从代码看BuildingAI:企业级智能体平台设计解析
本文从工程视角拆解开源智能体平台 BuildingAI,分析其前后端分离 + 微内核插件化的 Monorepo 架构、技术栈选型,深度解读智能体执行引擎、知识库等核心模块设计,对比同类项目,指出其企业级全栈特性与工程优势,为企业 AI 落地提供参考。
引言
近期, 在企业级开源智能体平台领域引起了开发者社区的关注。作为一名长期关注 AI 工程化落地的架构师,我决定深入其代码仓库(GitHub/BidingCC/BuildingAI),从工程实现的角度进行一次系统性的技术分析。本文将以专业工程师的视角,聚焦于项目的架构设计、模块拆分、工程实践等核心维度,力求客观呈现其技术实现的特点与取舍。
本文的分析完全基于对 BuildingAI 公开代码的结构化解读,不会引入任何未在源码中体现的假设或功能。同时,作为技术对比的参考,我会将其与 Dify、扣子等同类项目的已知公开架构思路进行简要横向对比,以突显不同工程哲学下的技术差异。
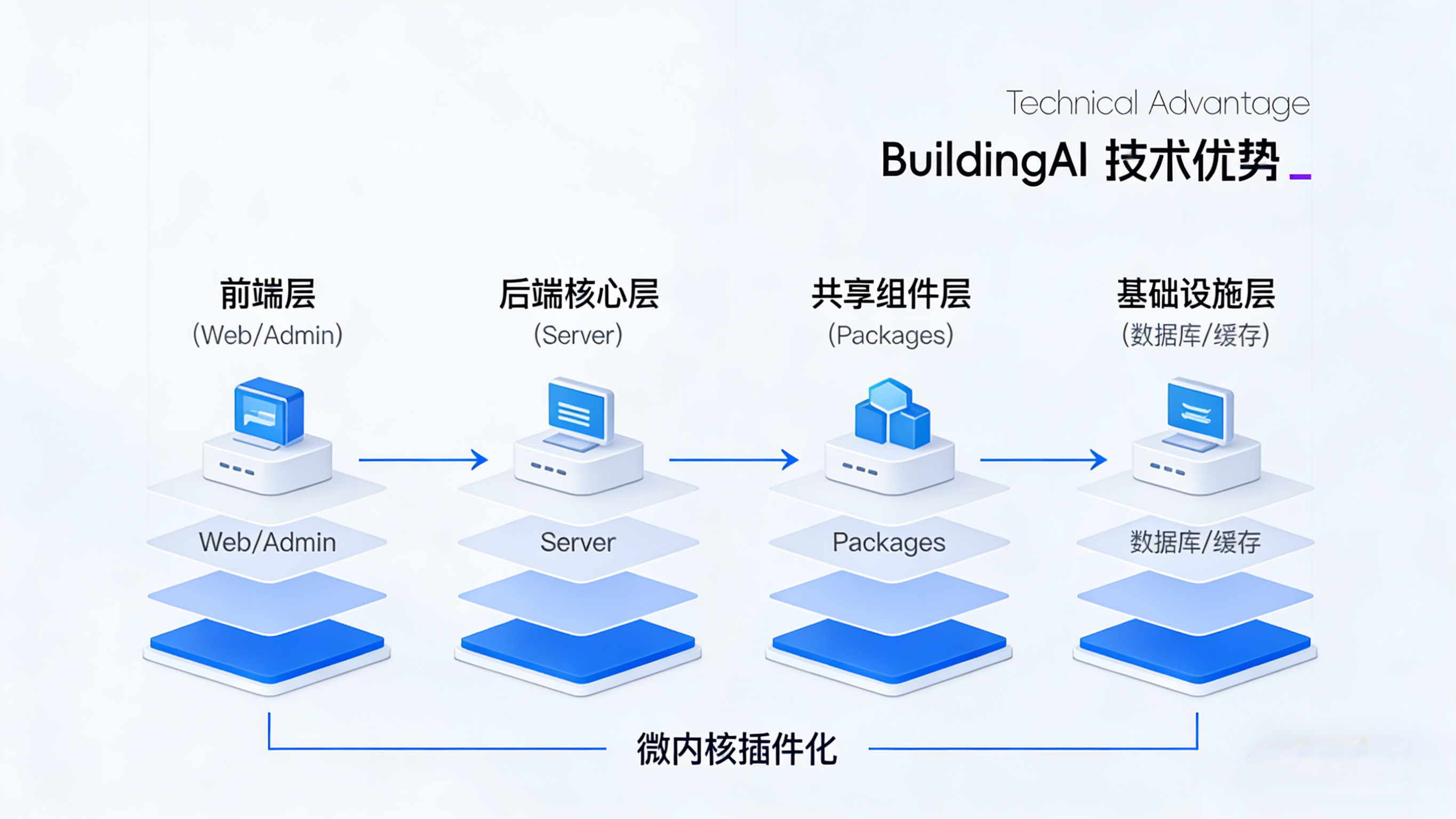
项目整体架构拆解
BuildingAI 采用了典型的 前后端分离 + 微内核插件化 的架构模式。从根目录结构可以清晰看出其模块化设计的意图:
├── apps/ # 多应用模块(Monorepo 结构)
│ ├── web/ # 前端应用(基于 Nuxt)
│ ├── server/ # 后端核心服务(基于 NestJS)
│ └── admin/ # 管理后台
├── packages/ # 共享的内部包
│ ├── ui/ # 通用 UI 组件库
│ ├── types/ # 共享 TypeScript 类型定义
│ ├── utils/ # 通用工具函数
│ └── core/ # 核心业务逻辑抽象层
├── docker/ # Docker 容器化配置
└── docs/ # 项目文档
这种 Monorepo 的组织方式在大型开源项目中日益常见,它有利于统一依赖管理、提升代码复用率、并简化跨模块的协作。BuildingAI 的 monorepo 实现得比较规整,通过 pnpm workspace 进行管理,确保了开发环境的一致性。
从技术栈的选择上,项目团队展现了对现代 Web 技术栈的成熟把控:
- 前端:Vue 3 + Nuxt 4 + Nuxt UI (基于 Tailwind CSS)。选择 Nuxt 意味着对 SSR/SSG、SEO 以及更好的性能体验有明确要求,这在一款面向企业、可能涉及公开访问应用的管理平台上是合理的工程考量。
- 后端:NestJS + TypeScript。NestJS 的模块化、依赖注入特性非常适合构建结构清晰、可测试性高的后端服务,这与 BuildingAI 宣称的“企业级”定位相符。
- 数据库:PostgreSQL 作为主关系型数据库,Redis 用于缓存和会话管理。这是一个经典且稳健的选择,支持复杂查询和高并发场景。
- 全链路类型安全:前后端均使用 TypeScript,并在 packages/types 中维护共享类型定义,这显著提升了大型项目的代码可靠性和开发者体验。
整体来看,BuildingAI 的架构在启动之初就考虑了较高的工程完备性,没有采用“先跑起来再重构”的常见快速原型策略,这为其长期维护和扩展奠定了良好的基础。
关键模块深度分析
- 智能体(Agent)执行引擎
在 packages/core/agent 目录下,定义了智能体的核心抽象与执行流程。其设计并非一个简单的 Prompt 组装器,而是一个可编排的工作流执行引擎。
关键文件 agent-engine.ts 揭示了一个基于状态机的执行模型:
- 编排逻辑:智能体被定义为由多个“能力单元”(Capability Unit)通过有向图连接而成的工作流。每个单元可以是基础 LLM 调用、知识库检索(RAG)、工具调用(MCP)或条件判断。
