NVIDIA NIM 开发并部署 AI Agent(智能体)实战
社区环境及参考

基于 NVIDIA NIM 开发并部署 AI Agent(智能体)的完整案例,以企业级客服智能体为例,涵盖 Agent 核心逻辑开发、基于 NIM 的推理服务部署、Agent 服务封装与上线全流程。
案例背景
开发一个“金融产品咨询智能体”,具备以下能力:
- 理解用户自然语言问题(如“信用卡分期利率是多少?”);
- 检索金融产品知识库(RAG 能力);
- 调用 NIM 提供的 LLM 生成合规、准确的回答;
- 部署为可对外调用的 HTTP 服务。
前置条件
- 硬件:配备 NVIDIA GPU(RTX 4090/A100/H100,显存 ≥ 16GB);
- 软件:Docker、NVIDIA Container Toolkit、Python 3.9+、FastAPI、LangChain;
- 账号:NVIDIA NGC 账号(获取 NIM 容器,https://ngc.nvidia.com/)。
步骤 1:部署 NVIDIA NIM 推理服务(Llama 3.1 + BGE-M3)
首先部署 NIM 提供的 LLM 服务(对话生成)和嵌入模型服务(知识库检索)。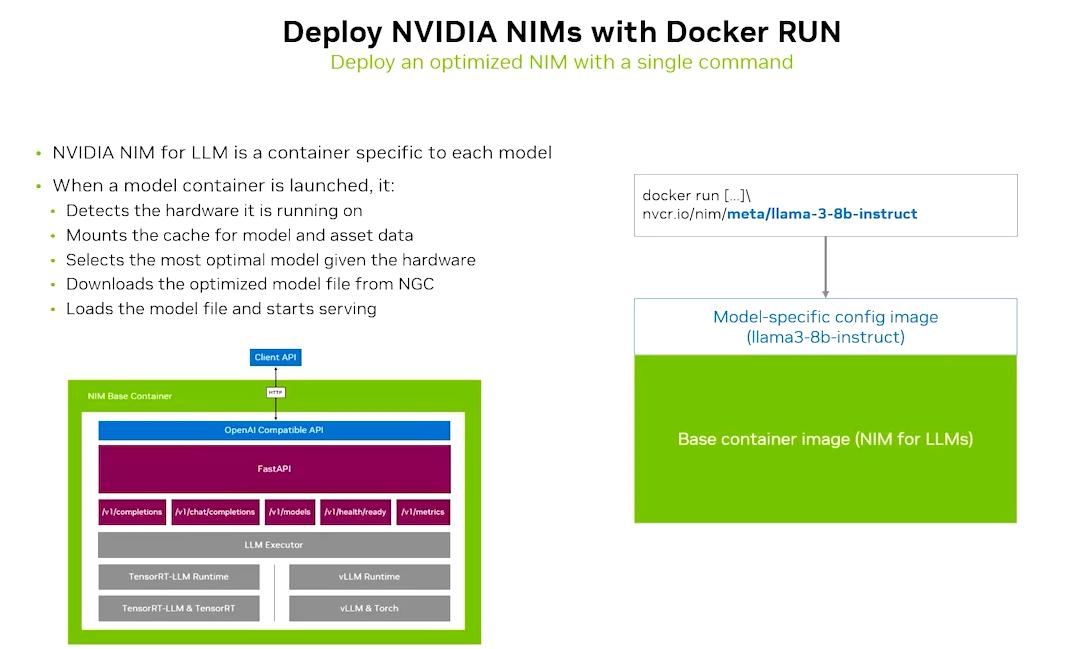


1.1 启动 NIM Llama 3.1 8B 服务(对话生成)
# 1. 登录 NGC(首次需执行,输入 NGC API Key)
docker login nvcr.io
# 2. 拉取 NIM Llama 3.1 8B 镜像
docker pull nvcr.io/nim/meta/llama3.1-8b-instruct:latest
# 3. 启动 NIM LLM 服务(暴露 8000 端口,占用 1 块 GPU)
docker run -d --name nim-llm --gpus all -p 8000:8000 \
-e NVIDIA_API_KEY="你的 NGC API Key" \
nvcr.io/nim/meta/llama3.1-8b-instruct:latest
1.2 启动 NIM BGE-M3 服务(文本嵌入)
# 1. 拉取 NIM BGE-M3 镜像
docker pull nvcr.io/nim/bge-m3:latest
# 2. 启动 NIM 嵌入服务(暴露 8001 端口)
docker run -d --name nim-embed --gpus all -p 8001:8000 \
-e NVIDIA_API_KEY="你的 NGC API Key" \
nvcr.io/nim/bge-m3:latest
1.3 验证 NIM 服务
# 验证 LLM 服务
curl http://localhost:8000/v1/models
# 验证嵌入服务
curl http://localhost:8001/v1/models
返回模型列表(如 llama3.1-8b-instruct)则说明部署成功。
步骤 2:开发 AI Agent 核心逻辑
基于 LangChain 封装 Agent,整合“知识库检索 + NIM LLM 推理 + 合规校验”能力。
2.1 安装依赖
pip install langchain fastapi uvicorn requests faiss-cpu python-multipart
2.2 Agent 核心代码(finance_agent.py)
import requests
import faiss
import numpy as np
from langchain.schema import HumanMessage, SystemMessage
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
# ====================== 配置项 ======================
# NIM 服务地址
NIM_LLM_URL = "http://localhost:8000/v1/chat/completions"
NIM_EMBED_URL = "http://localhost:8001/v1/embeddings"
# 金融产品知识库(示例数据)
KNOWLEDGE_BASE = [
"信用卡分期利率:3期 0.9%/期,6期 0.85%/期,12期 0.8%/期",
"储蓄卡跨行取款手续费:每月前3笔免费,之后每笔2元",
"房贷基准利率:首套房 LPR - 20BP,二套房 LPR + 60BP",
"理财产品起购金额:稳健型 1万元,进取型 5万元"
]
# 合规提示词(确保回答符合金融监管要求)
SYSTEM_PROMPT = """
你是专业的金融客服智能体,需遵守以下规则:
1. 仅回答知识库中的金融产品问题,超出范围请回复“暂无相关信息”;
2. 回答需准确、简洁,不夸大收益、不承诺保本;
3. 禁止透露客户隐私、禁止提供投资建议。
"""
# ====================== 工具函数 ======================
class NIMEmbedding:
"""适配 NIM 嵌入服务的封装类"""
def embed_texts(self, texts: list) -> list:
"""批量生成文本嵌入向量"""
try:
resp = requests.post(
NIM_EMBED_URL,
json={"input": texts},
timeout=10
)
resp.raise_for_status()
