NVIDIA NIM 推理微服务介绍
NIM 是 **GPU 加速的推理微服务套件**,核心架构为“预优化容器 + 标准化接口 + 多环境适配”容器化封装:每个 NIM 对应一个 Docker 容器,内置模型文件 + 推理引擎(TensorRT-LLM/VLLM/SGLang) + 运行时依赖,支持 Llama 3.1、GPT-4o 等主流模型;标准化 API:提供与 OpenAI 兼容的等接口,同时支持 NVIDIA 扩展功能(如工
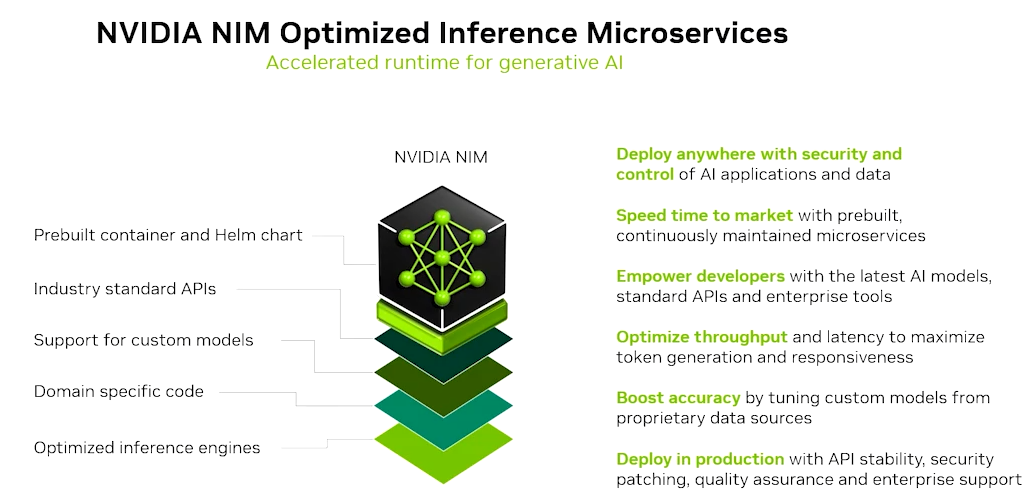
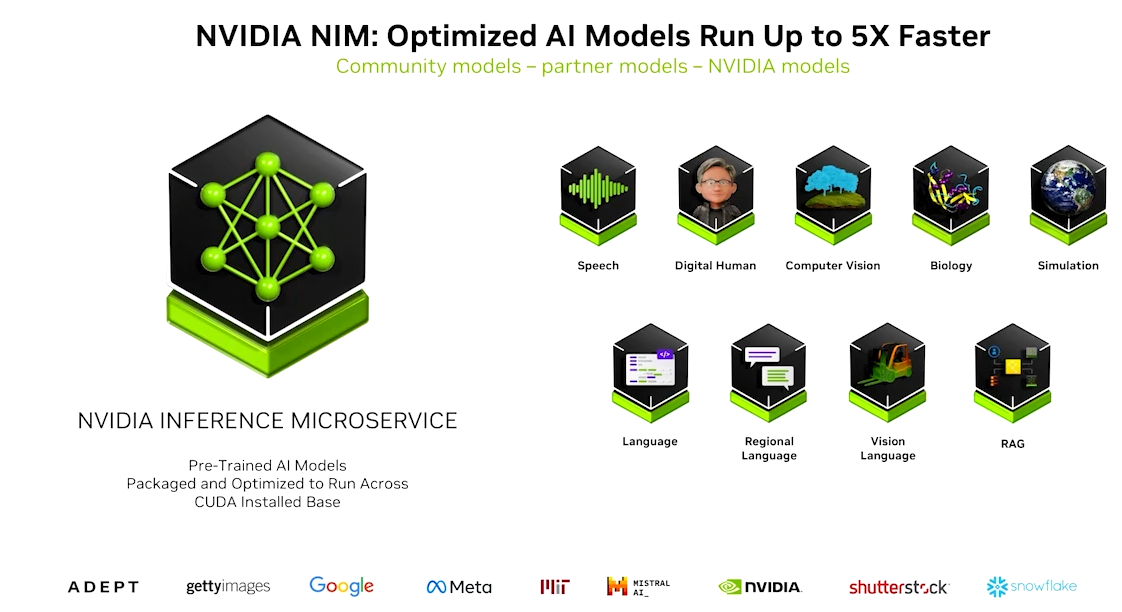
NVIDIA NIM™ 是一套易于使用的预构建容器工具,可在任何 NVIDIA 加速基础设施(云、数据中心、工作站和边缘设备)上快速部署最新 AI 模型。
一、企业面临的挑战(Challenges for Enterprises)
企业在 AI 部署中普遍遇到的痛点包括:
- 模型部署复杂度高:需要手动配置推理引擎、依赖环境,适配不同 GPU/架构的成本高;
- 数据安全风险:云托管模型 API 可能导致敏感数据泄露,合规性难以保障;
- 性能与成本矛盾:开源推理方案吞吐量低、延迟高,大规模部署时算力成本激增;
- 跨环境兼容性差:难以在数据中心、公有云、边缘设备等异构环境中统一部署模型。
二、什么是 NVIDIA NIM(What is NVIDIA NIM)
技术架构
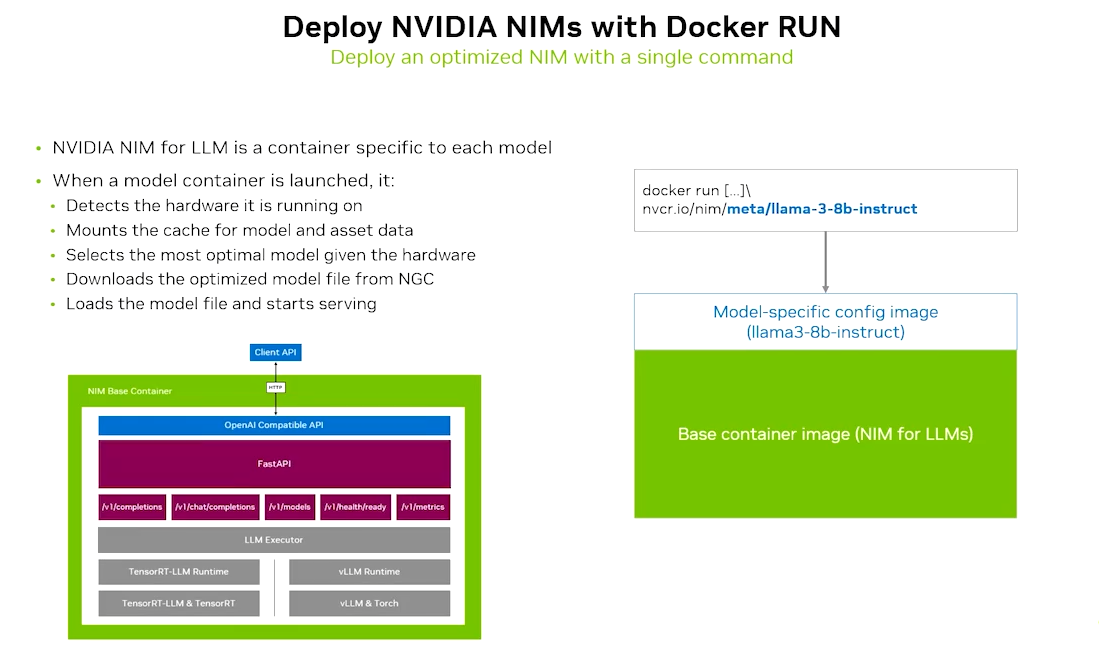
NIM 是 **GPU 加速的推理
微服务套件**,核心架构为 “预优化容器 + 标准化接口 + 多环境适配”:
- 容器化封装:每个 NIM 对应一个 Docker 容器,内置 模型文件 + 推理引擎(TensorRT-LLM/VLLM/SGLang) + 运行时依赖,支持 Llama 3.1、GPT-4o 等主流模型;
- 标准化 API:提供与 OpenAI 兼容的
/v1/chat/completions等接口,同时支持 NVIDIA 扩展功能(如工具调用、多 LoRA 加载); - GPU 优化层:基于 NVIDIA CUDA/Triton 推理服务器,实现 分页 KV 缓存、动态批处理、FP8 量化 等技术,大幅提升吞吐量(例如 Llama 3.1 8B 模型吞吐量比开源方案高 2.5 倍)。
核心特性
- 企业级安全:支持 SafeTensors 格式、CVE 漏洞实时修复、容器签名,符合 GDPR/PCI 等合规要求;
- 多环境部署:兼容 NVIDIA 加速的任何基础设施(数据中心 H100/A100、公有云 GPU 实例、RTX 工作站);
- 一键式交付:通过
docker run或 NGC 下载,5 分钟内完成模型部署,无需手动编译依赖。
三、利用 NIM 构建 AI 工作流(Team NIMs to Build AI Workflows)
以 RAG(检索增强生成)工作流 为例,NIM 的协作逻辑:
- 数据预处理:通过 NIM 微服务解析多模态数据(文本/表格/图像),完成语义分块;
- 向量生成:调用 NIM 嵌入模型(如 BGE-M3)生成向量,存储到 Pinecone/Weaviate 向量库;