- 上下文管理:设计了独立的 ContextManager 类来处理多轮对话中的上下文保持、修剪与注入。值得注意是,它实现了基于 Token 数或轮次的双重淘汰策略,这在平衡上下文长度与成本/性能时很实用。
- 工具调用(MCP)集成:通过 mcp-adapter 模块,将 Model Context Protocol 规范的工具抽象为统一的 Tool 接口。代码显示,它支持动态加载远程或本地工具定义(tools.json),实现了插件热插拔的能力。这种设计使得扩展新工具无需重启服务。
与 Dify 的工作流设计相比,BuildingAI 的 Agent 引擎在代码结构上显得更偏向于程序化定义和强类型约束。Dify 的工作流节点更多以可视化配置为核心,其底层执行引擎的抽象层级可能更高。而 BuildingAI 的引擎代码中暴露了更多的执行细节和控制钩子(Hooks),这为开发者进行深度定制提供了可能性,但也带来了一定的上手复杂度。
2.知识库(RAG)模块++
知识库实现位于 apps/server/modules/knowledge-base。其架构清晰地分为了索引、存储、检索三个层次:
- 索引层:支持多种向量化模型(通过 VectorModelAdapter 抽象),代码中已看到对接 OpenAI Embeddings 和本地 Sentence Transformer 的适配器。索引过程被设计为异步任务队列(Bull.js),避免阻塞主请求。
- 存储层:向量数据支持 PostgreSQL(pgvector)和 Qdrant。元数据和文件信息存储在 PostgreSQL 中。这种分离存储的设计提供了灵活性。
- 检索链:检索并非简单的向量相似度搜索。在 retrieval-chain.ts 中,实现了一个可配置的“检索-重排”管道。默认流程是:向量搜索 -> 关键词补充 -> 相关性重排(使用 Cross-Encoder)。这种多阶段检索策略在实践中能有效提升准确率。
- 工程亮点:知识库的文件解析器(file-parsers/)设计得非常模块化,支持 Markdown、PDF、Word、Excel 等多种格式。每种解析器都实现了统一的 ContentParser 接口,并加入了简单的错误恢复机制,这体现了对生产环境复杂性的考虑。
3.多模型与计费聚合层
这是 BuildingAI 区别于许多纯技术研究型项目的关键商业模块,代码位于 apps/server/modules/llm-gateway 和 apps/server/modules/billing。
- LLM 网关:它作为一个统一的代理,对接了 OpenAI、Azure、文心一言、通义千问等十多个模型供应商。其核心价值在于抽象了不同厂商 API 的差异,为上层应用提供了统一的聊天、补全、嵌入接口。代码中使用了策略模式,每个供应商对应一个 ProviderStrategy 实现。更关键的是,网关集成了流式响应、Token 计数和简单的故障转移逻辑。
- 计费系统:与 LLM 网关深度集成。在 LLMInvocationInterceptor 这个拦截器中,每次模型调用后会实时计算消耗的 Token 数,并调用计费服务进行扣费或配额检查。计费模块自身实现了套餐、订单、支付(对接微信/支付宝)等完整闭环。从代码耦合度看,计费并非事后嫁接,而是在架构初期就被纳入核心链路,这使得其“开箱即可商用”的宣称有了扎实的工程基础。
4.应用市场与插件系统
apps/server/modules/marketplace 和 packages/plugin-core 构成了项目的扩展生态基石。
- 插件核心:定义了一套完整的插件生命周期(注册、安装、激活、卸载)和沙箱机制。插件可以贡献新的智能体能力、工具(MCP)、甚至前端组件。热插拔的实现依赖于 Node.js 的模块缓存管理和动态导入。