return [d["embedding"] for d in resp.json()["data"]]
except Exception as e:
raise RuntimeError(f"嵌入服务调用失败:{str(e)}")
def embed_query(self, query: str) -> list:
"""生成单个查询的嵌入向量"""
return self.embed_texts([query])[0]
class NIMLLM:
"""适配 NIM LLM 服务的封装类"""
def generate_response(self, context: str, query: str) -> str:
"""结合上下文生成回答"""
try:
payload = {
"model": "llama3.1-8b-instruct",
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"上下文:{context}\n问题:{query}"}
],
"temperature": 0.1, # 低随机性保证回答准确
"max_tokens": 200
}
resp = requests.post(NIM_LLM_URL, json=payload, timeout=20)
resp.raise_for_status()
return resp.json()["choices"][0]["message"]["content"].strip()
except Exception as e:
raise RuntimeError(f"LLM 服务调用失败:{str(e)}")
# ====================== Agent 核心类 ======================
class FinanceAgent:
def __init__(self):
# 初始化嵌入模型和向量库
self.embedding = NIMEmbedding()
self.llm = NIMLLM()
self._build_knowledge_vector_db()
def _build_knowledge_vector_db(self):
"""构建知识库向量库"""
# 生成知识库文本的嵌入向量
knowledge_embeddings = self.embedding.embed_texts(KNOWLEDGE_BASE)
# 初始化 FAISS 向量库(维度与 NIM 嵌入一致)
dimension = len(knowledge_embeddings[0])
self.index = faiss.IndexFlatL2(dimension)
self.index.add(np.array(knowledge_embeddings).astype("float32"))
self.knowledge_texts = KNOWLEDGE_BASE
def retrieve_context(self, query: str, top_k: int = 2) -> str:
"""检索与问题最相关的知识库内容"""
query_embedding = self.embedding.embed_query(query)
# 向量检索(L2 距离)
distances, indices = self.index.search(
np.array([query_embedding]).astype("float32"),
k=top_k
)
# 过滤低相关性结果(距离阈值可根据实际调整)
context = []
for i, idx in enumerate(indices[0]):
if distances[0][i] < 1.0: # 距离越小越相关
context.append(self.knowledge_texts[idx])
return "\n".join(context) if context else "暂无相关信息"
def run(self, query: str) -> str:
"""Agent 主流程:检索 → 生成回答"""
# 1. 检索知识库
context = self.retrieve_context(query)
# 2. 调用 LLM 生成回答
return self.llm.generate_response(context, query)
# ====================== FastAPI 服务封装 ======================
app = FastAPI(title="金融客服智能体 API")
agent = FinanceAgent() # 初始化 Agent
# 请求体模型
class AgentRequest(BaseModel):
query: str
# 响应体模型
class AgentResponse(BaseModel):
code: int
msg: str
answer: str = ""
@app.post("/api/finance/query", response_model=AgentResponse)
def agent_query(request: AgentRequest):
"""智能体对外调用接口"""
try:
if not request.query.strip():
raise HTTPException(status_code=400, detail="查询内容不能为空")
# 执行 Agent 逻辑
answer = agent.run(request.query)
return AgentResponse(code=200, msg="success", answer=answer)
