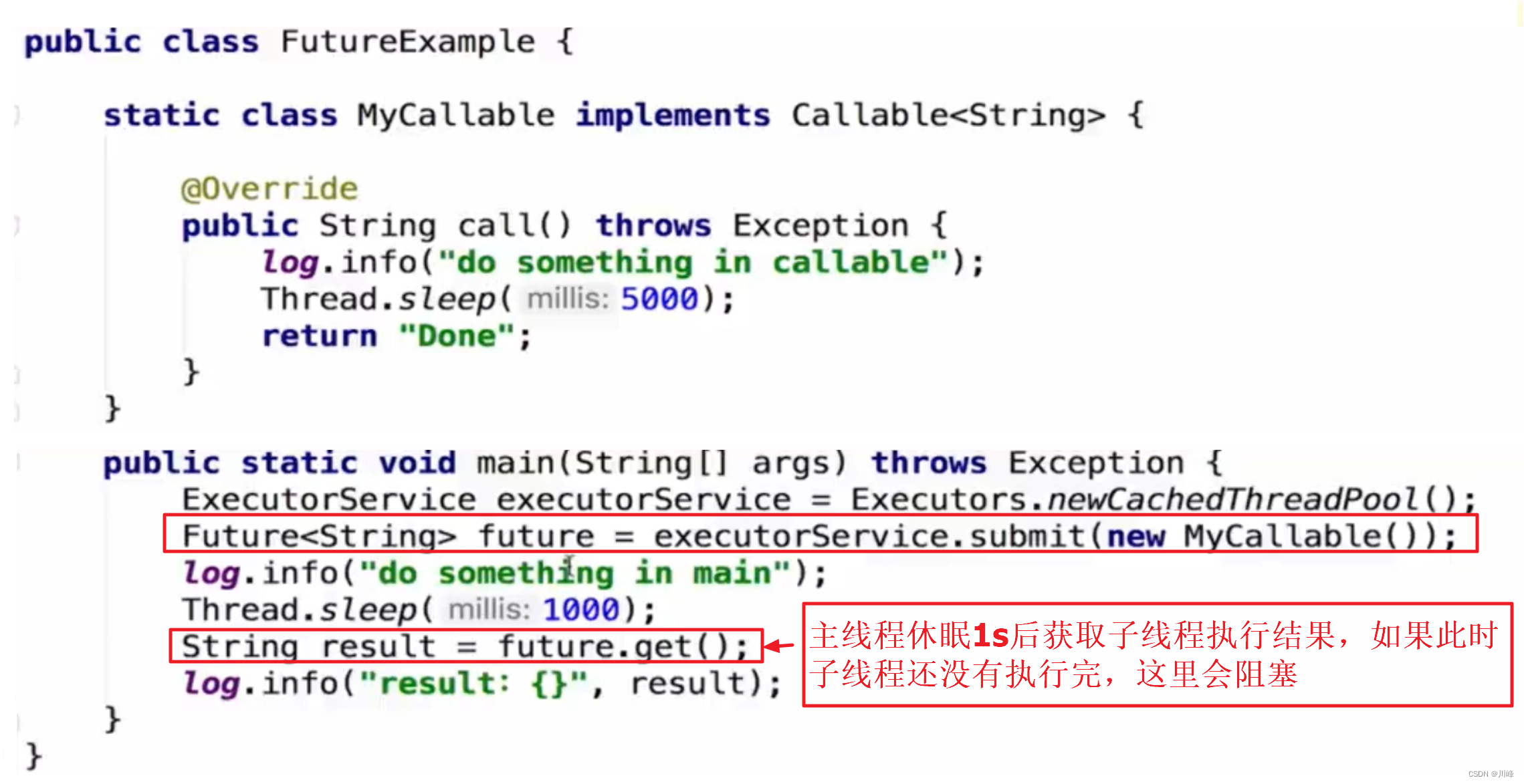

可以看到线程池可以接收一个Callabe接口返回一个Future接口,在调用者线程需要结果的时候通过future.get结果即可。
而FutureTask也可以接收一个Callabe接口,我们将FutureTask丢入线程中运行,在调用者线程需要结果的时候仍然可以通过futureTask的get方法获取到。FutureTask也可以直接提交到线程池中运行。
使用FutureTask在不同线程之间获取结果时非常方便。
BlockingQueue 阻塞队列
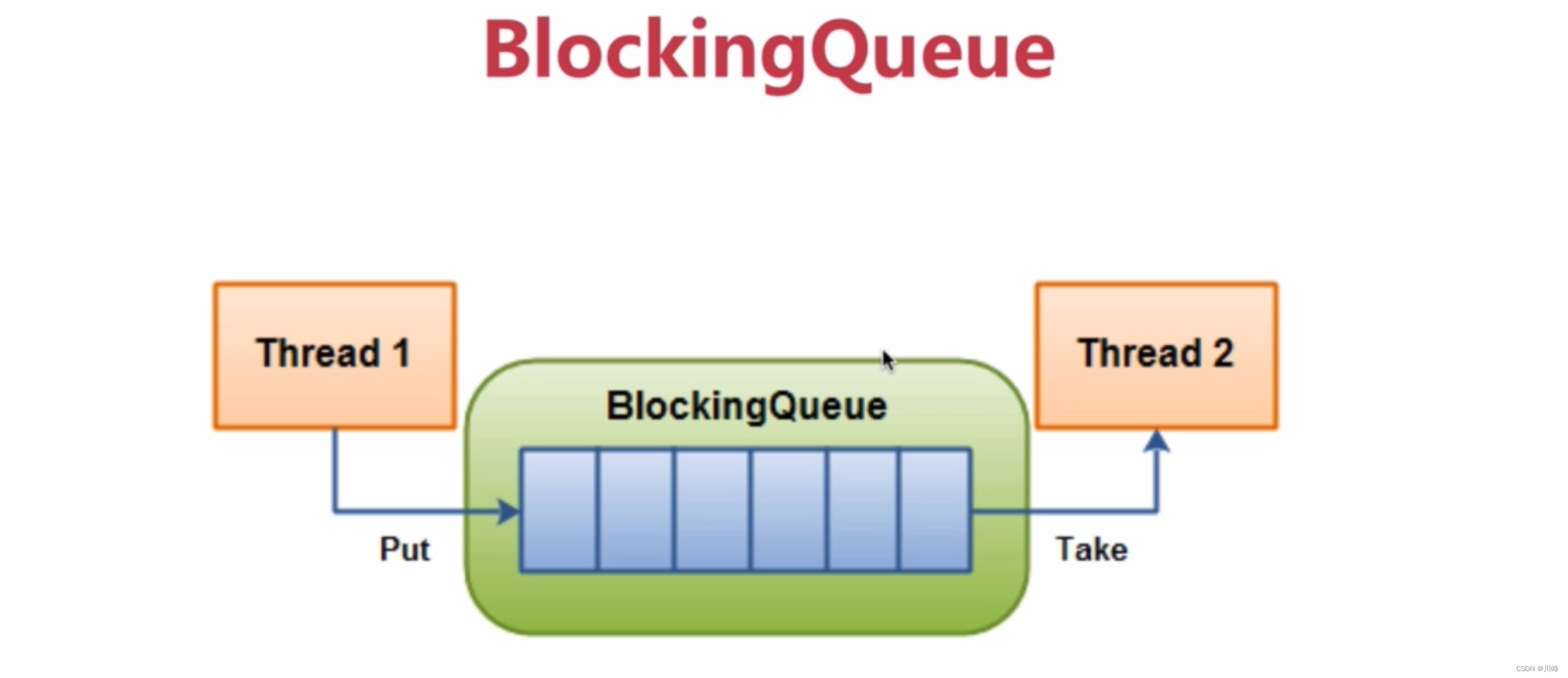
- BlockingQueue 是一个阻塞队列,是线程安全的,主要用于生产者/消费者模型。