- LLM 推理:NIM LLM 服务接收用户查询,调用工具检索向量库,生成上下文增强的回复;
- 工作流编排:结合 NeMo Guardrails(安全护栏)、Orchestrator(流程管理),实现 预算控制、PII 脱敏、响应缓存 等功能。
工具链集成
- 与 NeMo 平台联动:支持参数高效微调(PEFT)、多 LoRA 动态加载(同时服务多个租户的定制模型);
- 与 Kubernetes 集成:通过 Helm 图表实现 NIM 容器的自动扩缩容、健康检查。
四、在自有基础设施上部署(Deployment on Self-Owned Infrastructure)
部署方案
适用于 数据中心、私有云、空气隔离环境:
- 硬件要求:需配备 NVIDIA GPU(如 H100/A100),推荐搭配 NVLink 实现多卡互联;
- 部署步骤:
- 从 NGC 下载 NIM 容器(需 NVIDIA AI Enterprise 许可证);
- 通过 Docker Compose 或 Kubernetes 编排多个 NIM 服务(如 LLM + 嵌入模型 + 语音转写);
- 配置内部 API 网关,实现负载均衡与权限控制。
优势
- 数据主权:模型与数据均在自有环境内运行,无外部依赖;
- 性能可控:支持 GPU 算力隔离,保障核心业务的低延迟(例如 ITL 低至 32ms)。
五、在公有云上部署(Deployment on Public Cloud)
主流云平台方案
- Azure AI Foundry:NIM 与 Azure 托管 GPU 实例(如 NC A100 v4)集成,通过 Azure ML SDK 一键部署,支持自动扩缩容;
- AWS:在 Amazon EC2(p5.24xlarge)/EKS 上运行 NIM 容器,结合 Amazon S3 存储模型文件,利用 AWS Batch 处理批量推理任务;
- GCP:通过 GKE 部署 NIM 集群,搭配 Google Filestore 实现模型文件共享。
云部署优势
- 弹性算力:按需调用公有云 GPU 资源,降低峰值算力成本;
- 生态联动:与云厂商服务(如 Azure OpenAI、AWS Bedrock)互补,实现混合部署。
六、应用场景
NIM 已在多行业落地:
- 客服智能助手:金融/电信企业通过 NIM 部署定制 LLM,结合 RAG 检索知识库,实现 90% 以上的自动问题解答;
- 内容生成:媒体行业用 NIM 批量生成新闻摘要、营销文案,吞吐量达 1200 tokens/s;
- 医疗辅助诊断:医院通过 NIM 部署医学影像分析模型,在本地数据中心实现 2 秒内生成诊断建议;
- 工业质检:制造业在边缘设备(RTX 工作站)部署 NIM 视觉模型,实时识别产品缺陷。
=====================================
NVIDIA NIM 是一套面向企业的 AI 推理微服务解决方案,核心是通过预优化容器化封装 + 标准化接口 + 全环境适配,解决企业在 AI 模型部署中的“复杂、低效、不安全”等痛点:
一、技术架构:“容器化微服务 + 全栈加速”
NIM 的底层架构以 “模型-引擎-容器-编排” 四层为核心:
- 模型层:覆盖 LLM(大语言模型)、嵌入模型、多模态模型 等,包括 Llama 3.1、GPT-4o、BGE-M3、Flux.1 等主流模型,支持企业自定义微调模型的无缝接入;
- 推理引擎层:内置 TensorRT-LLM、vLLM、SGLang 等优化引擎,通过 FP8 量化、分页 KV 缓存、动态批处理 等技术,将吞吐量提升 2~3 倍(例如 Llama 3.1 8B 在 H100 上单卡吞吐量达 1201 tokens/s);
- 容器层:每个 NIM 对应一个 企业级 Docker 容器,预封装模型文件、运行时依赖、安全组件(如模型签名、漏洞扫描),支持“一键启动”;
- 编排层:适配 Kubernetes/Helm 图表,支持自动扩缩容、健康检查,同时通过 NIM Proxy 实现多模型统一 API 网关,简化调用流程。
二、核心能力:解决企业 AI 部署的四大痛点
NIM 解决方案围绕“易用、安全、高效、灵活”四大核心能力设计:
1. 降低部署门槛:5 分钟完成模型上线
- 标准化接口:提供与 OpenAI 兼容的
/v1/chat/completions等 API,无需修改代码即可从云服务切换到本地部署; - 一键式交付:通过
docker run或 NGC 下载容器,例如部署 Llama 3.1 仅需一行命令:docker run nvcr.io/nim/meta/llama3.1-8b-instruct:latest - 工具链集成:与 LangChain、CrewAI 等框架联动,支持 RAG(检索增强生成)、多智能体工作流的快速搭建。
2. 企业级安全:数据主权与风险可控
- 数据隔离:模型与数据均在企业自有环境内运行,无外部依赖,符合 GDPR/PCI 等合规要求;
- 可信执行:
- 模型签名:每个 NIM 容器均经过加密签名,可验证完整性;
- 漏洞扫描:发布前自动检测 Critical/High 级 CVE 漏洞,定期滚动补丁;
- 安全护栏:集成 NeMo Guardrails 微服务,支持 内容安全检测、话题控制、越狱攻击防护(合规性提升 1.5 倍,延迟仅增加 0.5 秒)。
- 透明可审计:提供 SBOM(软件物料清单)、VEX(漏洞可利用性报告),便于企业安全团队审计。
3. 性能与成本优化:最大化 GPU 效率
- 高吞吐量 + 低延迟:通过 TensorRT-LLM 优化,Llama 3.1 8B 在 H100 上单卡支持 200 并发请求,ITL(初始 token 延迟)低至 32ms;
- 算力资源复用:支持多 LoRA 动态加载(同时服务多个租户的定制模型),GPU 利用率提升 40%;
- TCO 降低:相比开源方案,相同任务下算力成本降低 50% 以上。
4. 全环境适配:“云-边-端”无缝部署
NIM 支持在 任何 NVIDIA 加速基础设施 上运行:
- 数据中心/私有云:适配 H100/A100 等 GPU,支持 NVLink 多卡互联;
- 公有云:与 Azure/AWS/GCP 的托管 GPU 实例(如 NC A100 v4)深度集成,支持自动扩缩容;
- 边缘设备:在 RTX 工作站、嵌入式 GPU 上运行轻量化 NIM 容器,满足低带宽场景需求。
三、部署方案:两种模式满足不同场景