except HTTPException as e:
return AgentResponse(code=e.status_code, msg=e.detail)
except Exception as e:
return AgentResponse(code=500, msg=f"服务异常:{str(e)}")
# 启动服务(本地测试)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
步骤 3:部署 Agent 服务并测试
3.1 启动 Agent 服务
# 运行 FastAPI 服务
python finance_agent.py
服务将启动在 http://0.0.0.0:8080。
3.2 测试 Agent 接口
# 测试有效查询
curl -X POST "http://localhost:8080/api/finance/query" \
-H "Content-Type: application/json" \
-d '{"query": "信用卡分期12期的利率是多少?"}'
# 测试无效查询
curl -X POST "http://localhost:8080/api/finance/query" \
-H "Content-Type: application/json" \
-d '{"query": "股票怎么买?"}'
3.3 预期输出
- 有效查询返回:
{"code":200,"msg":"success","answer":"信用卡分期利率:12期 0.8%/期"} - 无效查询返回:
{"code":200,"msg":"success","answer":"暂无相关信息"}
步骤 4:企业级部署优化(可选)
若需生产环境部署,可补充以下优化:
4.1 容器化 Agent 服务
创建 Dockerfile:
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY finance_agent.py .
EXPOSE 8080
CMD ["python", "finance_agent.py"]
构建并启动容器:
docker build -t finance-agent:v1 .
docker run -d --name finance-agent -p 8080:8080 finance-agent:v1
4.2 Kubernetes 部署(大规模场景)
创建 agent-deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: finance-agent
spec:
replicas: 2
selector:
matchLabels:
app: finance-agent
template:
metadata:
labels:
app: finance-agent
spec:
containers:
- name: agent
image: finance-agent:v1
ports:
- containerPort: 8080
resources:
limits:
cpu: "1"
memory: "2Gi"
---
apiVersion: v1
kind: Service
metadata:
name: finance-agent-service
spec:
type: LoadBalancer
selector:
app: finance-agent
ports:
- port: 80
targetPort: 8080
部署到 K8s 集群:
kubectl apply -f agent-deployment.yaml
总结
- 核心流程:先部署 NIM 提供的 LLM/嵌入服务(容器化一键启动),再基于 LangChain 封装 Agent 逻辑(检索 + 推理 + 合规),最后通过 FastAPI 封装为 HTTP 服务;
- 关键优势:NIM 预优化容器大幅降低 LLM 部署门槛,标准化 OpenAI 兼容接口无需修改核心代码;
- 企业级适配:支持容器化/K8s 部署,可根据业务需求扩展为多 Agent 协作、多模型调用的复杂场景。
该案例可直接落地,也可根据实际业务扩展知识库、增加工具调用(如查询用户账单)、接入语音识别(NIM RIVA 服务)等能力。
你想了解在不同环境下部署 NVIDIA NIM 的具体方法,我会按 开发测试、单机生产、企业级集群、云托管 四大典型环境分类,给出适配各场景的部署步骤、核心配置和代码/命令示例,覆盖从新手体验到大规模生产的全场景需求。
核心前提(所有环境通用)
- 硬件:需配备 NVIDIA GPU(RTX 4090/A100/H100 等,显存 ≥ 8GB,大模型需 ≥ 16GB);
- 基础软件:安装 NVIDIA 驱动(≥535 版本)、Docker(或 Podman)、NVIDIA Container Toolkit;
- 账号:NVIDIA NGC 账号(获取 API Key,地址:https://ngc.nvidia.com/)。
一、开发/测试环境(RTX AI PC/轻量工作站)
适合开发者体验、功能验证,操作极简,无需复杂配置。
场景特点
- 单 GPU、低并发、快速启动;
- 支持可视化工具/一键脚本部署。
部署步骤(以 Llama 3.1 8B 为例)
1. 环境准备(仅首次执行)
# 安装 NVIDIA Container Toolkit(让 Docker 识别 GPU)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-docker2
sudo systemctl restart docker