- 生产者线程不断生产新的对象放入队列,直到达到队列的最大值,消费者线程负责从队列中取不断消费对象。
- 当队列已满时,生产者线程将被阻塞,直到消费者线程对队列进程出队操作,
- 当队列为空时,消费者线程将被阻塞,直到生产者线程对队列进行入队操作。
- 不能向
BlockingQueue插入一个空对象,否则会抛出NullPointerException。
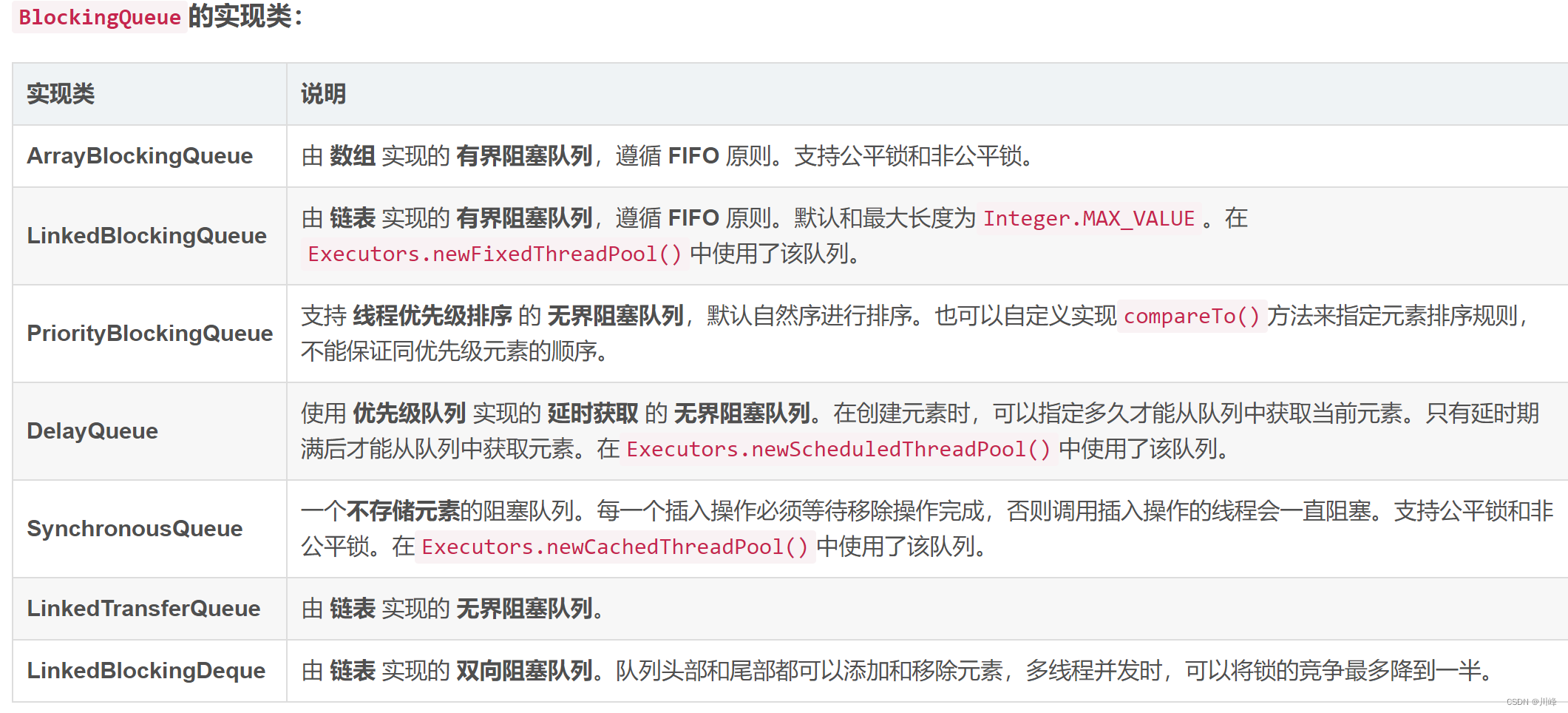
BlockingQueue是线程安全的
当队列满的时候进行入队操作,或者队列空的时候进行出队操作,会阻塞。
用于生产者消费者,生产者不断生产新对象加入到队列直到达到上限值,消费者不断从队列消费对象直到队列为空。
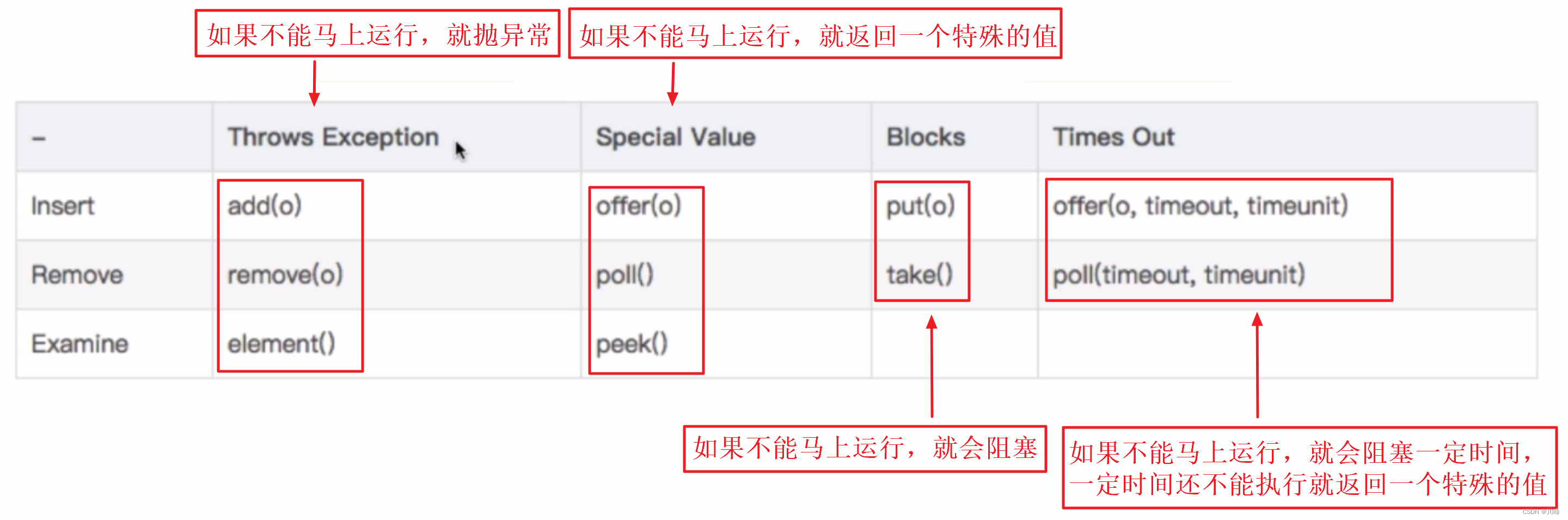





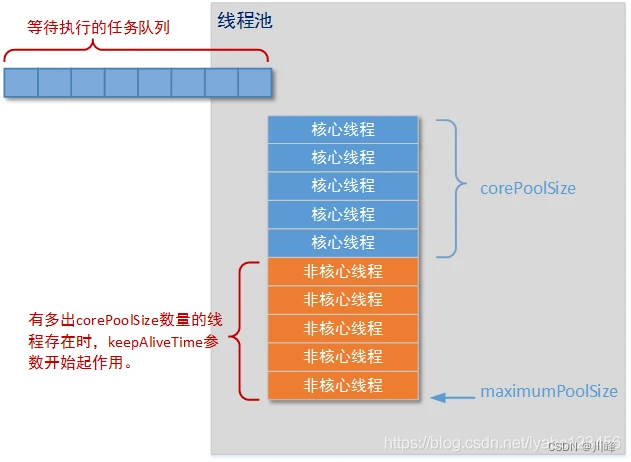