NIM 提供 “自托管”和“混合部署” 两种核心方案:
1. 自有基础设施部署(数据中心/私有云)
- 适用场景:对数据安全要求高的金融、医疗、政府机构;
- 部署流程:
- 从 NGC 下载 NIM 容器(需 NVIDIA AI Enterprise 许可证);
- 通过 Docker Compose/Kubernetes 编排多 NIM 服务(如 LLM + 嵌入模型 + 语音转写);
- 配置内部 API 网关,实现负载均衡与权限控制;
- 优势:数据主权完全可控,支持空气隔离环境部署。
2. 公有云部署
- 适用场景:需要弹性算力的互联网、零售企业;
- 主流方案:
- Azure AI Foundry:NIM 与 Azure 托管 GPU 实例集成,通过 Azure ML SDK 一键部署;
- AWS EKS:在 EC2 p5.24xlarge 上运行 NIM 容器,结合 S3 存储模型文件;
- 优势:按需调用算力,峰值成本降低 60%。
四、行业应用场景:覆盖多领域核心需求
NIM 已在 金融、制造、医疗、零售 等行业落地:
1. 金融:智能客服与风控
- 部署定制 LLM + RAG 工作流,自动解答客户咨询(准确率 92%),同时通过 NeMo Guardrails 过滤敏感信息;
- 案例:某银行通过 NIM 部署金融合规 LLM,审核效率提升 80%。
2. 制造:工业质检与数字孪生
- 在边缘 RTX 工作站部署 NIM 视觉模型,实时识别产品缺陷(准确率 99%);
- 案例:Pegatron 结合 NIM + Omniverse 构建工厂数字孪生,新产线施工周期缩短 40%。
3. 医疗:辅助诊断与病历处理
- 在本地数据中心部署医学影像分析 NIM 模型,2 秒内生成诊断建议,数据全程不离开医院;
- 案例:某三甲医院通过 NIM 处理病理报告,效率提升 5 倍。
4. 零售:个性化推荐与供应链优化
- 部署 NIM 嵌入模型 + 向量库,实现商品个性化推荐(转化率提升 25%);
- 结合 cuOpt 优化配送路线,物流成本降低 15%。
总结
NVIDIA NIM 是 “开箱即用的企业级 AI 推理引擎”,通过容器化封装、全栈优化、安全合规设计,帮助企业在 5 分钟内完成模型部署,同时兼顾性能、成本与数据安全,是当前企业落地生成式 AI 的核心工具之一。
=====================================
以下是 NVIDIA NIM 部署的具体操作步骤(含代码示例),同时整合了技术架构、应用场景与行业场景的核心信息:
一、技术架构回顾
NIM 的核心架构为 “四层微服务”:
- 模型层:预封装 Llama 3.1、GPT-4o、BGE-M3 等模型;
- 推理引擎层:TensorRT-LLM/vLLM 实现 GPU 加速;
- 容器层:Docker 容器封装模型+依赖+安全组件;
- 编排层:K8s/Helm 实现扩缩容与统一网关。
二、NIM 部署具体步骤(以“Llama 3.1 8B + RAG 工作流”为例)
前提条件
- 配备 NVIDIA GPU(如 A100/H100/RTX 4090);
- 安装 Docker、NVIDIA Container Toolkit;