- 应用市场:更像是一个插件管理中心,支持插件的发现、安装、版本更新。代码显示,它支持从远程仓库或本地文件安装插件。
- 扩展性评价:这套插件系统的设计复杂度较高,但其清晰的接口契约和生命周期管理,使得 BuildingAI 的平台化属性非常突出。开发者不仅可以“使用”平台,还可以“扩展”和“销售”自己的插件,这为其生态构建提供了技术上的可行性。
工程实践亮点
- 配置驱动的灵活性:项目大量使用 JSON Schema 和配置文件来定义智能体、工作流、知识库索引策略等。这种“配置即代码”的理念,平衡了灵活性和复杂度,使得高级用户可以通过修改配置而非代码来实现定制。
- 错误处理与可观测性:代码中遍布结构化的错误日志(使用 Pino)、完善的异常类型定义和事务回滚机制。在关键链路上(如模型调用、支付)实现了重试和降级策略。集成了 OpenTelemetry 用于链路追踪的雏形,体现了对可观测性的重视。
- 数据隔离与多租户:在数据库表设计和 API 层,普遍看到了 tenant_id 和 organization_id 字段。权限系统(apps/server/modules/auth)基于角色的访问控制(RBAC)实现得比较细致,支持到数据行级隔离,这满足了企业级部署的多团队使用场景。
- 容器化与部署友好:docker-compose.yml 文件提供了完整的开发和生产环境示例,涵盖了应用、数据库、缓存、向量数据库等所有依赖。一键部署的体验打磨得较好。
架构哲学对比
与 Dify、扣子等平台进行横向技术对比,能更好地理解 BuildingAI 的工程定位:
- Dify:更偏向于 “AI 应用开发工作台”,其核心技术理念是让开发者通过可视化编排,快速构建基于 LLM 的应用。它的架构核心是高度抽象的工作流引擎和直观的界面,降低使用门槛是首要目标。其开源版本在商业闭环能力(如多租户、复杂计费)上相对轻量。
- 扣子:作为大厂产品,其技术封闭,但从其定位看,更侧重低代码和生态集成,与现有办公流程结合紧密。作为云服务,其架构考虑更多的是规模、稳定性和生态可控性。
- BuildingAI:从代码呈现出的架构看,它定位为 “企业级、可私有化、自带商业底座的开源基础设施”。它不回避复杂性,提供了从模型接入、智能体编排、知识库管理、用户权限到支付计费的全栈解决方案。其架构设计明显考虑了长期维护、深度定制和私有化部署的需求。一体化设计让它在真实工程落地时,省去了自行拼装认证、计费、运维等多个子系统的工作量和集成风险。
总结
从纯粹的工程视角分析,BuildingAI 的代码库展示了一个目标明确、架构完整、工程实践成熟的开源项目。
其技术完整性令人印象深刻。它没有停留在“另一个智能体编排工具”的层面,而是系统地解决了 AI 应用从开发、测试到上线运营、商业化整个生命周期中的工程技术问题。Monorepo 管理、全链路类型安全、清晰的模块边界、深入的插件化支持,这些选择都指向了其对项目长期生命力和可维护性的高要求。
当然,这种完整性也带来了相应的复杂度。对于仅需要一个简单智能体原型的团队,BuildingAI 可能显得“过重”;但对于计划将 AI 能力深度整合到业务流程,并需要私有化部署、独立商业化运营的“先进组织”或创业者而言,BuildingAI 提供的一站式解决方案,显著降低了在架构拼装、系统集成和合规性处理上的工程成本和潜在风险。
它的架构表明,团队不仅理解 AI 技术,更深刻理解将 AI 转化为可持续商业服务所必需的软件工程体系。在众多 AI 开源项目中,BuildingAI 选择了一条更具工程挑战但也更贴合企业真实需求的道路。其后续发展,值得广大工程师和架构师持续关注。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 42
42 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)