2. 一键启动 NIM 服务
# 登录 NGC(输入你的 NGC API Key)
docker login nvcr.io
# 拉取并启动 Llama 3.1 8B NIM 容器(暴露 8000 端口)
docker run -it --gpus all -p 8000:8000 \
-e NVIDIA_API_KEY="你的 NGC API Key" \
nvcr.io/nim/meta/llama3.1-8b-instruct:latest
3. 可视化工具辅助部署(可选,新手友好)
- Flowise:打开 Flowise → 拖拽「Chat NVIDIA NIM」节点 → 点击「Set up NIM Locally」→ 选择模型自动下载部署;
- AnythingLLM:进入配置 → AI Providers → LLM → 选择 NVIDIA NIM → 运行安装程序自动部署。
验证方式
访问 http://localhost:8000/v1/models,返回模型列表即部署成功。
二、单机生产环境(物理服务器/私有云单机)
适合中小规模业务(日均请求 ≤ 10 万),兼顾稳定性与资源利用率。
场景特点
- 单 GPU/多 GPU(单机)、固定并发、需持久化/日志管理。
部署步骤(以多模型部署为例)
1. 自定义配置启动 NIM
创建 docker-compose.yml(支持多模型、持久化日志):
version: '3.8'
services:
# LLM 服务(Llama 3.1 8B)
nim-llm:
image: nvcr.io/nim/meta/llama3.1-8b-instruct:latest
ports:
- "8000:8000"
environment:
- NVIDIA_API_KEY=你的 NGC API Key
- LOG_LEVEL=info # 日志级别
- MAX_CONCURRENT_REQUESTS=50 # 最大并发
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1 # 占用 1 块 GPU
capabilities: [gpu]
volumes:
- ./nim-logs:/var/log/nim # 日志持久化
restart: always # 异常自动重启
# 嵌入模型服务(BGE-M3)
nim-embed:
image: nvcr.io/nim/bge-m3:latest
ports:
- "8001:8000"
environment:
- NVIDIA_API_KEY=你的 NGC API Key
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
restart: always
2. 启动服务
docker-compose up -d
3. 监控与维护
# 查看日志
docker-compose logs -f nim-llm
# 重启服务
docker-compose restart nim-llm
# 升级镜像
docker-compose pull nim-llm && docker-compose up -d
三、企业级集群环境(Kubernetes 集群)
适合大规模、高并发、弹性扩展的生产场景(如金融/制造行业核心业务)。
场景特点
- 多节点、多 GPU、自动扩缩容、统一运维;
- 支持大模型(70B+)多节点分布式部署。
部署步骤
1. 集群前置配置
# 安装 NVIDIA GPU 设备插件(让 K8s 识别 GPU)
kubectl apply -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.14.0/nvidia-device-plugin.yml
# 安装 Helm(K8s 包管理工具)
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
2. 单模型部署(Helm 示例)
① 创建 values.yaml 配置文件:
# values.yaml
replicaCount: 2 # 副本数(弹性扩展)
image:
repository: nvcr.io/nim/meta/llama3.1-8b-instruct
tag: latest
pullSecrets:
- name: ngc-secret # NGC 登录密钥(需提前创建)
service:
type: ClusterIP # 集群内访问,可改为 LoadBalancer 对外暴露
port: 8000
resources:
limits:
nvidia.com/gpu: 1 # 每个副本占用 1 块 GPU
requests:
cpu: 2
memory: 16Gi
env:
- name: NVIDIA_API_KEY
value: "你的 NGC API Key"
- name: MAX_TOKENS
value: "2048"
② 创建 NGC 密钥并部署:
# 创建 NGC 登录密钥(替换 <NGC_API_KEY> 为你的密钥)
kubectl create secret docker-registry ngc-secret \
--docker-server=nvcr.io \
--docker-username='$oauthtoken' \
--docker-password=<NGC_API_KEY>
# 部署 NIM 服务
helm install nim-llm ./nim-chart -f values.yaml