- 拥有 NVIDIA NGC 账号(获取 NIM 容器)。
步骤1:安装依赖环境
# 安装 NVIDIA Container Toolkit(使 Docker 支持 GPU)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-docker2
sudo systemctl restart docker
步骤2:拉取并启动 NIM LLM 服务(Llama 3.1 8B)
# 从 NGC 拉取 NIM Llama 3.1 容器
docker pull nvcr.io/nim/meta/llama3.1-8b-instruct:latest
# 启动 NIM LLM 服务(暴露 8000 端口,指定 GPU 0)
docker run -it --gpus all -p 8000:8000 \
-e NVIDIA_API_KEY="你的 NGC API Key" \
nvcr.io/nim/meta/llama3.1-8b-instruct:latest
- 验证服务:访问
http://localhost:8000/v1/models,返回模型信息则启动成功。
步骤3:部署 NIM 嵌入模型(BGE-M3)
# 拉取 BGE-M3 容器
docker pull nvcr.io/nim/bge-m3:latest
# 启动嵌入服务(暴露 8001 端口)
docker run -it --gpus all -p 8001:8000 \
-e NVIDIA_API_KEY="你的 NGC API Key" \
nvcr.io/nim/bge-m3:latest
步骤4:搭建 RAG 工作流(Python 示例)
import requests
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings # 兼容 NIM 接口
# 1. 定义 NIM 服务地址
LLM_URL = "http://localhost:8000/v1/chat/completions"
EMBED_URL = "http://localhost:8001/v1/embeddings"
# 2. 自定义 Embedding 类(适配 NIM 接口)
class NIMEmbeddings:
def embed_documents(self, texts):
resp = requests.post(EMBED_URL, json={"input": texts})
return [d["embedding"] for d in resp.json()["data"]]
def embed_query(self, text):
return self.embed_documents([text])[0]
# 3. 构建向量库(示例文档)
docs = ["NVIDIA NIM 支持容器化部署", "NIM 内置 TensorRT-LLM 推理引擎"]
embeddings = NIMEmbeddings()
vector_db = FAISS.from_texts(docs, embeddings)
# 4. 检索+生成(RAG)
query = "NIM 用了什么推理引擎?"