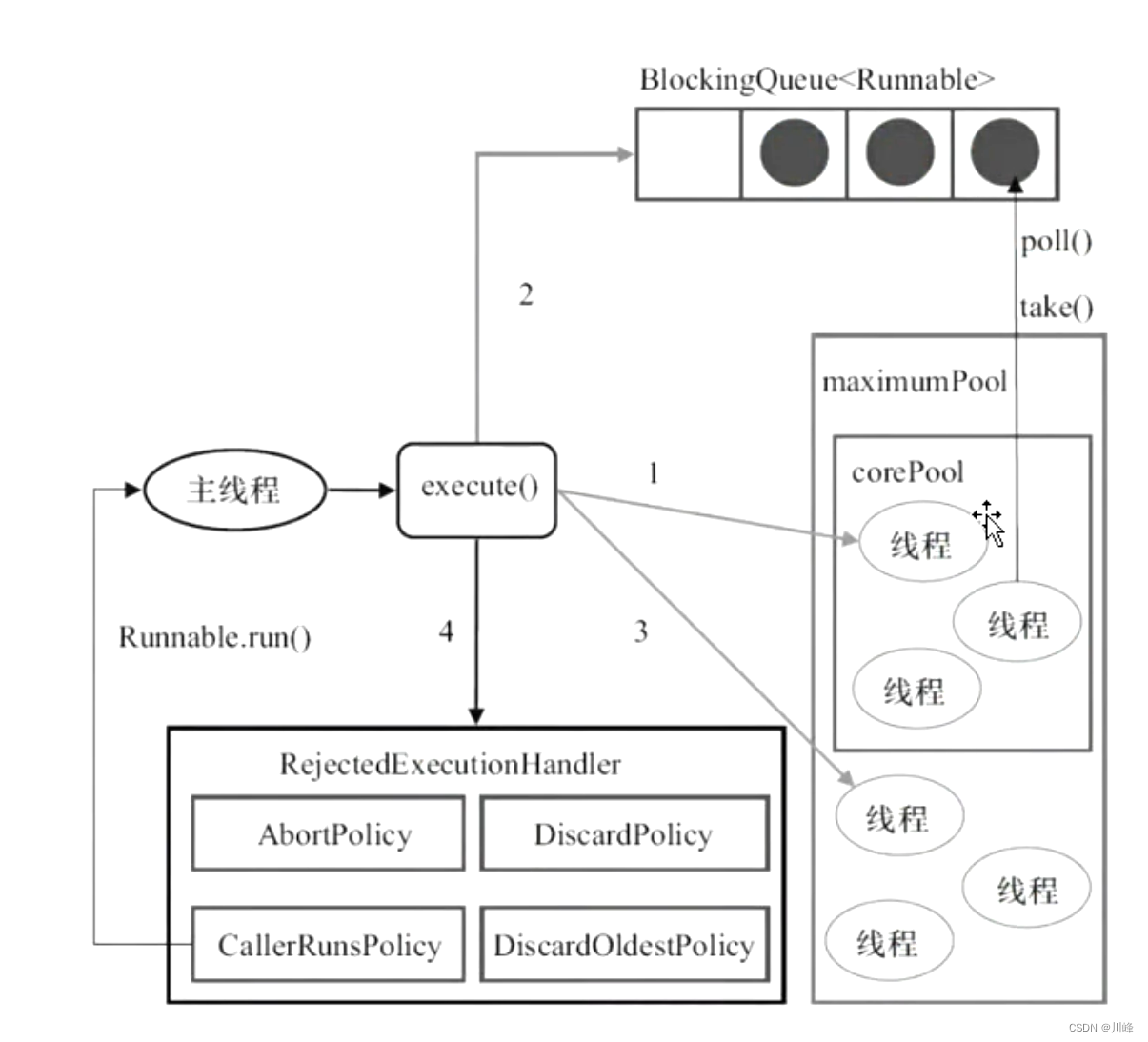
线程池中添加任务的顺序:1.corePool 2.BlockingQueue 3.maximumPool

每分钟调用以上方法,可以监控线程池状态

线程池不用的时候,不要忘记调用 shutdown() 方法
Executors.newScheduledThreadPool 和 Timer 类的功能类似


合理地配置线程池
要想合理地配置线程池,就必须首先分析任务特性,可以从以下几个角度来分析。
- 任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
- 任务的优先级:高、中和低。
- 任务的执行时间:长、中和短。
- 任务的依赖性:是否依赖其他系统资源,如数据库连接。