3. 大模型多节点部署(70B+ 模型)
针对 70B/400B 等超大模型,需跨节点调度 GPU:
# 1. 安装 LeaderWorkerSet(管理多节点 Pod)
kubectl apply -f https://github.com/NVIDIA/leader-workerset/releases/download/v0.1.0/leaderworkerset-crds.yaml
kubectl apply -f https://github.com/NVIDIA/leader-workerset/releases/download/v0.1.0/leaderworkerset-controller.yaml
# 2. 部署多节点 NIM(示例:Llama 3.1 70B,跨 2 节点,每节点 2 块 GPU)
curl -X POST "${nemo_base_url}/v1/deployment/model-deployments" \
-H "Content-Type: application/json" \
-d '{
"name": "llama3.1-70b-instruct",
"namespace": "meta",
"config": {
"model": "meta/llama3.1-70b-instruct",
"nim_deployment": {
"image_name": "nvcr.io/nim/meta/llama3.1-70b-instruct",
"image_tag": "latest",
"pvc_size": "100Gi",
"gpu": 4, # 总计 4 块 GPU
"multi_node": true,
"num_nodes": 2 # 跨 2 节点
}
}
}'
4. 验证与扩缩容
# 查看部署状态
kubectl get pods -l app=nim-llm
# 弹性扩缩容
helm upgrade nim-llm ./nim-chart --set replicaCount=3
四、云托管环境(NVIDIA Cloud Functions/NVCF)
适合无本地算力、需弹性扩缩的场景,无需管理底层硬件。
场景特点
- 零基础设施管理、按需付费、自动扩缩容;
- 支持公有云(AWS/Azure/GCP)+ NVIDIA 云函数联动。
部署步骤
1. 环境准备
- 注册 NVCF 账号(https://build.nvidia.com/);
- 配置云账号权限(如 AWS IAM 权限),确保可访问 NGC 仓库。
2. 一键部署 Elastic NIM
① 登录 NVCF 控制台 → 选择「Elastic NIM」;
② 选择目标模型(如 Llama 3.1 8B)、GPU 规格(如 A10G/H100);
③ 配置扩缩容策略(最小/最大副本数、触发阈值);
④ 点击「Deploy」,系统自动分配资源并启动服务。
3. 命令行部署(可选)
# 安装 NVCF CLI
pip install nvidia-cloud-functions
# 登录 NVCF
nvcf login --api-key <你的 NVCF API Key>
# 部署 NIM 服务
nvcf model deploy \
--model-name meta/llama3.1-8b-instruct \
--gpu-type A10G \
--min-replicas 1 \
--max-replicas 5
4. 调用与管理
# 获取服务端点
nvcf model list
# 调用 NIM 服务
curl -X POST "https://api.nvcf.nvidia.com/v2/nim/meta/llama3.1-8b-instruct/chat/completions" \
-H "Authorization: Bearer <NVCF_API_KEY>" \
-H "Content-Type: application/json" \
-d '{
"messages": [{"role": "user", "content": "Hello World"}],
"temperature": 0.1
}'
五、不同环境部署对比与选型建议
| 环境类型 | 核心优势 | 适用场景 | 关键配置 |
|---|---|---|---|
| 开发/测试 | 快速启动、操作简单 | 功能验证、新手体验 | 单 GPU、端口映射 |
| 单机生产 | 稳定、低运维成本 | 中小规模业务、固定并发 | 持久化日志、资源限制 |
| K8s 集群 | 弹性扩展、统一运维 | 大规模高并发、核心业务 | 多 GPU、多节点、Helm |
| 云托管(NVCF) | 零硬件管理、按需付费 | 无本地算力、弹性需求 | 扩缩容策略、GPU 规格 |
总结
- 核心逻辑:所有环境均基于 NIM 容器化封装,差异仅在“部署载体”(Docker/Compose/K8s/云函数);
- 选型原则:小体量用单机 Docker,大规模用 K8s,无本地算力用 NVCF;
- 通用验证:无论哪种环境,均可通过
http://<IP>:<端口>/v1/models验证服务是否启动; - 扩展建议:生产环境建议搭配监控(Prometheus + Grafana)、日志收集(ELK),大模型需关注显存/网络带宽。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 20
20 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)