retrieved_docs = vector_db.similarity_search(query)
context = "\n".join([d.page_content for d in retrieved_docs])
# 调用 NIM LLM 生成回复
payload = {
"model": "llama3.1-8b-instruct",
"messages": [{"role": "user", "content": f"根据上下文回答:{context}\n问题:{query}"}]
}
response = requests.post(LLM_URL, json=payload)
print(response.json()["choices"][0]["message"]["content"])
步骤5:K8s 编排(Helm 示例)
# values.yaml
replicaCount: 2
image:
repository: nvcr.io/nim/meta/llama3.1-8b-instruct
tag: latest
service:
type: ClusterIP
port: 8000
resources:
limits:
nvidia.com/gpu: 1
# 部署到 K8s 集群
helm install nim-llm ./nim-chart -f values.yaml
三、应用场景与行业落地
1. 通用应用场景
- 智能客服:部署 NIM LLM + RAG,自动解答用户咨询(支持多轮对话);
- 内容生成:批量生成产品文案、代码注释,吞吐量达 1200 tokens/s;
- 数据分析:结合 NIM 多模态模型,解析表格/图表并生成报告。
2. 行业场景
| 行业 | 落地案例 |
|---|---|
| 金融 | 某银行用 NIM 部署合规 LLM,审核贷款申请效率提升 80%,敏感信息脱敏率 100%。 |
| 制造 | Pegatron 通过 NIM + Omniverse,实现工厂缺陷检测(准确率 99%),成本降低 30%。 |
| 医疗 | 某三甲医院用 NIM 部署影像分析模型,2 秒生成诊断建议,数据全程本地存储。 |
| 零售 | 某电商用 NIM 嵌入模型实现商品推荐,转化率提升 25%,物流路线优化成本降 15%。 |
===============================================================
以下是 NVIDIA NIM 在不同行业的典型落地案例,涵盖金融、制造、医疗、零售等领域,包含具体场景、技术方案与实际收益:
一、金融行业:场景数据生成与智能风控
案例1:金融市场场景模拟(某大型投行)
- 业务痛点:需要快速生成符合历史特征的金融市场场景(如金融危机、通胀周期),用于压力测试与风险评估,但传统方法依赖人工建模,耗时长达数周。
- NIM 解决方案:
- 部署 Llama 3.70B NIM 解析自然语言指令(如“生成 2008 年金融危机峰值的收益率曲线”);
- 结合 VAE/DDPM 生成模型 NIM,基于历史数据生成高保真的市场场景(如掉期曲线、波动率表面);
- 通过 NIM 标准化 API 与现有风控系统集成。
- 收益:场景生成时间从 4 周缩短至 2 小时,模型生成的场景与真实历史数据拟合度达 92%,支持日均 1000+ 次压力测试。
案例2:多代理金融聊天机器人(某国际银行)
- 业务痛点:客服与投资咨询场景需同时处理贷款、投资、账户管理等多类请求,传统系统响应慢且合规性难保障。
- NIM 解决方案:
- 用 Llama 3 NIM 构建 3 个专业代理(贷款、投资、通用客服),通过意图分类路由请求;
- 集成 NeMo Guardrails NIM 实现敏感信息过滤、合规校验(符合 GDPR/PCI);
- 基于 K8s 与 NIM 自动扩缩容,支持日均 5 万+ 并发请求。
- 收益:客户咨询响应时间从 12 秒降至 2.5 秒,合规违规率从 8% 降至 0.1%,人工客服工作量减少 60%。
二、制造行业:智能工厂与缺陷检测
案例1:和硕(Pegatron)智能工厂优化
- 业务痛点:工厂面积超 2000 万平方英尺,需同时监控 3500+ 台机器人、百万级传感器数据,人工巡检效率低。
- NIM 解决方案:
- 部署 视觉洞察 Agent(VIA)NIM,结合 RAG 工作流解析自然语言查询(如“检查产线 3 的工人安全帽佩戴情况”);
- 用 Metropolis + NIM 多摄像头跟踪,实时分析视频流并生成告警;
- 与 Omniverse 数字孪生联动,模拟产线优化方案。
- 收益:安全事故响应时间从 30 分钟缩短至 1 分钟,产线设备故障率降低 22%,工厂整体效率提升 18%。
案例2:Foxconn 数字孪生与设备维护
- 业务痛点:设备维护依赖人工经验,停机时间长,影响产能。
- NIM 解决方案:
- 通过 NIM 嵌入模型 解析设备手册、传感器数据,构建故障知识库;
- 部署 Llama 3 NIM 实现“自然语言查询 + 故障根因分析”(如“解释机床温度异常的 3 种可能原因”);