性质不同的任务可以用不同规模的线程池分开处理。
- CPU密集型任务:应配置尽可能小的线程,如 NCPU + 1
- IO密集型任务:由于IO密集型任务线程并不是一直在执行任务,则应配置尽可能多的线程,如 2*NCPU
- 混合型的任务:如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。可以通过
Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列 PriorityBlockingQueue 来处理。它可以让优先级高的任务先执行。
执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。
建议使用有界队列。有界队列能增加系统的稳定性和预警能力,可以根据需要设大一点儿,比如几千。如果当时我们设置成无界队列,那么线程池的队列就会越来越多,有可能会撑满内存,导致整个系统不可用,而不只是后台任务出现问题。
线程池是怎么复用线程的?
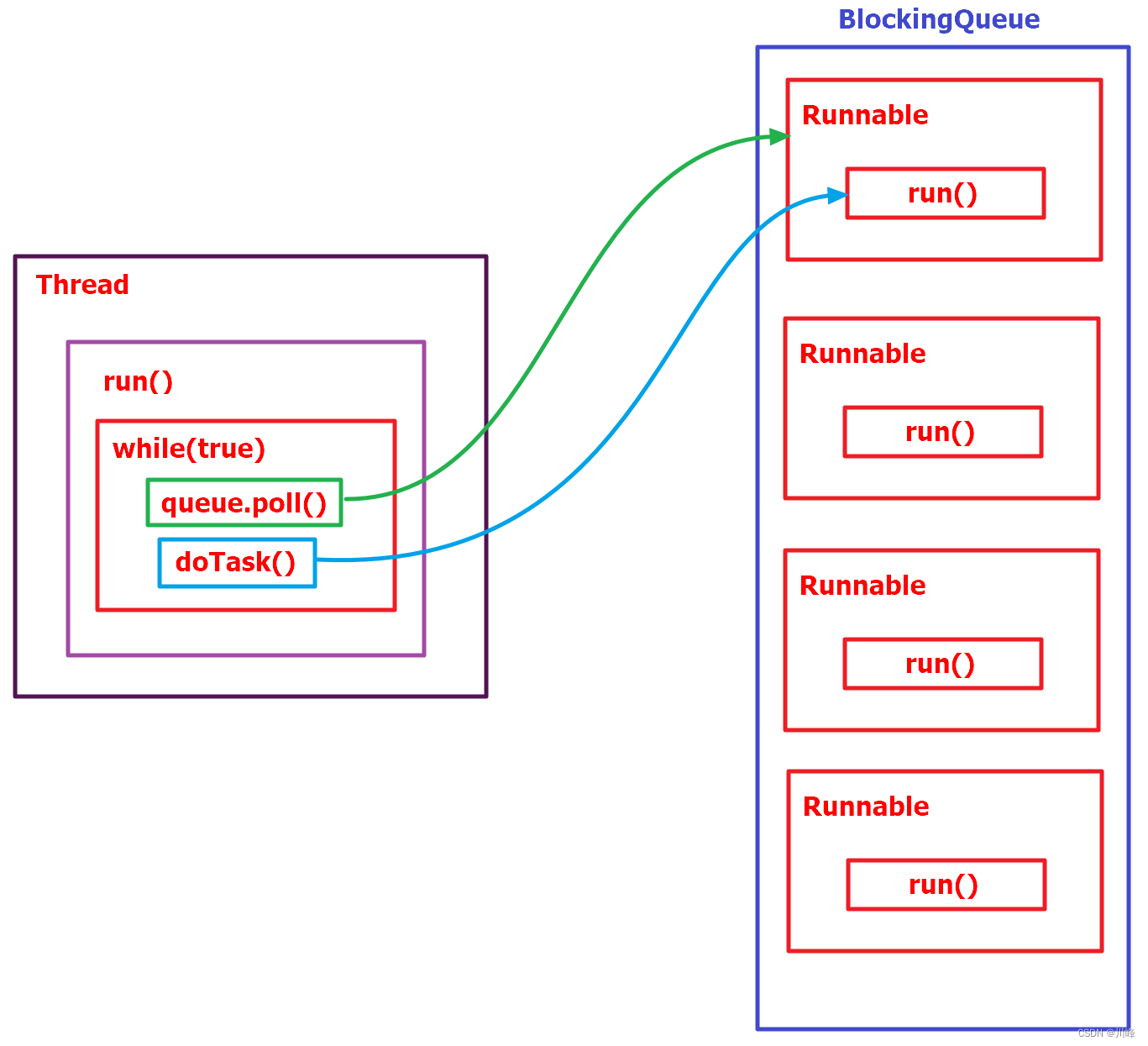
- 线程池将线程和任务进行解耦,线程是线程,任务是任务,摆脱了通过Thread创建线程时,一个线程必须对应一个任务的限制。
- 在线程池中,同一个线程可以从阻塞队列中不断获取新任务来执行,其核心原理在于线程池对Thread进行了封装,并不是每次执行任务都会调用Thread.start()来创建新线程,而是让每个线程去执行一个“循环任务”,在这个“循环任务”中不停检查是否有任务需要被执行,如果有则直接执行,也就是调用任务中的run方法,将run方法当成一个普通方法执行,通过这种方式只使用固定的线程将所有任务的run方法串联起来。