- 结合 Omniverse 数字孪生,模拟维护方案的效果。
- 收益:设备预测性维护准确率达 95%,非计划停机时间减少 40%。
三、医疗行业:设备训练与影像分析
案例1:医疗设备训练助手(某医疗设备厂商)
- 业务痛点:临床医生在无菌环境(如手术室)中难以快速查询医疗设备操作手册(IFU),传统纸质文档效率低。
- NIM 解决方案:
- 部署 Llama 3.70B NIM + 嵌入模型 NIM 构建 RAG 工作流,解析设备 IFU 文档;
- 集成 RIVA ASR/TTS NIM,支持语音交互(医生口述问题,系统语音回复);
- 本地部署 NIM 容器,确保数据不离开医院环境。
- 收益:设备操作查询时间从 15 分钟缩短至 30 秒,医生培训成本降低 50%,手术流程效率提升 20%。
案例2:梅奥诊所(Mayo Clinic)影像分析
- 业务痛点:医学影像(如病理切片)分析需高算力,但敏感数据无法上云。
- NIM 解决方案:
- 在本地 DGX Blackwell 200 系统上部署 医学影像模型 NIM(如 MONAI 分割模型);
- 通过 NIM 容器封装模型,支持多 GPU 并行推理;
- 结合 NeMo Guardrails 确保数据隐私合规。
- 收益:病理切片分析时间从 2 小时缩短至 8 分钟,诊断准确率提升 9%,同时满足 HIPAA 合规要求。
四、零售行业:个性化推荐与内容生成
案例1:安利(Amway)营销助手与 Copilot
- 业务痛点:全球营销人员需快速生成个性化健康方案、营销材料,但传统工具效率低且数据安全风险高。
- NIM 解决方案:
- 部署 DeepSeek R1 NIM 加速 LLM 推理,支持日均千万级案例检索;
- 用 NeMo Guardrails NIM 过滤敏感信息(如消费者隐私、商业机密);
- 结合混合云架构,NIM 动态调度 GPU 资源,实现跨场景算力分配。
- 收益:营销材料生成时间从 4 小时缩短至 15 分钟,营销人员效率提升 50%,敏感信息拦截率达 99.9%。
案例2:欧莱雅(L’Oréal)个性化美妆推荐
- 业务痛点:消费者难以从海量产品中找到适配的美妆方案,传统推荐依赖关键词搜索,精准度低。
- NIM 解决方案:
- 部署 Llama 3.1 70B NIM + 嵌入模型 NIM 构建多模态 RAG 工作流;
- 结合 NVClip NIM 实现“文本 + 图像”混合检索(如上传肤色照片,推荐适配粉底液);
- 通过 NIM 与 CreAItech 平台集成,生成符合品牌调性的个性化内容。
- 收益:产品推荐转化率提升 25%,用户平均订单金额增加 18%。
五、其他行业:能源与媒体
案例:Worley(能源工程公司)Agentic AI 转型
- 业务痛点:EPC(工程/采购/施工)项目中,文档处理、流程协作效率低,跨团队沟通成本高。
- NIM 解决方案:
- 用 NIM + NeMo Framework 构建 AI 智能体,自动解析项目文档、生成施工方案;
- 通过 Triton 推理服务器 与 NIM 联动,支持多模型并行推理;
- 本地部署 NIM 容器,确保项目数据安全。
- 收益:项目文档处理时间减少 70%,跨团队协作效率提升 45%,项目交付周期缩短 20%。
这些案例体现了 NVIDIA NIM“容器化 + 标准化 + 全环境适配” 的核心优势,帮助企业在保障安全合规的前提下,快速落地生成式 AI 并实现业务效率的显著提升。
===============================================================
NVIDIA NIM的部署可适配多种环境,包括RTX AI PC、Kubernetes集群、NVIDIA云函数(NVCF)等主流场景,不同环境的部署流程适配了对应平台的资源特性,以下是各场景下详细且可落地的部署步骤:
- RTX AI PC环境(适合开发者/AI爱好者测试体验)
该场景部署操作简单,支持通过可视化工具或安装程序快速启动,以下是两种常用方式:- 通过Flowise集成部署:先打开Flowise工具,在Chat Models中拖动Chat NVIDIA NIM节点到操作区;点击“Set up NIM Locally”下载NIM安装程序;选择目标模型(如Llama3.1 - 8B - instruct),完成后配置内存限制与未占用的主机端口;最后启动容器并保存chatflow,即可在聊天窗口测试模型。
- 借助AnythingLLM部署:进入AnythingLLM的配置界面,依次选择“Config”>“AI Providers”>“LLM”;在服务商选项中选NVIDIA NIM,点击运行NIM安装程序;安装完成后切换至托管模式,导入所需NIM模型并设为活跃状态;启动NIM服务后返回工作空间,就能通过聊天窗口调用模型。
- Docker容器部署(适合单机/小型自托管场景)
此方式适配工作站或小型服务器,依赖Docker与NVIDIA容器工具包,步骤如下:- 环境准备:安装Docker后,配置NVIDIA Container Toolkit以支持GPU调用,命令如下:
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list sudo apt-get update && sudo apt-get install -y nvidia-docker2 sudo systemctl restart docker - 拉取并启动NIM镜像:登录NGC账号后,拉取目标模型镜像并启动,以Llama3.1 - 8B - instruct为例:
docker pull nvcr.io/nim/meta/llama-3.1-8b-instruct:latest docker run -it --gpus all -p 8000:8000 -e NVIDIA_API_KEY="你的NGC密钥" nvcr.io/nim/meta/llama-3.1-8b-instruct:latest - 验证服务:访问
http://localhost:8000/v1/models,若返回模型信息,则部署成功。
- 环境准备:安装Docker后,配置NVIDIA Container Toolkit以支持GPU调用,命令如下:
- Kubernetes集群部署(适合企业级大规模部署)
该场景支持多节点扩展与统一管理,适配数据中心等大规模算力集群,步骤如下:- 前置配置:确保K8s集群节点搭载NVIDIA GPU,安装NVIDIA设备插件与支持GPU的容器运行时(如containerd);同时安装Nemo部署管理的Helm Chart,并将平台基础URL存入环境变量
nemo_base_url。 - 通过API部署NIM:执行curl命令发送POST请求部署模型,以Llama3 - 8B - instruct为例:
curl --location "${nemo_base_url}/v1/deployment/model-deployments" \ --header 'Content-Type: application/json' \ --data '{ "name": "llama3-8b-instruct", "namespace": "meta", "config": { "model": "meta/llama3-8b-instruct", "nim_deployment": { "image_name": "nvcr.io/nim/meta/llama3-8b-instruct", "image_tag": "1.0.3", "pvc_size": "25Gi", "gpu": 1 } } }' - 查看部署状态:用curl命令查询部署进度,直至状态显示为ready:
curl --location "${nemo_base_url}/v1/deployment/model-deployments/meta/llama3-8b-instruct" | jq - 删除冗余服务:若需清理模型,执行DELETE请求即可:
curl -X DELETE "${nemo_base_url}/v1/deployment/model-deployments/meta/llama3-8b-instruct"
- 前置配置:确保K8s集群节点搭载NVIDIA GPU,安装NVIDIA设备插件与支持GPU的容器运行时(如containerd);同时安装Nemo部署管理的Helm Chart,并将平台基础URL存入环境变量
- 多节点K8s部署(适配超大规模模型,如70B参数以上模型)
当单节点GPU无法承载大模型时,可通过该方式实现跨节点算力调度,步骤如下:- 前置校验:确认目标NIM模型支持多节点部署,集群CSI驱动支持ReadWriteMany模式的持久卷,且存储容量不低于700GB;同时验证多节点网络互通,并安装Mellanox网卡与NVIDIA MOFED驱动。
- 配置网络与依赖:部署NVIDIA Network Operator并启用NFD,定义NICClusterPolicy与IP over IB多网络;安装LeaderWorkerSet(LWS)组件,用于管理多节点Pod调度。
- 部署多节点NIM:创建模型缓存目录,通过Helm Chart配置NIM服务,指定GPU数量与节点间RDMA网络通信参数;最后通过命令查看LWS与NIM服务状态,确认跨节点部署成功。
- NVIDIA云函数(NVCF)部署(适合无本地算力的云托管场景)
该方式无需管理底层基础设施,支持自动扩缩容,步骤如下:- 环境准备:确保网络可访问NGC容器仓库(nvcr.io)与NVIDIA云API,防火墙开放443端口;注册NVCF账号并完成权限配置。
- 上传镜像:将所需NIM容器镜像上传至NGC私有仓库(若使用公共镜像可跳过)。
- 一键部署:在NVCF控制台选择“Elastic NIM”,指定目标模型镜像、GPU规格与扩缩容策略;系统会自动分配硬件资源并启动服务,部署完成后获取云服务端点即可调用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)