- 源码中ThreadPoolExecutor中有个内置对象Worker,每个worker都是一个线程,worker线程数量和参数有关,每个worker会while死循环从阻塞队列中取数据,通过置换worker中Runnable对象,运行其run方法起到线程置换的效果,这样做的好处是避免多线程频繁线程切换,提高程序运行性能。
线程池被创建后里面有线程吗?如果没有的话,你知道有什么方法对线程池进行预热吗?
线程池被创建后如果没有任务过来,里面是不会有线程的。如果需要预热的话可以调用下面的两个方法:
- 全部启动:
prestartAllCoreThreads() - 仅启动一个:
prestartoreThread()
核心线程数会被回收吗?需要什么设置?
- 核心线程数默认是不会被回收的,如果需要回收核心线程数,需要调用下面的方法:
allowCoreThreadTimeOut()即设置允许核心线程超时 (将allowCoreThreadTimeOut值改为true,默认为false)
AtomicReference 和 AtomicReferenceFieldUpdater 有何区别?
- 二者的方法使用上差别不大,原理都是基于
Unsafe类的CAS操作,设置值都是调用compareAndSet(),获取值都是调用getAndUpdate()或者getAndSet()方法(Android要求API Level 24才能用getAndUpdate())。 - ARFU 更省内存,如果是开发框架内频繁使用 ARFU 比较适用,而 AR 使用更加友好,但是 AR 内部会多占用额外的字节空间。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)